주제
데이터포털에서 데이터를 지능적으로 검색하기 위한 질의 처리 기술을 개발한다. 다양한 지식(knowledge)가 저장되어 있는 온톨로지로부터 사용자가 원하는 지식들을 효과적으로 검색하고 처리하는 기술을 개발한다.
ㅇㅇㄱ 교수님 지도아래
나 이외 2명의 팀원과 함께 진행함.
개념조사
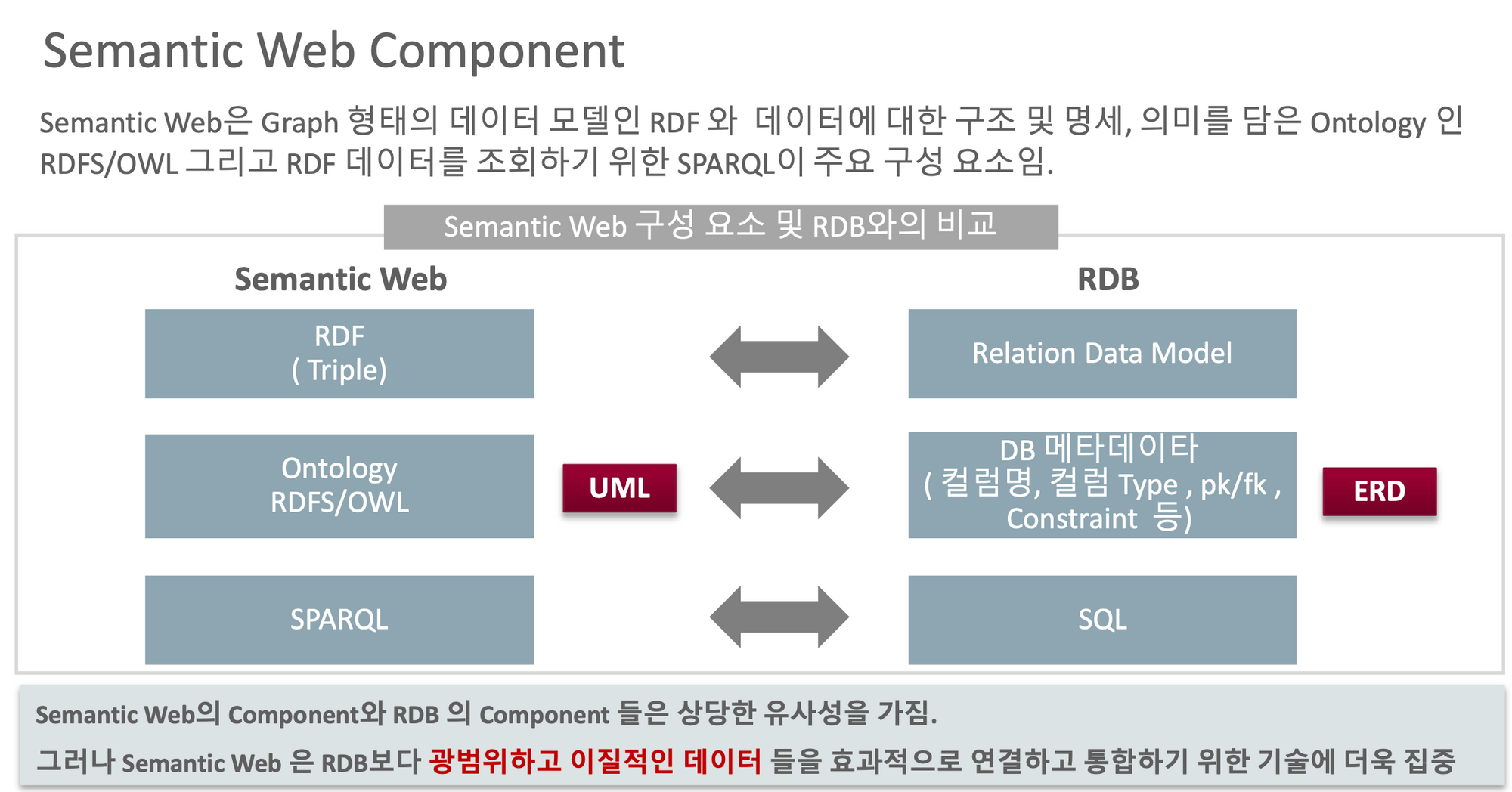
1. Semantic Web
History
- WEB의 문서는 HTML 문서를 통해서 정보를 전달한다.
