개요
예전에 네이버에서 CLOVA X라고 해서 OpenAI의 ChatGPT에 대항하는 LLM 모델이 등장했다고 해서 흥미를 끌었던 적이 있었습니다.
하지만 당시에는 대화 가능한 LLM 모델을 처음 공개한 상황이고 서비스 개발에 활용할 수 있는 API같은 게 미비했었던 걸로 기억합니다. (그때 열심히 찾아보긴 했었습니다만, 발견은 못했었거든요)
최근에 네이버 클라우드에도 지원서를 내보면서(물론 떨어질 듯ㅠ) 네이버의 LLM 성능이 궁금하기도 하고, API 같은 엔드포인트가 있는지 확인해볼 겸 해서 글로 남깁니다.
Naver Cloud Platform
구글 클라우드 플랫폼이나 AWS처럼 클라우드 기반의 다양한 기술을 모아놓은 곳이 네이버에도 존재합니다. 여기에서 CLOVA Studio라는 서비스를 활용하여 CLOVA X를 활용해볼 수 있습니다.
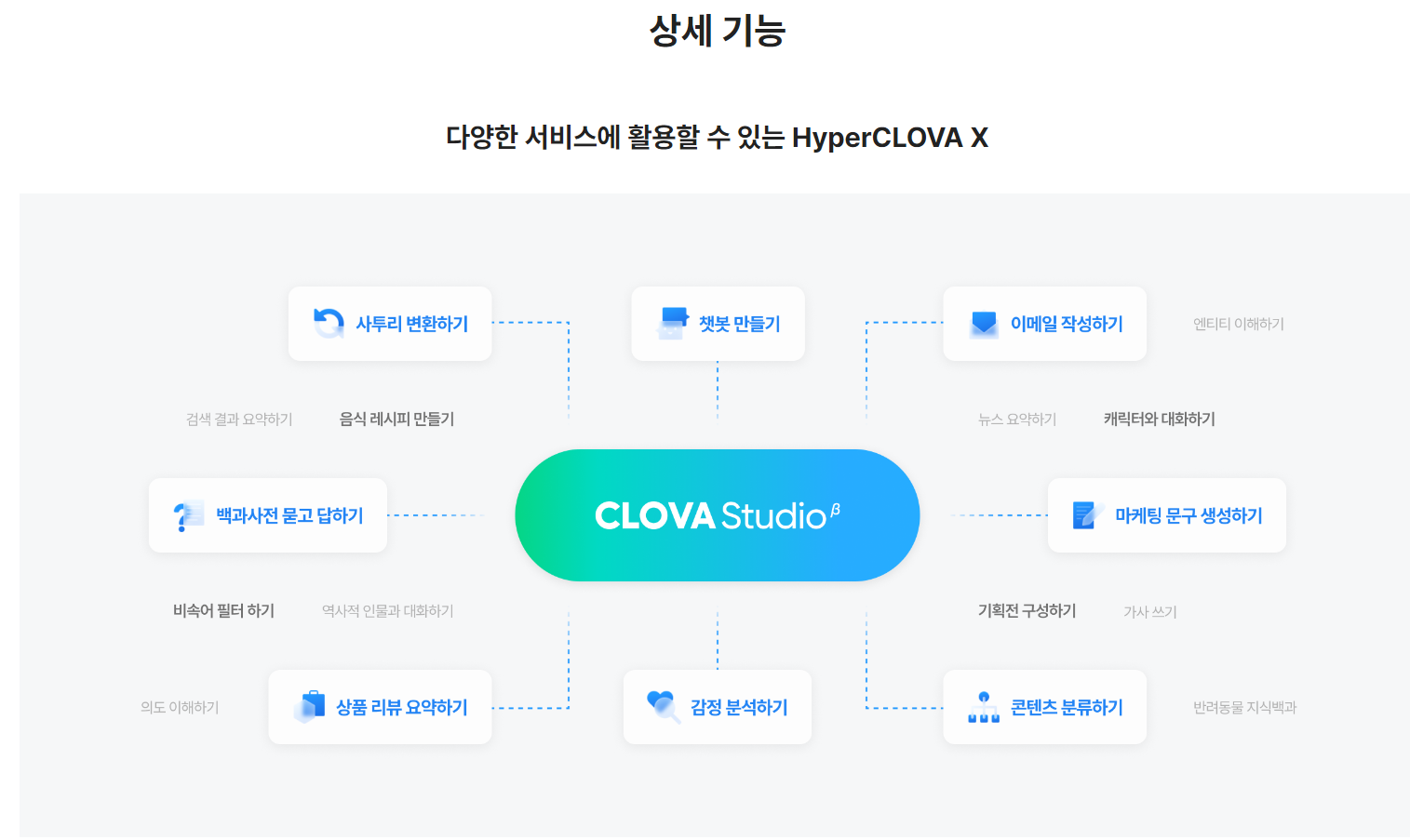
생각보다 재밌는 기능이 많았습니다. ChatGPT는 그저 LLM 모델만 제공하는 느낌인데, 네이버는 튜닝이라고 하여 LLM모델을 특정 용도에 맞춰 사용할 수 있게 제공하는 방식도 있었습니다.
