개요
첫번째 질문이 사용자에게 제공이되고, 다음 질문이 자소서 기반의 메인 질문이 될지, 사용자 말한 답변에 대한 꼬리질문이 될지를 판단하는 분기 로직 설계를 해야한다. 판단 기준을 고려하고, 가능한 범위에서 합당한 방법을 찾아야한다.
접근 방법 비교
| 방식 | 아이디어 | 장점 | 단점 | 결론 |
|---|---|---|---|---|
| 랜덤 꼬리질문 | 무작위로 메인/꼬리 선택 | 구현 단순, 지연 無 | 합당성·일관성 부족, 사용자 경험 불안정 | ❌ 제외 |
| LLM 판단 | LLM이 답변 읽고 분기 | 맥락 이해 탁월, 품질 높음 | 추가 호출 지연, 비용 증가, 일관성 낮음 | ❌ 제외 |
| 키워드 판단 | 자소서 키워드 vs 답변 키워드 매칭 | 빠름, 비용 낮음, 일관된 기준 | 동의어/의미 유사 처리 필요 | ✅ 채택 |
키워드 판단 선택 이유:
LLM 모델은 실시간 서비스 특성상 지연이 크면 UX가 크게 떨어짐.
LLM은 정확하지만 느리다
랜덤방식은 근거가 없음.
따라서 빠르고 합리적인 키워드 기반 분기 로직을 채택했다.
키워드 판단 로직 설계
핵심 아이디어
- 자소서 키워드를 사전 구축
- 사용자 답변에서 키워드 추출
- 일치/유사도 점수화 → 임계값 기준으로 메인/꼬리질문 분기
데이터 흐름
- 자소서 키워드 사전 구축
- 사용자 답변 STT → 텍스트 변환
- 답변 키워드 추출
- 자소서 키워드와 비교 → 점수 산출
- 임계값 이상 → 꼬리질문, 이하 → 메인 질문
분기 판단 로직
| 항목 | 설명 |
|---|---|
| resume_text | 사용자 자소서 내용 (PDF에서 추출 or 사용자 입력) |
| user_answer | 사용자가 방금 한 답변 (텍스트 형태) |
| extract_resume_keywords() | KeyBERT를 활용하여 자소서에서 핵심 키워드 추출 |
| matched_keywords | 사용자 답변 내 자소서 키워드와 일치한 단어 리스트 |
| 분기 기준 | matched_keywords의 길이가 2 이상이면 꼬리질문 진행 |
구현 포인트
- 키워드 추출: KeyBERT, KoNLPy 등 활용
- 동의어 매핑: “무중단=blue-green”, “지연=latency” 등 사전 매핑
- 유사도 계산: 코사인 유사도 기반 임베딩 활용
- 부정/회피 감지: “잘 모르겠습니다” → 무조건 메인 질문
- 쿨다운 규칙: 꼬리질문 연속 2회 이상 방지
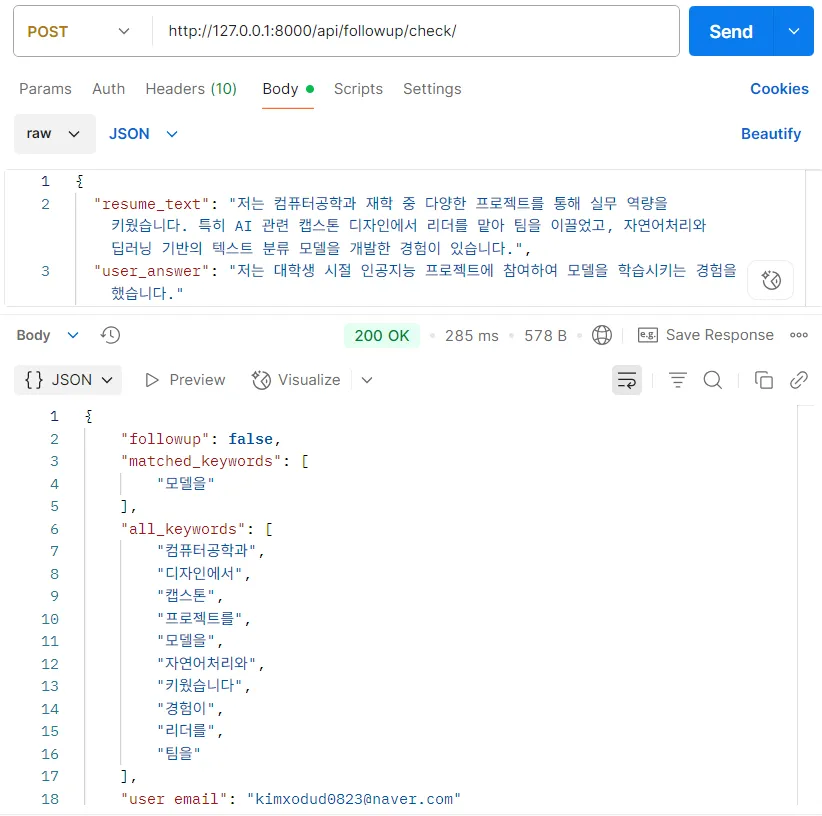
테스트
{
"resume_text": "저는 컴퓨터공학과 재학 중 다양한 프로젝트를 통해 실무 역량을 키웠습니다. 특히 AI 관련 캡스톤 디자인에서 리더를 맡아 팀을 이끌었고, 자연어처리와 딥러닝 기반의 텍스트 분류 모델을 개발한 경험이 있습니다.",
"user_answer": "저는 대학생 시절 인공지능 프로젝트에 참여하여 모델을 학습시키는 경험을 했습니다."
