[Redis] 캐시 전략, Redis 아키텍처
- 메모리에 복구하는 방법
- 기본 설정
- key eviction
- 자료구조
- 캐시 읽기 전략
- 캐시 쓰기 전략
- Redis 아키텍처 3가지
- Redis 클러스터링
- Failover
- 캐시 설계시 고려할 점
- 권장 설정
- 파이프라이닝
- 트랜잭션
- 성능에 영향을 미치는 요인
- memory fragmentation
Redis 기본 동작
데이터를 어떻게 복구?
- 인메모리 데이터베이스지만, 디스크에 백업 가능
- 기본적으로 인메모리 데이터베이스는 휘발성이므로 서버가 꺼지면 데이터가 유실되지만, Redis는 디스크에 데이터를 백업하고 다시 읽어서 메모리에 로드하는 기능을 제공
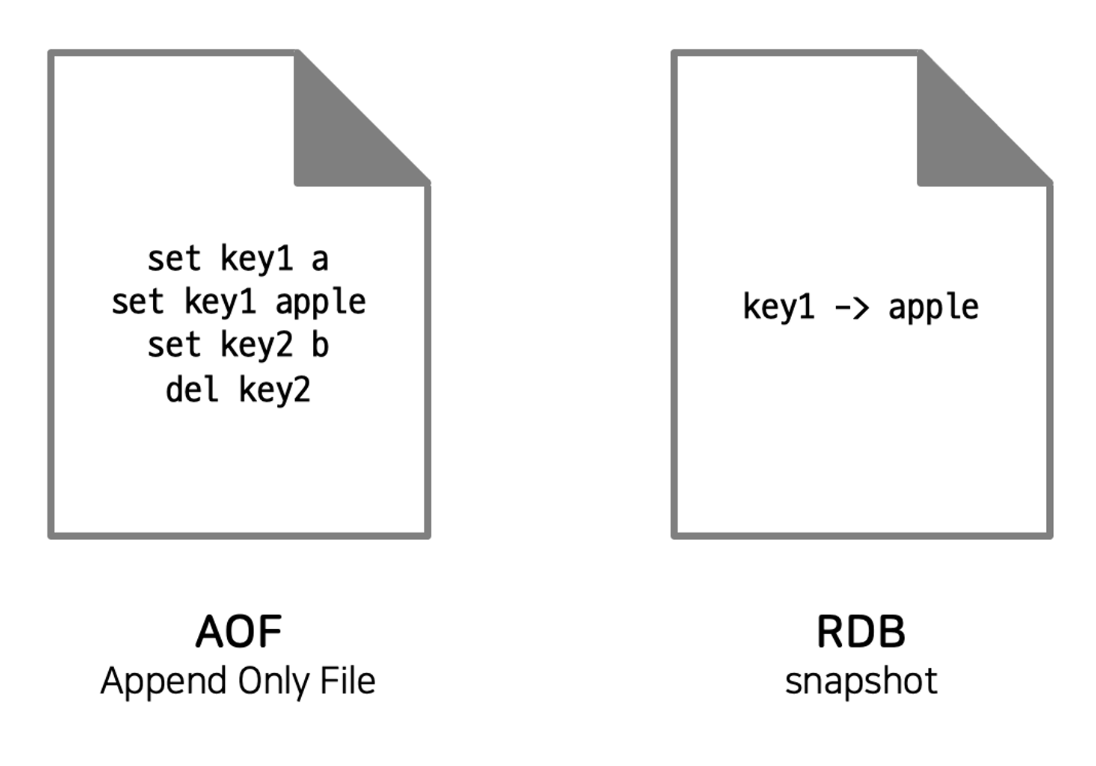
- RDB 방식 - 특정 간격마다 메모리에 있는 데이터 스냅샷을 디스크에 백업 (버저닝 가능)
- AOF 방식 - 명령이 실행될때마다 데이터를 파일에 기록
- persistence 보장 X - 캐싱할 때 사용될 수 있음
차이점
- RDB는 AOF와 다르게 스냅샷 사이의 간격이 있으므로, 스냅샷과 Redis중지 시점 사이 데이터가 유실될 수 있음
- RDB방식은 메모리의 스냅샷을 그대로 로드하여 복구하므로 속도가 빠름
기본 설정
- dump.rdb 파일에 스냅샷 백업
- AOF 기본적으로 활성화
Redis서버 재시작시 스냅샷을 가지고 다시 메모리에 로드함
2023-06-11 21:05:42 1:M 11 Jun 2023 12:05:42.436 * RDB age 6 seconds
2023-06-11 21:05:42 1:M 11 Jun 2023 12:05:42.436 * RDB memory usage when created 8.88 Mb
2023-06-11 21:05:42 1:M 11 Jun 2023 12:05:42.439 # Done loading RDB, keys loaded: 3, keys expired: 0.
2023-06-11 21:05:42 1:M 11 Jun 2023 12:05:42.439 # <search> Skip background reindex scan, redis version contains loaded event.