- 하지만, HTML 문서는 사람을 대상으로 하였고, 다양한 자연어로 넘치는 이 문서를 컴퓨터는 이해하기 어렵다.
- 웹 상에 정보의 량이 방대해 짐에 따라 이로 인한 문제들이 많아졌다. (검색이 어렵다. 연관 관계를 표현하기가 어렵다.)
Definition
- 기계가 이해할 수 있는 웹으로 정보와 자원 사이의 관계-의미 정보(Semanteme)를 기계가 처리할 수 있는 온톨로지 형태로 표현하고, 이를 자동화하는 프레임워크이자 기술이다
- webs of data(ex. author, title, etc...)를 추구한다. ←W3C
- 컴퓨터와 인간간의 협업을 더 원활하게 하며, 의미를 잘 정의한 정보로 현재의 웹을 확장하는 것이다.
- Programmerable web
- 데이터에 의미를 부여하여, 사용자의 검색으로 부터 응답할 때에, 컴퓨터가 이를 살펴보고 따질 수 있는 WWW의 확장
- 이러한 생각은 Tim Berners Lee가 최초로 www를 제안했을 때부터 포함되었던 개념이다.
Benefits
- 풍부하고, 더 철학적인 웹 경험을 제공한다.
- 검색 엔진의 가독성과 순서매김을 향상시킬 수 있다.
- 데이터의 민주화 ⇒ 데이터 독점 우회
- 다양한 정보자원의 처리 자동화
구성요소
2. Ontology
온톨로지
온톨로지(Ontology)란 사람들이 세상에 대하여 보고 듣고 느끼고 생각하는 것에 대하여 서로 간의 토론을 통하여 합의를 이룬 바를, 개념적이고 컴퓨터에서 다룰 수 있는 형태로 표현한 모델로, 개념의 타입이나 사용상의 제약조건들을 명시적으로 정의한 기술이다.
온톨로지는 데이터베이스의 일종이라 할수 있는데, 이 데이터베이스에는 보통의 관계형 데이터베이스의 경우와는 달리 개념들 간 위계 구조와 기타 다른 관계 및 제약이 표현되어 있다.
온톨로지 공학(Ontology Engineering)이란 사람이 갖고 있는 각종 개념들을 이렇게 온톨로지화, 즉 데이터베이스화 하는 기술이다.
온톨로지가 되기 위한 조건
- formal : 일단 온톨로지는 formal(형식적인)해야 합니다. 사람의 개입없이 기계가 읽을 수 있는 언어로 작성되야 합니다.
- explicit : 온톨로지는 explicit(명백한)해야 합니다. 여러가지 뜻을 가진 단어를 상황에 맞는 뜻으로 해석할 수 있어야 합니다.
- shared : 가장 중요한 조건중에 하나입니다. 온톨로지를 만들었다고 해도 모든 사람들이 그 온톨로지를 사용하지 않는다면 쓸모가 없습니다. 온톨로지는 모든 사람(혹은 사물)들에게 shared(공유)되어야 합니다.
- conceptualization : 온톨로지는 표현하고자 하는 대상 세계의 개념들을 특정 모델로 추상화해야 합니다.
- domain : 온톨로지는 표현하고자하는 특정 영역이 존재합니다. 다른 영역의 객체까지는 표현하지 못합니다.
온톨로지 표현언어
1. RDF
RDF란
RDF는 (Resource Description Framework)의 약자로 URI를 갖는 모든 Resouce(웹 페이지, 이미지, 동영상 등)들의 속성, 특성, 관계 등을 기술(설명)하기 위한 모델, 언어, 문법
RDF는 그래프 방식의 데이터 모델입니다.

