ByteTrack: Multi-Object Tracking by Associating Every Detection Box 논문 리뷰

https://github.com/ifzhang/ByteTrack
1. Abstract
다중 객체 추적(Multi-object tracking, MOT)은 비디오에서 객체의 bounding box와 identity를 추정하는 것을 목표로 합니다.
대부분의 방법들은 일정 점수 이상인 detection box 를 연결하여 객체의 identities를 추적합니다. 임계값에 따라 낮은 detection score를 가진 객체(예: 가려진 객체)는 그냥 버려지고, 이는 실제 객체의 누락 혹은 인식하고 있던 궤도에서 떨어져 나가게 됩니다.
이러한 문제를 해결하기 위해 나온 단순하고 효과적인 association method가 Byte Track 입니다. 높은 detection score만 사용하는 것이 아니라 거의 모든 detection box를 연결하여 추적합니다. 낮은 점수의 detection box의 경우, tracklet과의 유사성을 활용하여 실제 객체를 복구하고 backgroud detection을 필터링하여 배경을 제외 시킵니다. 그 결과, MOT task 에서 **Byte Track은 **좋은 성능을 이루어 냈습니다.
2. Introduction
기존의 문제점
기존 대부분의 MOT method는 점수가 낮은 detection box를 제거하여 true positive / false positive trade-off를 다룹니다. 여기서 가려진 객체들을 탐지하지 못한다는 단점이 존재합니다.
ByteTrack을 통한 해결방안
ByteTrack에서는 이를 해결하기 위해, 낮은 confidence detection box들을 제거하는 대신에 detection box를 tracklet과 연결해 모든 detection box를 추적할 수 있도록 했습니다.
즉, 낮은 score의 detection box는 tracklet에 매칭되어 객체가 올바르게 복구되고, backgroud box는 매칭된 tracklet이 없기 때문에 제거됩니다.
여기서 우리는 높은 점수부터 낮은 점수까지 검출된 모든 상자를 활용하기 위해 tracklet에 기본 단위 byte로 명명되는 효과적인 association 방법을 제시했습니다. 해당 방식은 임계값(예: 0.35) 이상의 검출 상자를 모션 유사성 또는 외관 유사성 기반으로 tracklets에 매칭 시킵니다. 이후, 유사하게 Kalman filter를 사용하여 tracklets의 위치를 새 프레임에서 예측합니다.
유사성 계산 방법
IoU 또는 Re-ID feature distance로 계산
- IOU
