
시스템 콜(System call)
시스템 콜을 다시 정리해보면, 멀티 유저 시스템에서 한 프로세스가 다른 프로세스에 I/O로 함부로 접근하여 데이터를 망치는 일을 사전방지(prevent)하고자 시스템에 허락을 받는 매커니즘임.
그렇다면, 시스템 콜은 정확히 언제 일어나는 것인가?
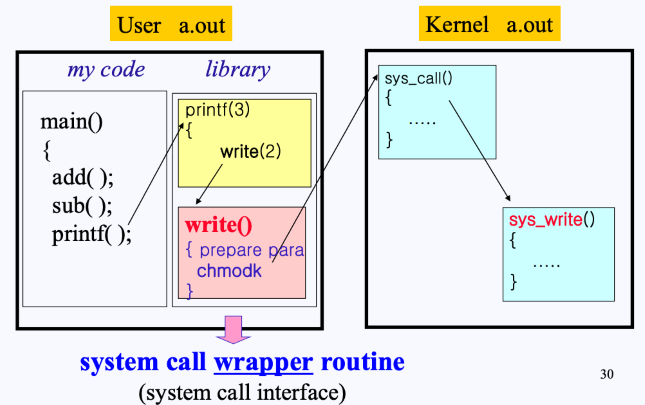
참고:
- 리눅스 명령어는 옆에 붙은 숫자에 따라 (1) Commands, (2) System call, (3) library functions 을 구분할 수 있음
- 이때, 모든 system call function은
sys_로 시작함
위 그림에서 User의 소스를 보면, 함수 안에 add(), sub() 뒤에 printf() 함수가 어떤 순서로 처리되는지를 확인해보자.
- 해당 함수
printf()는 라이브러리(3) 내부에 구현되어 있는 곳으로 가게 됨. printf()는 I/O를 위한 함수이므로,write()라는 Wrapper Routine 시스템 콜을 호출하여 작업을 요청하게 됨.- Wrapper Routine에는 prepare parameter(왜 커널로 가게 되는지 알려주는 정보를 담고 있음)와 chmodk가 들어있음
- 즉, Wrapper Routine은 트랩으로 넘어갈 내용들을 준비하고, 실질적으로 트랩을 일으키는 공간임
- 이후 프로그램은 trap에 걸려 커널 영역으로 가게 되며, 커널 내부에 존재하는
sys_write()함수가 호출되게 됨.
Wrapper Routine

Wrapper Routine에선 트랩을 일으키기 전에 Prepare parameter들을 준비하게 되는데, 그 중 가장 중요한 것이 system call number임
- ** system call number: 커널이 가지고 있는 system call function의 시작 주소를 담고있는 Array의 Index번호
- system call number는 컴파일러와 서로 합의된 규칙하에 적용이 됨
이후 int $0x80과 같이 의미없는 문자들을 이용해 Machine Instruction을 주어 트랩을 유발시킴
- 그림에서 나오는
int $0x80는 x86 기준임
트랩이 걸린 후에는 커널이 system call number을 가지고 system call function table에 접근해 function의 시작 주소에 접근하게 됨
Kernel System Call Function
커널에서는 유저가 원하는 요청에 대한 반환 값을을 시스템 콜을 호출한 유저 영역으로 넘겨줘야 한다. 따라서 떄로는 커널이 유저 영역으로부터 데이터를 가져와야 하는 경우도 있음.
- 이러한 기능들은 오직 커널만이 가지고 있음(오직 커널만이 모든 메모리 영역에 접근이 가능함)
chmodk가 호출되면 비트 모드가 Kernel 모드로 바뀌며, 독립된 커널 프로그램이 수행됨.- 다음 그림처럼 이러한 것에 필요한 함수들도 다 구현이 되어 있음
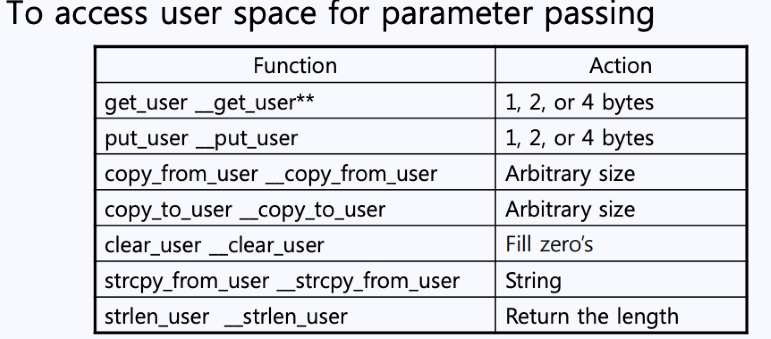
나만의 새로운 System call 작성에 대하여
내가 직접 시스템 콜을 직접 만들어 사용한다면, 심플하게 구현할 수 있으며 기존 시스템콜보다 좋은 성능을 보일 수는 있음
- 그러나, 해당하는 시스템 콜만의 새로운 system call number를 정의해야 되며, 이 떄문에 해당 프로그램은 플랫폼에 의존적이게 됨
- 또한 한 번 만든 시스템 콜은 변경이 불가능하기 때문에 수정을 할 수 없는 문제도 있음
대신 기존에 있던 시스템 콜인 read나 write, ioctl 등에 있는 fd(file descriptor)를 이용하는 방법이 있음
- fd란, 운영체제가 만든 파일이나 소켓을 편하게 부르기 위해서 부여하는 0과 음수가 아닌 정수값임. (프로세스가 파일들에 접근할 땐 이 fd를 사용하게 됨)
- fd는 보통 적은 숫자만이 활용되고 있음. 따라서 잘 쓰지 않는 999와 같은 번호에 본인의 fd를 지정하고 사용하면, 훨씬 안전하게 로직을 수행할 수 있게 됨
프로세스 매니지먼트(Process Management)

- 위 그림에서 분홍색 부분이 커널임.
