구글 허밍버드(Google Hummingbird)
처음 소개된 것이 2013년 8월 경으로 알려져있는 허밍버드는 랭킹과 관련한 구글의 코어 알고리즘의 업데이트로서 검색자가 사용한 쿼리 의도를 더욱 정교하게 이해하고 이 의도에 관련성이 더 높은 콘텐츠를 매칭 시키기 위해 만들어졌다.
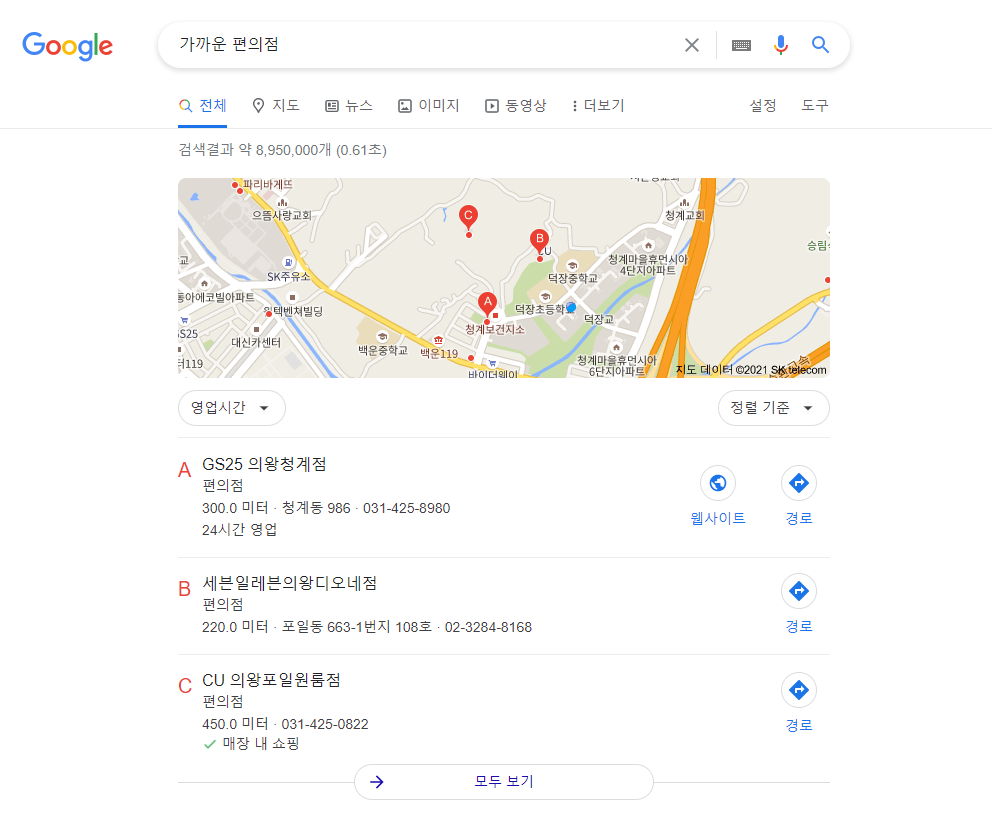
이렇게 출현한 허밍버드 이전의 구글 검색은 사전을 찾아보는 듯한 느낌을 주는 검색이었다면 허밍버드 이후의 구글은 자연스럽게 사람과 대화를 하는 것 같은 느낌을 주는 검색이 되었다. 예를 들어 “가까운 편의점” 이라고 검색을 했을 때 가까운 편의점이라는 사전적인 의미로만 검색결과를 보여주는 것이 아니라 아래의 실제 검색 결과에서 처럼 “나를 중심으로 가까운 편의점을 찾아줘”라는 말로 검색 의도를 이해하고 이에 대한 답을 시도하는 것이 허밍버드라고 할 수 있다.
허밍버드 업데이트 이후 구글의 검색어 구성은 단순한 단어들의 나열이 아니라, 의미를 가진 문장을 구성하는 일부로 이해되게 된 것이다. 그래서 이제는 검색 결과 상위라고 해서 타이틀에 검색 쿼리에 들어간 단어가 꼭 들어가는 것이 아니다. 오히려 쿼리 속의 단어가 전혀 들어가 있지 않아도 검색 의도에 부합하면 상위에 오게 되었다.
