사용자에게 면접이 끝난후 피드백을 전달하기 위해서 피드백 기준을 세웠고 그중에 음성 분석에 관한 근거있는 수치를 뽑아 피드백을 줄수있게끔 하는 역할을 맡았다. 구축하기전에 어떤 기술로 어디까지 수치화 시킬수있으며 방법이 무엇이 있을지 고민해야한다.
기술
| 분석 항목 | 가능 여부 | 사용 라이브러리 |
|---|---|---|
| 🎙 음성의 떨림 (Jitter) | ✅ 가능 | librosa, parselmouth |
| 📉 목소리 높낮이 변화 (Pitch) | ✅ 가능 | librosa, praat-parselmouth |
| 🕒 말 속도 (Speech rate) | ✅ 가능 | librosa, speechpy |
| 🔊 감정 상태 (Emotion) | ✅ 가능 | Hugging Face 모델, openSMILE |
| ⏸️ 망설임/침묵 시간 (Pause length) | ✅ 가능 | librosa, webrtcvad |
librosa 를 사용하여 음성의 떨림,목소리 높낮이,말 속도, 침묵시간 을 분석해보았다.라이브러리 선택 이유
사용자 답변의 말투와 감정, 속도, 침묵 비율 등을 분석해야
했기 때문에, 음성 신호를 시간·주파수 도메인에서 다룰 수 있는
라이브러리를 찾았습니다.
비교 후보로는 torchaudio, => 리브로사
praat-py 등이 있었지만, => 리브로사
그 중에서:
- Parselmouth는 Praat를 Python으로 감싸서
사용할 수 있게 만든
라이브러리로, pitch(음 높이),jitter(주기),shimmer(진폭)
, 감정 성분 분석에 특화되어 있었습니다.
- Librosa는 음성 신호를 스펙트로그램이나 mel scale(멜 스케일) 등
으로 변환해서 말 속도나 침묵 비율 계산에 효율적이었고,
Python 생태계에서 가장 널리 쓰이는 오디오 분석 도구였습니다.
Praat 자체는 GUI 기반이라 자동화가 어렵고, torchaudio는 설치와
환경 구성이 무거운 데 반해, Parselmouth와 Librosa는 가볍고 직관적인
API를 제공해서 빠르게 분석 결과를 도출할 수 있었고,
학습곡선도 낮아 사용하기 좋았습니다.테스트

“Claude 3 Haiku” 에 전달할 프롬프트를 생성 테스트 결과