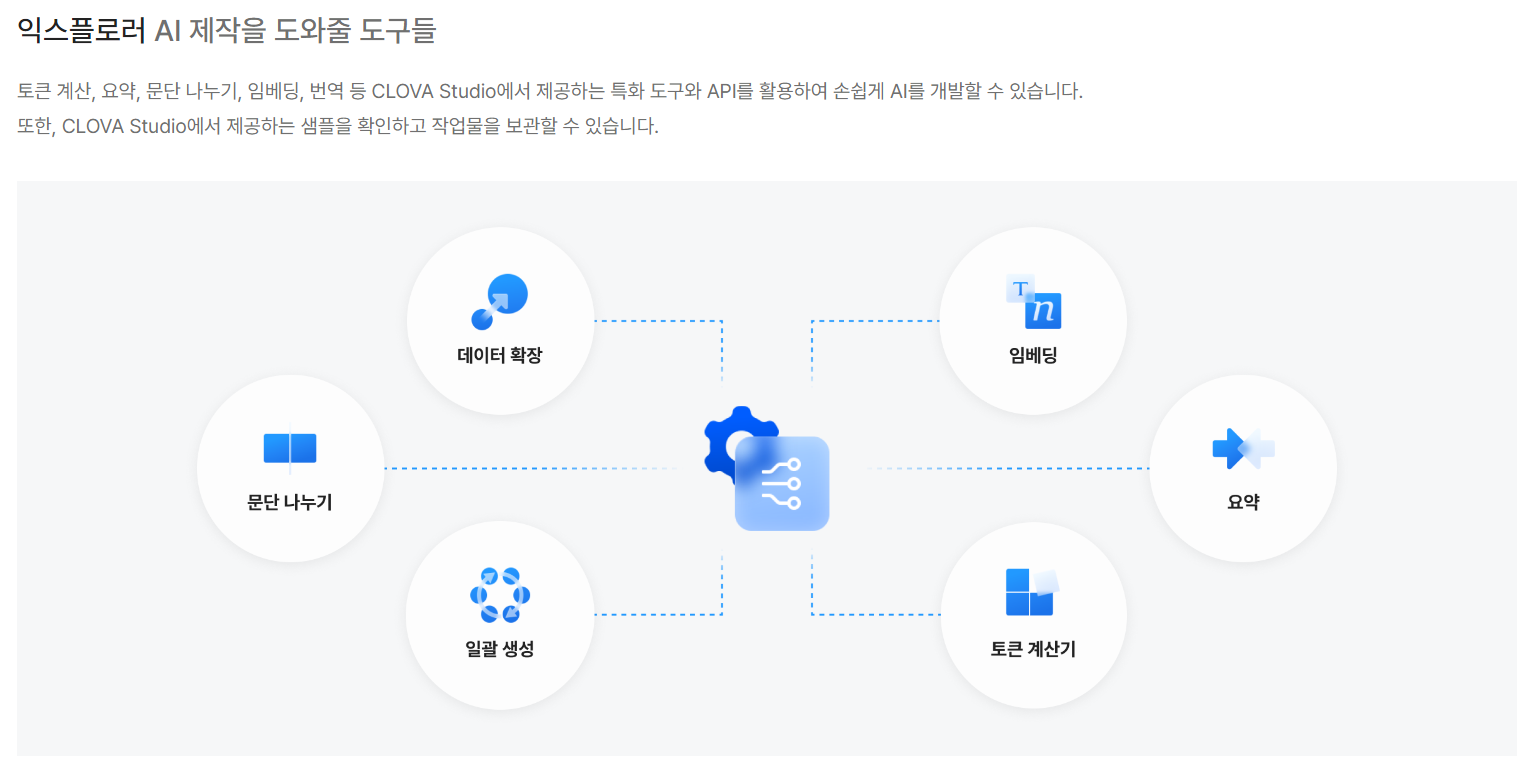
그리고 ChatGPT의 Code Inspector와 비슷하게 LLM이 활용할 수 있는 도구들도 제공됩니다.