Hummingbird에는 스팸과 싸우기 위해 설계된 Panda , Penguin 및 Payday , 지역 결과를 개선하기 위해 설계된 Pigeon , 광고가 많은 페이지를 강등하도록 설계된 Top Heavy , 모바일 보상을 위해 설계된 Mobile Friendly 와 같이 SEO 공간 에서 친숙한 이름을 가진 다른 부분도 포함
구글 랭크브레인 (Google Rankbrain)
랭크 브레인은 기계학습을 사용하여 검색 엔진 쿼리와 가장 관련성이 높은 결과를 결정하는 구글의 핵심 알고리즘 구성 요소라고 할 수 있다. 랭크브레인은 프리랭크브렌인과 포스트 랭크브레인으로 구분할 수 있는데, 프리랭크브레인은 구글이 사전적으로 가지고 있는 검색 쿼리별로 검색 의도를 구분하는 로직에 의해 추정한 검색 의도를 기반으로 표시할 검색 결과를 결정하는 알고리즘이라고 할 수 있다. 포스트랭크브레인은 검색 결과 페이지에 게재된 검색 결과에 대해서 검색자들이 보인 다양한 반응을 바탕으로 검색자의 진정한 의도를 결정하는 해석모델을 통해 검색 결과를 조정해나가는 알고리즘이라고 할 수 있다.
랭크브레인이라는 것은 결국 검색자가 진정 원하는 것이 무엇인가를 검색자의 피드백을 통해서 특정해나가면 구글의 검색 결과를 검색자들의 의도에 더욱 관련성 높게 만들려는 구글의 노력이라고 할 수 있겠다.
랭크브레인은 기계 학습 측면에서 다른 업데이트와 차별이 되는데, 이것은 유용한 검색 결과를 생성하도록 랭크브레인 알고리즘을 교육하려고 다양한 소스에서 데이터를 확보하여 공급한다. 이렇게 공급한 데이터를 바탕으로 프리랭크브레인의 결과를 생성하고 이에 대해서 검색자들이 보내주는 피드백 시그널을 포스트랭크브레인에 던져 결과를 개선해나가는 것이다. 이런 특성 때문에 랭크 브레인에 의한 결과는 같은 국가 같은 지역이라도 같은 쿼리에 대해서 시간에 따라 다른 결과를 보여줄 수 있다.
예를 들어보면, “MAC”이라는 키워드로 검색을 했을 때 이 검색의 진정한 의도는 무엇일까? 이것이 여성 화장품 브랜드 M.A.C을 찾는 것일까? 아니면 애플의 Mac 컴퓨터를 찾는 것일까? 혹은 MacOS를 찾는 것일까? 이 검색 쿼리에 답하려고 할 때 구글이 콘텐츠 품질이나 백링크와 관련한 정보만 활용한다면 특정 프로모션이나 PR활동으로 백링크를 많이 획득한 쪽의 콘텐츠가 검색 결과의 상위를 모두 차지하게 될 것이다. 바로 이런 경우에서 랭크브레인만이 가진 특징이 발휘되는데, 구글의 머신러닝 알고리즘 랭크브레인은 어느 것을 우선해야하는가를 검색자의 행동에서 인식한 패턴을 기반으로 보다 만족스러워할 검색 결과를 예측한다.
다른 예를 들어보면 한국에서 “가장 최근의 올림픽 개최지”라고 검색했을 때 어떤 답을 보여주는가? 2016년 하계 올림픽 개최지였던 리오 데 자네이로를 보여주는 것이 맞을까? 아니면 2020년 하계 올림픽 개최 예정지였던 도쿄가 맞을까? 아니면 2018년 동계 올림픽 개최지였던 평창이 맞을까? 이에 대해서 구글의 현재 검색 결과는 검색 결과 최상단에 리오 데 자네이로의 지도와 지역 관련 사진을 보여주고 검색 결과 1위에 위키피디아의 올림픽 항목을 그리고 2위에 동계 올림픽에 대한 위키피디아 페이지를 보여주고 있다. 이런 검색 결과의 구성에 검색자들의 행동 시그널을 적극 활용하는 것이 바로 랭크브레인이다.