2023-06-11 21:05:42 1:M 11 Jun 2023 12:05:42.440 * DB loaded from disk: 0.014 seconds
2023-06-11 21:05:42 1:M 11 Jun 2023 12:05:42.440 * Ready to accept connections- 추가 정보
- 관련 설정은 redis의 conf파일에서 지정
- 저장을 blocking방식으로 할지, nonblocking방식으로 할지도 정할 수 있음
- AOF는 너무 커지면 백그라운드에서 자동으로 다시 실행되도록 할 수도 있음
- AOF의 처리 속도 개선을 위해 fsync옵션을 설정하여 sync주기를 조절 가능 - sync 주기 길어지면 RDB의 단점 나타남
key eviction
차지한 메모리가 maxmemory의 한계에 도달하면, 정책에 따라 데이터를 제거해야 함
max memory 기본설정
- 32bit system - 3GB
- 64bit system - 제한 없음
제한을 걸어두지 않고 메모리를 모두 쓰게 되면 스왑 메모리를 사용함 → 성능 저하
memory-policy
- noeviction - maxmemory도달시 데이터 추가 X
- allkeys-lru - 오랫동안 사용하지 않은 데이터 삭제
- allkeys-lfu - 최소 빈도 접근 데이터 삭제
- allkeys-random - 랜덤 삭제
- volatile-lru - 오랫동안 사용하지 않았고 expire설정이 있는 데이터 삭제
등등 8가지의 key eviction 정책 지원
** 대부분의 DB는 만료 시간이 설정된 데이터중 접근한지 가장 오래된 데이터를 제거하는 volatile-lru를 기본 제거 정책으로 택함
Redis 자료구조
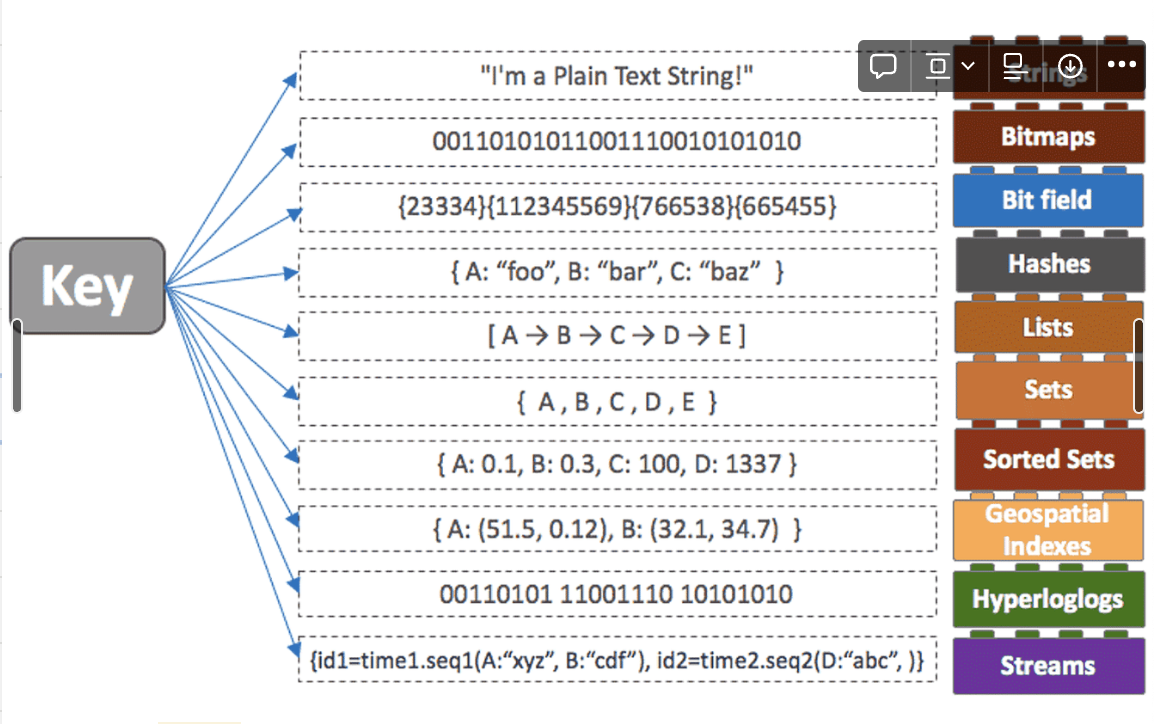
- string - set 커맨드로 저장되는건 모두 기본적으로 string
- hash - 문자열 필드와 해당 필드에 대한 값으로 구성
- 키:값 형태로 개별적으로 접근 가능
- sorted sets - score값을 가지고 그에 따라 정렬
- List
- 트위터는 유저의 타임라인에 보일 게시글 캐싱을 위해 리스트 사용
- key가 있을 때에만 신규트윗을 저장함 - 자주 사용하지 않는 유저는 caching key가 존재하지 않음
- 자주 사용하지 않는 유저를 위해 타임라인을 저장해놓는 불필요한 작업 X
- streams - 로그 저장에 유리
