멀티 칼럼 인덱스 도입
배경
소개팅 주선 서비스에서 추천 데이터가 있다.
다른 데이터에 비해 추천 데이터는 엄청나게 많이 생긴다. 보통 한 유저당 일주일에 평균적으로 5~10개의 추천 데이터가 생기기 때문에 추천 데이터가 많이 쌓여있는 상태다 그리고 앞으로 유저가 많아질수록 추천 데이터 증가 폭은 5~10배 늘어나므로 앞으로도 계속 많이 쌓일 예정이다 쿼리 튜닝을 한다면 지금 이 부분이 가장 1순위라고 생각해서 튜닝을 진행 해 봤다
문제 해결
기존
SELECT
r.id AS recommendationId,
up.career_detail AS careerDetail,
up.age AS age,
up.user_representative_images AS userRepresentativeImages
FROM
recommendation r
INNER JOIN
users u ON r.partner_user_id = u.id
INNER JOIN
user_profile up ON u.user_profile_id = up.id
WHERE
r.type = 'NORMAL'
AND r.to_user_id = UUID_TO_BIN('0192d3d9-0ccd-79a8-8dac-cc948a0b71eb')
AND r.deleted_at IS NULL;
ORDER BY r.id ASC기존 쿼리이다 join이 2번 들어가는 상황이다 일주일에 한번씩 추천 데이터가 초기화되기 때문에 유저가 한번에 볼 수 있는 추천 데이터는 최대 10개 뿐이라 현상황에서는 정렬은 따로 넣어주지 않았다 근데 왜 id로 정렬하냐면
ORDER BY를 안 써도 정렬이 되니까 ORDER BY를 쓰면 두 번 정렬이 된다고 생각할 수 있는데, 그렇지 않다고 한다. MySQL서버는 정렬을 인덱스로 처리할 수 있는 경우, 부가적으로 불필요한 정렬 작업은 수행하지 않는다. 그러므로 ORDER BY를 쓰는 습관을 가지는게 좋다. 혹시나 실행 계획이 변경 되었을 때, ORDER BY가 명시되지 않았다면 원하는 결과가 나오지 않을 수도 있다.
지금 보면 join두번과 WHERE절에서 성능 오버헤드가 발생하지 않을까 예상이 되긴 하지만 실행계획을 봐보자
먼저 EXPLAIN ANALIZE를 사용해서 봐보자
-> Nested loop inner join (cost=101289 rows=0.0199) (actual time=34.6..266 rows=13 loops=1)
-> Inner hash join (r.PARTNER_USER_ID = u.ID) (cost=101289 rows=0.0199) (actual time=34.5..266 rows=13 loops=1)
-> Filter: ((r.TO_USER_ID = <cache>(uuid_to_bin('0192d3d9-0ccd-79a8-8dac-cc948a0b71eb'))) and (r.`type` = 'NORMAL') and (r.DELETED_AT is null)) (cost=50639 rows=99.6) (actual time=34.4..266 rows=13 loops=1)
-> Table scan on r (cost=50639 rows=996200) (actual time=0.0775..234 rows=1e+6 loops=1)
-> Hash
-> Covering index scan on u using FK_USERS_USER_PROFILE_ID (cost=0.45 rows=2) (actual time=0.0915..0.0931 rows=2 loops=1)
-> Single-row index lookup on up using PRIMARY (ID=u.USER_PROFILE_ID) (cost=0.00301 rows=1) (actual time=0.00432..0.00434 rows=1 loops=13)
들여쓰기는 호출 순서를 의미하며, 실제 실행 순서는
들여쓰기가 같은 레벨에서는 상단의 위치한 라인이 먼저 실행
들여쓰기가 다른 레벨에서는 가장 안쪽에 위치한 라인이 먼저 실행
- recommendation 테이블 조건 필터링 (Table scan on r)
- 작업: recommendation 테이블에서 조건을 충족하는 행을 찾기 위해 전체 테이블 스캔을 수행
- 조건: type = 'NORMAL', to_user_id = UUID_TO_BIN('0192d3d9-0ccd-79a8-8dac-cc948a0b71eb'), deleted_at IS NULL
- 추가 정보: recommendation 테이블에서 이 조건을 모두 만족하는 행을 찾아냄
- 실행 세부 정보:
- 비용: cost=50639, 예상 행 수: rows=996200.