CLOVA X를 사용해보자
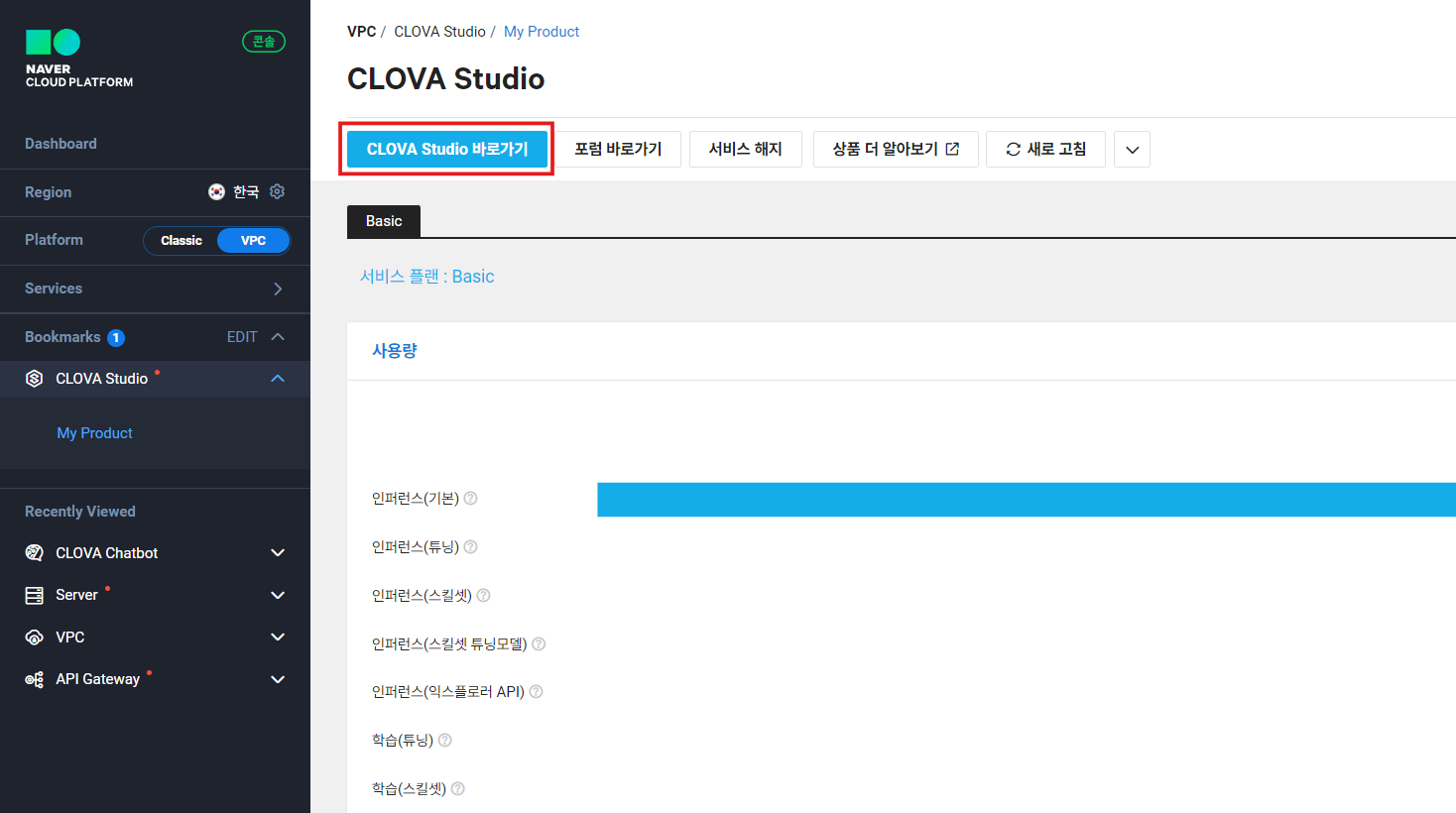
네이버 클라우드 플랫폼(이하 NCP)에서 CLOVA Studio 이용권한을 신청하시면 위와 같은 화면이 나타나는데요. CLOVA Studio 바로가기 버튼을 클릭합니다.