redis > XADD mysteam * sensor0id 1234 temperature 19.8 “163482341307-0”- 메세지의 id는 일반적으로 시간 정보와 시퀀스 번호의 조합으로 자동 생성됨
- id값을 이용해 시간 범위로 검색 가능
- 실제 서버에 로그가 쌓이는 것처럼 append-only로 저장되며 데이터가 변경되지 않음
캐시 목적으로 Redis 사용하기
캐시 읽기 전략
- cache-aside
- read-through
- refresh-ahead
cache-aside
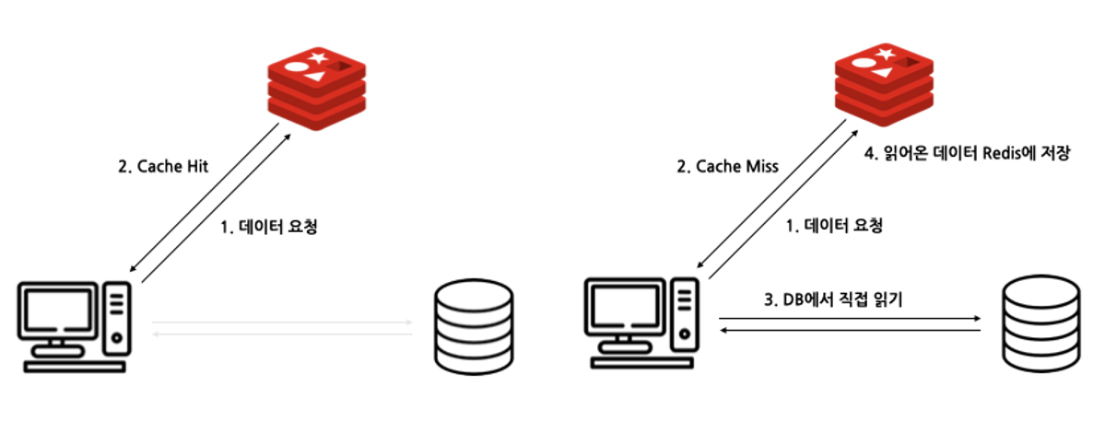
- 캐시 우선 확인, 있으면 캐시에서 읽어옴
- 없으면 DB에 접근해 데이터를 먼저 가져온 뒤에 캐시에 저장
→ 읽는 일이 많을 때 사용하는 전략
→ Redis에 장애가 발생해도 데이터를 가져올 수 있음
→ 처음 요청했을 때는 캐시 스토리지에 아무것도 없음 - 처음부터 데이터를 캐시 저장소에 넣어 두는 방법도 있음
단점
- 캐시 미스 발생시 지연 발생 가능성
- 처음 Redis 접근, 이후 DB 접근, 마지막으로 Redis에 또 데이터를 쓰기 위해서 총 세번 DB접근
- 캐시 불일치 문제
- 일반적으로 cache-aside 전략은 이를 해결하기 위해 다른 전략과 함께 사용됨
read-Through
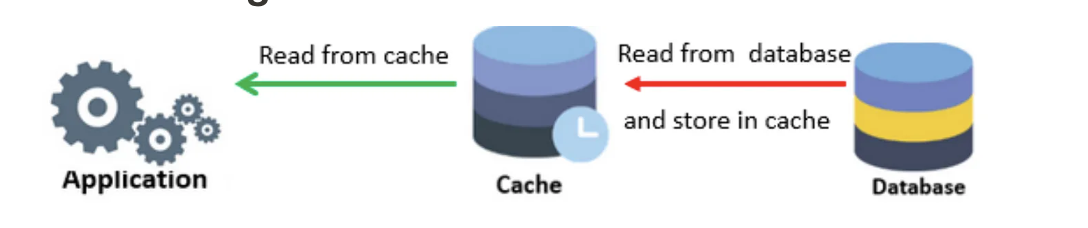
기본적으로 Cache-aside방식과 유사하지만, 데이터베이스에서 데이터를 가져오는 역할을 담당하는 게 애플리케이션이 아닌 캐시라는 점에서 차이가 있음
장점
- 애플리케이션 코드가 단순화됨
- cache-aside는 키가 만료되면 db에 동일한 데이터를 여러 번 요청할 수 있지만, read through는 1개의 쿼리만 데이터베이스로 전송
refresh-ahead
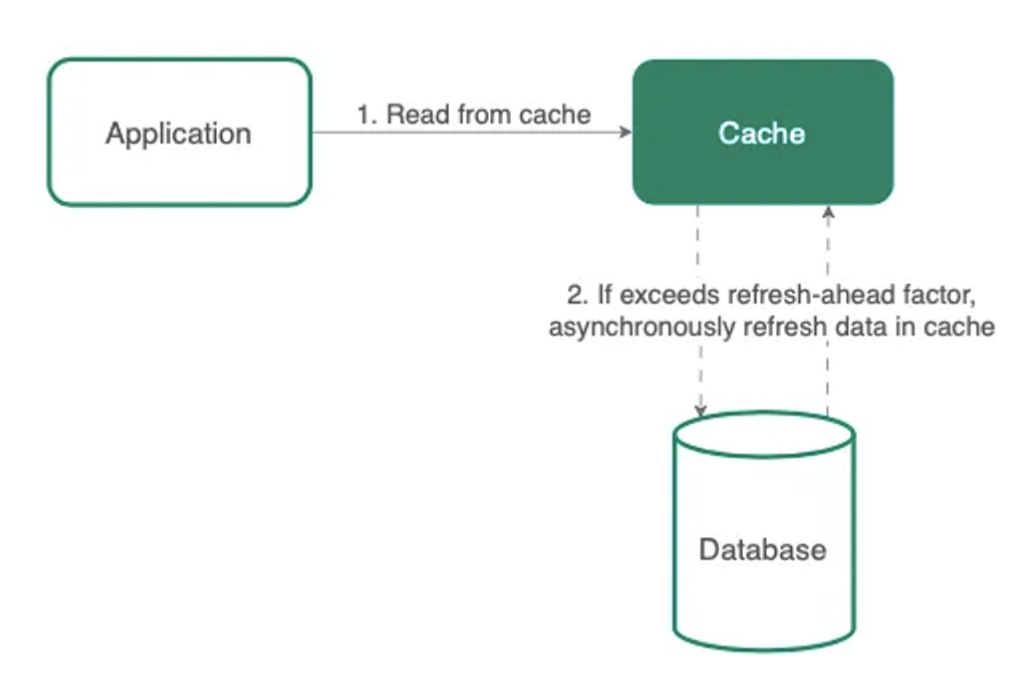
캐시된 데이터는 일정 기간이 지나면 만료됨 → 만료된 키를 요청하면 miss발생, DB에 접근해야 하므로 대기 시간이 길어짐
Refresh-ahead의 경우 가까운 장래에 요청될 것으로 예상되는 데이터에 대해, 데이터가 expired되기 전에 캐시 데이터를 리프레시함
캐시 쓰기 전략
- write-through
- write-back
write-through
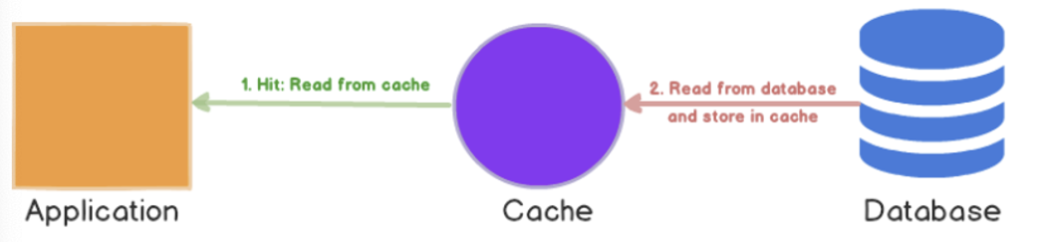
