실행 계획
데이터 접근 절차를 결정하는 건 DBMS아키텍처의 쿼리 평가 엔진이다. 이는 쿼리를 가장 처음으로 읽어들이는 모듈이다.
실행 계획 선택 과정
쿼리 평가 엔진은 이전 글에서 언급했듯 연산을 평가하고 플랜을 실행하는 기능, 파서, 옵티마이저를 포함하고 있다.
파서 - 파싱
입력된 SQL은 파서로 전달되어 구문을 분석한다. 즉 사용자가 입력한 SQL구문의 문법적 오류를 검사한다. (FROM 절에 존재하지 않는 테이블을 적는 경우 등)
옵티마이저 - 실행 계획 작성 + 비용 연산
파싱 단계를 통과한 쿼리는 옵티마이저로 전송되어, 인덱스 유무 및 데이터 분산 정보 등을 고려해서 선택 가능한 많은 실행 계획을 작성한다. 이 각 계획의 비용을 연산한다.
그리고 가장 낮은 비용의 실행 계획을 선택한다.
이 때 실제로 최적의 플랜이 선택되지 않는 경우가 있다. 이에 대한 내용은 아래에서 살펴 보자.
카탈로그 매니저
카탈로그 = DBMS의 내부 정보를 모아놓은 테이블들 - 즉 메타데이터 저장소이다.
[카탈로그가 포함하는 정보]
- 테이블별 레코드 수
- 테이블의 필드 수 및 크기
- 필드의 카디널리티
- 필드 값 분포도
- 필드 내부의 NULL 수
- 인덱스 정보
카탈로그 매니저는 이런 카탈로그 정보를 옵티마이저에게 제공한다. 옵티마이저가 실행 계획을 세우기 위해서 필요하다.
플랜 평가
세워진 여러 계의 실행 계획 중에 최적의 결과를 선택한다. 여기서 선택된 실행 계획대로 이후 DBMS가 실제 코드로 변환한 뒤 데이터 접근을 수행한다.
❓옵티마이저가 최적의 플랜을 선택하지 못하는 경우
만약 테이블에 삽입, 갱신, 제거가 수행된다고 하자. 이 때 카탈로그 정보가 갱신되지 않는다면 옵티마이저는 최신 카탈로그 정보를 가지고 있지 않는다.
이 경우 옵티마이저는 과거의 정보를 가지고 있으므로 잘못된 계획을 세우게 된다.
예시로, 테이블을 만들고 1억 건의 데이터를 삽입했는데 카탈로그 정보가 업데이트되지 않는다면 옵티마이저는 해당 테이블에 데이터가 0개라고 생각하고 플랜을 생성한다.
그렇다면 어떻게 해야 할까?
쿼리 실행 계획을 작성할 때 최신 카탈로그 정보를 사용하게 보장해야 한다.
오라클처럼 기본 설정에서 정기적으로 갱신하게 하는 경우도 있고, 갱신 처리가 수행되는 시점에 자동으로 통계 정보가 갱신되는 DBMS도 있다.
[카탈로그 업데이트 시점]
4
- 데이터 삽입, 삭제, 수정시
- 인덱스, 뷰, 테이블 구조 등이 변경될 때
- 수동적으로 관리자가 업데이트할 때
실행 계획
쿼리 실행 계획의 출력 포맷은 DBMS마다 다르지만, 일반적으로 조작 대상 객체, 객체에 대한 조작 종류, 대상 레코드 수를 포함한다.
아래 사진에서 region은 조작 대상 객체, Seq Scan은 조작의 종류를 나타낸다. 마지막으로 대상 레코드 수는 rows에서 표현하고 있다.
이 때 각 조작(조인 등)에서 얼마만큼의 레코드가 처리되는지에 대한 정보는 카탈로그로부터 얻은 메타데이터로부터 얻은 값이다. 따라서 실제 실행한 시점의 정보와 차이가 있을 수 있다.
예시로, 테이블의 모든 데이터를 삭제하고 실행 계획을 다시 검색하면 rows가 그대로 출력된다. 메타 정보가 업데이트되지 않았기 때문이다.
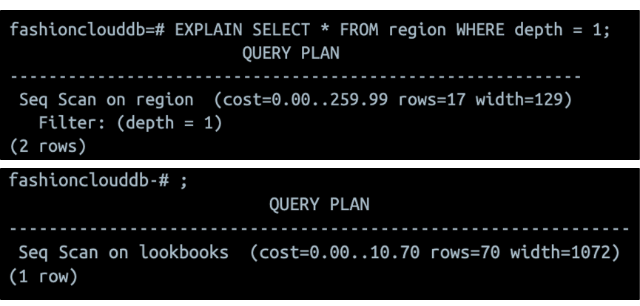
❓ lookbooks에는 데이터가 5개뿐인데 대체 어떤 카탈로그를 가지고 조회했길래 rows가 70이 나올까?