RankBrain은 Google의 전체 검색 알고리즘(Hummingbird)의 일부
구글 버트 (Google BERT)
버트는 가장 최근에 구글 알고리즘에 포함된 요소이면서 최근에 가장 주목 받는 업데이트이다. 이미 구글은 버트 업데이트 때문에 SEO 측면에서 뭔가 달라질 것은 없다고 이미 말하고 있지만 업계 안에서는 상당한 소란이 있을 정도로 관심을 불러 일으켰다.
구글의 알고리즘에 포함되기 이전에 버트는 엔티티 인식, 감정 분석, 질문과 답변 등 자연어 처리(NLP) 분야의 다양한 개별 솔루션들을 모두 합친 지금 단계에서는 가장 완벽하다고 평가 받고, 그 성능 때문에 주목 받고 있는 사전 훈련된 비지도 자연어 처리 모델로 자연어 처리계의 완벽한 종합 선물 세트라고 할 수 있다. 그리고 구글은 이 버트를 자신들의 검색 알고리즘에 포함시킨 것이다.
구글은 이렇게 구글의 알고리즘에 포함시킨 버트가 제 구실을 하게 하기 위해 많은 텍스트 데이터들을 학습시켰다. 예를 들어 엄청난 컴퓨팅 파워와 돈을 사용해서 위키피디아의 모든 텍스트를 학습시켰다. 버트가 포함된 구글의 큰 특징은 아래와 같이 단어의 순서만 다를 뿐 같은 단어로 구성된 두 문장이 사실은 서로 다른 뜻을 가지고 있을 때 그 두 문장을 차이를 제대로 이해하고 검색 결과를 만들어낼 수 있게 되었다는 점이다.
예시문장1: does us citizen need visa for Korea?예시문장2: does Korea citizen need visa for US?
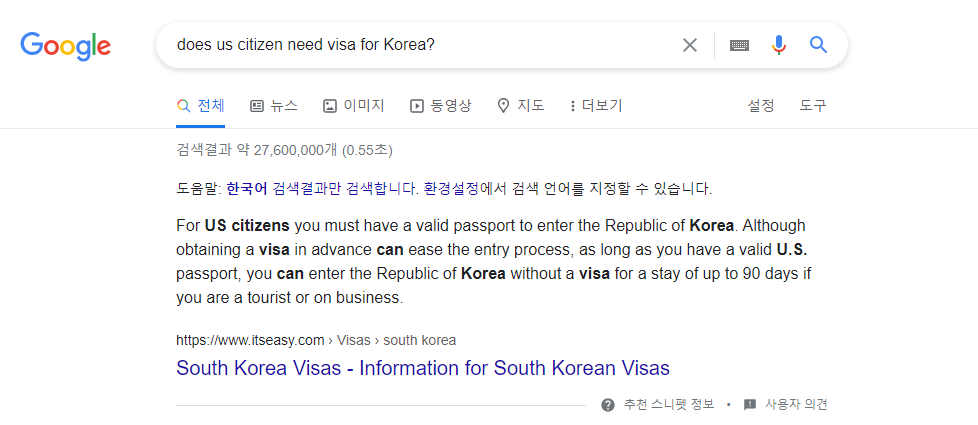
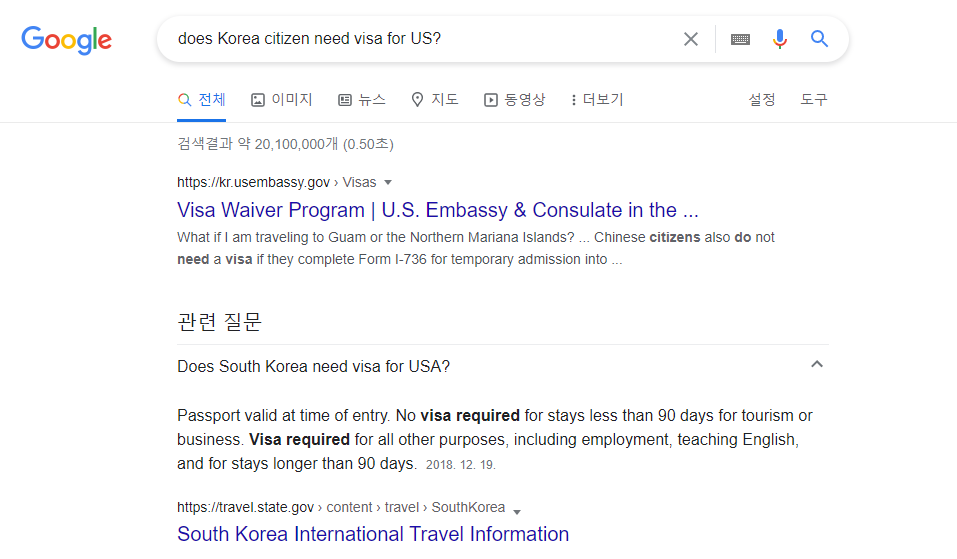
버트, 랭크브레인을 포함해서 최근 검색 알고리즘 업데이트의 큰 맥락은 허밍버드 이후 계속해서 강조되어오던 것 처럼 검색자 의도에 잘 대응하는 포괄적이고 심도있는 콘텐츠를 지속적으로 제작하는 것이 유일하게 신경써야할 부분이라 할 수 있다.
Intelligent Search vs Semantic Search Example
