
생활코딩 👩💻 머신러닝야학
- 밀린 머신러닝 강의를 다 들었다. 수료 전까지 오랜지3 강의까지는 다 들을 예정이다!
- 머신러닝은 처음 공부해보는 분야라서 오늘 배운 내용들을 간단히 밑에 정리해 두겠다.
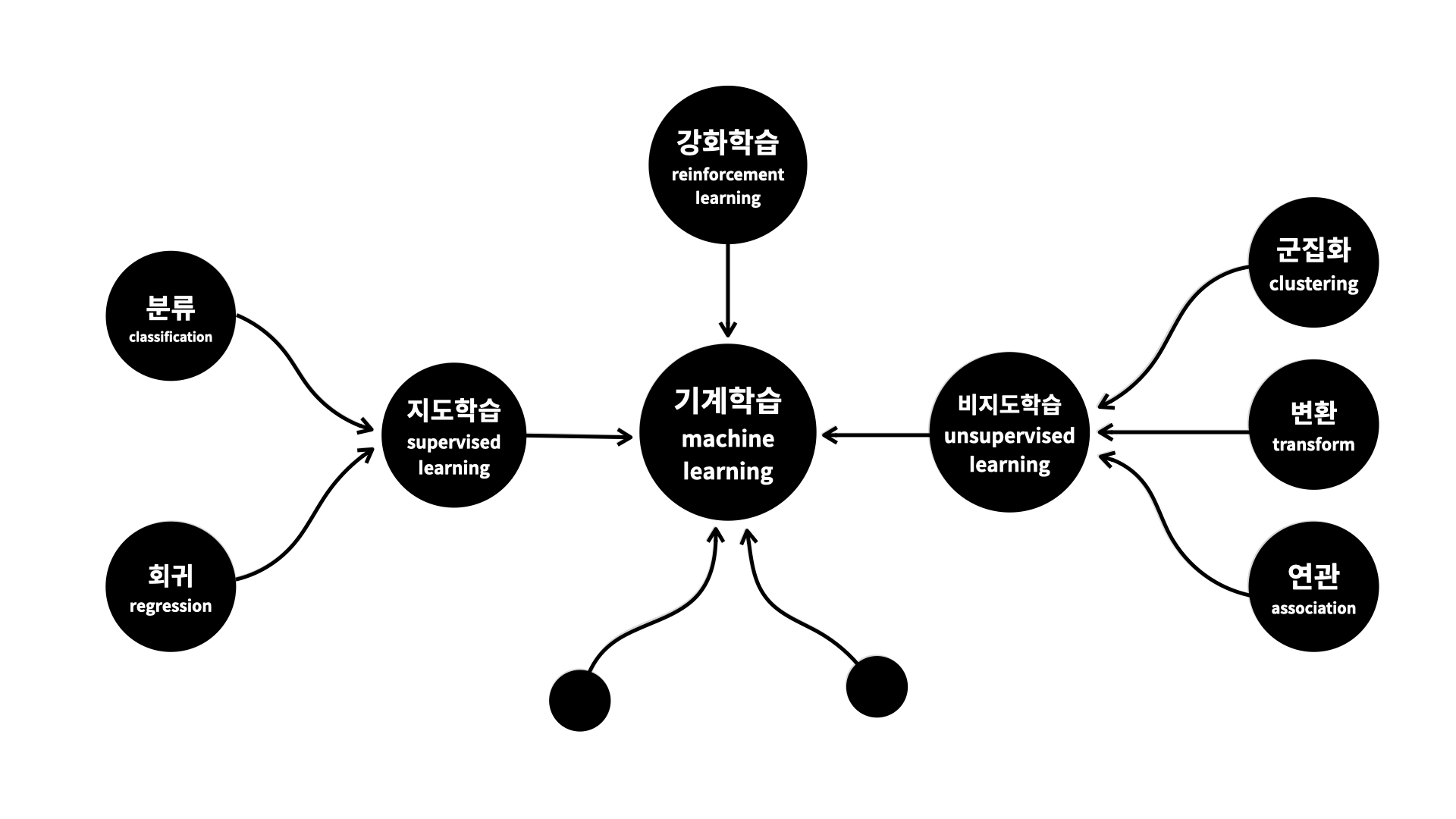
지도학습 Supervised learning
: 과거의 데이터들(독립변수와 종속변수로 이루어진)을 컴퓨터에게 학습시켜 모델(model)을 만든다. 역사적이다.
- 회귀(regression): 예측하고 싶은 종속변수가 숫자일 때 사용하는 지도학습 방법 -> 지도학습의 회귀로 해결해주세요.
- 분류(classification): 예측하고 싶은 결과가 이름 혹은 문자일 때 사용하는 지도학습 방법 -> 지도학습의 분류로 해결해주세요.
- 종속변수가 양적(quantitative) 데이터(숫자) -> 회귀 사용
- 종속변수가 범주(categorical) 데이터(문자) -> 분류 사용
비지도학습 Unsupervised learning
: 데이터를 정리 정돈해서 그 표에 담긴 데이터의 성격을 파악하는 것을 중요한 목적으로 한다. 독립변수와 종속변수의 구분이 중요하지 않다. 탐험적이다.
- 군집화(clustering): 비슷한 것들을 찾아 그룹을 만드는 것. 즉 서로 가까운 관측치(행)를 찾아주는 머신러닝 기법 -> 행을 그룹핑
- 군집화와 분류의 비교: 어떤 대상들을 구분해서 그룹을 만드는 것이 군집화라면, 분류는 어떤 대상이 어떤 그룹에 속하는지를 판단하는 것 - 연관 규칙 학습(association rule learning): 서로 연관된 특징을 찾아내는 것. 즉 서로 관련이 있는 특성(열)을 찾아주는 머신러닝 기법 -> 열을 그룹핑
- 변환(transform): 학습자들을 위한 까치밥(?)으로 남겨주신 부분... 나중에 공부하고 이 부분을 채워놔야겠다.
강화학습 Reinforcement learning
: 경험을 통해 실력을 키워가는 머신러닝 기법.
-> 더 많은 보상을 받을 수 있는 정책을 만드는 것이 핵심
- 주어진 환경(environment)에서 에이전트(agent)가 현재 상태(state)를 파악하고 정책(policy)에 따른 행동(action)을 하는 과정을 반복하며, 더 많은 보상(reward)을 받을 수 있도록 정책(policy)를 보완한다. 즉 판단력을 기른다.
오늘 공부하면서 느낀 점
- 머신러닝 매 강의마다 학습자들의 공부 의욕을 고취해 주시고 스스로를 기특해할 수 있도록 해 주신 기여자분들께 정말 감사하다.
- '수업을 마치며' 강의에서 본 내용이 인상깊어서 여기에도 적어 둔다.
지금까지 사실 소비라고 생각해 온 것들이 사실은 생산활동이었다는 것을 자각하자. 생산과 소비는 편의상 구분해 둔 개념의 신기루일 뿐 사실은 하나이다. 생산은 어렵고 힘든 것이 아니다. 우리가 좋아하는 소비처럼, 생산도 설레고 즐거운 활동임을 곧 알게 될 것이다.
- 즐겁게 좋은 공부를 할 수 있어서 행복했다. 다음에는 오랜지3 강의를 즐겁게 들으며 내용 정리를 해봐야겠다!
- 공부를 잠시 쉬었다가 다시 하려니까 버겁다.. 조금씩 공부량을 늘려봐야겠다. 일 다녀와서 피곤하더라도 조금이라도 공부하고 자야지.

응애 나 애기 개발자