ECS Auto Scaling 사용법
먼저 ECS에 클러스터와 서비스가 생성되어있다고 가정하고 작성을 하겠습니다.
ECS관련 자료 (링크)
오토 스케일링 설정 방법
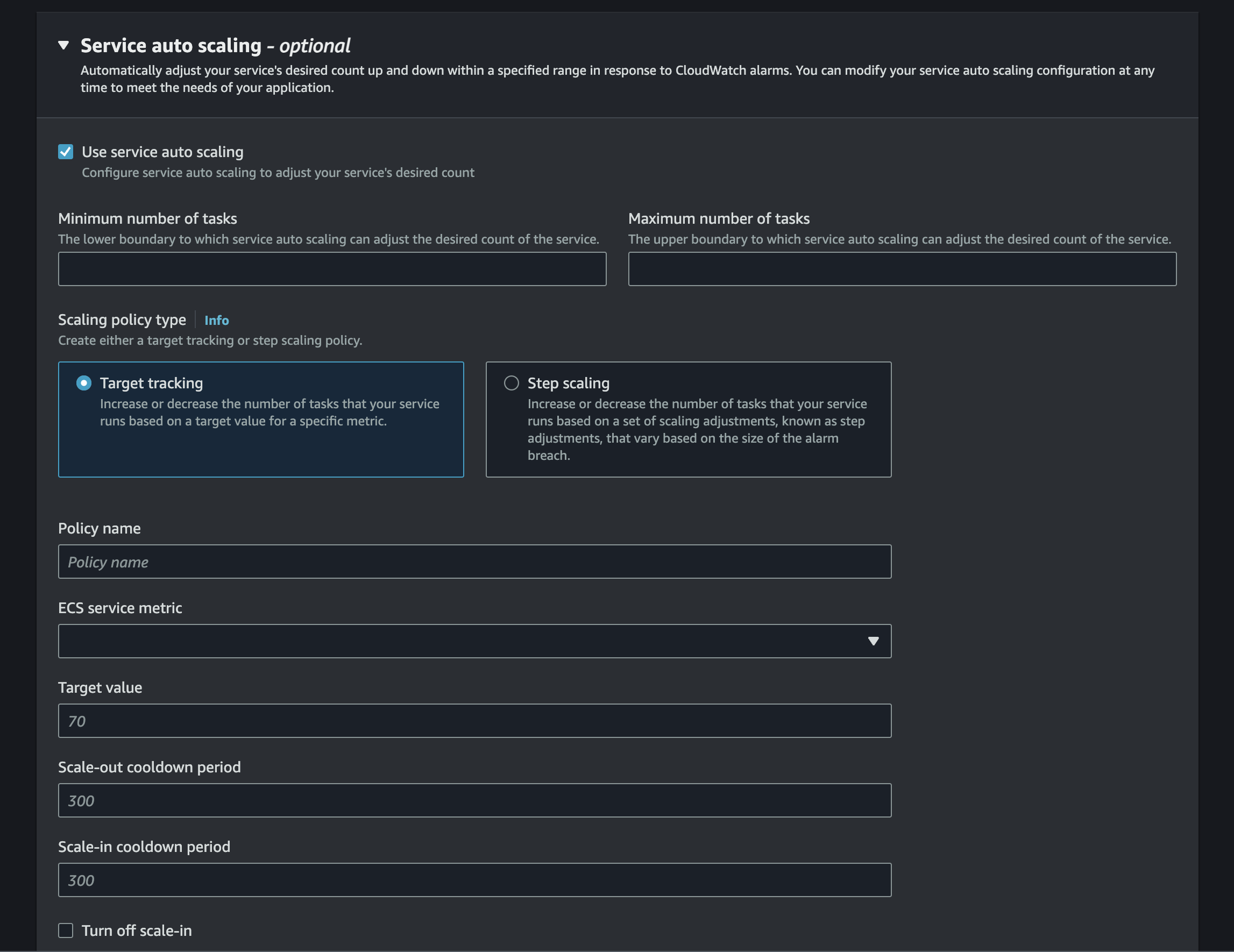
ECS에서 Auto Scaling 관련 옵션을 설정할 때는
-
최소 태스크 수(Minimum number of tasks) / 최대 태스크 수(Maximum number of tasks)를 설정할 수 있습니다.
-
정책 이름(Policy name)을 입력해줍니다.
-
ECS 서비스 지표(ECS service metric)에서 3가지 기준이 있습니다.
-
ECSServiceAverageCPUUtilization: 서비스의 CPU 평균 사용률을 나타냅니다. 서비스의 CPU 사용률이 높아지면, 추가 인스턴스(태스크)를 생성하여 부하를 분산할 수 있습니다.