- 데이터가 추가되거나 업데이트할때 캐시를 업데이트한 뒤 데이터베이스에서도 업데이트
장점
- 캐시에 들어있는 데이터는 항상 일관성 유지
단점
- 값을 쓸 때마다 캐시와 데이터베이스에 모두 쓰기 때문에 업데이트와 생성은 항상 2번의 패널티를 가짐 → 쓰기 작업이 많은 경우 딜레이를 유발할 수 있음
write-back
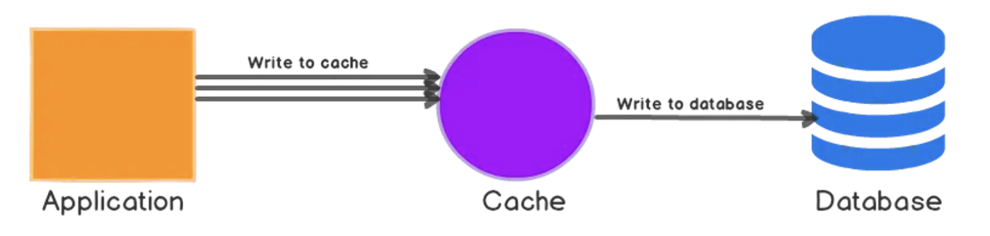
- 기본적으로 write-through와 유사하지만 데이터베이스 쓰기 호출이 비동기식
장점
- 후기입 방식은 쓰기 성능을 향상시키므로 write작업이 다수 발생할 경우 유리
- write-through와 마찬가지로 캐시 일관성 유지
단점
- 비효율적 캐시 사용 - 자주 요청되지 않는 데이터도 캐시에 기록됨 (ttl로 최소화 가능)
write-around
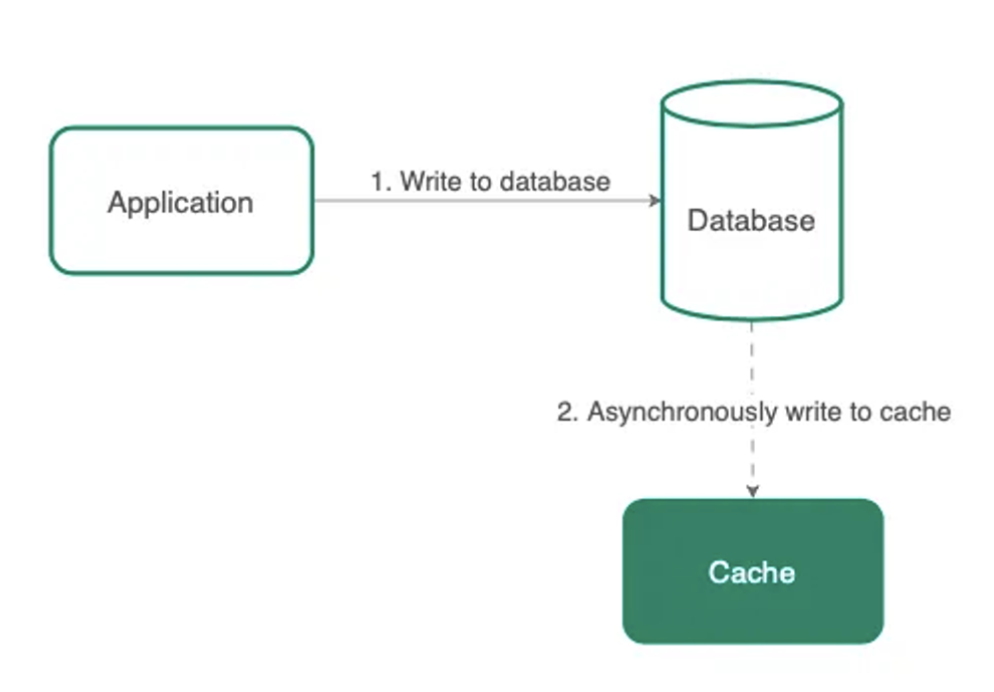
- 먼저 데이터에 대한 명령을 데이터베이스에서 업데이트한 뒤 키 업데이트를 위해 캐시를 비동기적으로 호출
장점
- 데이터가 한 번 작성되고 hit ratio가 낮은 상황에서 유리
- 예) 채팅방 메세지 및 실시간 로그
Redis의 아키텍처
- Replication
- Sentinel
- Cluster
Replication
- HA기능이 없으므로 마스터에 장애 발생시 수동 복구
- 단순 master - replica 구성
Sentinel
- 센티넬 노드가 다른 노드들을 모니터링
- 마스터가 비정상일 때 자동 failover
- 3대 이상의 센티넬 노드가 존재하고, 과반수 이상의 센티넬 노드가 동의해야 failover를 진행함
Cluster
- 데이터가 자동으로 분할되어 저장되는 샤딩 기능 제공
- 모든 노드가 서로를 감시
- 마스터가 비정상일 때 자동 failover
- 최소 3대의 마스터 노드 필요
- 슬롯 단위 데이터 관리
아키텍처 선택 기준
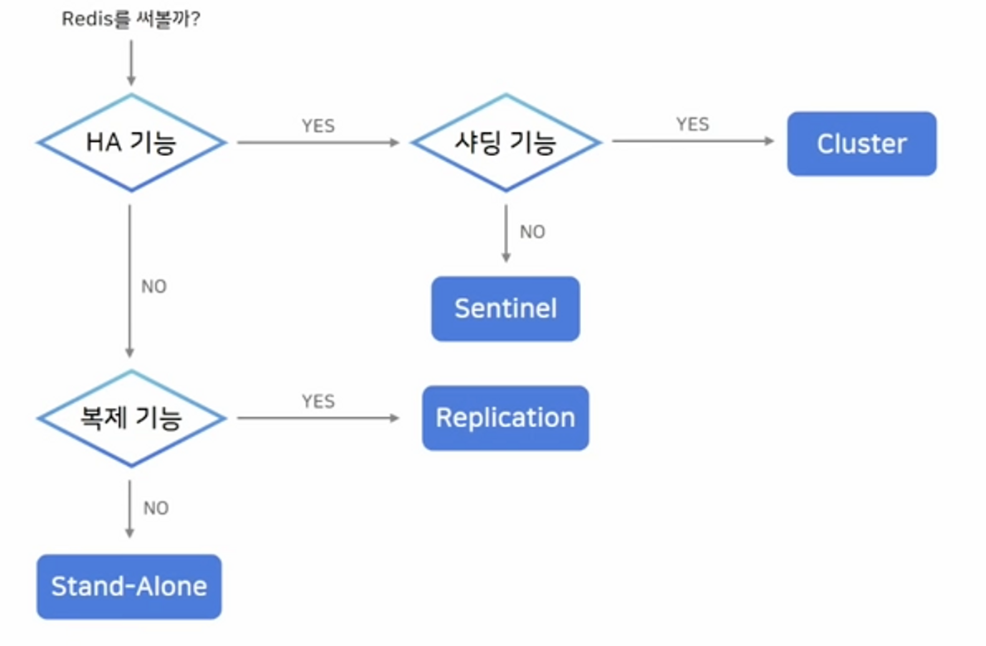
- 자동 failover가 필요하고, Scale-out이 필요하다 → Cluster
- 자동 failover는 필요하지만, Scale-out까지는 필요하지 않다 → Sentinel
- 수동 failover여도 괜찮지만 복제 기능은 그래도 필요하다 → Replication
- 복제 기능도 필요 없고, Scale-out도 필요하지 않다 → Stand-Alone(단일 마스터 노드)
Cluster: Redis 클러스터를 왜 쓸까?
