UUID 도입 배경과 과정
배경
- 우리 서비스는 소개팅 서비스로 유저와 유저가 상호작용 하기 때문에 url이나 message body에 상대방의 userId가 들어가는 경우가 종종 있다 예를들어 "/v1/어쩌고/저쩌고/{user-id}" 를 사용해서 추천, 매칭이 이미 진행된 상대방의 프로필을 볼 수 있다
- 물론 서버 내부에서 허가되지 않는 프로필 조회는 막긴 하지만(정말 너가 얘랑 매칭된게 맞는지 등등) 세션이나 jwt로 userId를 숨겨서 주는데 저렇게 심지의 타인의 userId가 노출 된다면 이는 의미가 퇴색된다고 생각했다
- 번호를 보고 서비스의 규모를 추정할 수 있어진다, 소개팅 서비스 특성상 유저 풀에 대해서 예민할 수 있다
실제로 잘못된 userId에 접근하여 슬랙 에러 알림으로 알림이 여러번 온 적 있었다 우리는 어떤 id를 요청했을때 에러가 발생하는지 로그를 띄웠는데
1, 2, 3, 4, 5, 6 이렇게 차근차근 위로 올리는 유저가 몇 있었다 ㄷㄷ
이를 해결하기 위해 userId를 암호화해서 보내거나 앞단에서 SPA(상태 관리 라이브러리(예: Redux, Vuex)를 사용해 URL에 민감한 정보를 포함시키지 않고도 페이지를 렌더링) 등 있겠지만 UUID를 입하기로 했다
(그리고 토스 페이먼츠 PG연동할때 필요하기도 해서 도입했다)
도입시 문제점
사실 UUID를 도입하는 것 자체는 너무 쉽다 그렇다고 마냥 도입할 수 없는게 여러 문제점이 있다
1. InnoDB의 클러스터링 인덱스를 효율적으로 사용하지 못한다
클러스터링 인덱스란 저장되는 순서가 PK값을 기준으로 정렬이 되는 것이다. 하지만 uuid는 랜덤 값이기 때문에, 클러스터형 인덱스를 조정 한다
InnoDB 의 테이블에서 순서를 보장하기 위해 기존의 레코드를 페이지 넘어서까지 이동 시켜서 정렬을 한다 레코드 양이 적으면 영향은 적을 수 있지만 레코드 양이 매우 많은 경우 PK 컬럼 데이터의 레코드의 이동은 매우 큰 성능적인 영향을 끼칠수도 있다
2. 세컨더리 인덱스의 크기가 늘어난다
세컨더리 인덱스는 프라이머리 키를 주소처럼 사용한다 uuid는 128비트이기 때문에 일반적으로 사용하는 정수형 pk보다 데이터가 크다
과연 진짜일까?
실제로 값을 넣어서 테스트 해보니 레코드가 100만개는 있어야 어느정도 성능적인 이점이 있다 하지만 어디서 슬로우 쿼리가 발생할 수 있을지 장담할 수 없고 이왕 하는거 미리미리 제대로 해보자
해결
UUID는 16 옥텟 (128비트)의 수이다. 표준 형식에서 UUID는 32개의 십육진수로 표현되며 총 36개 문자(32개 문자와 4개의 하이픈)로 된 8-4-4-4-12라는 5개의 그룹을 하이픈으로 구분한다.
Timestamp - Timestamp - Timestamp & Version - Variant & Clock sequence - Node id
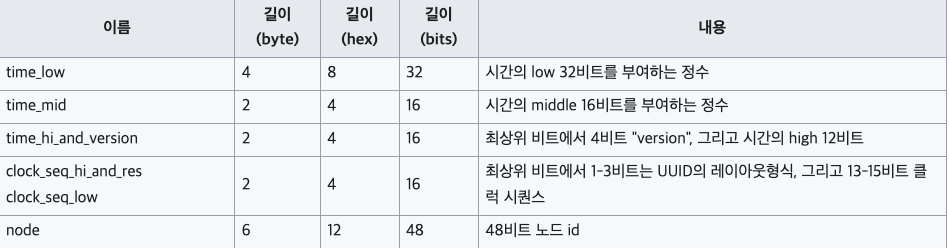
사진 출처: https://ko.wikipedia.org/wiki/%EB%B2%94%EC%9A%A9_%EA%B3%A0%EC%9C%A0_%EC%8B%9D%EB%B3%84%EC%9E%90
5개의 버전이 존재하며 각 버전마다 UUID를 만드는 방식이 다르다
버전 1 (MAC 주소) : 현재시간과 MAC주소를 기반으로 생성
버전 2 (DCE 보안) : 현재시간과 MAC주소와 DCE Security version으로 생성
버전 3 (MD5 해시) : MD5해시를 기반으로 이름과 네임스페이스에 대한 조합으로 생성
버전 4 (랜덤) : 랜덤한 값으로 생성
버전 5 (SHA-1 해시) : 이름과, SHA-1 해싱으로 생성
버전3은 MD5알고리즘이 보안에 취약하고 네임스페이스에 의존적이기 때문에
버전5도 네임스페이스에 의존적
버전2는 Mac주소를 사용하기 때문에 보안에 취약하다
4는 가장 많이 쓰이지만 랜덤이기 때문에 "도입시 문제점"에 말한 문제가 발생한다
그럼 1버전을 사용해야 하나?
하지만 1버전은 Mac주소를 사용하기 때문에 보안에 취약하다
버전7도 있다
버전7은 시간 기반 랜덤 UUID로, 타임스탬프와 랜덤 데이터를 결합하여 생성된다. 이는 Version 1과 Version 4의 장점을 결합한 형태로 볼 수 있다고 한다