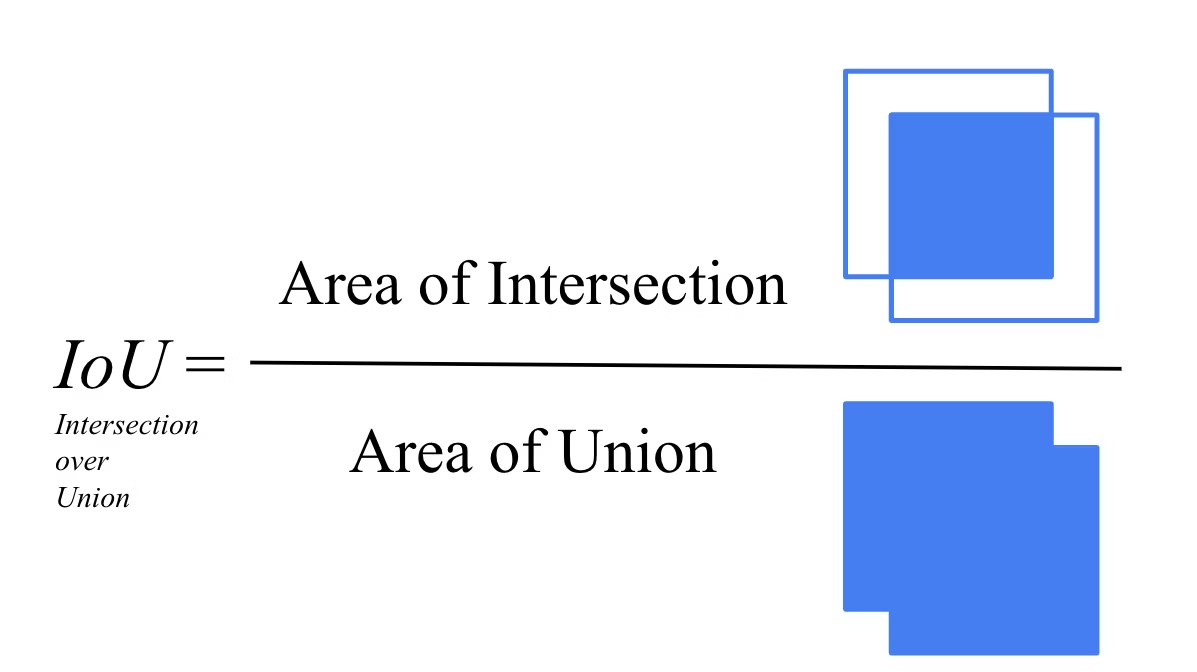
물체 검출 분야에서 2개의 영역이 얼마나 겹쳐 있는 가를 표시하는 지표 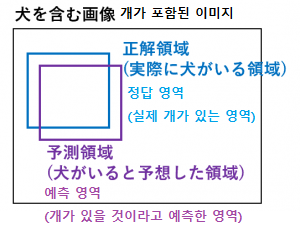
이미지와 정답 라벨(어느 영역에 어떤 것이 있는가에 대한 정보) 가 전달 될 때, 이것을 얼마나 정확하게 검출하는 가에 대한 문제입니다.
정답영역과 예측 영역이 겹쳐진 부분이 클 수록 IOU 값이 커집니다. 예측 영역이 어긋나거나, 정답 영역에서도 너무 작은 영역이 겹치거나 정답 영역에 포함되어 있어도 너무 크면 IOU 값이 낮아집니다.
즉, IOU 값이 클수록 물체가 잘 검출되고 있다고 판단할 수 있습니다.-
Re-ID feature distance
(= Re-ID (Re-Identification) feature distance)
사람이나 물체 등을 다른 시간이나 장소에서 재식별하는 기술입니다.
방식은 딥러닝 기반의 모델을 사용해 개체의 특징을 추출해서 특징 벡터 간의 거리를 계산합니다.
특징 벡터는 일반적으로 다차원 벡터로 표현되며, 벡터 간의 거리를 계산하여 개체 간의 유사성을 측정합니다. Re-ID feature distance는 이러한 거리 측정 방법을 의미합니다. 주로 사용되는 거리 측정 방법으로는 유클리디안 거리(Euclidean distance)와 코사인 유사도(Cosine similarity) 등이 있습니다.
고성능인 detector 인 YOLOX를 BYTE를 연관시켜서 ‘ByteTrack’ 이라는 효율적이고 간결한 추적기를 만들었습니다.
3. Related Work
3-1) Object Detection in MOT
MOT 모델의 구조는 일반적으로 Detector와 Tracker로 2가지로 구성됩니다.
Tracking by detection
tracking by detection은 앞선 SORT 논문에서 detection의 성능이 좋아지면 tracking의 성능 또한 함께 좋아진다는 것을 말합니다.
해당 방법론은 tracking을 위해서 frame 단위의 이미지에서 detector를 통해 detection box를 검출해내고 tracking알고리즘을 통해 프레임들을 연결해주는 방식을 의미합니다.
객체 감지 기술은 빠르게 발전하고 있으며, 이제는 더 강력한 detector 를 사용하여 더 높은 추적 성능을 얻기 위한 방법이 많이 사용되고 있습니다.
추천하는 성능 좋은 detector
- RetinaNet : 단일 단계 객체 검출기
- CenterNet
- YOLO : 시리즈 검출기
만약, 동영상의 sequence에서 객체가 가려지거나 블러가 발생하면, 비디오 객체 검출 에서 말한것 처럼 매우 낮은 score의 detection 이 증가하게 된다는 단점이 존재합니다.