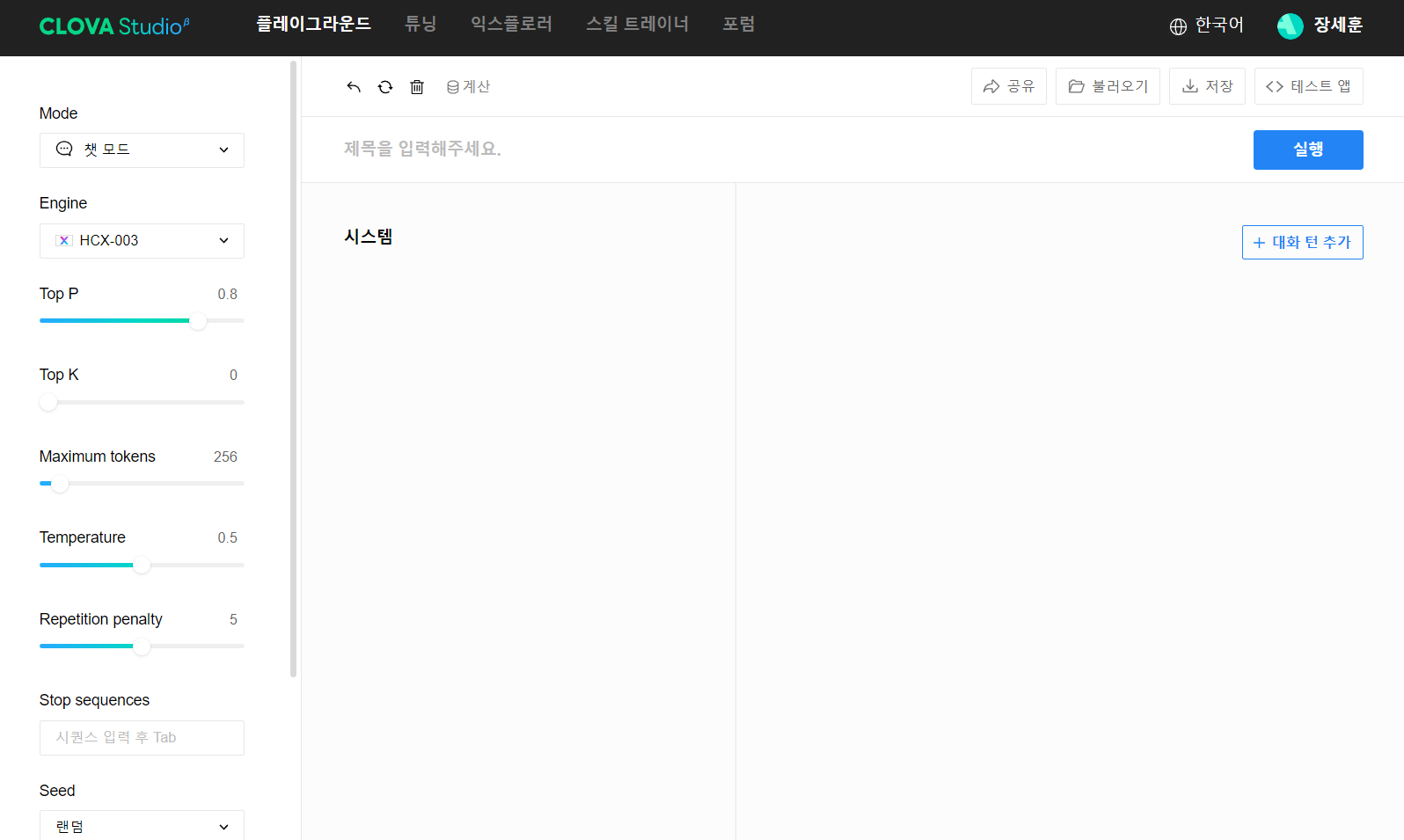
다른 기능들도 많지만, 오늘 포스트의 목적은 플레이그라운드에 있습니다. 당장 이리저리 둘러봐도 CLOVA X를 활용할 수 있는 API Endpoint가 보이지 않습니다. 네이버는 오른쪽에 보이는 <> 테스트 앱 버튼을 통해 임시 배포를 하고, 실제 서비스에 활용하기 위해서는 서비스 앱 신청이라는 과정을 거쳐야 합니다.
챗봇 만들기
간단하게 제목과 시스템 메시지를 작성하고 테스트 앱으로 배포해봅시다.
저는 제가 운영중인 디스코드 봇을 위한 챗봇으로 만들어볼게요.

간단하게 시스템 메시지를 작성했으니, 오른쪽의 대화영역에서 테스트를 해봅시다.