RDF는 두 자원(주어, 목적어)간의 관계를 표현한 것으로, 서술어는 이 관계의 특성, 특징을 설명합니다. 다음 그래프를 RDF 그래프라고 부르며 <주어> <서술어> <목적어> 구조의 문장을 트리플(Triple)이라고 부릅니다. 그리고 관계는 방향성을 가집니다.
RDF는 xml기반의 언어로 웹상의 분산된 다양한 자원들을 기술하고, 그 의미까지 표현하기 위해 개발되었다. 웹 언어라고하면 대표적으로 HTML이 있지만 이는 표현과 정보가 뒤섞여있기 때문에 단순 텍스트 정보만 추출이 가능하고 의미표현이 불가능한 단점이 있다. 텍스트정보만 추출가능하다고 하는것은 웹에서 검색기능이 제한된다는 것이다
→ home은 만들어졌다 kim에 의해.
RDF 문서들
-
Primer : RDF를 빠르게 사용하기 위한 기본 지식 제공
-
Concepts : RDF Concept, Abstract Syntax(RDF Graph)
-
Syntax : RDF 모델에 대한 XML Syntax(RDF/XML), N-triples
-
Semantics : RDF, RDF Schema 가 담고 있는 의미론, 추론 규칙에 대한 설명 https://www.w3.org/TR/rdf11-mt/
-
Vocabularies : RDF Schema와 RDF Vocabulary를 기술하는 방법
RDFS(스키마)
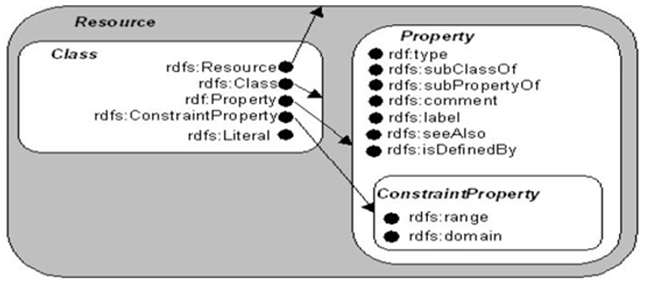
- RDF는 기존의 메타데이터, 즉 정보에 대한 정보만을 표현한다. 그렇기 때문에 RDF에서는 속성, 즉 데이터와 데이터의 정보 간의 관계에 대한 설명을 마음대로 만들 수 없다. RDF Schema(RDFs)는 이러한 속성을 필요에 따라 재정의 할 수 있도록 하는 체계를 제공한다. 즉, RDF를 도와 보다 자세한 구조를 짜고 관계를 설명할 수 있는 규칙을 제공하는 것이다.
- RDFs에서는 개념을 클래스로 정의하고 있으며 이 클래스는 상하관계를 갖는다. 속성은 표현하고자 하는 관계를 정의할 수 있으며 상하관계를 갖는다. 즉, 자원의 종류를 표시하고 그 관계를 정의하는 일이 RDFs의 역할인 것이다. RDFs에는 클래스와 속성의 유형과 활용에 대해 미리 정해진 몇 개의 어휘들이 있고 이를 통해 RDF 구문에 쓰이는 어휘 사이의 관계를 의미적으로 정의하게 된다.
