클린 아키텍쳐. 코드를 짜다보면 한번쯤 만나는 아키텍쳐중 하나. 웹에 떠도는 여러가지 그림들과 설명들을 보다보면 정신이 아득해진다.
그래도 어찌어찌 파고들어가다보면 대략적인 구조가 보이는데, 서술하면 대략 이렇다.
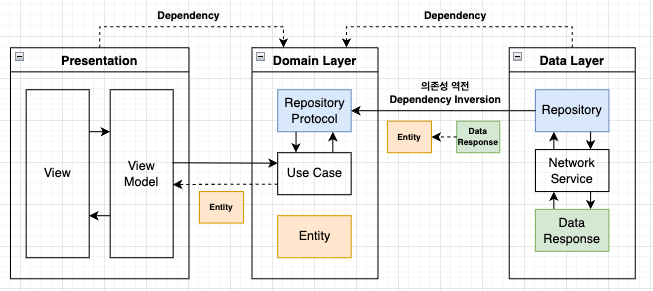
- Presentation Layer
- Data Layer
- Domain Layer
큰 틀로서 3계층의 레이어로 분류하고, 각각의 레이어가 독립적으로 동작이 가능해야하며, 정해진 역할을 수행하도록 분류하는 개념이다.
세밀하게 각 레이어의 역할을 서술하면...
Presentation Layer
구성요소
- View
- ViewModel
뷰 영역. UI와(View) UI를 제어하기 위한 코드를 포함하는 계층이다.
통상적으로 클린 아키텍쳐는 Mvvm UI 아키텍쳐 디자인 패턴과 함께 사용되는데, 여기서 V(View) 와 VM(ViewModel) 의 영역으로 볼 수 있다.
직접적으로 데이터를 획득하지는 않지만, 다른 레이어가 전달해준 데이터를 가지고 뷰가 표기되는것을 가정하여 구성해야한다.
Data Layer
구성요소
- Repository
- Data Mapper (response struct)
- Api Struct (network service)
직접적으로 데이터를 획득하는 레이어. 서비스 서버가 될수도 있고, 로컬 저장소가 될수도 있는 타겟을 대상으로 요청에 맞는 원본 데이터를 획득하는 역할.
어떠한 단일 목적(ex 유저 데이터획득, 로컬디비에서 데이터 획득)에 맞춰 클래스를 분류하며, 이런 클래스를 Repository 로 명명한다.
단, 이 Repository 는 Doamin Layer 에 있는 프로토콜을 기반으로 하며, 프로토콜을 일치시켜서 동일목적의 다른 Remote를 가진 Repository 를 생성할수도 있다.
- UserRepositoryOfServer : A 서버를 통한 유저데이터 획득
- UserRepositoryOfLocalDB : 로컬 DB에 저장되어있는 유저데이터 획득
각 Repository 가 구성되기 위해 필요한 프로토콜은 DomainLayer 에 위치해있으며, 이때문에 Domain Layer 와 의존성을 가진다.
획득한 데이터를 1차적으로 가지고있기 위해 Data Mapper 라는것도 존재하는데, 나같은경우 이걸 Response 나 DTO 와 같은 명명을 붙여서 사용중. 이 데이터를 획득한 초기 데이터로 볼 수 있다.
말은 복잡하지만, 실제로는 서버에서 획득한 정보(json 이라던가?)를 파싱하기위한 codable struct 라고 보면 된다.
Domain Layer
구성요소
- UseCase
- Repository Protocol
- Entity
흔히들 말하는 비지니스 로직을 포함하고있는 레이어. 획득한 데이터를 어떻게 가공할지에 대한 부분이 포함되어있다.
Data Layer 에서 획득한 정보를 재가공하여 어플리케이션에서 쓰는 데이터로 2차가공 하고, 이를 Entity 라고 명명해서 사용중.
UseCase 는 비지니스 로직 구성에 필요한 Repository 를 인자로 가지고, 뷰 모델이 호출할 수 있는 get형 함수를 포함한다. 2가지 이상의 Repository 를 통해 데이터를 획득하거나, 이 데이터를 조합해서 하나의 Entity 로 전환하는 등 의 작업이 이뤄진다.
UseCase 의 생성과 Repository Protocol
UseCase 는 자신이 필요한 데이터를 요청할때 Repository 를 통해 요청한다. 그런데 UseCase 는 Domain Layer 에 있고, Repository 는 Data Layer 의 영역에 위치해있다.
두 레이어 사이에 쌍방으로 의존성이 생겨버린다.
클린아키텍쳐에서는 이런 의존성 관리가 중요한데... 서로 맞물려버리면 매우 난감하다.