- 실제 시간: actual time=0.0775..234 (이 단계에서 100만 개의 행을 스캔하며, 최종적으로 13개의 행이 조건에 맞는 행으로 선택) - 이 단계에서 반환된 13개의 행이 다음 조인 단계로 전달.
- 해시 테이블 생성 및 users 테이블 조회 (Covering index scan on u using FK_USERS_USER_PROFILE_ID)
- 작업: users 테이블에서 recommendation.partner_user_id와 일치하는 users.id를 찾아 해시 테이블을 생성
- 조건: r.partner_user_id = u.id를 만족하는 행을 FK_USERS_USER_PROFILE_ID 인덱스를 사용하여 조회
- 실행 세부 정보:
- 비용: cost=0.45, 예상 행 수는 rows=2.
- 실제 시간: actual time=0.0915..0.0931 (최종적으로 2개의 행이 검색). - 해시 조인을 위해 users 테이블에서 조회한 데이터를 해시 테이블에 저장
- 해시 조인을 사용한 recommendation과 users 결합 (Inner hash join)
- 작업: recommendation의 필터링된 13개의 행을 해시 조인을 통해 users 테이블의 결과와 결합.
- 조건: recommendation.partner_user_id = users.id
- 실행 세부 정보:
- 비용: cost=101289, 예상 행 수는 rows=0.0199.
- 실제 시간: actual time=34.5..266, 13개의 행을 반환.
- user_profile 테이블에서 단일 행 조회 (Single-row index lookup on up using PRIMARY)
- 작업: 조인된 결과 13개 행 각각에 대해 user_profile.id = users.user_profile_id 조건을 사용하여 user_profile 테이블에서 단일 행 조회.
- 조건: ID = u.USER_PROFILE_ID
- 실행 세부 정보:
- 비용: cost=0.00301, 예상 행 수는 rows=1.
- 실제 시간: actual time=0.00432..0.00434, 13번 반복하여 user_profile에서 13개의 최종 결과 행을 반환
또한 Inner Hash Join이 적용된 것을 볼 수 있따. MySQL 8.0부터 도입된 Batched Key Access (BKA) 와 Block Nested Loop (BNL) 방식의 최적화 덕분에, 쿼리에 따라 Hash Join을 선택할 수 있다
BKA랑 BNL에 대해서
MRR과 배치 키 액세스(mrr & batch_key_access)(off)
MRR (multi-range read), DS-MRR(disk sweep multi-range read)라고도 함.
기존에는 네스티드 루프 조인 방식을 사용함 드라이빙 테이블의 레코드를 한 건 읽어서 드리븐 테이블의 일치하는 레코드를 찾아서 조인을 수행하는 방식
네스티드 루프 조인 방식에서는 조인 처리를 MySQL 엔진이 담당하고, 실제 레코드를 검색하고 읽는 부분은 스토리지 엔진이 담당, 이런 방식에서는 스토리지 엔진에서는 최적화를 수행할 수 없음
이런 단점을 보완하기 위해 조인 버퍼에 조인 대상을 버퍼링한다. 조인 버퍼에 레코드가 가득 차면 MySQL 엔진은 버퍼링된 레코드를 스토리지 엔진으로 한 번에 요청한다. 이렇게 해서 디스크 읽기를 최소화할 수 있다. 이 방식을 MRR이라고 한다.
MRR을 응용해서 실행되는 조인 방식을 BKA(Batched Key Access) 조인이라고 한다. 부가적인 정렬 작업이 필요해서 성능이 저하되기도 한다.
결론: 버퍼링된 걸 원기옥처럼 모아서 스토리지 엔진에 전달하기 때문에 디스크 접근 횟수는 줄어든다.