기본적으로 input으로 주어지는 데이터의 의미를 이해하는 것과 가지고 있는 데이터의 의미를 이해하는 것에서 그치는 semantic search와 intelligent search는 여러 가지 차이가 있다. intelligent search는 수집된 의미를 기반으로 더 많은 작업을 수행한다. 여기서 나아가서 기존 문서를 metadata 기반에서 더 뛰어넘은 분석이 가능하며, 머신러닝을 통해 이전 검색보다 더 나은 결과를 유추할 수 있다. 또한, 해당 데이터의 우선 순위를 매기고, 필터링을 수행하는 것까지 가능해진다. 이를 기반으로 특정 카테고리로 데이터를 구분하는 것까지 수행하며 더 많은 것을 가능하게 한다.
1. Auto complete (자동 완성)

→ semantic search : semantic search는 해당 단어와의 연관성이 있는 단어를 찾음으로서 자동완성을 지원할 수 있다. 하지만, 이것이 실제로 유저들에게 필요한 정보인지는 고려하지 못한다.
→ intelligent search : 위의 그림에서도 볼 수 있듯이 "자동 오"까지만 작성했을 때, "자동 오"를 포함한 데이터 중에서도 가장 많이 검색되거나 내가 최근에 검색했던 단어와 연관이 있는 데이터를 우선으로 제시하는 것이 가능하다.
2. 오타 수정
→ semantic search : 특정 단어와 단어 사이의 연관성을 유추하는 Semantic search는 오타를 스스로 수정할 수 없다.
→ intelligent search : 다수의 사람들이 실수하는 패턴 등을 기반으로 하여, 유사한 단어를 찾을 수 있다. 또한, 특정 개인이 자주 실수하는 맞춤법에 대하여 비교대조를 통해 이를 바로 잡는 것도 가능하다.
3. 이미지 검색 (구글에서 제공하는 서비스)
→ semantic search : 이미지 input을 처리할 수 있는 방법은 동일한 metadata를 포함하는지 여부를 통해서 가능하다.
→ intelligent search : 해당 이미지를 특정 class로 분류하고 이를 바탕으로 검색을 수행할 수 있다. input이미지로부터 유의미한 데이터를 추출하고, 이를 기반으로 검색을 수행할 수 있다.
-
네이버 딥러닝 이용 이미지 검색
이미지가 의미하는 대상이 뭔지까지 알아냄
4. direct result (구글에서 제공하는 서비스)
⇒ 유용할 거 같은 정보가 있는 사이트를 제공할 뿐만 아니라, 해당 페이지의 결과물을 바로 출력.