그래서 UseCase 는 A Repository 를 직접 참조하지 않고 생성자에서 자신이 가지고있는 Protocol 을 따르는 특정 클래스를 받아오도록 설계한다.
struct AEntity {
let string: String
}
protocol A_Repository_Protocol {
func getARepositoryData() -> AEntity
}
class AUseCase {
let aRepository: A_Repository_Protocol
init(aRepository: A_Repository_Protocol) {
self.aRepository = aRepository
}
}그리고 AUseCase 가 생성될때 DataLayer 에서 A_Repository_Ptorocol 을 따르는 repository 를 찾아서 주입하는식.
class ARepository: A_Repository_Protocol {
func getARepositoryData() -> AEntity {
...
}
}
let repo = ARepository()
let useCase = AUseCase(aRepository: repo)처음 구성할때는 이게 무슨 코드낭비(?) 인가 싶었는데, 적용해보면 느낌이 온다. usecase 가 특정 프로토콜을 따르는 모든 Repository를 받아낼 수 있기 때문에 Repository 의 교체가 자유롭다.
DataMapper 와 Entity
Data Layer 에서 서버와의 처리가 끝나고 DomainLayer 로 데이터를 넘겨줘야 할때. 이때 data mapper 를 그대로 넘겨주려면 또다시 Domain Layer 와 Data Layer 의 의존성이 쌍방으로 생겨버린다.
Data Layer 는 Domain Layer 에 있는 클래스들이 뭐가있는지 다 보이지만, Domain Layer 는 Data Layer 가 어떤 클래스를 가지고있는지 모르기때문.
그래서 DataMapper 를 Domain Layer 의 Entity 로 변환하는 작업이 필요하다.
struct AEntity {
let string: String
}
struct ADataMapper: Codable {
let responseString: String
func toDomain() -> AEntity {
return AEntity(string: responseString)
}
}이렇게 DataMapper 가 가져온 스트링을 Entity 로 전환하는 함수를 짜고...
class ARepository: A_Repository_Protocol {
func getARepositoryData() -> AEntity {
let dataMapper = ADataMapper(responseString: "server response")
return dataMapper.toDomain()
}
}프로토콜에 따라 Entity 로 전환한 데이터를 반환한다.
마무리
이 규칙에 맞춰서 코드를 짜다보면 간단한 코드조차 여러가지 클래스로 분할되어 이게 맞는지, 잘 쓰고있는건지 아리송해진다.
처음 도입시에는 이게 의미있는 작업인지 헛수고인지 판단하기 어려웠는데, 서버가 나중에 개발되는 프로잭트를 진행하게되자 이 구조가 빛을 보게되었다.
결국 앱에서 쓰게되는 Entity 는 서버가 주는 데이터를 그대로 쓰지 않는 경우가 비일비재하니까, 디자인에 맞춰 Entity 를 구상하고... 로딩시점에 맞춰 UseCase와 Repository Protocol 을 설계한다.
그리고 Repository는 테스트데이터를 1초정도 딜레이를 주고 리턴하는 식으로 합을 맞춰두면 서버가 오기전에 빠른속도로 프론트 작업을 완료할 수 있다.
그리고 서버가 완성되고 실제 통신코드를 작성해야할때 DataLayer 의 Repository 들을 서버데이터 획득이 가능하도록 짜맞추면 완성.
마무리2
웹에 떠도는 예제들은 이 아키텍쳐 구성을 맞추기위해 여러갈래의 폴더구조로 클래스를 분류하는데, 이럴경우 의존성을 지키는것이 생각보다 쉽지 않다.
폴더를 아무리 세밀하게 만들더라도 하나의 프로잭트 안에서 빌드되다보니 참조가 마구 꼬이는 현상이 발생했다. 프로토콜도 귀찮다는 이유로 하나 둘 작성하지 않게되고...(...나만 그런가)
이걸 방치하면 아키텍처는 커녕 오히려 더더욱 복잡한 코드만 양산하는 결과를 만들어낸다.
이 문제의 원인은 클래스간의 참조가 하나의 프로잭트 안에 담겨있기 때문이다.
그럼 각 레이어를 분리하면 어떨까?
서브모듈이라던가... 라이브러리 라던가... 워크스페이스를 이용한 방법이라던가?
여러가지를 검토하다가 Cocoapods 의 private cocoapod 를 채택. 이 방법으로 Data, Domain Layer 를 분류하고 메인 프로잭트 타겟에는 presentation layer 만 남기는 방법을 발견했다.
이건 다음 포스트에서...