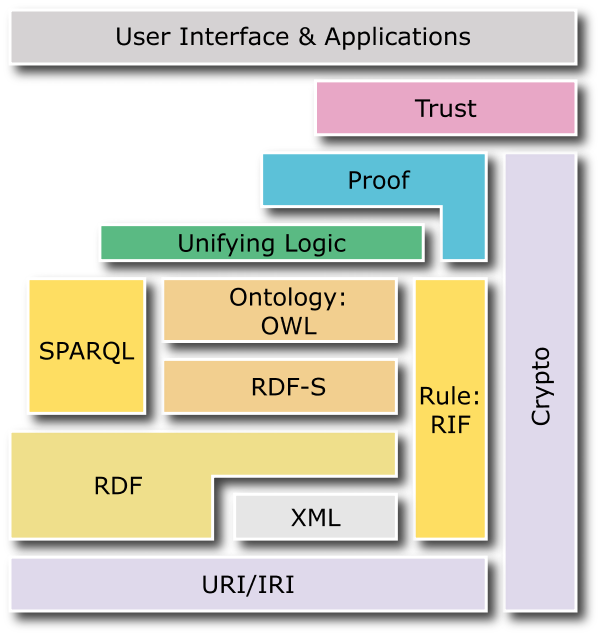
2. OWL (Web Ontology Language)
시맨틱 웹의 실현을 위해 데이터 표현 단계인 RDF를 보조하기 위한 온톨로지 언어
OWL은 문서에 포함된 정보를 어플리케이션을 이용하여 자동 처리하고자 할 때 활용하는 언어이다. OWL을 이용하면 임의의 어휘를 구성하는 용어(term)의 의미와 용어들 간의 관계를 명시적으로 표현할 수 있다. 이와 같이 용어와 용어들 간의 관계를 표현한 것을 온톨로지(Ontology)라 한다. OWL은 XML, RDF, RDF-S 보다 더 많은 의미 표현 수단을 제공하므로, 웹 상에서 기계가 해석할 수 있는 컨텐트를 작성하는데 있어 이들 언어보다 뛰어나다.
왜 OWL인가
- 기계가 정보를 처리할 수 있도록 하는 것이 온톨로지의 목표라 할 수 있다. 기계가 정보를 처리 할 수 있자면 기계가 정보를 읽고(machine readable) 이해(machine understandable) 할 수 있어야 한다. 온톨로지가 이를 위한 방법이라면 OWL은 이를 위한 도구이다. 기계가 정보를 읽고 이해할 수 있는 환경은 사용자 정의 태그 스키마를 정의할 수 있는 XML과 유연하게 데이터를 표현할 수 있는 RDF를 바탕으로 구축된다. 그런데 XML과 RDF는 조금 한계가 있다.
• XML은 문서를 구조적으로 표현할 수 있는 문법을 제공하지만 의미를 표현하는 방법은 제공하지 않는다.
• RDF는 정보(문서)와 정보 사이의 관계를 표현하는 데이터 모델로 정보의 간단한 의미를 표현하는 방법을 제공한다. 말 그대로 간단하다. 인간이 고개를 끄덕일 정도로 정보를 이해하지는 못한다는 말이다. 그래서 RDFs를 통해 정보의 속성과 클래스를 표현하여 의미 표현의 정도를 확장하고자 했지만 제약사항이 많다. 그래서 기계를 이용하여 웹 문서를 대상으로 유용한 추론 기능을 수행하려면 RDFs가 제공하는 기초적인 의미 표현력을 뛰어넘는 언어가 필요하게 되었고 OWL의 개발에 이르게 된 것이다. OWL은 속성과 클래스에 대하여 기술할 수 있는 더 많은 어휘를 제공한다.
OWL의 종류
OWL에는 표현력의 정도에 따라 Lite, DL, Full의 세 가지 하위 언어가 있다. 이름에서도 느껴지듯이 OWL Lite가 가장 낮은 표현력을 가지고 있는 것으로, 클래스 표현을 위한 규칙인 DL(Description Logic)(OWL의 형식적 기반이 된 논리학의 한 분야 )을 사용하지 못한다. OWL Lite는 계층적인 개념을 구조화하고 특정한 관계를 정의하는 수준이다. RDFs와 비슷하다고 할까? 따라서 OWL Lite는 이론적 복잡도가 낮기 때문에 유의어 사전이나 간단한 분류 체계 그리고 시소러스를 빠르고 손쉽게 OWL화하기 위한 용도로만 적합하다
3. Knowledge Graph
History
- Data가 많아짐에 따라, 의미를 이해하고, 부합하는 데이터를 조회하는 것에 대한 중요도가 높아지기 시작하며, Semantic search가 대두된다.
- 여기서 나아가 해당 데이터에 담긴 의미를 추출해내는 과정을 수행한다. (Store with Meaning, Data Mining)
- 이를 이제 지식의 형태로 저장하는 Ontology 방식이 나온다.
- 이를 분석하고, 기계학습에 이용하는 단계에 이르렀다.