→ 고가용성, 자동 failover 및 샤딩
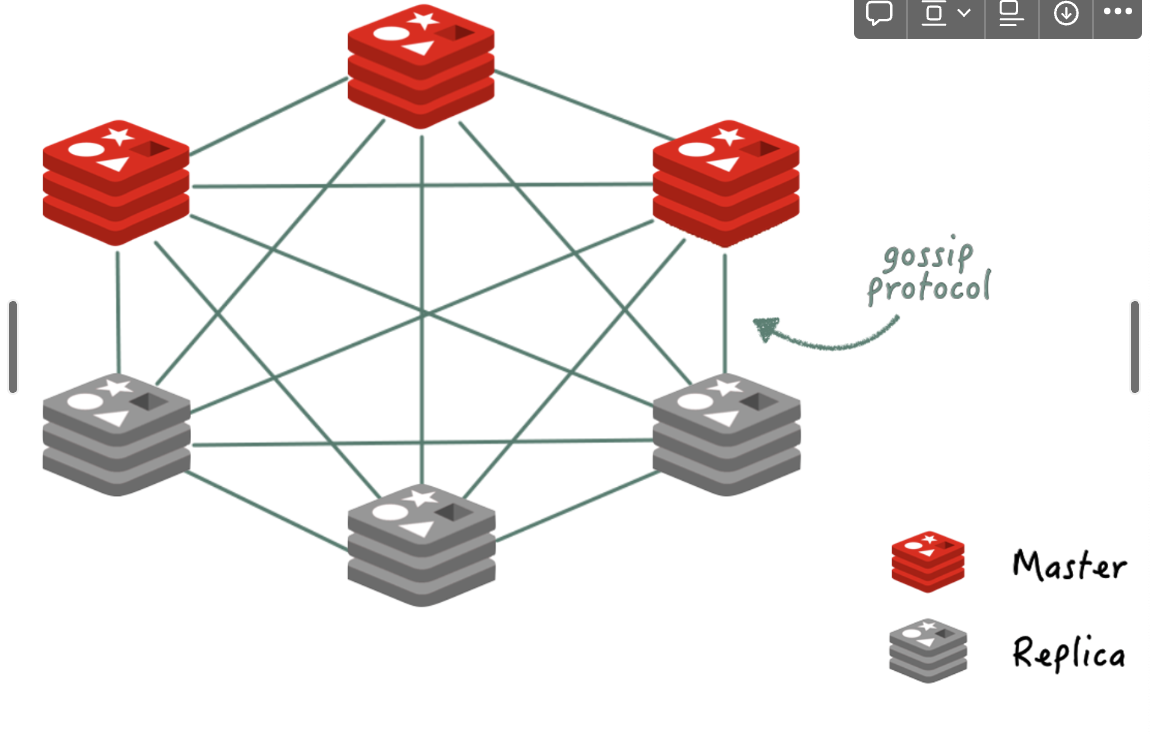
Redis Cluster 특징
- 마스터는 무조건 3개 이상, 레플리카는 0개 이상
- Sentinel과 다르게 모든 노드가 서로 연결된 Mesh 구조
- 클라이언트에서 Redis서버로 연결하기 위한 포트 번호에 10000을 더한 포트도 열어둠
- 구성 정보 및 장애 여부를 전파
- Sentinel아키텍처와 다르게 가십 프로토콜로 서로가 서로를 모니터링하는 방식
- 애플리케이션이 클러스터의 노드 중 하나라도 연결되면 클러스터의 전체 상태 정보를 확인할 수 있음
- 각 노드는 전체 키스페이스의 서브셋을 가짐 (샤딩)
어떤 데이터가 어떤 노드로 갈지는 어떻게 정하지?
- master 1, 2, 3중에 어디로 갈지 결정해야 함
- 단순히 mod연산으로 데이터를 노드에 할당할 경우
hash(0) mod n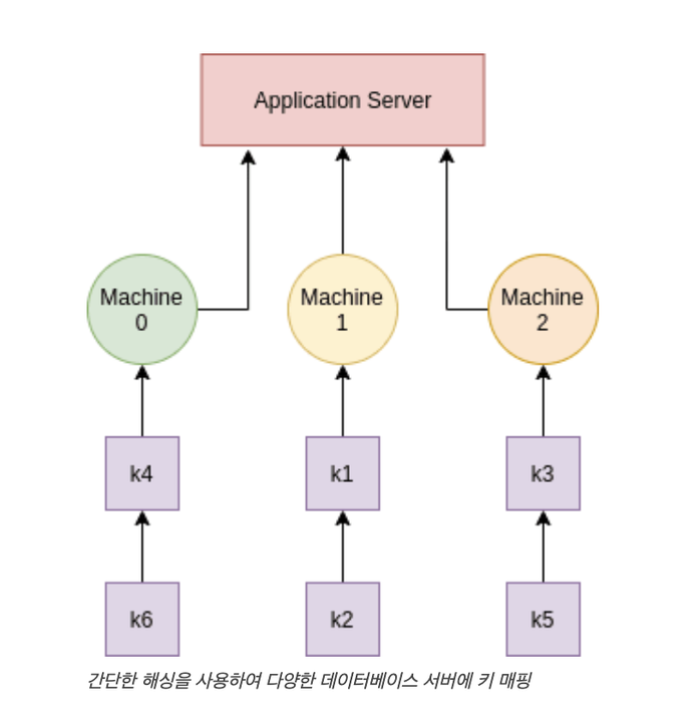
(좌) 노드 추가 전, (우) 노드 추가 후
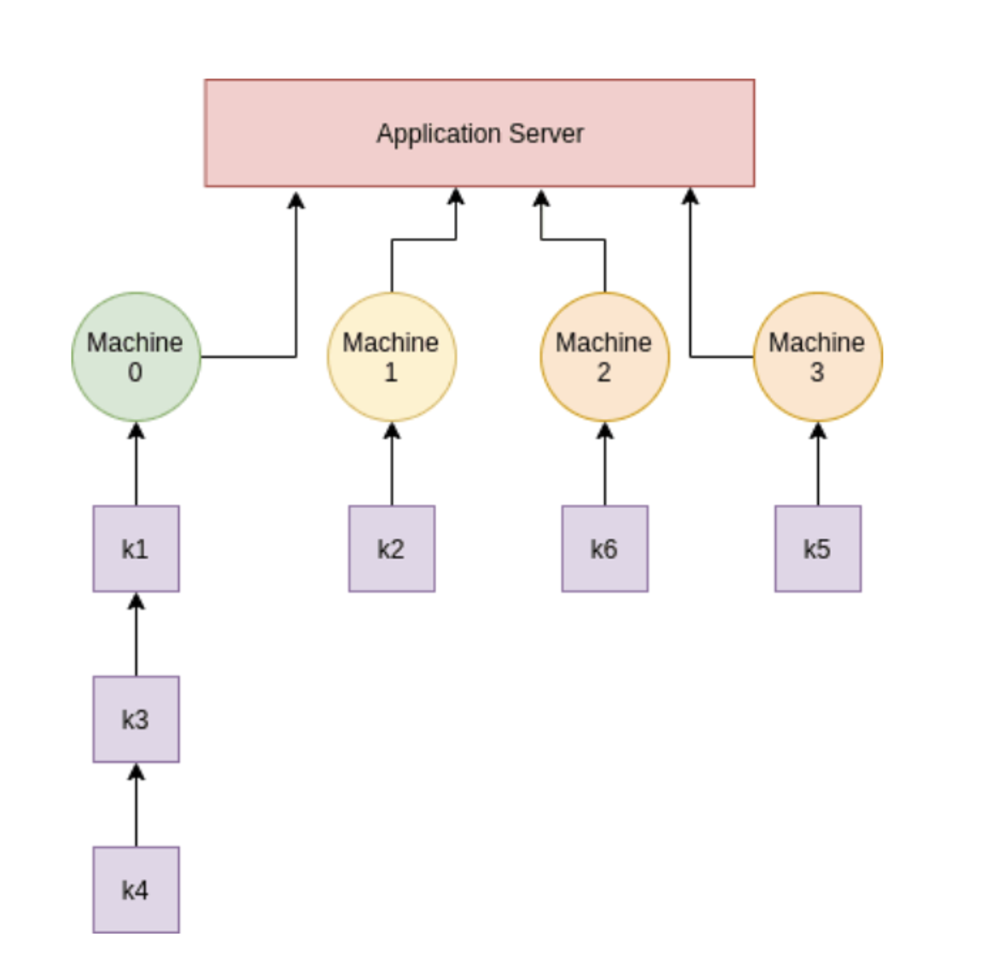
- 노드가 추가될 경우 각 키의 서버 번호를 찾기 위해 모든 해시를 다시 계산
