내가 프로젝트에서 맡은 부분이다. TTS를 하기 위해서는 STT가 필수적이로 필요하다.
왜냐고하면, 사용자가 답변을 하면 그 답변을 기반으로 꼬리질문을 생성해야하는데
그러기 위해서는 STT를 이용하여 LLM과 함께 꼬리질문 텍스트를 만들어야한다.
즉, 순서가 TTS -> STT -> LLM -> TTS 이런방식이다.STT(Speech-to-Text)란?
- 사람이 말한 음성을 인식해서 텍스트로 변환하는 기술
을 말한다.
STT의 주요 기술
| 항목 | AWS Transcribe Streaming | OpenAI Whisper (API) | Google Cloud Speech-to-Text | Naver CLOVA Speech |
|---|---|---|---|---|
| 제공 방식 | AWS 관리형 API (스트리밍/WebSocket) | 오픈소스 모델 + API | Google 관리형 API | 네이버 클라우드 API |
| 정확도 (한국어) | 다소 낮음 (억양, 빠른 말에 약함) | 매우 우수 (잡음/억양 포함) | 우수 | 한국어 최적화, 매우 우수 |
| 실시간성 | 실시간 지원 | API: 실시간 미지원 → Faster-Whisper로 실시간 유사 구현 가능 | 실시간 지원 | 실시간 스트리밍 지원 |
| 비용 | 약 $0.0004 / 초 (약 $0.024 / 분) | 약 $0.006 / 분 (약 $0.0001 / 초) | 약 $0.016 / 분 (표준 모델) | (공식 공개 없음) 실시간 도입 시 비용 인하 + 기능별 요금화 |
| 데이터 전송 | AWS로 전송됨 | 로컬 처리 가능 (자체 서버 무료), API는 전송 발생 | Google 서버로 전송됨 | 네이버 서버로 전송됨 |
| 확장성 / 커스터마이징 | API 기반, 변경 불가 | 자유로운 후처리/저장/연동 | 일부 설정 가능 | 한국어 특화 옵션 제공 |
| 특징 요약 | 통합 운영 용이하지만 정확도·비용 부담 | 최고 수준 정확도, 비용 효율적이지만 실시간 구현 추가 필요 | 다국어 강점, 관리형 API | 국내 서비스 최적화, 높은 한국어 인식 + 실시간 대응 가능 |
다양한 기술을 조사해보았다.
일단 Google Cloud Speech-to-Text 와 Naver CLOVA Speech 제외하기로했다.
첫번째, 우리는 AWS방식 위에 운영을 할것이다.
두번째, STT로 변환하는 지연시간이다.
세번째, 비용
크게 위와 같이 3가지를 고려했다.OpenAI Whisper 테스트
모델 성능 비교 (40초 음성 기준 & CPU 사용)
- Whisper 에서도 여러 종류의 모델이 있다.
| 사용 모델 | 언어 설정 | 걸린 시간 | 정확도 | 도출 결과 |
|---|---|---|---|---|
| Whisper_base | X | 15.71초 | 5/57 | 안녕하세요. 저는 ooo입니다. 유나 레일아트 정말 예쁘다. 얼마 했을까? 너무 궁금합니다. 저도 하고 싶어요. 유나야, 그럴 거면 화장실 가서 양치 배꼽아 흘리겠다. 아직 2초가 되었어요. 무슨 말을 해야 할까요? 우리 조화이팅, 최강조화이팅. 렌접조도 화이팅. 우리 모두 화이팅에서 취업 잘 됐으면 좋겠습니다. 화이팅. |
| Whisper_base | O | 11.16초 | 8/57 | 안녕하세요 저는 ooo입니다 유나 레일아트 정말 예쁘다 얼마 했을까 너무 궁금합니다 저도 하고 싶어요 유나야 그럴 거면 화장실 가서 양치 배꼽아 흘리겠다 아직 이씨 위초가 되었어요 음 무슨 말을 해야 할까요 우리 조 하이팅 최강조 하이팅 렌접조도 하이팅 우리 모두 하이팅에서 취업 잘 됐으면 좋겠습니다 하이팅 |
| Whisper_small | O | 26.91초 | 4/57 | 안녕하세요 저는 ooo입니다 유나 내일 하트 정말 예쁘다 얼마 했을까 너무 궁금합니다 저도 하고 싶어요 유나야 그럴 거면 화장실 가서 양치 뱉고 와 흘리겠다 아직 22초가 되었어요 무슨 말을 해야 할까요? 오리조 화이팅 최강조 화이팅 면접조도 화이팅 오리모도 화이팅해서 취업 잘 됐으면 좋겠습니다 화이팅 |
기본적으로 11초 이상 지연시간이 발생되는 것을 확인했다.
정확도는 부분적으로 변환을 재대로 못하는 모습을 보이고 있었다.
정확도는 검증용으로 LLM을 사용하면 해결할 수 있다.