⇒ ex. 구글에서는 영화 정보를 검색 시에 검색자의 위치 정보를 활용하여 라이센스를 보유한 사용자 인근의 영화관의 상영정보를 바로 제공합니다.
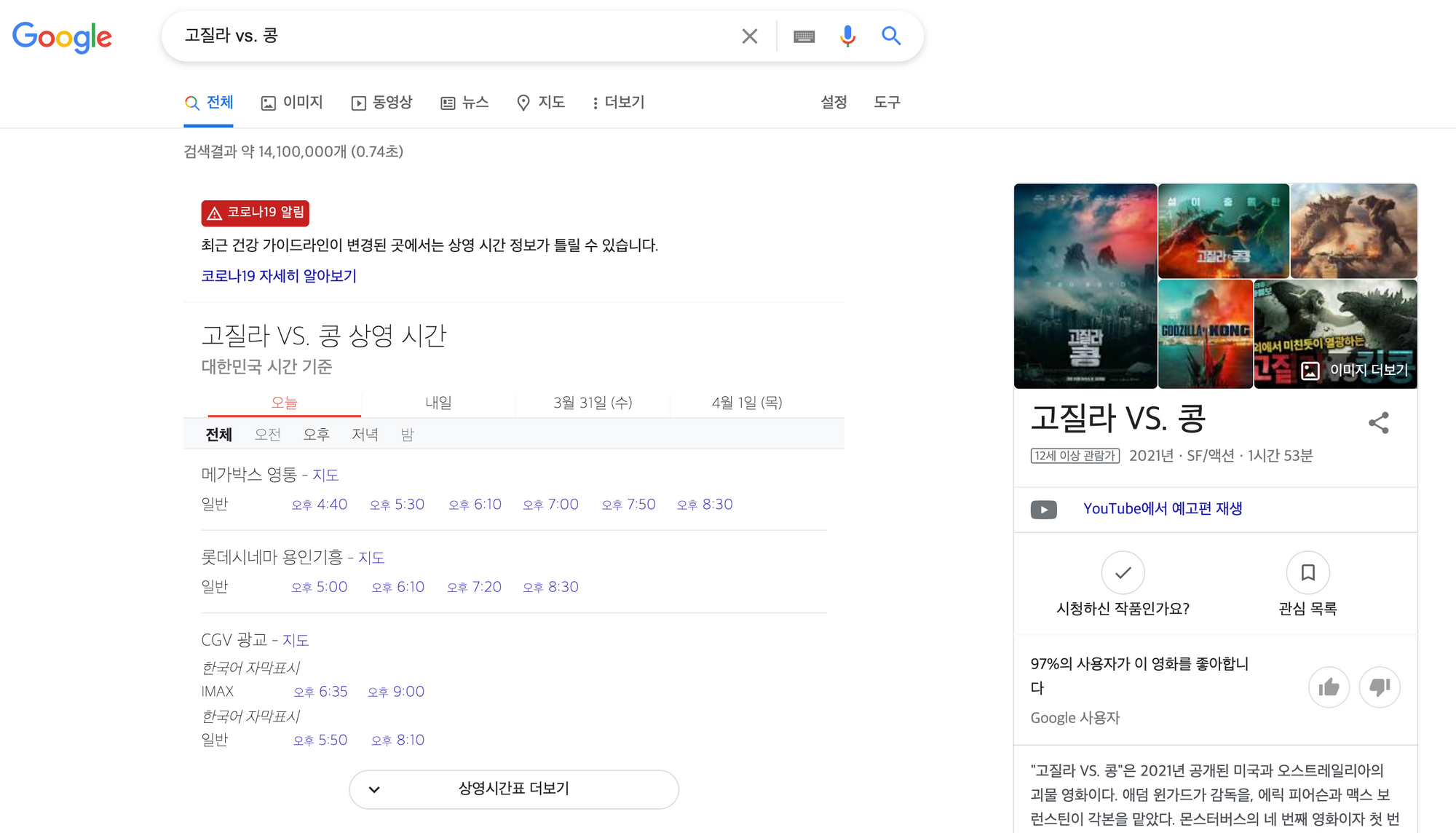
5. 추천 스니펫 (구글에서 제공하는 서비스)
⇒ 특정 문서의 링크를 먼저 제공하는 것이 아닌 구글이 찾은 해당 물음에 대한 결론을 먼저 제시합니다.