- 다량의 데이터 이동 발생
- 서버 하나 추가/삭제할때마다 계속 리샤딩 → 장애에 취약
해시 슬롯
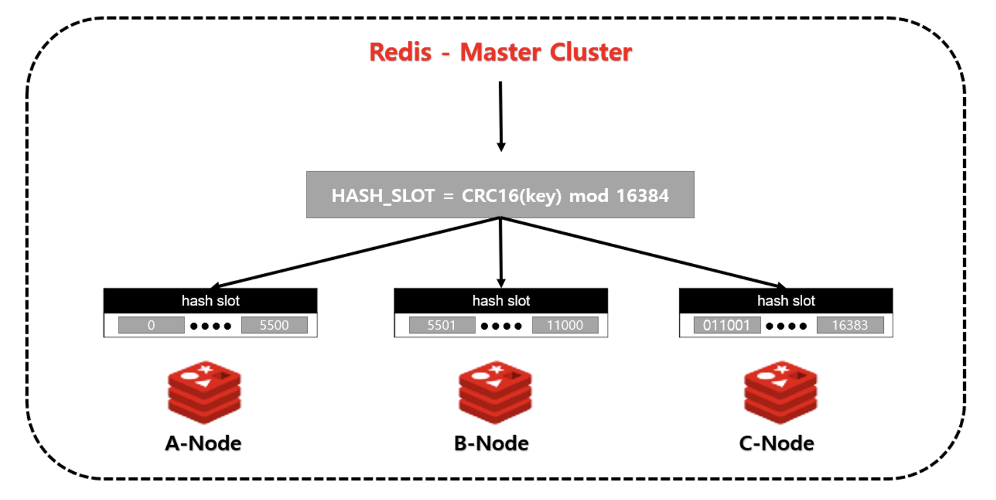
- Redis Cluster는 hash slot 알고리즘을 사용하여 데이터를 분산 저장함
HASH_SLOT = CRC16(key) mod 16384 - 각 노드는 총 16384개의 해시 슬롯을 나눠 가짐
- 데이터의 키 값을 해시 함수로 넘긴 후 해시 슬롯 값 계산 → 데이터가 들어갈 노드 결정
- 기본적으로 클러스터 내의 각 노드에 일정하게 배분 (변경 가능)
- 노드를 추가하거나 제거해도 해시 슬롯 범위가 유지되므로 데이터 이동이 최소화됨 예)
-
노드 A에는 0~5500까지의 해시 슬롯 존재
-
노드 B에는 5501~11000까지의 해시 슬롯 존재
-
노드 C에는 011001~16383까지의 해시 슬롯 존재
→ aaa라는 키를 저장한다면
CRC16("aaa") mod 16384를 수행하고, 그 값이 1000이라고 할 때1000은 0 ~ 5460 범위에 속하므로 Redis#1에 저장된다.
만약 aaa라는 키에 해당하는 데이터가 1번 노드에 저장되어 있는데 2번 노드로 요청한다면?