-
ECSServiceAverageMemoryUtilization: 서비스의 메모리 평균 사용률을 나타냅니다. 메모리 사용률이 높아지면, 추가 인스턴스를 생성하여 메모리 부족 문제를 해결할 수 있습니다.
-
ALBRequestCountPerTarget: Application Load Balancer(ALB)의 각 타겟 그룹당 요청 수를 나타냅니다. 서비스의 트래픽이 증가하면 추가 인스턴스를 생성하여 요청을 처리할 수 있습니다. (순간적인 트래픽이 몰리는 경우 이 방법도 좋지만 아래에서 추가설명하겠지만 Target Value(대상 값)을 데이터 바탕으로 지정을 해서 기준을 설정하면 좋은 방법 중 하나이다.
사용자가 많아지면 CPU, Memory의 사용률이 늘어나지만 기준을 잘세워서 설정하는 것이 중요하다 보편적으로 CPU사용률을 기준으로 많이하지만 정책을 추가해서 CPU, Memory의 사용률에 각각 조건을 걸어줘도 인스턴스(태스크)가 늘어나는걸 확인할 수 있다. 또한 Memory기준으로만 조건을 세운다면 Memory의 단독 사용률의 증가는 문제가 있다는 걸 알 수 있습니다. 정책(조건)을 추가할 때 그에 맞는 이유가 있다면 그렇게 적용하시면됩니다.
