deep learning에서 골치 아픈 문제 중 하나는 vanishing/exploding gradient 문제이다.
이 문제는 역전파 과정에서 입력층으로 갈 수록 기울기(gradient)가 점차적으로 작아져 기울기 소실(gradient vanishing)이 발생하거나 엄청 커져 기울기 폭주(gradient exploding)를 일으키는 문제이다.
위 문제가 일어나지 않게하고 안정화하여 학습 속도를 가속화하려고 사용하는게 정규화(normalization)이다.
오늘은 여러 정규화 중 배치 정규화(batch normalization)에 대해 알아보겠다.
역전파(BackPropagation)
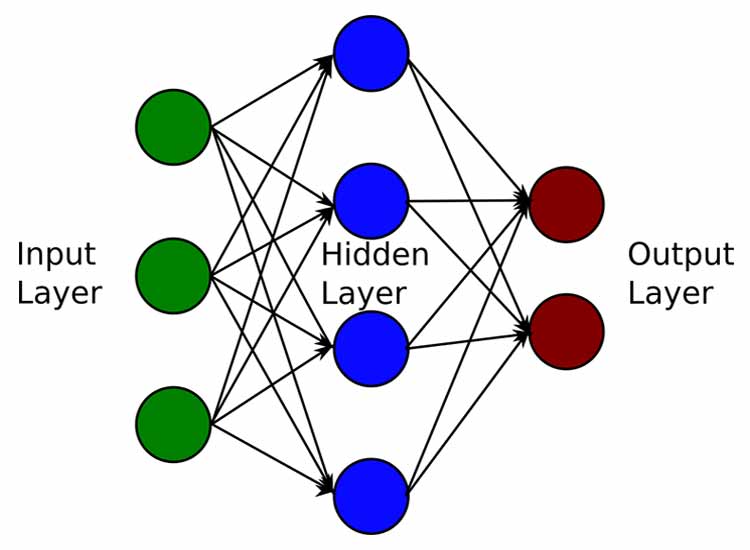
역전파 과정을 거치는 이유는 결과값을 토대로 뒤에서 부터 weight와 bias를 업데이트하여 loss function을 낮추기 위해서이다.
순전파는 입력층에서 출력층으로 향한다면 역전파는 출력층에서 입력층으로 반대로 계산하면서 가중치를 업데이트 해간다.
이 과정에서 레이어(Layer)가 많을 경우 기울기 소실(Gradient Vanishing)과 폭주(Exploding) 문제가 생긴다.
기울기 소실(Gradient Vanishing)
심층신경망에서 가중치를 Back Propagation으로 학습시키는 과정에서 곡선의 기울기가 0이 되어 더 이상 학습할 수 없는 문제인데 이 문제의 원인은 시그모이드 함수이다.
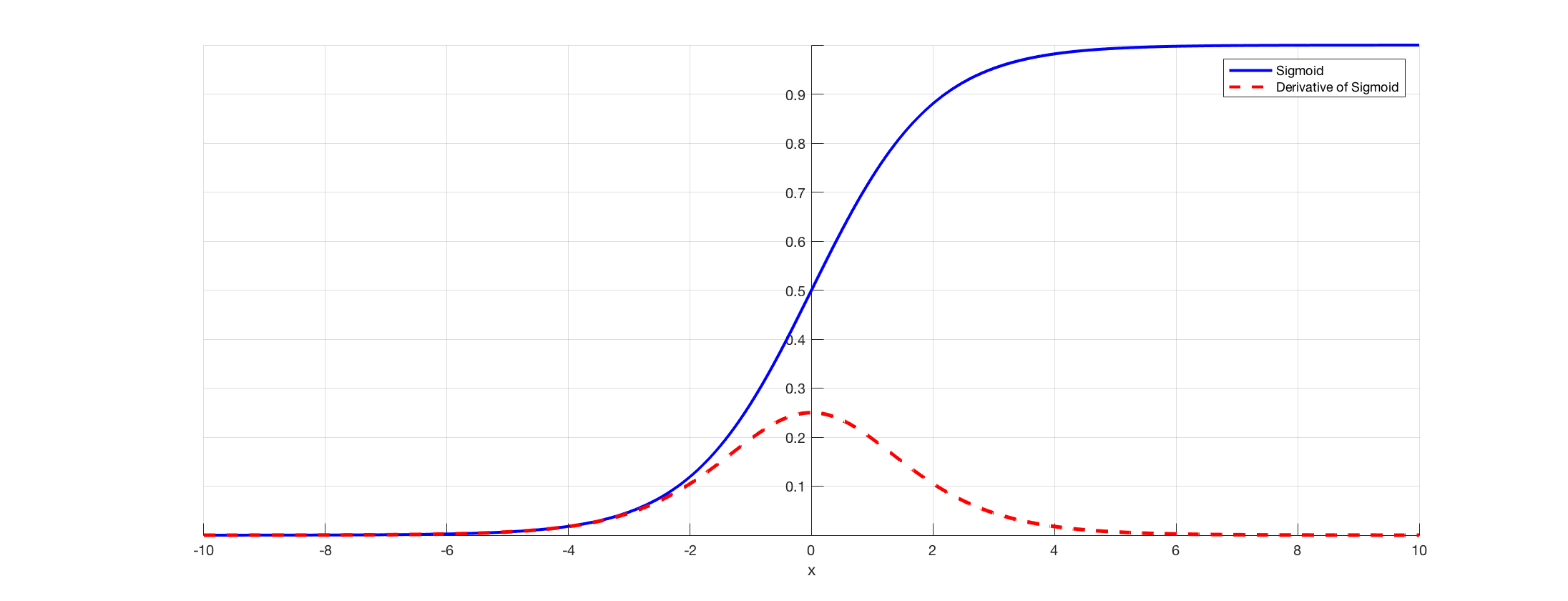 시그모이드 함수는 0~1값을 표현 하지만 시그모이드(비선형 포화함수) 미분값은 0~0.25 사이의 값만 표현이 가능하기에 역전파로 결과값에 대한 가중치 계산 시 전달되는 값이 1/4 감소되는 현상이 발생합니다. 3번 이상 미분계산 시 0에 가까운 값이되어 학습되지 않습니다.