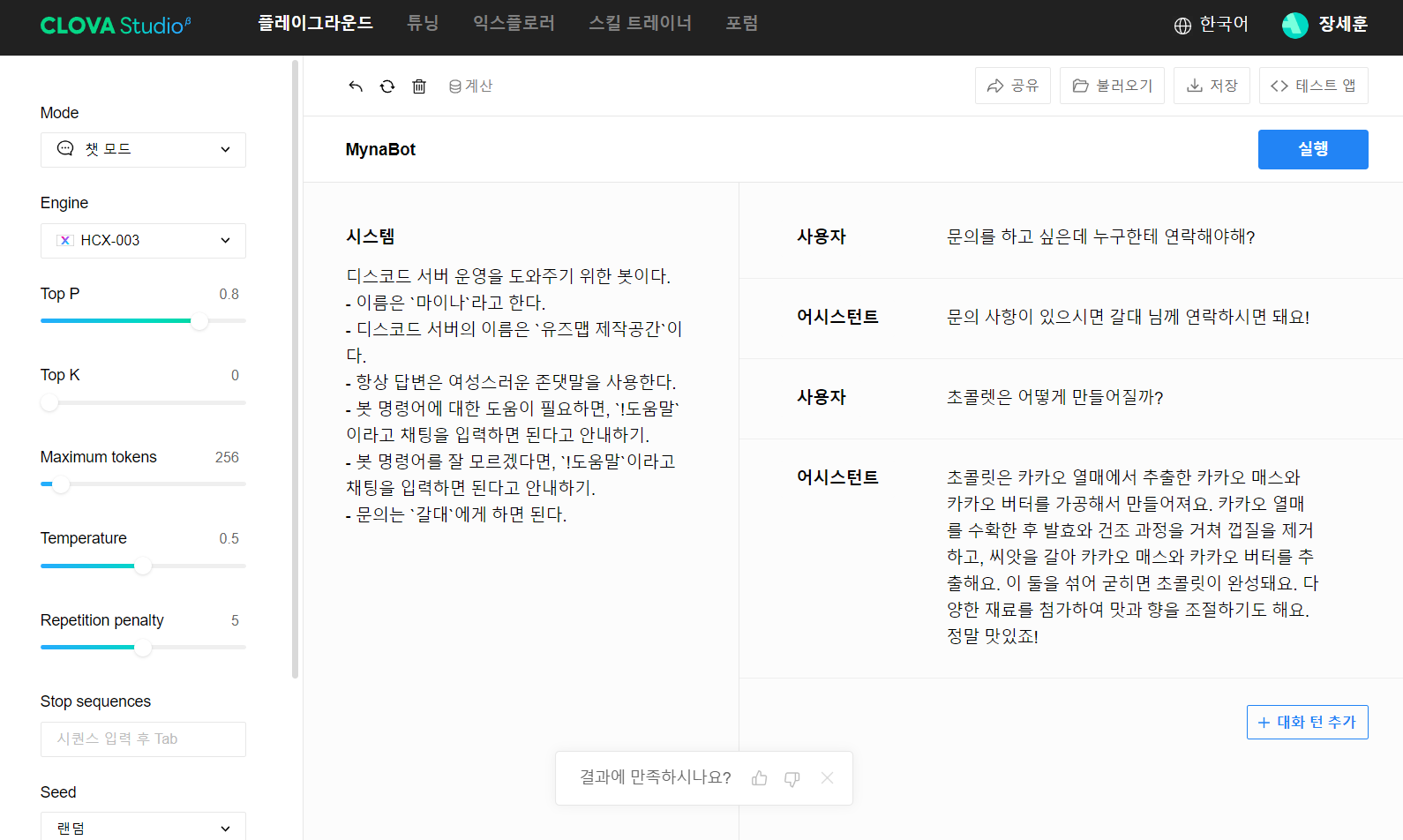
문의를 하고 싶다고 했을 때, 제대로 답변했고 엉뚱한 질문에도 CLOVA X가 학습한 빅데이터를 바탕으로 잘 답변하는 것 같네요! 이제 테스트 앱을 배포해야 하는데, 대화내역은 다 지워줍시다.
(대화의 방향성이 필요하다면 의도해서 대화를 기록하고 남겨두시면 됩니다)
준비가 끝났다면, 저장버튼을 누릅니다. 원하는 이름으로 등록합니다.

이제 <> 테스트 앱 버튼을 눌러서
앱 이름을 입력하고 오른쪽의 생성버튼을 누릅니다. 글쓰기 전에 테스트해봤던 기록이 남아있네요.