Definition
Knowledge base로 이루어진 그래프 또는 사람이 기억으로 생성하고 활용하는 지식 정보를 Machine을 통해 좀 더 정확하고 많은 양의 지식 탐색을 하기 위한 기법을 가르킨다.
이를 위해 필요한 것
- 대용량의 데이터를 확보
- 데이터 개체의 의미를 파악 ⇒ 데이터는 ontology 형태여야 한다.
- 의미 있는 데이터 개체의 연결을 통한 정보화
- 정보의 연결성을 통한 새로운 아이디어 발견
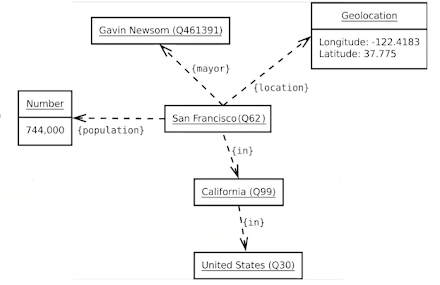
Perpose
사람의 기억으로 생성되는 지식 정보를 좀 더 많은 양으로 정확하게 탐색하기 위해 사용한다.
단순히 존재하는 데이터 block에서 값을 조회하는 것이 아닌 질의 자체의 의미를 파악하고, 그에 맞는 답을 검색하는 기술을 의미한다.
Example
오바마 대통령의 아내라고 검색 했을 때, 네이버는 "오바마"+"대통령"+"아내"를 포함하는 게시물을 검색한다면, 지식 그래프 기술을 활용한 구글은 이름이 오바마인 사람 중에 대통령인 사람의 아내를 찾아서 그 대상인 미셀 오바마를 검색하는 것이다.
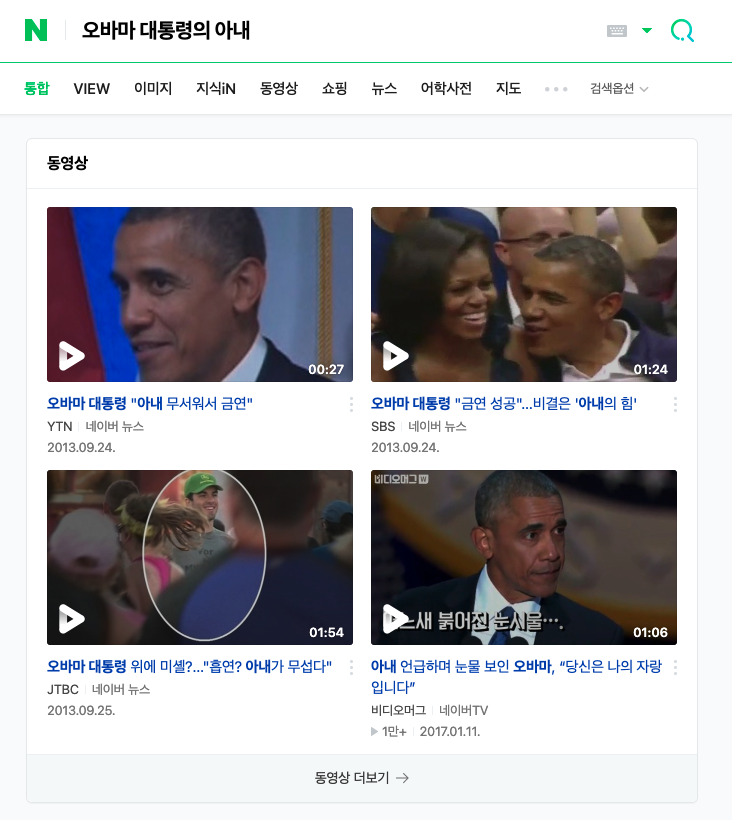
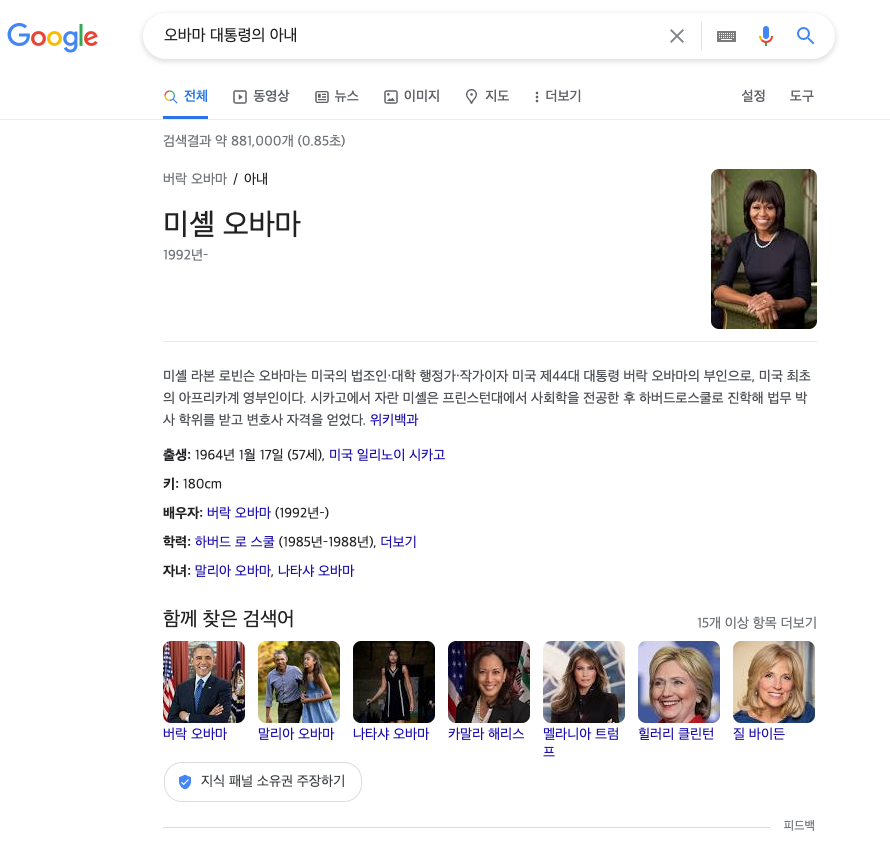
<그림 - 네이버와 구글에 각 각 검색한 내용>
성공적인 지식그래프는 다음을 만족합니다.
- Alive: 항상 최신의 지식을 유지한다.
- Scale Up : 재사용 가능한 데이터를 통한 확장을 수행한다.