버전7은 UUID는 타임스탬프를 앞부분에 포함하고, 나머지 부분을 랜덤 데이터로 채운다 타임스탬프가 앞에 있기 때문에 시간 순서대로 UUID가 생성된다 그렇기 때문에 데이터베이스에서 시간에 따라 순차적인 UUID 값을 생성할 수 있다 이는 B-tree 인덱스에서 4버전 보다 성능이 좋아진다
그래서 버전 7을 도입하기로 했다
implementation 'com.fasterxml.uuid:java-uuid-generator:4.1.0' UUID uuidV7 = Generators.timeBasedEpochGenerator().generate();이렇게 생성할 수 있다, 그러면 이거를 매번 데이터를 삽입할 때마다 저런 코드를 작성해야 할까?
중복된 일을 제거해보자
우리는 JPA를 사용중인 ㅅ
@Id
@GeneratedValue(generator = "UUID")
@GenericGenerator(
name = "UUID",
strategy = "your.directory.UUID7Generator" // 커스텀 UUID 7 생성기 사용
)
@Column(name = "id", updatable = false, nullable = false, columnDefinition = "BINARY(16)")
private UUID id;public class UUID7Generator implements IdentifierGenerator {
@Override
public Serializable generate(SharedSessionContractImplementor session, Object obj) throws HibernateException {
// UUID Version 7 생성
return Generators.timeBasedEpochGenerator().generate();
}
}코드는 Hibernate를 사용하여 UUID 버전 7을 데이터베이스에 저장할 때 커스텀 생성기를 만들었다
여기서는 UUID7Generator라는 클래스가 사용자 정의 UUID Version 7 생성기고, 엔티티 클래스의 id 필드를 위한 UUID를 생성한다
Generators.timeBasedEpochGenerator(): com.fasterxml.uuid 라이브러리의 메서드로, UUID 버전 7을 생성하는 데 사용한다 POSIX Epoch Time(1970년 1월 1일부터 경과한 시간)을 기반으로 하여 고유한 UUID를 생성한다. 이를 통해 시간이 흐름에 따라 순차적으로 증가하는 UUID가 생성된다
@GeneratedValue(generator = "UUID"): generator 속성으로 "UUID"라는 이름의 커스텀 생성기를 사용하도록 지정
@GenericGenerator:
name: "UUID"로 설정된 생성기의 이름 @GeneratedValue(generator = "UUID")에서 이 이름을 참조하여 UUID를 생성하는 로직을 연결,
strategy: "your.directory.UUID7Generator"는 UUID를 생성하는 커스텀 클래스(UUID7Generator)를 지정한다 이 클래스를 사용하여 Hibernate가 엔티티의 PK를 생성한다
결과, 테스트
처음에 문제 정의를 할 때 랜덤한 uuid4는 데이터가 삽입될 때마다 B-트리에 페이지단위를 넘어서는 인덱스 재정렬이 일어나기 때문에 시퀀스인 uuid7를 공부하고 적용한 것이다
과연 진짜일까?
uuid4, uuid7을 비교해보자
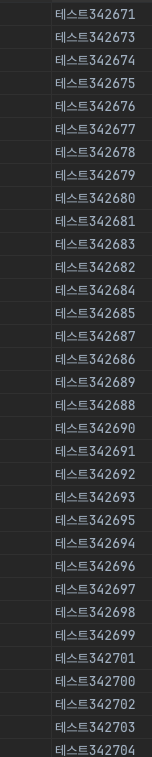
100만건 데이터 삽입 시간
uuid7

uuid4

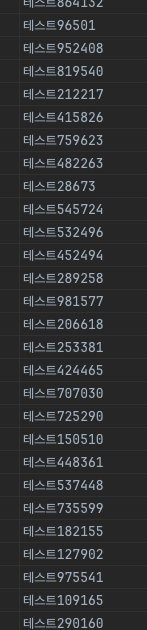
정리하자면 uuid version 4는 14분 11초가 걸렸고, uuid version7은 13분 39초가 걸렸다
그리고 uuid 7버전은 시간 단위로 잘 정렬이 되는걸 볼 수 있지만 uuid4는 그렇지 않다는 것도 알 수 있다.
조회도 적용하고 싶지만 노트북 쿨링팬 돌아가는 소리가 들리면서 컴퓨터가 너무 힘들어 한다 여기까지만 해야겠다
참고:
https://www.baeldung.com/java-generating-time-based-uuids
https://ko.wikipedia.org/wiki/%EB%B2%94%EC%9A%A9_%EA%B3%A0%EC%9C%A0_%EC%8B%9D%EB%B3%84%EC%9E%90

이욜