블록 네스티드 루프 조인(on)
조인의 연결 조건이 되는 칼럼에 모두 인덱스가 있는 경우 사용되는 조인 방식이다
네스티드 루프 조인과 차이점은 조인 버퍼 사용 여부와 조인에서 드라이빙 테이블과 드리븐 테이블이 어떤 순서로 조인되느냐다. 블록 네스티드 루프 조인에서는 조인 버퍼가 사용된다. 실행 계획에서 Extra 칼럼에 Using join buffer가 표시되면 조인 버퍼를 사용한다는 것을 의미한다.
조인은 드라이빙 테이블에서 일치하는 레코드의 건수만큼 드리븐 테이블을 검색하면서 처리된다. 그래서 드리븐 테이블을 검색할 때 인덱스를 사용할 수 없는 쿼리는 느려진다.
옵티마이저는 드라이빙 테이블에서 읽은 레코드를 메모리에 캐시(조인 버퍼)한 후 드리븐 테이블과 이 메모리 캐시를 조인하는 형태로 처리한다.
조인 버퍼가 사용되는 쿼리에서는 조인의 순서가 거꾸로인 것처럼 실행된다. A가 드라이빙, B가 드리븐 테이블일 때, A에서 검색된 레코드를 조인 버퍼에 담아두고, B의 레코드를 먼저 읽고 조인 버퍼에서 일치하는 레코드를 찾는 방식으로 처리된다.
결론: 드라이빙 테이블을 먼저 읽어 메모리에 올려둔 후, 드리븐 테이블을 읽으면서 캐싱된 드라이빙 테이블값과 연계지어 조인을 처리 / 네스티드 루프 조인은 조인 버퍼를 사용하지 않지만, 얘는 조인버퍼를 사용함
그렇다면 왜 옵티마이저는 recommendation과 user는 해시조인을 선택하고 user_profile에는 nested Loop Join을 선택했을까?
users 테이블이 크지 않지만, 한 번 해시 테이블을 생성하면 레코드가 많은 recommendation 테이블의 모든 일치하는 레코드를 빠르게 조회할 수 있으므로 Hash Join 선택
user_profile 테이블은 PRIMARY 키 (ID)를 사용한 단일 행 조회가 가능 이 상황에서 해시 테이블을 만드는 비용보다 단일 행을 직접 조회하는 비용이 더 적다
조인 순서에 의한 영향: 옵티마이저는 recommendation과 users의 조인을 먼저 실행하고, 그 결과와 user_profile을 조인한다 이전 조인 결과가 적은 양의 데이터라면, 남은 테이블에 대해 Nested Loop Join을 선택해 빠르게 단일 행을 조회하는 것이 효율적
일단 지금은 join을 할 때 FK로 join을 하기 때문에 예상대로 클러스터링 인덱스로 성능 오버헤드가 크지 않을 것으로 예상된다

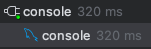
이정도의 시간이 걸린다
추천 테이블의 type이 ALL로 표시되어 있는데, 이는 해당 테이블에 대해 풀 테이블 스캔이 발생하고 있다는 것을 의미한다
추천 테이블에 적절한 인덱스를 추가해보자
인덱스 적용 후
CREATE INDEX idx_recommendation_type_to_user_id_deleted_at ON recommendation (type, to_user_id, deleted_at);이렇게 다중 칼럼 인덱스를 생성 해 줬다

실행 계획은 이렇다.
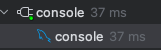
확실히 빨라진게 보인다 솔찍히 320ms -> 37ms 는 지금 당장 큰 의미는 없지만 추후에 추천 데이터는 일주일마다 엄청나게 늘어나기 때문에 미리미리 했다
추후에 정렬기준이 생긴다면 거기에도 인덱스를 걸어줘야 할 것 같다
그리고 인덱스를 걸었으니, 나중에 쿼리나 DB스펙이 변경된 경우 인덱스도 잘 관리해 줘야겠다
다중 칼럼 인덱스는 지정된 컬럼 순서에 따라 왼쪽부터 차례로 접근해야 최적의 성능을 제공한다
따라서, 인덱스는 to_user_id, type, deleted_at의 순서로 조건을 사용할 때 가장 효과적이다