→ MOVED 에러 발생, Redis 클라이언트 라이브러리에서는 자동으로 리다이렉트되도록 지원하므로 어플리케이션 레벨에서는 개발자가 클러스터를 신경 쓰지 않아도 됨
$ redis-cli -p 6302 127.0.0.1:6302> keys * 1) "key_02" 127.0.0.1:6302> get key_02 "value_02" 127.0.0.1:6302> get key_01 (error) MOVED 1579 127.0.0.1:6400
-
슬레이브 (레플리카)
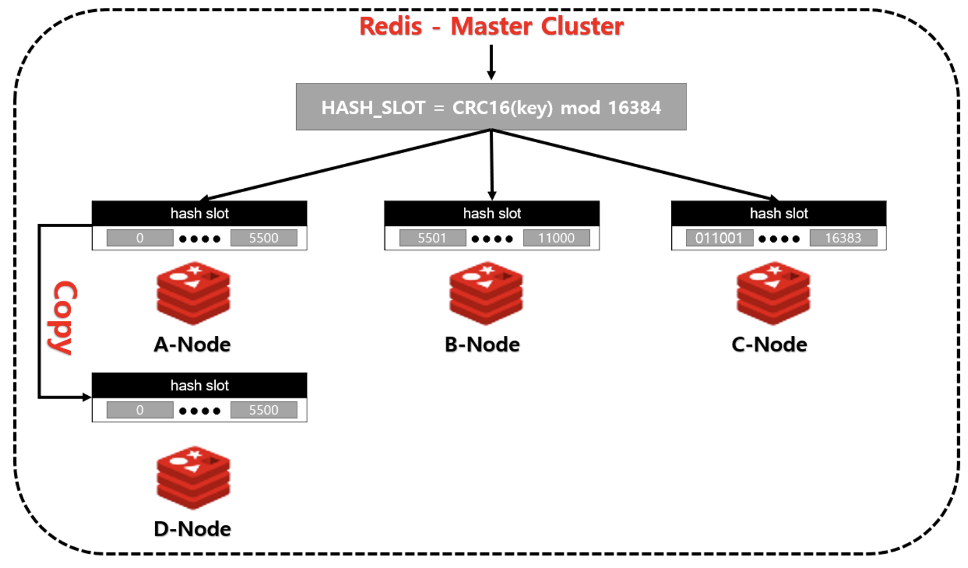
- 클라이언트에서 slave노드에 요청하면 자동으로 master 노드의 위치를 알려주어 다시 요청 (Redis 인터페이스 라이브러리에서 지원)
- 마스터 노드가 죽으면 슬레이브중 하나가 마스터 노드가 됨
- 복제 연결이 되어있는 동안 마스터 노드 데이터는 실시간으로 레플리카 노드에 복사됨
- 데이터 복제는 비동기 방식으로 이루어짐
Failover
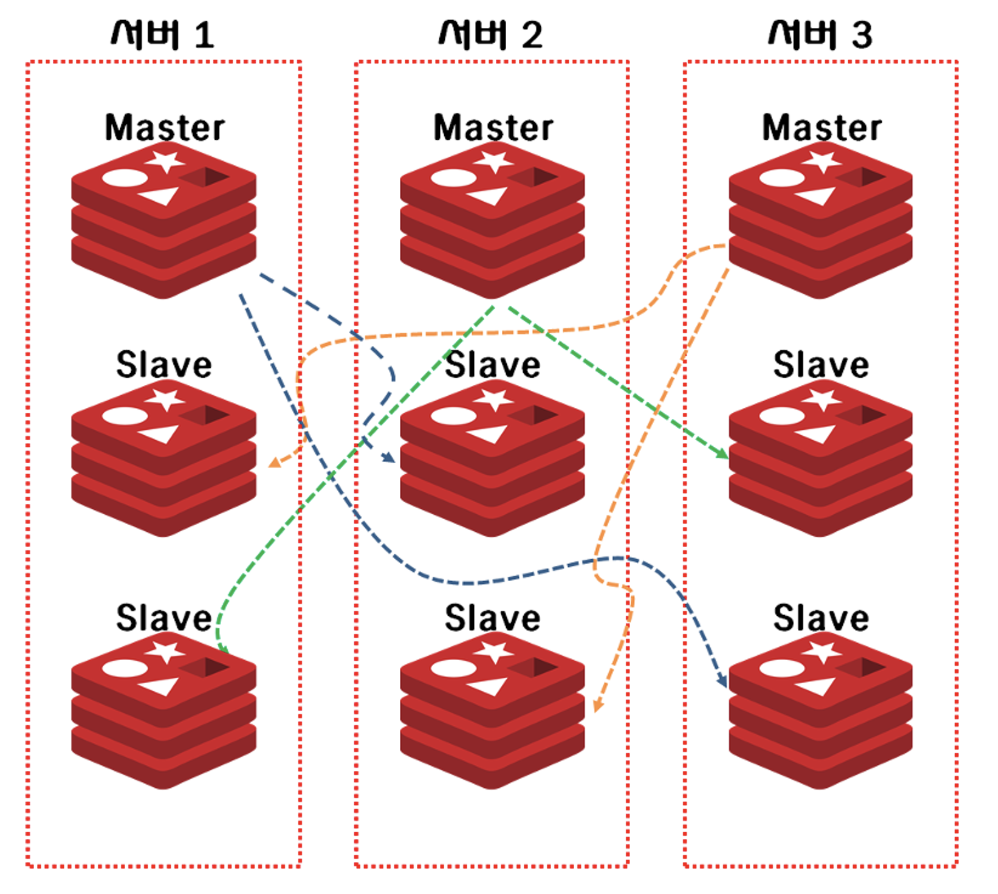
- master노드에 문제가 생겨 더 이상 통신이 불가능한 경우 → 자동으로 replica노드 중 하나가 master가 되어 작업을 계속함
- failover발생시에는 일시적으로 데이터에 접근 불가
- 복제는 데이터 삽입시에 바로 실행되므로, 일반적으로 failover프로세스는 빠르게 완료됨
- 사용자에게는 미비한 영향
failover 플로우
- master노드의 장애가 감지되면 failover가 트리거됨
- slave노드 중 하나를 새로운 마스터 후보로 정함
- 다른 slave노드들의 과반수가 승인하면 실제로 master로 승격
- 클라이언트는 기존 master에 대한 연결을 해제하고 새로운 master의 주소로 다시 연결 (라이브러리에서 지원)
- 새로운 master를 기준으로 클러스터 구성 업데이트
캐시 설계시 고려할 점
- 시스템이 읽기 작업 위주인지, 쓰기 작업 위주인지
- 반환되는 데이터는 항상 고유한지
- 어떤 종류의 데이터를 저장할지
- 높은 처리량을 요구하는지
…
Redis는 싱글스레드
- 한 사용자가 오래 걸리는 커맨드 실행 → 나머지 모든 요청은 대기하게 됨
- 한 번에 하나의 명령만 수행 가능
- keys * (모든 키 조회)를 실행하거나, key에 지나치게 많은 데이터가 들어 있는 상태에서 del(삭제) 수행하는 경우 장애의 원인이 될 수 있음
TIP
- keys * → scan으로 대체
- KEY명령어는 Redis가 모든 키를 스캔하고 일치하는 키를 찾음 → 키 공간이 클 경우 성능 문제를 야기할 수 있음
- SCAN기반의 전략은 키 공간을 작은 단위로 나누어 찾기 떄문에 KEYS보다 성능이 우수하며, 대규모 공간에서도 효율적으로 동작
- del → unlink로 대체 (백그라운드로 삭제)
- MAXMEMORY-POLICY를 ALLKEYS-LRU로 설정
- 메모리에 expire설정값이 없는 키만 남을 경우를 대비
- 데이터가 가득 참으로 인한 장애 가능성 없음
- O(N) 명령 조심!