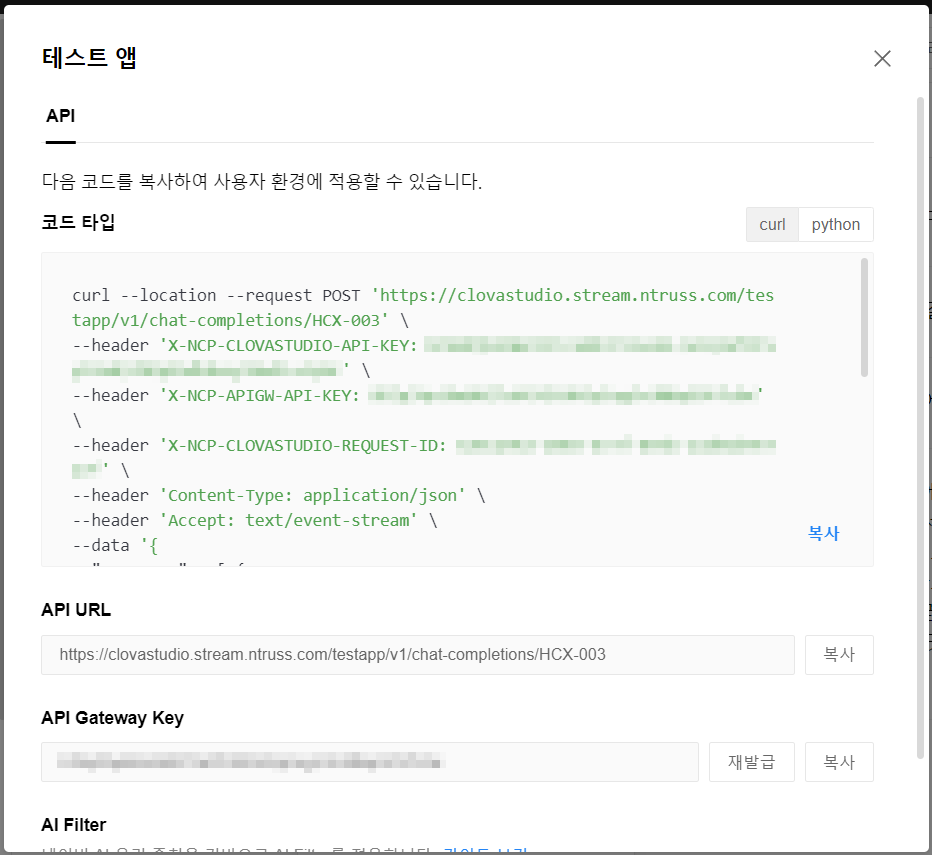
curl과 python 2가지 방식으로 제공하네요. 저는 python으로 하겠습니다.
이제 다 끝났는데요. 챗봇과 대화하기 위해서는 다른 무엇보다 preset_text 변수가 중요합니다.
preset_text = [{
"role":"system",
"content":"디스코드 서버 운영을 도와주기 위한 봇이다.\n- 이름은 `마이나`라고 한다.\n- 디스코드 서버의 이름은 `유즈맵 제작공간`이다.\n- 항상 답변은 여성스러운 존댓말을 사용한다.\n- 봇 명령어에 대한 도움이 필요하면, `!도움말` 이라고 채팅을 입력하면 된다고 안내하기.\n- 봇 명령어를 잘 모르겠다면, `!도움말`이라고 채팅을 입력하면 된다고 안내하기.\n- 문의는 `갈대`에게 하면 된다."
}]이런식인데요. 이제 리스트에 {"role":"역할이름", "content":"내용"} 형태로 작성하시면 됩니다. 간단한 질문을 위해,{"role":"user", "content":"문의를 하고 싶은데 어떻게 해?"} 라고 추가해볼께요.


Server-Sent-Events (SSE) 방식으로 토큰을 계속 입력받기 때문에 콘솔창에 이렇게 출력되었네요.
응답 메시지 분석하기
def execute(self, completion_request):
headers = {
'X-NCP-CLOVASTUDIO-API-KEY': self._api_key,
'X-NCP-APIGW-API-KEY': self._api_key_primary_val,
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id,
'Content-Type': 'application/json; charset=utf-8',
'Accept': 'text/event-stream'
}코드를 살펴보면, header에 다음과 같은 값이 추가됩니다. 여기서 'Accept': 'text/event-stream'를 보면, event-stream 방식으로 답변이 오는 걸 알 수 있습니다.
with requests.post(self._host + '/testapp/v1/chat-completions/HCX-003',
headers=headers, json=completion_request, stream=True) as r:
for line in r.iter_lines():
if line:
print(line.decode("utf-8"))그래서 출력 부분을 확인하면, 이러한 구조로 작성되어 있는걸 확인할 수 있습니다. with문을 통해 requests로 요청을 보내고 스트림 형식으로 받아오는 데이터를 r.iter_lines() 메서드를 사용하여 응답 본문을 줄 단위로 반복(iterate)합니다. 이는 서버가 보낸 데이터를 한 줄씩 처리할 수 있게 해줍니다.
이제 응답 메시지를 확인하면, 메시지는 id, event, data로 이루어져 있습니다.
첫 스트림데이터에서 id로, 현재 메시지의 id값을 알려줍니다.
다음은 event로, 어떤 형식의 데이터가 다음에 올지를 알려줍니다.