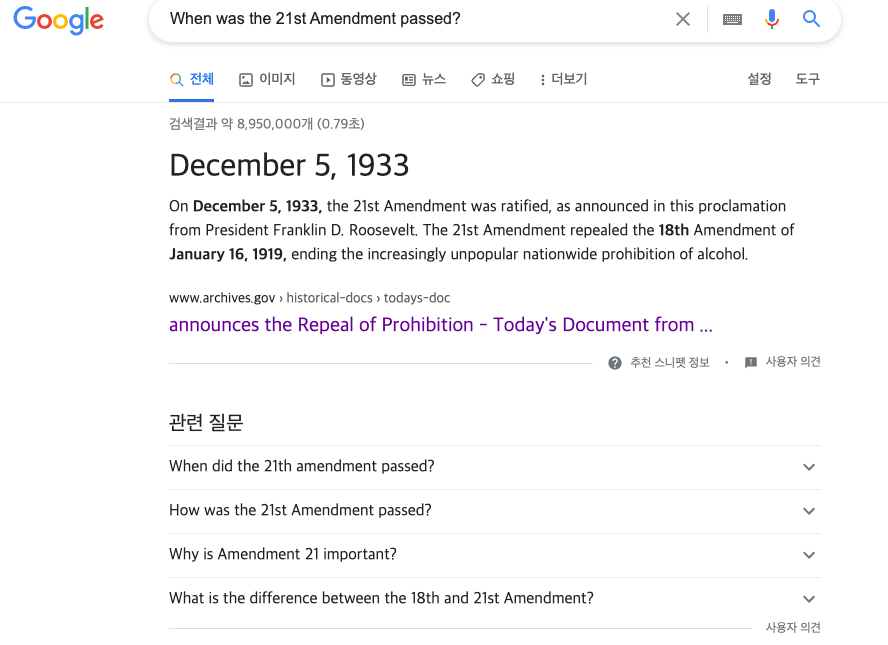
→ semantic search : 메타데이터를 기반으로 단지 링크의 정보를 제공하는 semantic search에서는 특정 문서의 특정 부분을 scrap해서 결과를 가져오는 것은 힘들다.
→ intelligent search : 특정 문서 전체를 분석하고, 이를 기반으로 더 적절한 데이터를 선별하는 지능형 검색에서는 특정 문서의 질문에 대한 답을 찾을 수 있다.
6. 길찾기 (길 검색) (구글에서 제공하는 서비스)
특정 위치를 검색할 경우, 길을 찾는 방법을 제공한다.
→ semantic search : 단지, 해당 위치 정보와 관련된 정보를 제공하며, 연관된 정보를 제공한다. 해당 단어의 정의와 같은 것을 제공한다.
→ intelligent search : 영통역을 검색했을 때, 가장 필요로 하는 정보는 영통역의 정의와 같은 것이 우선이 되지 않는다. 해당 영통역의 위치와 전철이 언제 출발하느냐가 중요한 정보가 된다. 이를 판단하고, 영통역을 검색한 것 만으로도 제공한다.