-
-
대상 값 (Target Value): 임계치를 지정하여줍니다. 설정한 값을 넘어가는경우 인스턴스가 추가가 됩니다.
- 예를들어 트래픽이 순간적으로 몰리는 경우의 서비스라면 대상 값을 낮게 지정해주어 여러 인스턴스가 추가되어 부하를 분산시켜줄 수 있습니다. 서비스 환경에 따라 대상 값을 설정 및 변경
-
확장 휴지 기간(Scale-out cooldown period): 스케일 아웃 이벤트가 발생한 후에 새로운 인스턴스가 추가되는 것을 방지하기 위한 시간입니다. 이 기간 동안 추가적인 스케일 아웃 이벤트가 발생하지 않습니다. 스케일 아웃 이후의 확장 휴지 기간은 시스템이 추가된 인스턴스에 대한 리소스 사용을 평가하고 안정화할 수 있는 시간을 제공합니다.(기본 값: 300)
-
축소 휴지 기간(Scale-in cooldown period): 스케일 인 이벤트가 발생한 후에 인스턴스를 제거하는 것을 방지하기 위한 시간입니다. 이 기간 동안 추가적인 스케일 인 이벤트가 발생하지 않습니다. 스케일 인 이후의 축소 휴지 기간은 시스템이 인스턴스가 제거된 후에도 여전히 정상적으로 작동하는지를 확인할 수 있는 시간을 제공합니다.(기본 값: 300)
