스터디 참여 로직 동시성 처리
1. 문제상황
- study hub 서버 개발을 하면서 유저가 스터디에 참여를 하면 스터디 게시글(studyPost)에 remainingSeat(잔여석)이 -1되어야 한다
- 멀티 쓰레드나 서버가 여러대일 경우에는 studyPost의 동시성 처리를 해야 동시에 참여한 유저가 발생할 경우 잔여석 감소 로직이 잘 돌아간다
StudyPostApplyEvenPublisher.class
@Component
@RequiredArgsConstructor
public class StudyPostApplyEventPublisher {
private final StudyPostRepository studyPostRepository;
@Transactional
public void acceptApplyEventPublish(Long studyId) {
StudyPostEntity studyPost = studyPostRepository.findByStudyId(studyId).orElseThrow(PostNotFoundException::new);
studyPost.decreaseRemainingSeat();
studyPostRepository.save(studyPost);
}
}StudyPostEntity.class
public void decreaseRemainingSeat() {
if (this.remainingSeat - 1 < 0) {
throw new NoRemainingSeatsException();
}
this.remainingSeat -= 1;
}StudyPostApplyEventPublisherTest.class
@Test
void 동시에_100개의_요청의_스터디_지원서가_수락되면_게시글의_잔여석이_줄어든다() throws InterruptedException {
// given
Long postedUserId = 1L;
StudyPostEntity post = StudyPostEntityFixture.SQLD.studyPostEntity_생성(postedUserId);
StudyPostEntity savedPost = studyPostRepository.saveAndFlush(post);
// when
int threadCount = 100;
ExecutorService executorService = newFixedThreadPool(32);
CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
executorService.submit(() -> {
try {
studyPostApplyEventPublisher.acceptApplyEventPublish(post.getStudyId());
} finally {
latch.countDown();
}
});
}
latch.await();
// then
StudyPostEntity actualStudyPost = studyPostRepository.findById(savedPost.getId()).orElseThrow();
assertEquals(0, actualStudyPost.getRemainingSeat());
}테스트 코드는 잔여석이 100명으로 지정된 스터디를 100명이 동시에 지원하는 경우의 테스트 코드이다
ExecutorService는 비동기로 실행하는 작업을 단순화하여 사용할 수 있게 해주는 자바 api이다
CountDownLatch는 100개의 요청이 끝날떄까지 기다려야 하므로 countDownLatch사용했다, 다른 쓰레드에서 수행중인 작업이 완료될때 까지 대기할 수 있도록 해주는 클래스이다
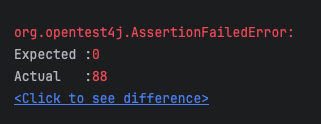
잔여석이 0개여야하는데 88개의 잔여석이 남았다
왜 이런 문제가 발생할까?