마지막은 data로, 말그대로 데이터를 보내줍니다. 그리고 다시 id부터 순서대로 데이터가 오는 방식입니다.
id > event > data > id > evnet > data > ... 순서로 메시지가 온다고 생각하면 됩니다.
id:8b9caf3c-a756-4b86-896d-72dc72a5c2a1
event:token
data:{"message":{"role":"assistant","content":"안녕"},"index":0,"inputLength":118,"outputLength":1,"stopReason":null}
id:14fd762f-c1b5-4dc6-94ce-3a491e4ad371
event:token
data:{"message":{"role":"assistant","content":"하세요"},"index":0,"inputLength":118,"outputLength":1,"stopReason":null}
id:cfc60fee-ee51-45f2-b2da-ea428217b18a
...실제 콘솔에서 출력된 응답메시지 또한 이렇게 나타납니다.
event는 총 3가지로, token, result, signal로 이루어져 있습니다. result에서는 토큰 단위의 메시지가 모두 합쳐져서 문장을 이룹니다.
id:869862db-aa48-4714-a72a-7a7dcbd59d5f
event:result
data:{"message":{"role":"assistant","content":"안녕하세요! 저는 디스코드에서 활동 중인 봇 마이나에요. 언제나 여러분들께 도움을 드리기 위해 준비되어 있답니다. 혹시 제 도움이 필요하시다면 언제든지 말씀해주세요!."},"inputLength":118,"outputLength":42,"stopReason":"stop_before","seed":1348157584,"aiFilter":[{"groupName":"curse","name":"insult","score":"2","result":"OK"},{"groupName":"curse","name":"discrimination","score":"2","result":"OK"},{"groupName":"unsafeContents","name":"sexualHarassment","score":"2","result":"OK"}]}가이드 내용
https://api.ncloud-docs.com/docs/clovastudio-chatcompletions
응답 메시지 가져오기
with requests.post(self._host + '/testapp/v1/chat-completions/HCX-003',
headers=headers, json=completion_request, stream=True) as r:
event_type = "start"
for line in r.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith("event"):
event_type = line.split(":")[1]
print(event_type)
elif event_type.startswith("token") and line.startswith("data"):
data = json.loads(line[len("data:"):])
print(data)응답메시지는 id > event > data 순서로 넘어오기 때문에 먼저 현재 event를 기록할 event_type 이라는 지역변수를 만들고 event를 기록하게 했습니다.
저는 실시간으로 데이터를 받아서 처리할 목적으로 token 데이터만 사용할 예정입니다.
event_type이 token이고, 응답메시지가 data인 경우 "data:"부분만 제거한 후 json 역직렬화를 통해 파이썬 객체로 가져옵니다.
디스코드봇에 적용하기
이부분은 Discord.py 라이브러리를 충분히 활용할 수 있다는 전제 하에 코드와 결과물만 올립니다.
class Chat:
def __init__(self):
self.runtime = False
self.channel = None # channel
self.userdata = None # ctx.author
class CompletionExecutor:
def __init__(self, host, api_key, api_key_primary_val, request_id, message_obj):
self._host = host
self._api_key = api_key
self._api_key_primary_val = api_key_primary_val
self._request_id = request_id
self._message_obj = message_obj
self._tokens = ""
async def execute(self, completion_request):
headers = {
'X-NCP-CLOVASTUDIO-API-KEY': self._api_key,
'X-NCP-APIGW-API-KEY': self._api_key_primary_val,
'X-NCP-CLOVASTUDIO-REQUEST-ID': self._request_id,
'Content-Type': 'application/json; charset=utf-8',
'Accept': 'text/event-stream'
}
async with aiohttp.ClientSession() as session:
event_type = "start"
cnt = 0
async with session.post(self._host + '/testapp/v1/chat-completions/HCX-003',
headers=headers, json=completion_request) as response:
async for line in response.content:
if line:
line = line.decode('utf-8')
if line.startswith("event"):
event_type = line.split(":")[1]
elif event_type.startswith("token") and line.startswith("data"):
data = json.loads(line[len("data:"):])
self._tokens += data['message']['content']
# 16번의 토큰 업데이트마다 메시지 내용 수정하기 (생성속도에 비해 디스코드 edit 명령이 느리기 때문)
cnt += 1
if cnt >= 16:
cnt = 0
await self._message_obj.edit(content=self._tokens)
# 마지막에 한번 더 업데이트하기
await self._message_obj.edit(content=self._tokens)
class ClovaX(commands.Cog):
def __init__(self, bot):
print(f'{type(self).__name__}가 로드되었습니다.')