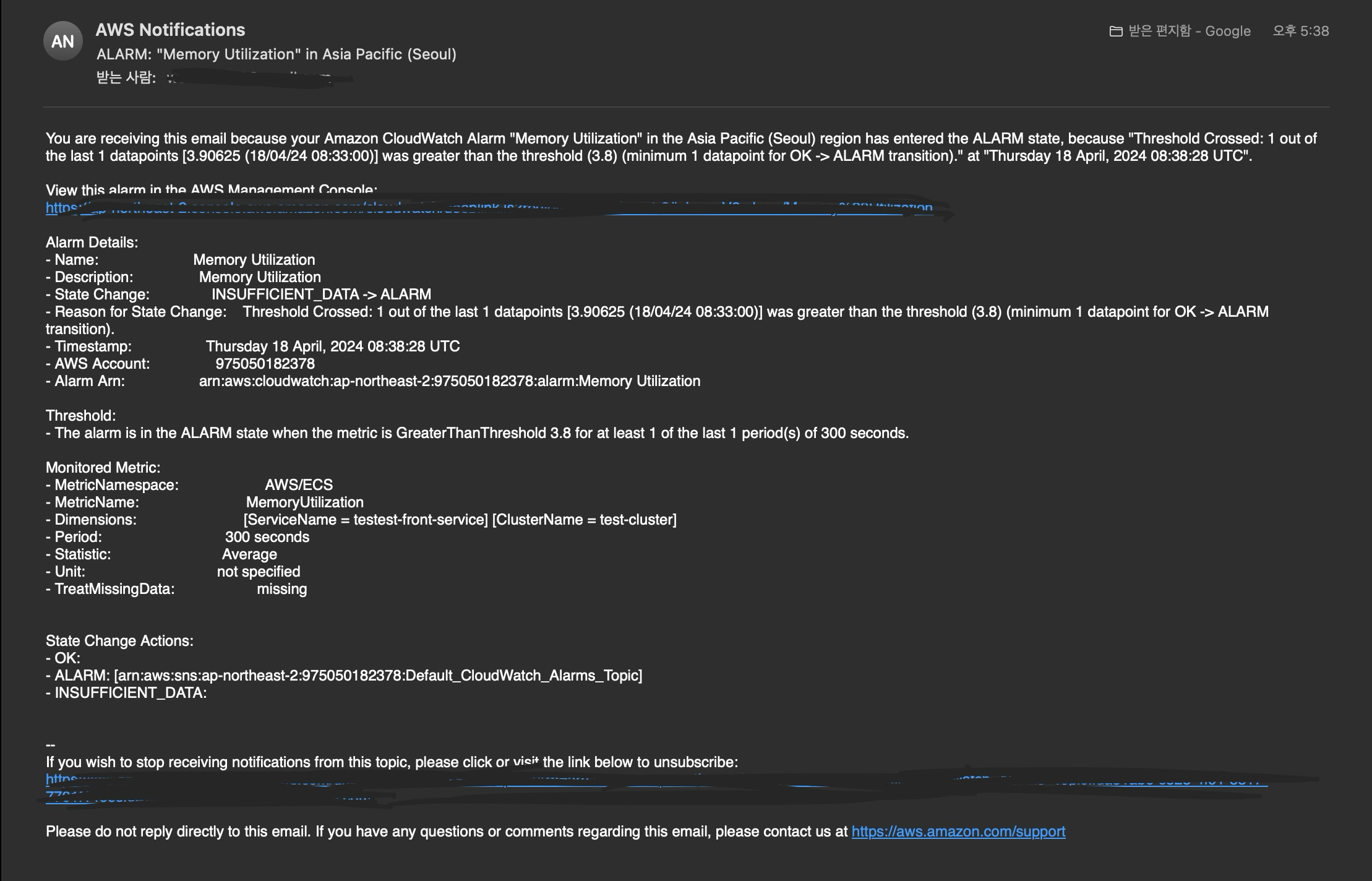
저는 Auto Scaling을 확인하기 위해서 서비스 모니터링을 통하여 작동하고 았는 CPU사용률(%)을 확인하고 사용률보다 낮은 대상 값을 설정하여 사용률이 넘어가 태스크가 추가되는 것을 확인할 수 있습니다.
CloudWatch
추가적인 확인으로는 AWS에서 제공하는 CloudWatch를 이용하여 직접 알림을 받는 방법도 있습니다.
CloudWatch > Alarms(경보) -> 경보 생성
-> 지표 선택
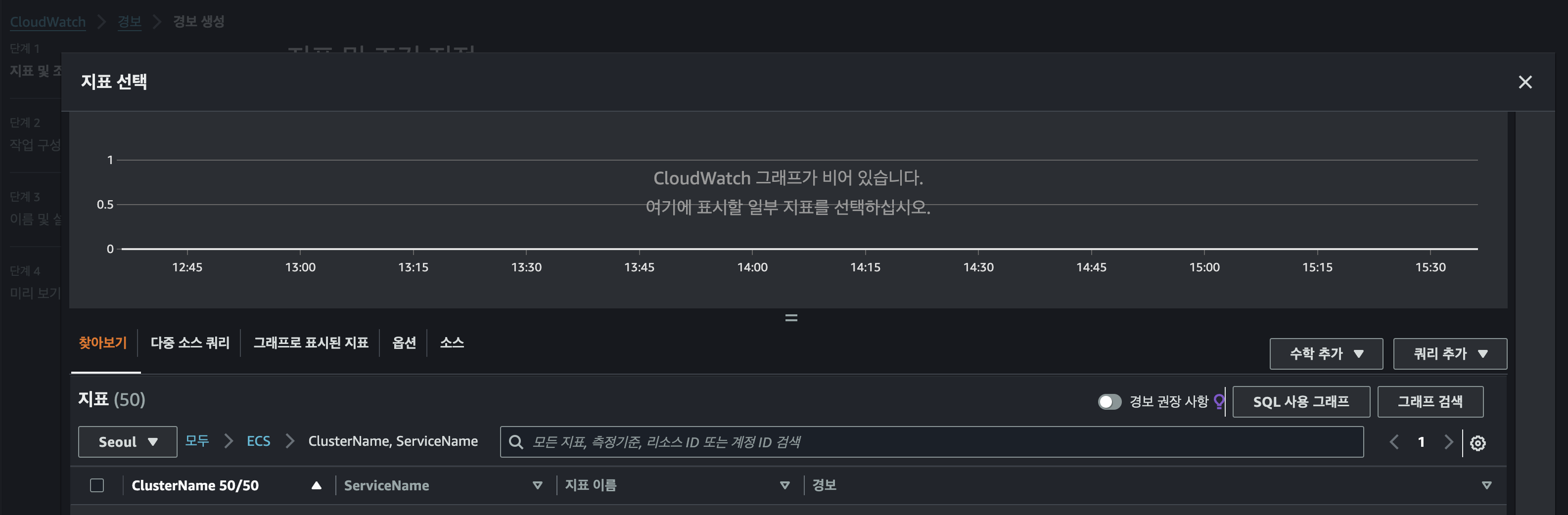
-> ECS -> 오토스케일링으로 설정하였던 서비스의 지표 CPU, Memory사용률

-> 임계값 설정(오토스케일링 값과 같게)
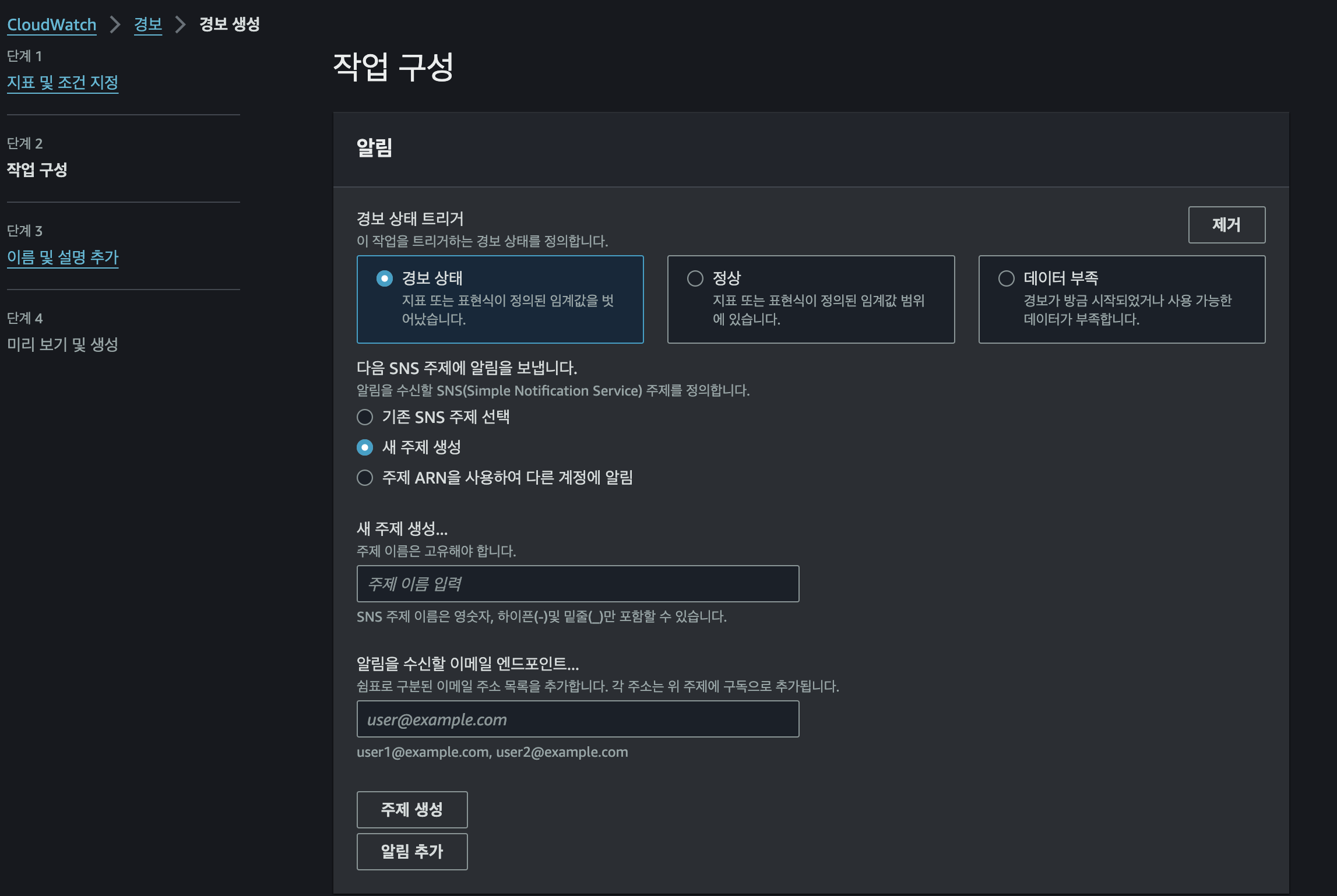
-> 알람 추가(주제이름을 지정 후 이메일정보를 입력합니다) -> 주제 생성 버튼을 클릭합니다

-> 경보이름과 경보 설명을 입력해줍니다.
생성을 완료하고나서 대상값이 넘어가면 태스크가 추가되고, 경보(알림)이 작동되면 지정한 이메일로 메일이 날라갑니다.