간단하게 쓰레드가 두개라고 가정해보자
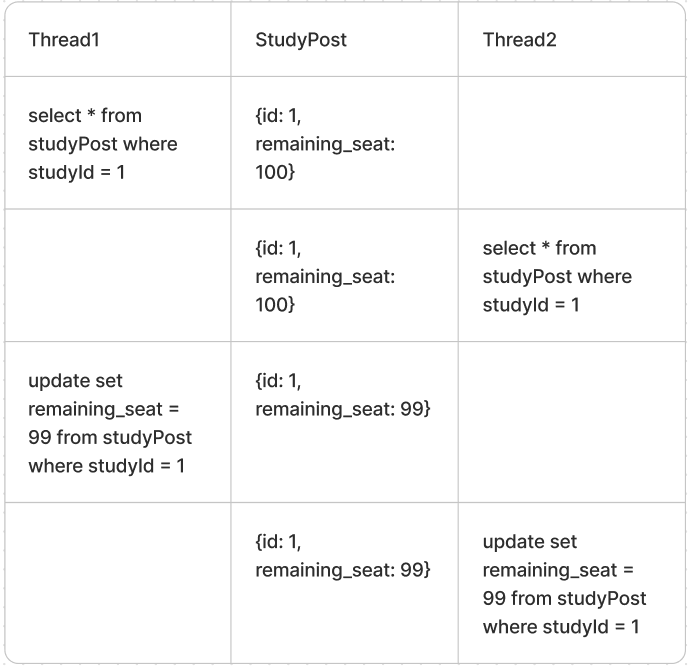
쓰레드 1이 데이터를 가져가서 데이터를 갱신한 값을 쓰레드 2가 가져가서 갱신한다고 생각했지만 실제로는 쓰레드1이 데이터를 가져가서 갱신하기 전에 쓰레드 2가 데이터를 가져간다 하지만 둘다 재고가 100인 상태에서 1을 줄인 값을 갱신하기 때문에 갱신이 누락된다 두개 이상의 쓰레드가 공유 데이터에 접근할 수 있고 동시에 값을 변경하려 해서 동시성 문제가 발생한 것이다
2. 해결책
하나의 쓰레드가 데이터를 가져가고 갱신한 후에 다른 쓰레드가 접근할 수 있게 해야 한다
1. Synchronized로 해결
자바에서는 Synchronized 사용하면 해당 메서드를 한개의 쓰레드만 접근할 수 있게 한다
@Transactional
public synchronized void acceptApplyEventPublish(Long studyId) {
StudyPostEntity studyPost = studyPostRepository.findByStudyId(studyId).orElseThrow(PostNotFoundException::new);
studyPost.decreaseRemainingSeat();
studyPostRepository.save(studyPost);
}그대로 테스트 코드 돌려보면
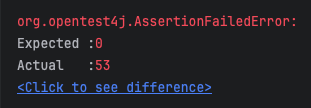
안쓸때보다 잔여석은 줄었지만 그래도 잘 동작하지 않는다
이유는 @Transactional어노테이션 때문이다
동작 과정을 단순하게 풀면
startTansaction();
acceptApplyEventPublish(Long studyId);
commitTransaction();이렇게 @Transactional이 붙은 메서드가 호출되면, Spring은 CGLIB으로 런타임에 동적으로 프록시 객체를 생성한고 그 객체는 원본 객체를 감싸는 형태이다
acceptApplyEventPublish메서드가 미처 트랜잭션에 커밋되지 못하고 undo로그나 트랜잭션 로그에 있을때(잔여석 - 1 을 레코드에 반영하기 직전)에 다른 쓰레드의 acceptApplyEventPublish메서드가 실행 되기 때문이다
해결책은 acceptApplyEventPublish메서드에 @Transactional을 제거하거나 @Transactional을 제거하고 implementations 계층에 decrease()메서드를 추가하고 거기에 @Transactional을 박아도되지만 이거는 단일 서버에서 가능하고 우리는 오토스케일링을 사용하여 부하가 발생할 시 최대 2개까지 ec2를 늘릴 수 있기 때문에 적절한 해결 방법이 아니다
2. Pessimistic Lock
실제로 데이터에 베타lock을 걸어서 다른 트랜잭션에서 lock이 해재되기 전까지 데이터에 접근할 수 없게 된다 하지만 데드락이 걸릴 수 있기 때문에 조심해야 한다
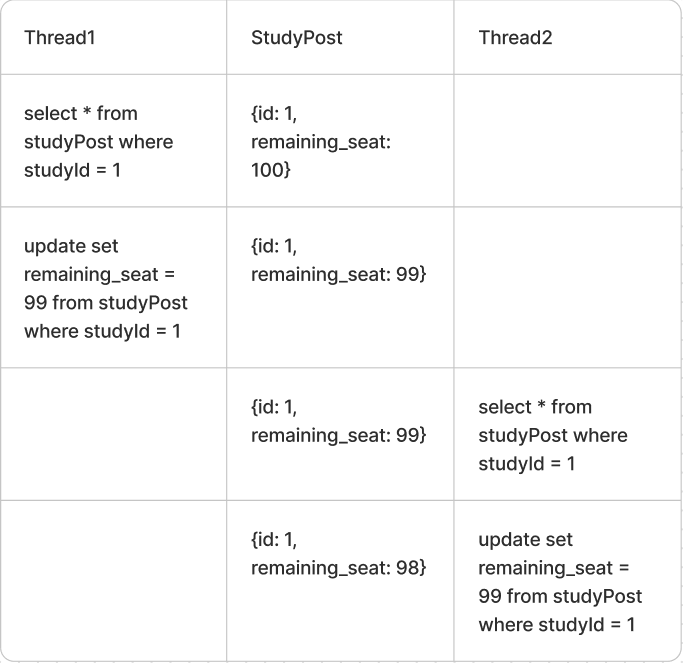