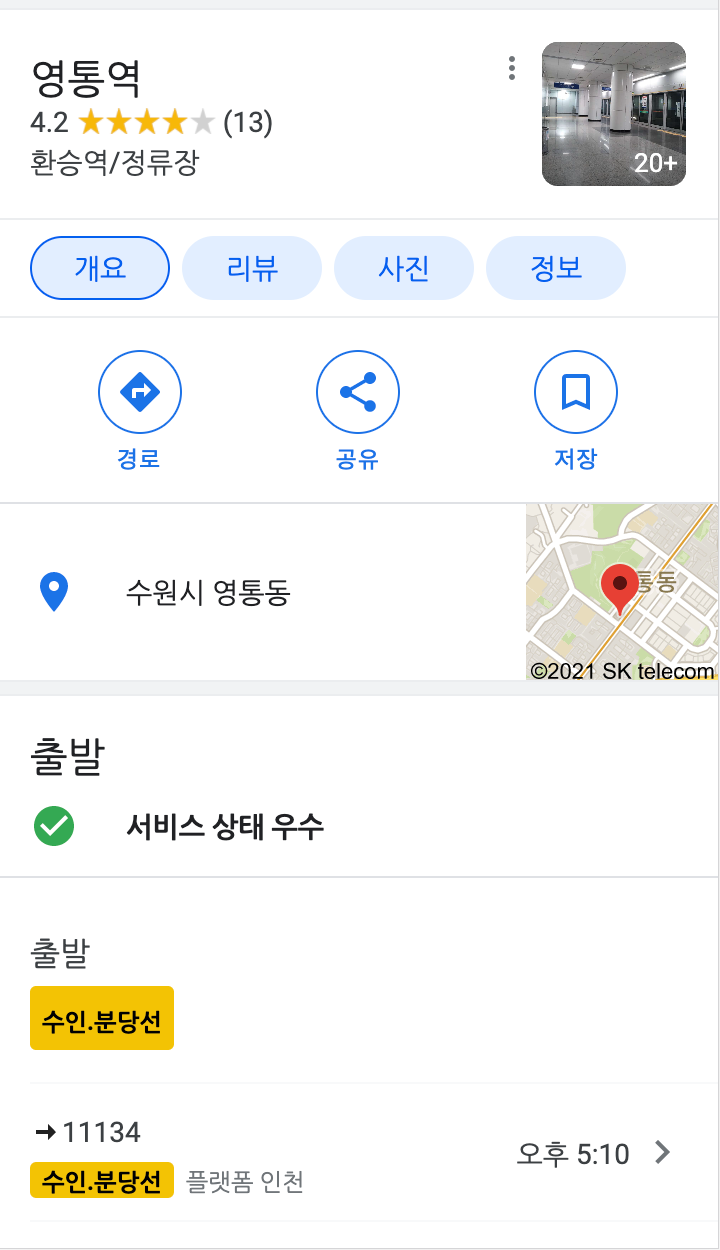
7. 목록 조회 (구글에서 제공하는 서비스)
가장 유명한 여성 우주비행사에 대한 검색 시에 다음과 같은 리스트를 제공할 수 있다. 단일 대상을 지칭하지 않는 물음에 대한 처리를 제공한다.
-
리스트를 제공
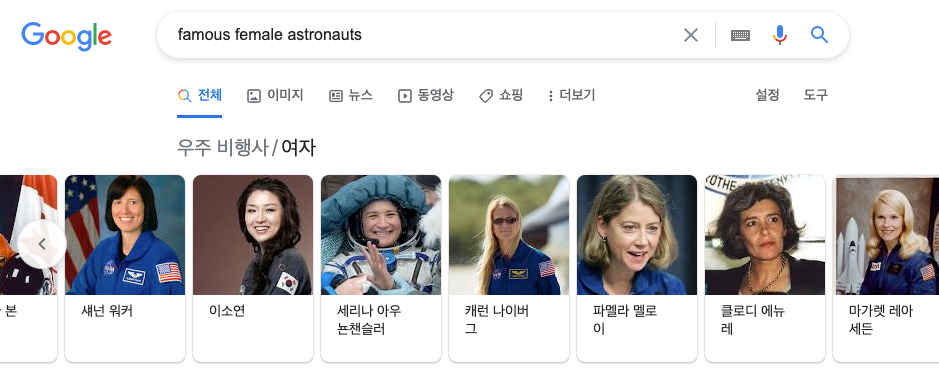
8. 추천 시스템
main과 같은 페이지 또는 최상단에 노출되는 정보에 대한 우선순위를 지정하는 시스템은 공급자와 소비자를 연결하는 플랫폼에서 가장 중요한 시스템이다. (ex. youtube 추천 알고리즘)
→ semantic search : 사용자의 history만이 주어졌을 때, 단지 이와 연관된 문서를 제공해줄 수 있다.
→ intelligent search : 사용자의 history와 다른 유저들의 history를 분석하고, 이를 기반으로 현재 트렌드와 사용자의 지속적인 변경 사항에 대한 처리를 수행할 수 있다.