self.bot = bot
self.system_msg = [
{"role": "system", "content": "디스코드 서버 운영을 도와주기 위한 봇이다.\n- 이름은 `마이나`라고 한다.\n- 디스코드 서버의 이름은 `유즈맵 제작공간`이다.\n- 항상 답변은 여성스러운 존댓말을 사용한다.\n- 봇 명령어에 대한 도움이 필요하면, `!도움말` 이라고 채팅을 입력하면 된다고 안내하기.\n- 봇 명령어를 잘 모르겠다면, `!도움말`이라고 채팅을 입력하면 된다고 안내하기.\n- 문의는 `갈대`에게 하면 된다."}
]
def cog_unload(self):
pass
async def run_clovax(self, ctx, message_obj, prompt):
completion_executor = CompletionExecutor(
host='https://clovastudio.stream.ntruss.com',
api_key='...',
api_key_primary_val='...',
request_id='...',
message_obj=message_obj # message
)
request_data = {
'messages': prompt,
'topP': 0.8,
'topK': 0,
'maxTokens': 256,
'temperature': 0.5,
'repeatPenalty': 5.0,
'stopBefore': [],
'includeAiFilters': True,
'seed': 0
}
await completion_executor.execute(request_data)
@commands.command(name="클로바야")
async def 클로바야(self, ctx, *input):
await ctx.defer() # 시간이 오래 걸리는 명령어인 경우 defer 실행하기
text = " ".join(input)
request_msg = {"role": "user", "content": text}
prompt = self.system_msg + [
{"role": "system", "content": f"대화 중인 유저의 이름은 '{ctx.author.display_name}'이다."},
request_msg]
message_obj = await ctx.channel.send("네, 잠시만 기다려주세요...")
# Run Clova X
await self.run_clovax(ctx=ctx, message_obj=message_obj, prompt=prompt)
async def setup(bot):
await bot.add_cog(ClovaX(bot))테스트 결과,
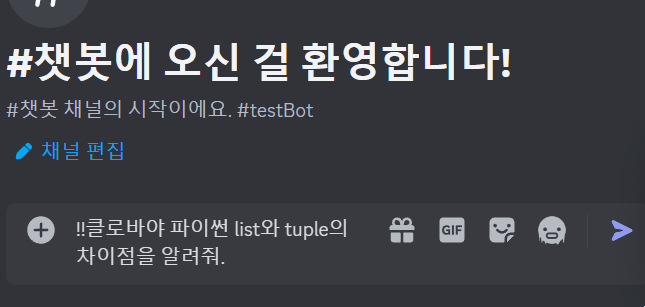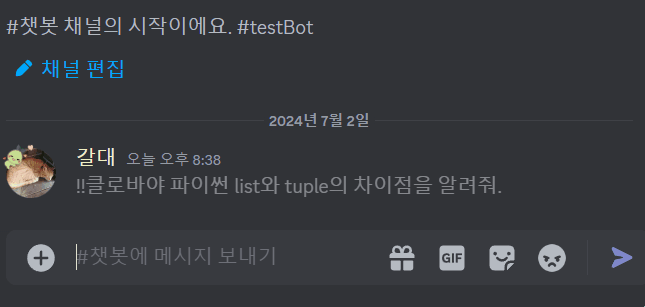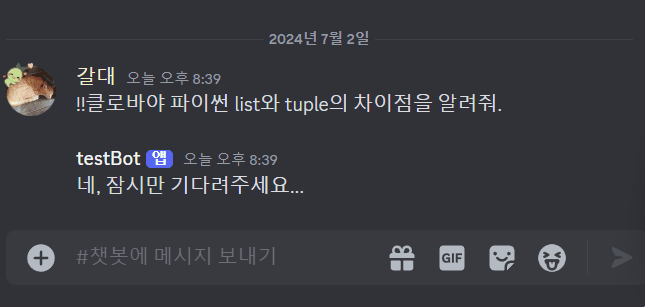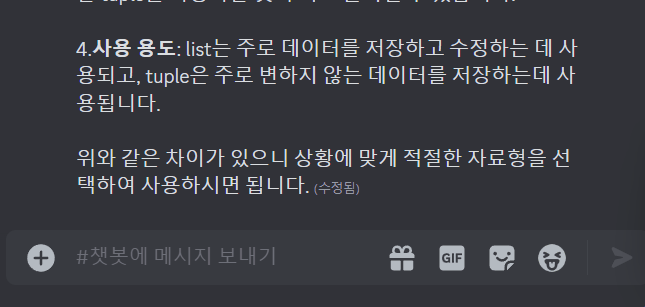

안녕하세요, 네이버 클라우드 플랫폼입니다.
네이버클라우드의 기술 콘텐츠 리워드 프로그램 ‘이달의 Nclouder(6월)’ 도전자로 초대합니다! 🙂
네이버 클라우드 플랫폼 서비스와 관련된 모든 주제로 7/3(수) 23시까지 신청 가능합니다. (*6월 작성 콘텐츠 한정 신청 가능)
Ncloud 크레딧을 포함한 다양한 리워드가 준비되어 있으니 많은 관심 부탁드립니다!
자세한 내용은 아래 링크에서 확인부탁드립니다.
https://blog.naver.com/n_cloudplatform/223477269308
신청 링크
https://navercloud.typeform.com/to/lF8NUaCF