따라서 이전 프레임의 정보를 활용하여 비디오 detection의 성능을 향상 시켜 해당 문제점을 극복하고자 합니다.
Detection by tracking
traking방식을 도입한 detection box 탐지는 정확도 향상에 도움을 줍니다.
객체 추적 방식 혹은 Kalman filter를 사용하여 연결된 다음 프레임에서 tracklets의 위치를 예측하고 예측된 box와 dectection box를 융합하여 탐지 결과를 향상시킵니다.
다른 방법으로는 이전 프레임의 추적된 상자를 활용하여 다음 프레임의 형상 표현을 향상시킵니다. 최근에는 프레임 간 상자를 전파하는 Transformer-based detectors 들이 나오기도 합니다. 대부분의 MOT방법은 높은 점수를 가진 detection box를 threshold으로 유지하고 있습니다. 따라서 가려진 객체들을 잘 탐지하지 못합니다. 따라서 본 논문에서는 ByteTrack을 사용하여 모든 detection box를 유지하며 연결될 수 있도록 도와줍니다.
3-2) Data Association
Data asssociation 부분은 multi-object tracking 기술에서의 핵심입니다.
이는 tracklets (tracklets는 객체 주적 경로에 관한 정보를 의미합니다) 과 detection box간의 유사도를 기반으로 연결하는 과정을 거치게 됩니다.
이때, 데이터 간의 유사도를 판단하여 매칭시키게 됩니다.
유사도
- appearance
- 외형을 보고 쫓아가는 것을 말합니다. 이는 우리 시야내에 있는 물체가 굉장히 빨리 움직이거나 우리가 물체를 발견한 시점 사이에 공백이 긴 경우 효과적입니다.
- BYTE에서는 detector에 의해 물체를 검출하는 것이 appearance 유사도를 이용하는 것입니다.
- motion model
- motion model을 이용한 매칭 기법은 kalman filter가 대표적입니다.
4. BYTE
이 논문은 핵심은 BYTE라는 association method를 사용한다는 점입니다.
해당 방식은 detector에서 제안한 detection boxes를 association 하는 방식을 설명합니다.

먼저 video sequence에서 프레임 단위로 분리하여 진행하게 됩니다.
- Det에 의해 검출된 detection box들을 모두 저장합니다.
- threshold 값보다 높은 detection box들은 D_high 에 저장하고 , 낮은 score를 가진 값들은 D_low에 나누어 저장합니다.
- 이전 프레임에서의 tracklet과 KalmanFilter를 이용해서 현재 프레임의 prediction box를 만들어서 t에 저장합니다.
- 첫번째 association 과정입니다. tracklet과 D_high를 IOU distance (similarity 계산) 기반으로 association을 진행해줍니다. (first assocaiton)
- 남은 값들 ( 매칭 되지 못한 값들 )에서 detection box는 D_remain에, tracklet은 T_remain에 저장해줍니다.
- T_remain 과 D_low를 IOU distance(similarity 계산)를 기반으로 association를 진행해줍니다.(second association)
- step 6에서 매칭되지 못한 track들은 삭제 해줍니다.
- step 6에서 매칭되지 못한 detection boxes 중 thershhld 보다 confidence가 높으면 새로운 tracklet으로 추가해준다.
각 개별 프레임의 출력은 현재 프레임에서 추적 대상 T의 bounding box 와 identities 들을 얻을 수 있습니다.
5. Conclusion
해당 방법은 Tracking 기법에서 중요한 모든 지표에서 좋은 발전을 보였습니다.
ByteTrack ID Switching 현상이 절반 가까이 줄이고 MOTA 성능까지 올렸습니다.
특히, ByteTrack은 낮은 score를 가진 가려진 객체를 탐지하는데 강건합니다.
해당 방법은 고전적 기법인 Kalman Filter와 Hungarian Algorithm을 이용하기 때문에 SORT에서 발생하는 occlusion 문제를 정확하게 파악하면서도 간단한 방식으로 성능 향상을 보였다는 장점이 있습니다.