- Monitora명령을 통해 특정 패턴을 파악할 때, monitor 자체도 서버에 부하를 줄 수 있다
모니터링하기
- Redis INFO 커맨드를 사용한 정보
- RSS - 물리메모리를 얼마나 쓰고 있냐
- maxmemory를 설정하도 더 사용할 가능성이 큼 → Swap사용시 성능저하
- Used Memory - Redis가 생각하는 자기가 쓰고 있는 메모리
- Connection 수 - 치솟다가 툭 떨어졌다 치솟다가 하는 방식이면 뭔가 문제가 있을 수 있음
- Redis는 싱글스레드이므로 연결이 필요할 때마다 연결을 맺고 끊고 하는 방식은 성능을 급격히 저하시킴
- 초당 처리 요청 수 - CPU의 영향을 받음
- RSS - 물리메모리를 얼마나 쓰고 있냐
Redis.conf 권장 설정
- maxclient 50000
- 넉넉하게 설정하라는 의미
- RDB/AOF 설정 off
- 성능상 유리
- 실제 서비스할땐 다 off함
- 꼭 필요하다 싶으면 Replica에만 설정
- 특정 커맨드 disable
- KEYS disable (ElasticCache는 이미 conf바꾸거나 keys같은거 막아둠)
- 전체 장애의 90퍼 이상이 KEYS와 SAVE설정을 사용하여 발생
- save설정은 1분안에 키가 만개가 바뀜 -
- 실제 서비스에서는 1분만에 만개 쓰는 경우가많음 - 디스크에 1분마다 30기가씩 쓴다고 생각하면 망함
추가
Redis의 트랜잭션
- Redis는 트랜잭션을 지원함
- 롤백을 지원하지 않음
- MULTI명령어를 사용해서 트랜잭션을 시작하고 GET, SET등의 명령을 실행하는데, 이 때 명령어는 대기열에 들어가고 실제로 실행되지 않음
- EXEC 입력할때까지 실제로 실행되지 않기 때문에 트랜잭션이 완전히 실행될 때까지 데이터베이스에 아무 것도 기록되지 않음 → 롤백과 비슷한 역할을 하지만, 롤백으로 간주되지 않음
- DISCARD를 통해 대기 중인 명령을 버릴 수 있음
Redis성능에 영향을 미치는 요인
- 네트워크 대역폭 및 홉 수 - CPU보다 큰 영향을 미침
- VM의 경우, 더 느림
- RAM속도와 메모리 대역폭 → 크게 좌우하지 않음
- CPU - 매우 중요. 단일 스레드인 Redis는 캐시가 많고 코어가 많지 않은 CPU를 선호함
- 이더넷 네트워크를 사용하여 redis에 액세스할 경우, 이더넷 패킷 크기 미만으로 유지될 때 효율적
- 클라이언트 연결 수 - 30000개의 연결은 100개의 연결에 비해 처리량이 절반으로 감소
파이프라이닝 지원
- 레디스는 단일 스레드이므로 락, 동기화 메커니즘을 처리할 필요가 없음
- 파이프라이닝 지원 - 개별 명령에 대한 응답을 기다리지 않고 한 번에 여러 명령을 내림으로서 성능을 향상
- 응답을 기다리지 않고 서버에 여러 명령을 보내되, 최종적으로 단일 단계에서 응답을 읽을 수 있음
- 클라이언트가 파이프라이닝으로 명령을 보내는 동안 서버는 메모리를 사용하여 응답을 대기열에 강제 배치
- 응답을 대기시키는데 필요한 메모리도 고려해야 함
- 파이프라이닝 하지 않고 각 명령을 제공하면, 소켓i/o관점에서 비용이 많이 들음 - 만약 서버가 초당 10000개의 요청을 처리할 수 있다고 쳐도 RTT 시간이 250밀리초면 초당 4개의 요청밖에 처리하지 못함
- 소켓 write()는 속도 저하를 일으킬 수 있음 → 파이프라이닝을 하면 일반적으로 단일 read()및 단일 write()호출로 여러 응답을 전달하므로 초당 수행되는 총 쿼리수가 훨씬 올라감
Memory Fragmentation
- 실제로 저장되는 메모리는 3GB여도 5GB의 자리를 차지할 수 있음
- 해제된 메모리의 공간이 다음 데이터를 저장하기에 충분하지 않으면 그 자리가 비워짐
- INFO로 확인 가능
- 4.0이후부터는 메모리 정리 메커니즘 제공
- Redis는 단일스레드이므로, 메모리 정리하는동안 요청 처리가 불가능 → 성능 손실
참고자료
redisinsignt로 redis cluster구성 관리
https://velog.io/@ma2sql/Redis-Cluster-Specification-1
Race Condition, Memory Fragmentation …
NHN클라우드 Redis세션 (data type사용 참고)
우아한테크세미나 우아한레디스 (안정 해시 설계 참고)
https://devaraj-durairaj.medium.com/caching-data-access-strategies-ecstasy-agony-2474cf031fa0