쓰레드1에서 락을 걸고 데이터를 가져가고 점유중이라서 쓰레드2는 대기하게 된다 쓰레드1이 update가 끝나면 쓰레드2가 데이터를 가져가고 점유한다
@Transactional
public void acceptApplyEventPublish(Long studyId) {
StudyPostEntity studyPost = studyPostRepository.findByIdWithPessimisticLock(studyId).orElseThrow(PostNotFoundException::new);
studyPost.decreaseRemainingSeat();
studyPostRepository.save(studyPost);
} @Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select s from StudyPostEntity s where s.studyId = :studyId")
Optional<StudyPostEntity> findByIdWithPessimisticLock(@Param("studyId") Long studyId);이렇게 하면 된다
테스트 코드도 잘 통과한다

하지만 Pessimisitic lock은 별도의 lock을 걸기 때문에 성능 감소가 일어날 수 있다
3. Optimistic Lock
lock을 사용하지 않고 version을 이용하여 정합성을 보장한다 스키마에 version을 추가한다 간단한 동작 방식은
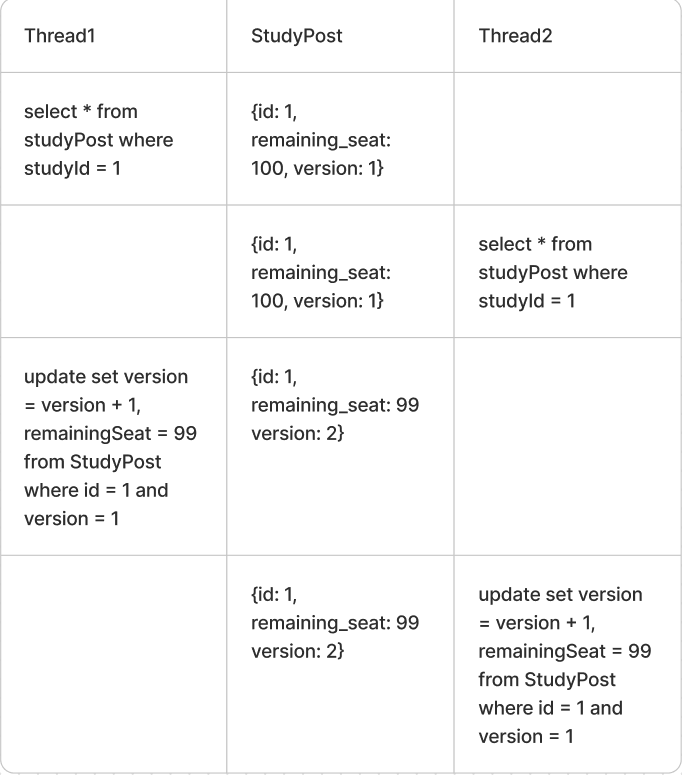
이렇게 버전을 추가해서 update할 때마다 1씩 버전을 올려주는데 쓰레드2의 update문은 실패한다 왜? 레코드의 버전은 2인데 where문에 버전 1 이니까 그럼 쓰레드2의 업데이트는 어칼건데? 별도의 로직을 작성해주어야 한다
@Lock(LockModeType.OPTIMISTIC)
@Query("select s from StudyPostEntity s where s.studyId = :studyId")
Optional<StudyPostEntity> findByIdWithOptimisticLock(@Param("studyId") Long studyId); while (true) {
try{
studyPostApplyEventPublisher.acceptApplyEventPublish(study.getId());
break;
} catch (Exception e) {
Thread.sleep(50);
}
}이렇게 version이 맞지않으면 예외에서 쓰레드를 잠시 멈추고 다시 시도하게 하는 로직을 추가했다
성공했다 하지만 Optimisitc lock은 별도의 lock이 없어서 Pessimsitic lock보다 성능상 이점이 있을 수 있지만 업데이트가 실패했을때 로직을 따로 작성해야 하고 충돌이 빈번하면 Pessimsitic lock보다 성능이 떨어진다 또한 쓰레드가 메서드를 실행하는 순서가 아닌 재시도 로직의 성공 순서가 되어서 5개의 잔여석에 6명이 지원하면 요청한 순서가 아닌 재시도 성공 순서라서 공정하지 않다