1. 테이블 풀 스캔
레코드 전체를 검색하는 단순한 실행 계획이다.
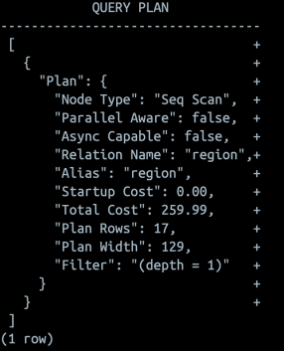
Seq Scan이란 postgreSQL에서 레코드를 순차적으로 접근하여 데이터 전체를 읽어낸다는 것을 의미한다. 물론 전체 스캔이 순차 접근만 포함한다고 보장할 수는 없지만, 실질적으로 같다고 볼 수 있다.
2. 인덱스 스캔
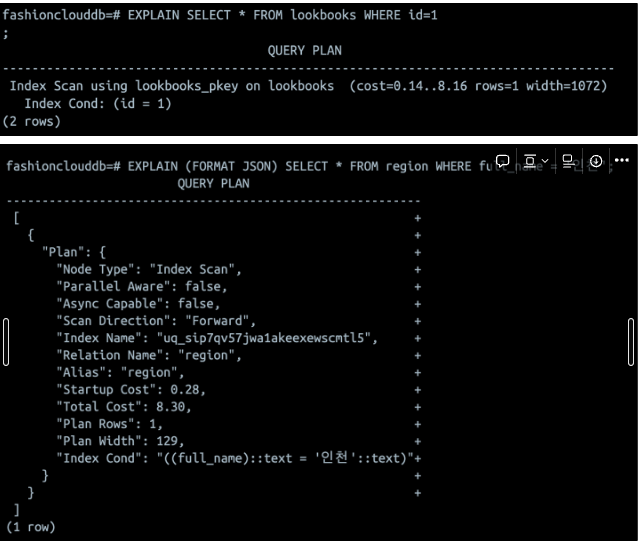
기본적으로 pk에는 클러스터링 인덱스가 걸린다. 따라서 id를 가지고 조건을 걸면 자동으로 Index Scan을 하게 된다.
인덱스를 사용할 때는 B-tree로 처리하여 풀스캔에 비해 훨씬 효율적으로 처리한다. (O(n)과 O(logn)의 차이)
레코드 수가 많아질수록 이 차이는 극명하게 벌어진다.
3. 간단한 조인 실행 계획
결합을 사용하면 실행 계획이 상당히 복잡해진다.
조인 알고리즘은 대표적으로 세 가지가 있다.
이 글에서는 개념만 짚고 넘어가고, 나머지는 조인에 대한 글에서 자세히 살피도록 하겠다.
- Nested Loops
- 가장 간단한 알고리즘으로, 한쪽 테이블을 읽으며 레코드 하나마다 결합 조건에 맞는 다른 쪽의 테이블을 찾음
- 절차 지향적 언어로 구현하면 이중 반복으로 구현되기 때문에 nested loops라고 함
- Sort merge
- 조인 전 전처리 과정에서 결합 키로 레코드를 정렬하고, 순차적으로 두 개의 테이블을 조인함
- 이 때 정렬된 중간 결과를 저장하기 위해 워킹 메모리 사용
- Hash
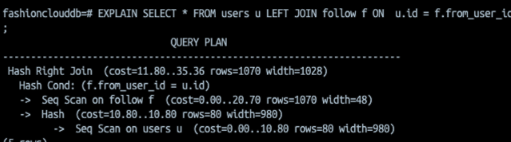
- 결합 키값을 해시값으로 맵핑
- 해시 테이블을 위해 워킹 메모리 사용
실행 계획은 트리 구조로 이루어진다. 중첩 단계가 깊을 수록 먼저 수행되고, 같은 단계에서는 위에서 아래로 실행한다.
예시로 PostgreSQL에서는 Nested Loop보다도 Seq Scan이나 Index Scan의 단계가 깊다. 따라서 결합 전에 테이블 접근이 먼저 수행된다.
실행 계획의 변경
옵티마이저가 최적의 실행 계획만을 선택하지는 않는다. 옵티마이저가 최적의 계획을 선택하지 않는다면, 수동으로 실행 계획을 변경하는 최후의 방법을 사용해야 한다.