}
예외 처리 및 방어 로직
resume_text또는user_answer가 비어 있을 경우 → 400 Bad Request- 키워드 추출 중 임베딩 오류 발생 시 →
[]반환 + 서버 로그 출력 access_token사용 시 →"이메일이 토큰에 없습니다."403 응답
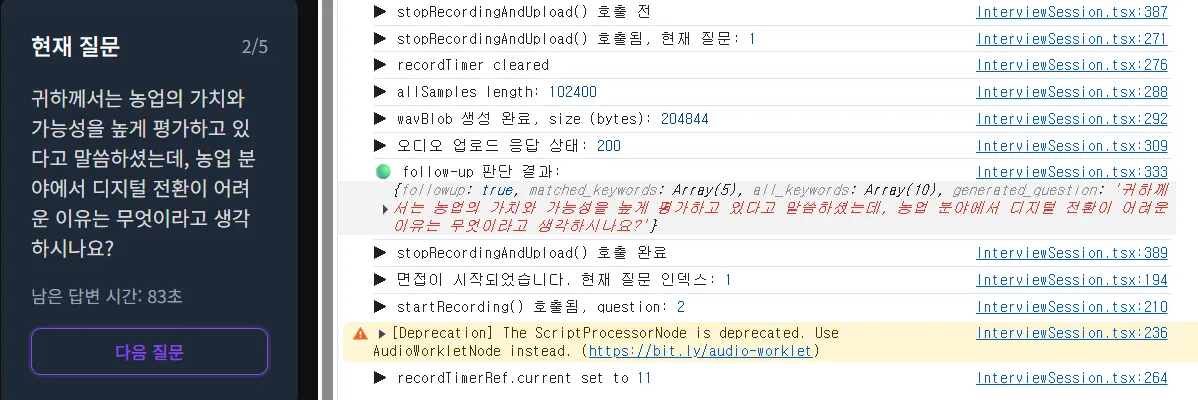
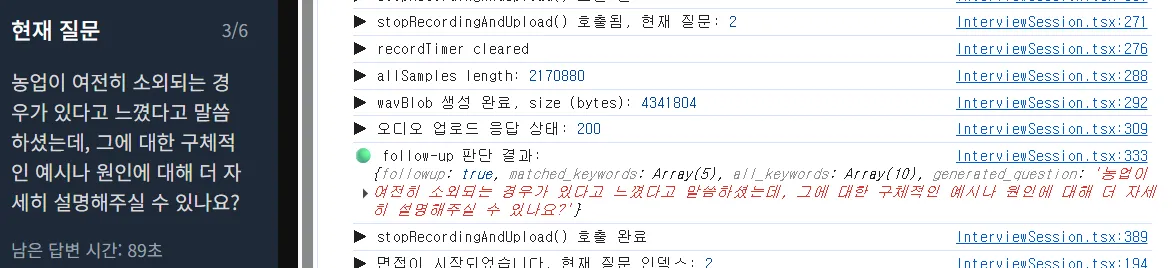
- 초기에 메인 질문이 5개가 준비 되었고, 꼬리질문이 판단되면 "3/6" 처럼 전체의 갯수가 증가한다.

꿈나무🌳