시그모이드 함수는 0~1값을 표현 하지만 시그모이드(비선형 포화함수) 미분값은 0~0.25 사이의 값만 표현이 가능하기에 역전파로 결과값에 대한 가중치 계산 시 전달되는 값이 1/4 감소되는 현상이 발생합니다. 3번 이상 미분계산 시 0에 가까운 값이되어 학습되지 않습니다.
(이 문제를 해결하기 위해 ReLU를 사용하게 되었는데 이 마저도 근본적인 해결방법이 아니다.)
기울기 폭주(Gradient Exploding)
Gradient Vanishing의 반대의 경우이다. 기울기가 점차 커져 가중치들이 비정상적인 값이 되면서 발산되기도 하는 현상인데 RNN에서 발생할 수 있다.
(이건 자료가 많이 없네요...)
Normalization(정규화)
 출처: https://link.springer.com/chapter/10.1007/978-3-319-33383-0_1
출처: https://link.springer.com/chapter/10.1007/978-3-319-33383-0_1
정규화는 값의 범위의 차이를 왜곡시키지 않고 dataset을 공통 스케일로 변경하는 것이다.
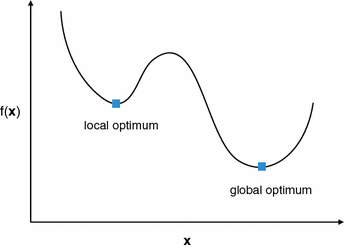
정규화를 사용하는 이유는 학습을 더 빨리 하기 위함과 Local otimum 문제에 빠지는 가능성을 줄이기 위해서 사용한다.
Batch Normalization(배치 정규화)
Batch Normalization은 비선형 포화함수 ex) sigmoid, hyper_tangent 등을 사용하면 미분값이 0에 가까워져 역전파 학습이 어려워지는 문제를 해결하기 위해 나왔다.
Batch Normalization은 일반 Normalization과 다르게 두 개의 파라미터 gamma와 beta 값을 가진다.