- 녹음이 계속되는건가? 아니면 파일이 나누어 져서 되는건가?
- 한개의 질문 마다 녹음이 되어 s3에 저장된다.
- 수치를 어떻게 조정해야할까?
- s3파일 위치가 수동적으로 표시를 해놔서 아직 개개인의 사용자의 음성분석이 가능할지는 미지수
- 데이터 세션을 ID 마다 일치 시켜서 저장하게 만들면된다.
- 목소리의 떨림 만 분석한 상태
- 말의 속도, 침묵시간, 감정 분석 등등 더 추가해야 할 거 같다.
등등 다양한 생각이 들었다.
권장값 기준
| 항목 | 권장 값 |
|---|---|
| sr | 16000 Hz |
| 채널 | mono |
| n_fft | 1024 (≈64 ms) 특징 추출용 |
| hop_length | 256 (16 ms) 또는 320 (20 ms) |
| 프레임 전송 | 20–30 ms(320–480 샘플 @16k) |
| RMS 목표 | −20 ~ −3 dBFS |
| 무음 컷 | ≥ 200 ms 연속 무음 제거 |
| SNR | ≥ 20 dB |
| 샘플 포맷 | int16 PCM, little-endian |
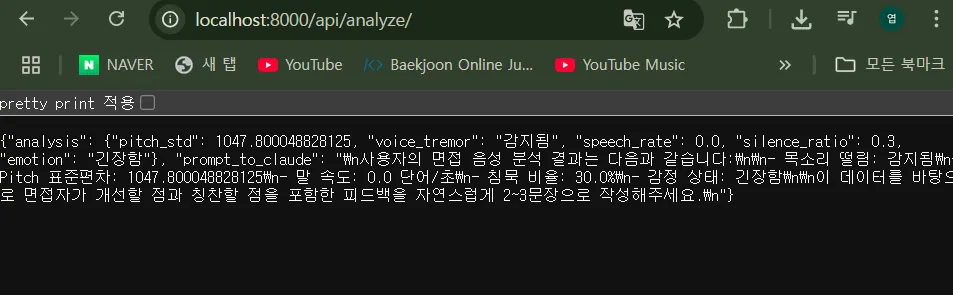
- 말속도,떨림,감정,침묵시간 감지 하여 수치로 나오는것을 확인
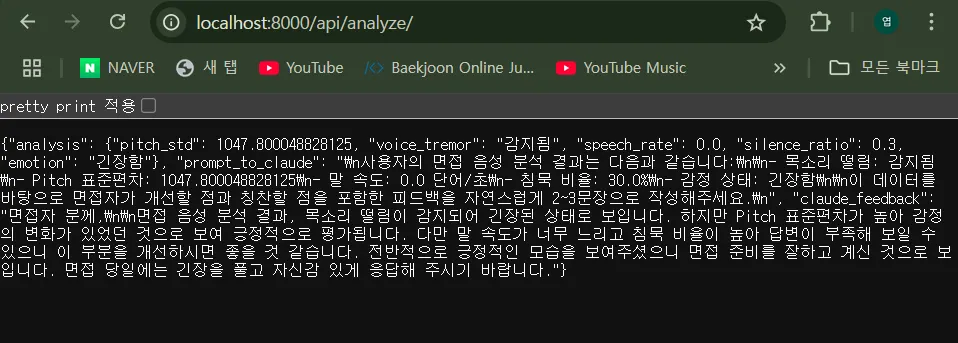
- Claude 3 Haiku 연동 후 LLM을 통한 피드백 내용 확인
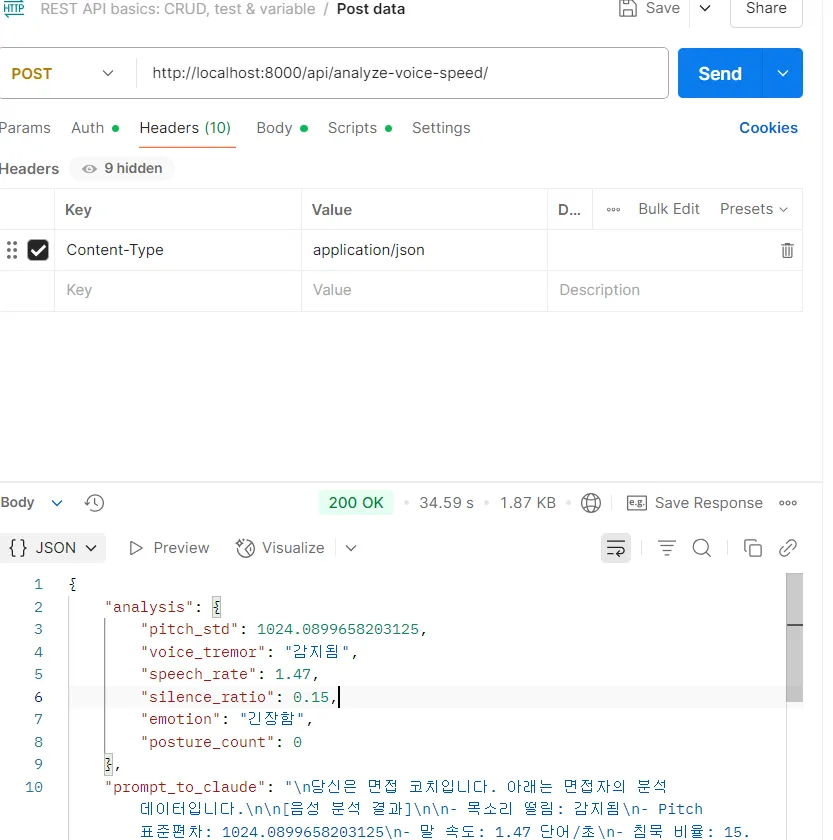
- LLM의 기준이 될 프롬프트를 작성후 피드백을 만들어서 제공!
Parselmouth는 pitch(음높이), jitter(주기), shimmer(진폭) 등
음성의 안정성과 "감정" 요소 분석에 사용했고,
Librosa는 말 속도, 침묵 구간, 에너지 변화 같은 시간 기반 음성특징
을 추출하는 데 사용했습니다.추가정보) 감정 상태나 피로도를 음성 분석으로 정확히 알 수 있나?
정확히는 "추정"만 가능하지만, 일정 jitter/shimmer 수준이나
pitch 기복, 에너지 레벨 등을 종합하면
긴장, 불안, 피로의 가능성을 높게 예측할 수 있습니다.
단정 짓지 않고, "해당 가능성 있음" 수준으로 제공합니다.
꿈나무🌳