4. Named Lock
이름을 갖는 metadata lock을 사용한다 트랜잭션이 종료될 때 lock이 자동으로 해제하지 않는다 Pessimistic락이랑 비슷하지만 Pessimisitic lock은 row나 table단위로 걸지만 named lock은 메타 데이터에 건다
mySQL에서는 getLock명령어로 lock을 획득하고 release명령어로 lock을 해제한다
쉽게 말해서 이전에는 StudyPost의 레코드에 락을 걸었다면 별도의 metadata에 lock을 거는거다
LockRepository로 사용해보자
public interface LockRepository extends JpaRepository<StudyPostEntity, Long> {
@Query(value = "select get_lock(:key, 3000)", nativeQuery = true)
void getLock(String key);
@Query(value = "select release_lock(:key)", nativeQuery = true)
void releaseLock(String key);
}
편의성을 위해 StudyPostEntity에 native query를 사용했는데 제대로 사용하려면 별도의 jdbc를 사용해야 한다
try {
lockRepository.getLock(id.toString());
studyPostApplyEventPublisher.acceptApplyEventPublish(study.getId());
} finally {
lockRepository.releaseLock(id.toString());
}이렇게 lockRepository에 명시적으로 lock을 걸고 끝나면 finally로 lock을 해제해주는 로직을 작성 해 준다
테스트 코드도 잘 돌아간다
주로 분산 락을 구현할때 사용한다 하지만 실제로 제대로 사용하려면 락 해제와 세션관리와 커넥션을 잘 관리해야 하고 같은 데이터소스를 사용하기 때문에 커넥션 풀 사이즈도 관리해야 한다 많이 복잡하다
3. 결론
- Synchronized로 해결 -> 오토 스케일링으로 최대 ec2 두대라서 안됨
- Pessimistic Lock -> 비즈니스 로직상 스터디헙에서 가장 중요한건 스터디 참여기 때문에 데이터의 정확성과 일곤성이 매우 중요해서 적합, 하지만 충돌 가능성이 그다지 높진 않아서 별도의 Lock을 걸기 때문에 성능이 그다지 좋지않음 Optimistic Lock이 더 좋을거같음
- Optimistic Lock -> 스터디 참여 순서가 메서드를 실행하는 순서가 아닌 재시도 로직의 성공 순서가 되어서 5개의 잔여석에 6명이 지원하면 요청한 순서가 아닌 재시도 성공 순서라서 공정하지 않음
- Named Lock -> 제대로 구현하려면 너무 복잡함(다음주 론칭임....) 같은 사유로 Lettuce, Redisson 도 안쓸 예정
Pessimistic Lock을 쓰자