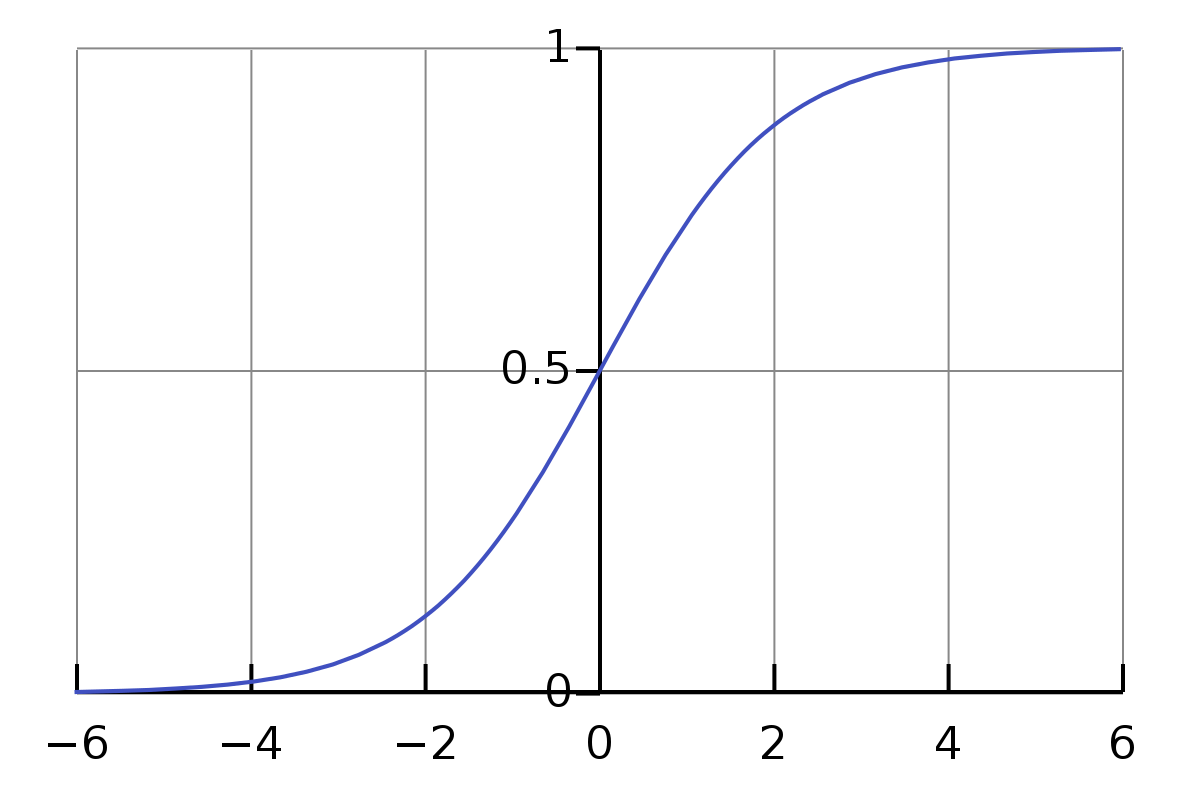 출처: https://en.wikipedia.org/wiki/Sigmoid_function
출처: https://en.wikipedia.org/wiki/Sigmoid_function
이 값이 존재하는 이유는 예를 들어 sigmoid함수를 사용한다 했을때 위 이미지 처럼 x축으로 -2에서 2사이는 선형적인걸 볼 수 있다.
선형적인 부분은 활성화 함수이 영향력이 감소할 수 있기에 감마와 배타 값으로 비선형성을 유지할 수 있게 해준다.
사실 batch normalization은 감마와 배타 값을 훈련시키는 것이다.
배치 정규화의 장점은 3가지가 있다.
-
학습 속도를 빠르게 할 수 있다.