하지민 실시간 면접 서비스인 만큼 지연시간을 최대한 줄여야한다.AWS Transcribe Streaming 테스트 (40초 음성 기준)
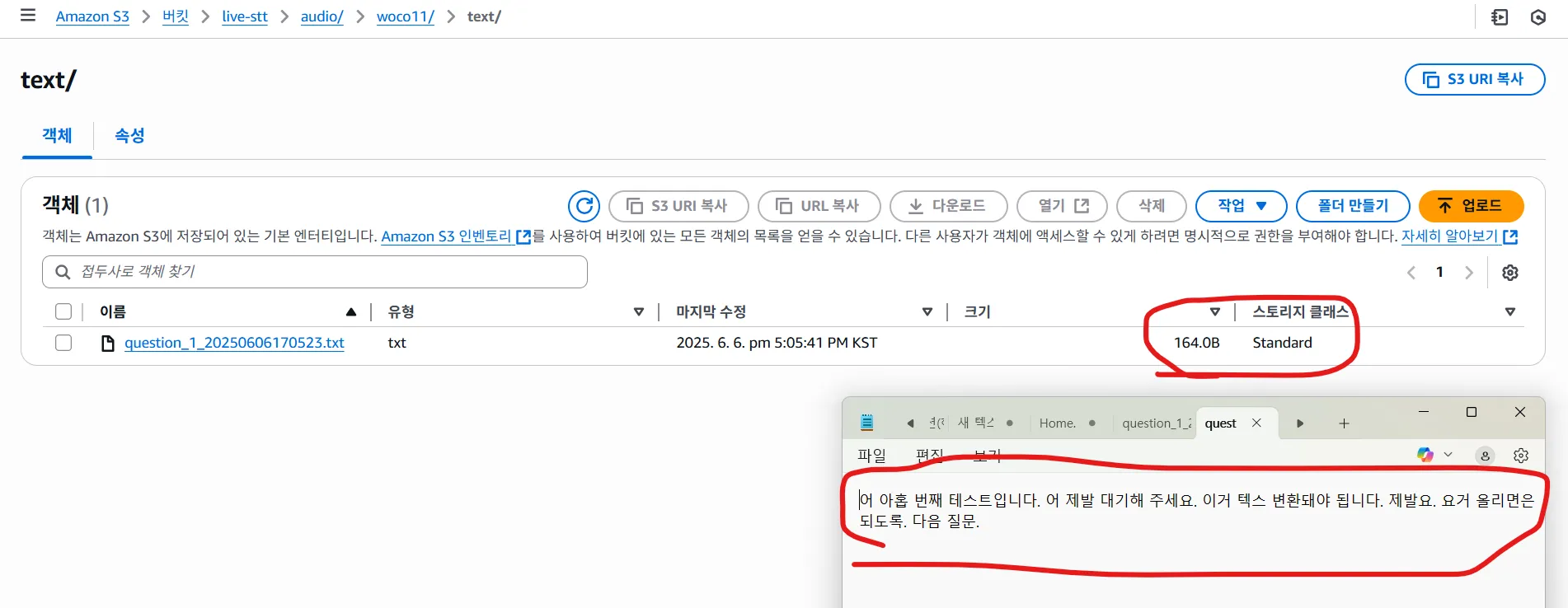
웹 소켓 -> webm 녹음 -> wav 변환 -> 백서버 에서 AWS으로 wav 업로드(s3) -> 트랜스 크라이브를 통해 텍스트화
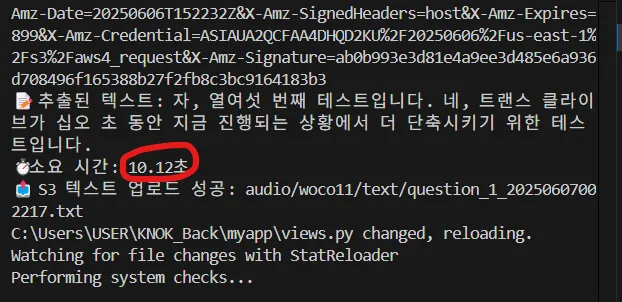
- 10초면 "Whisper" 보다 조금더 괜찮은 성능이다.
- 방식을 다르게하면 어떻게 될까?
프론트(녹음) → 웹소켓을 통해 실시간 트랜스 크라이브 API 호출→ s3에 업로드
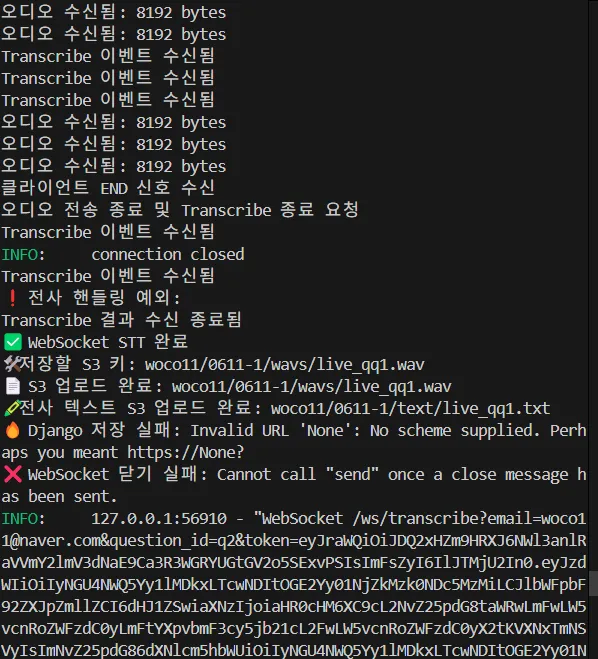
처음에는 websocket이 시작하자 마자 종료되는 현상이 발생했지만,
시간 지정과 버튼 트리거를 통해서 해결하였다.
- 실시간으로 음성이 변환이 되어 텍스트로 저장되는것을 확인
최종 선택 (AWS Transcribe Streaming)
- "Whisper" 보다 성능이 좋다.
- AWS 기반이기 때문에 프로젝트와 호환성이 좋다.
- 지연시간이 더 짧다.
- 실시간으로 변환이 진행되기 때문에 프로젝트에 더욱 알맞다고 판단.
- 비용적으로도 더욱 효율적이다.
- 정확도는 검증용 LLM을 통해 정확도를 올리면 되는것이다.

꿈나무🌳