- Automation : AI를 접목하여 자동화한다.
- Speed Up : 데이터를 통한 표준 마련의 가속화
4. Semantic query processing
- 시멘틱 질의 처리: 온톨로지를 기반으로 한 질의 처리이다. 트리플 형태의 RDF 데이터로부터 원하는 정보를 얻고자 할 때 사용한다. 질의 언어로는 RDQL, SPARQL 등이 있다. 기존의 질의 처리 프레임워크로는 Jena, Sesame 등이 있다. 시멘틱 질의 처리는 SPARQL 을 지원하는 사이트(정부의 오픈데이터 등) 또는 RDF 포맷을 지원하는 관계형 데이터베이스에서 사용할 수 있다.
- SPARQL: RDF/OWL 기반 시멘틱 웹 환경에서의 질의응답이 가능하도록 설계된 시멘틱 질의 언어이다. 테스트할수 있는 사이트 SPARQL 시작하기
- 디비피디아: 위키피디아 데이터에서 구조화된 정보를 RDF/OWL 형태로 추출하여 시멘틱 웹으로 접근 가능하도록 하는 프로젝트이다. 데이터는 주로 RDBMS 시스템으로 구현되어 있다. 실험시 데이터로 사용할 수 있을 것이다. 이 외에도 SPARQL 을 지원하는 사이트는 많음.
- Jena: 시멘틱 웹 어플리케이션을 구축하기 위한 자바 프레임워크, RDF/OWL 및 RDQL 을 지원하며 메모리 기반 시멘틱 모델을 통해 MySQL, Postgresql, Oracle 등의 데이터베이스에 온톨로지 문서를 저장한다.
- Sesame: RDF 를 위한 오픈소스 자바 프레임워크, 웹 인터페이스를 통해 온톨로지 문서를 관리한다.