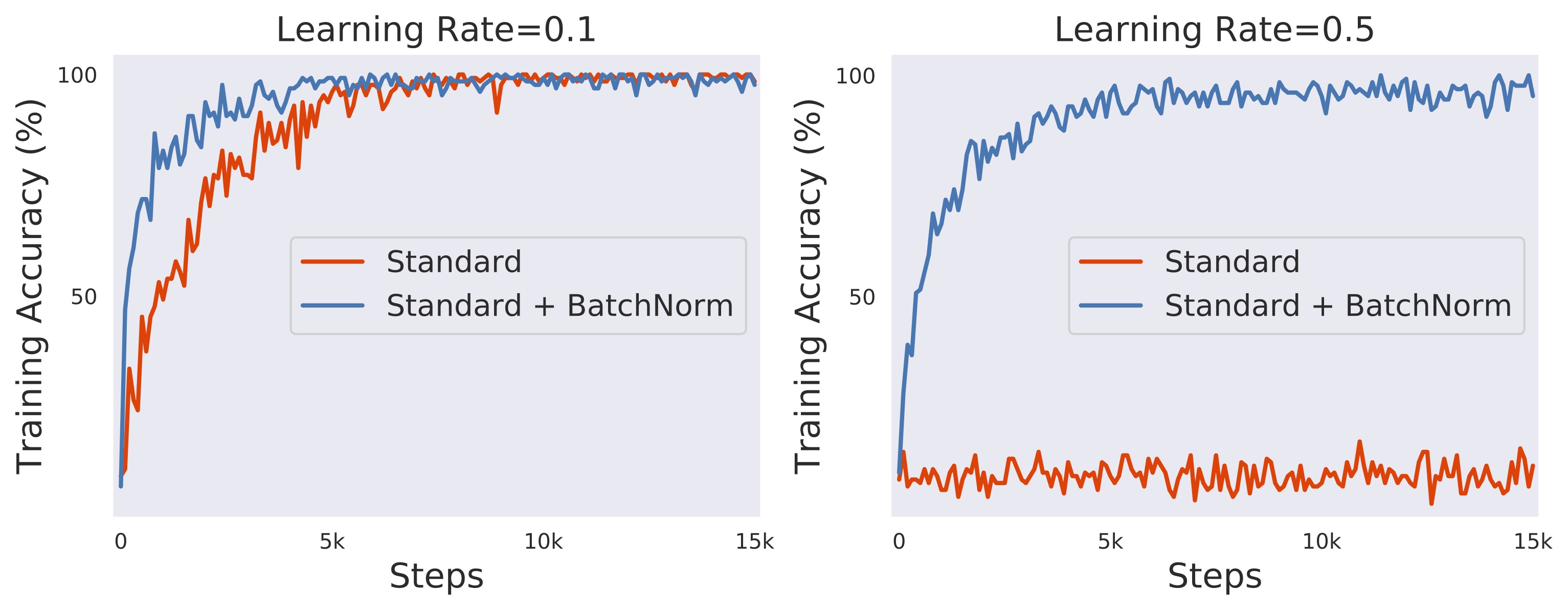
출처: https://gradientscience.org/batchnorm/ -
가중치 초기화에 대한 민감도를 감소시킨다 즉 hyper parameter의 설정이 좀 더 자유로워 진다.
-
모델의 일반화(regularization) 효과가 있다.
이런 장점 때문에 많이 쓰이는 것 같다.
Internal Covariate Shift
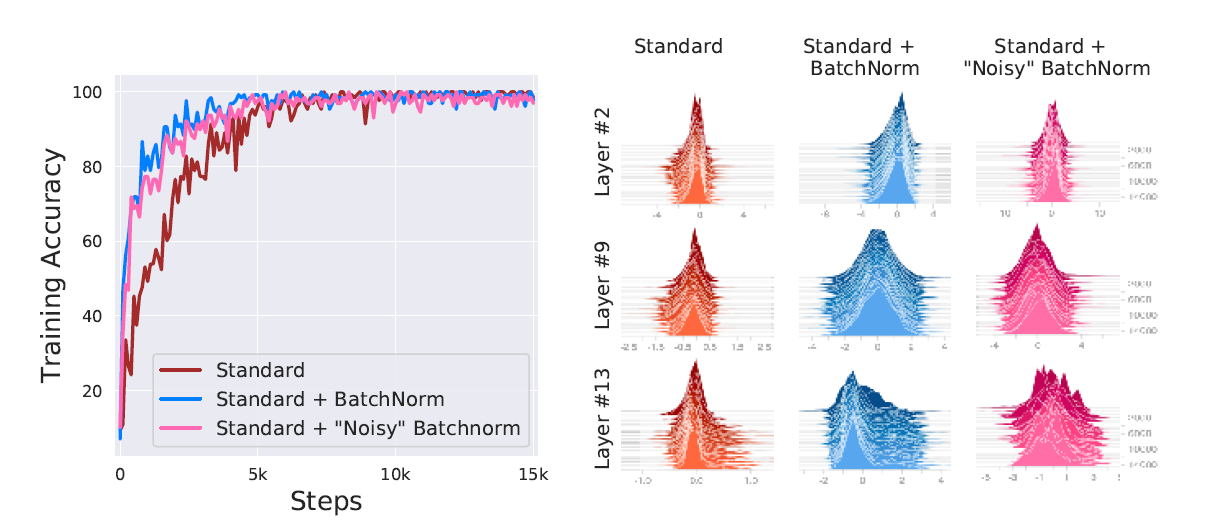
Covariate Shift(공변량 변화)가 네트워크 안에서 일어나는 현상을 Internal Covariate Shift라고 한다.
Convariate Shift(공변량 변화)
학습 시기와는 다르게 테스트 시기에 입력데이터의 분포가 변경되는 현상이다.
매 스탭마다 hidden layer에 입력으로 들어오는 데이터의 분포가 달라지는 것을 의미하며 레이어가 깊을수록 심화될 수 있다.
2015년도 BN논문에는 BN이 Internal Covariate Shift를 해결할 수 있다고 주장했지만
2018년도 BN논문에는 BN이 Internal Covariate Shift를 해결한 것은 아니다라고 한다.
하지만, 그렇다고 효과가 없던건 아니였다.
Smoothing효과
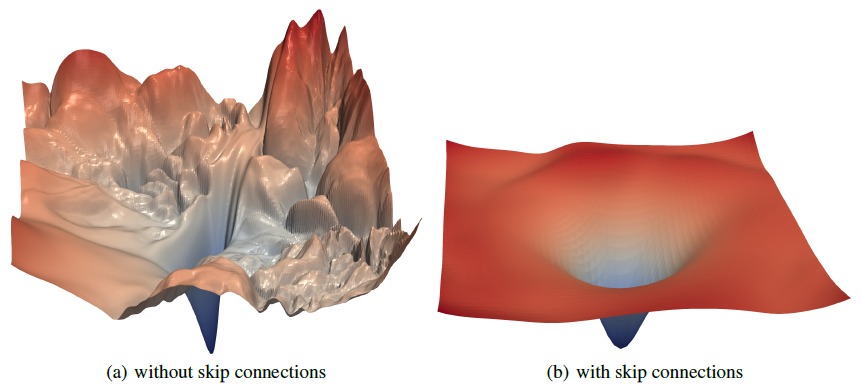
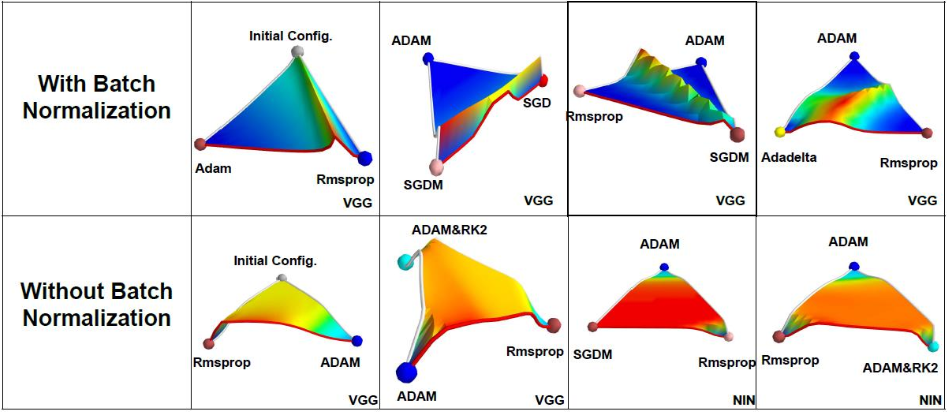
출처: https://jithinjk.github.io/blog/nn_loss_visualized.md.html
그럼 왜 BN을 쓰면 결과가 좋냐
그 이유는 Smoothing효과 때문이다. Batch Normalization은 Optimization Landscape를 부드럽게 만드는 효과가 있다.
사진과 같이 Smoothing효과로 global optim에 도달하기 쉬워진 것을 알 수 있다.
이렇게 Batch Normalization은 2015년 이후 수상작에 모두 적용될 정도로 좋은 기법이다.