- 커널이 1차적으로 해야하는 일은 하드웨어를 관리하는 일임(CPU, Memory, disk, tty 등의 하드웨어 자원들을 세팅함)
- 1차적인 업무가 끝나면, 그 이후에 유저 프로그램들을 support하게 됨
이렇듯 커널은 효율적인 하드웨어 관리와 유저 프로그램을 지원하기 위해 다음과 같이 자체적인 Internal Data Structure을 가지고 있음.
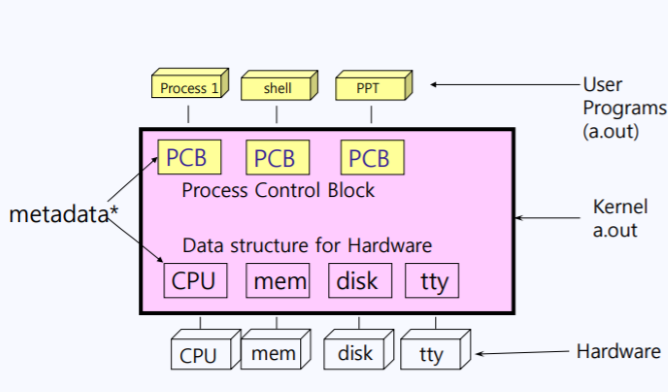
- Data Structure에는 (우선) 각 하드웨어에 대한 정보가 담겨있음
- ex) 위 그림에서
mem에는 메모리의 총 크기가 어느정도이며, 어디서부터 어디까지 사용되고 있는지 등에 대한 정보가 담겨있음
- ex) 위 그림에서
- 또한 Data Structure에는 프로세스들을 관리하기 위한 PCB(Process Control Block)도 가지고 있음
- 위 두 Data Structure들을 합하여 메타데이터라고 부름
PCB(Process Control Block)
프로세스를 관리하기 위한 PCB에는 다음과 같은 정보들이 들어가있음.
- 해당 프로세스의 PID(프로세스 식별자)
- 프로세스의 우선순위
- 대기 현상(입출력 작업 시 waiting이 일어날 수 있음)
- 프로세스 상태(run, sleep)
- 프로세스가 어디에 올라와 있는지(메모리, disk)
- 열린 파일들
- 유닉스에서는 모든게 파일임.
- 이때, 파일은 Sequenct of bytes임
- I/O조차 파일로 간주됨
- 현재 프로세스가 실행되고 있는 환경에 대한 정보
- 터미널
- 상태 벡터 저장 공간(state vector save area)
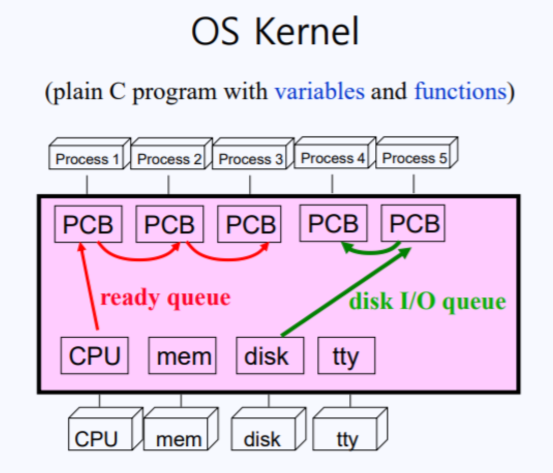
- 만약 프로세스 A가 CPU를 사용하다가 디스크로 갔는데, 디스크가 먼저 들어온 일을 처리하고 있으면 waiting을 신청하고 대기열(waiting queue)에 들어가서 기다리게 됨.
- waiting queue 중 cpu에 링크를 걸어두고 기다리는 것을 ready queue라고 부르며, 디스크에 링크를 걸어두고 기다리는 것을 disk wait queue(혹은 Disk I/O queue)라고 부름
- 이때 A는 점유하던 CPU를 다른 프로세스에게 주게 되고, A가 하던 작업의 내용을 A의 PCB에 저장하게 됨.
- 이 저장 공간을 상태 벡터 저장 공간(state vector save area)라고 부름(즉, 프로세스의 상태들을 저장한다고 보면 됨)
- 만약 프로세스 A가 CPU를 사용하다가 디스크로 갔는데, 디스크가 먼저 들어온 일을 처리하고 있으면 waiting을 신청하고 대기열(waiting queue)에 들어가서 기다리게 됨.
Child process 생성
컴퓨터를 키면 제일 먼저 Kernel process가 로드됨. 그리고 이 커널은 터미널이 켜질 때 마다 그에 해당하는 Shell 즉, Child Process를 만듦.
- ** shell: 많은 프로그램들(Utility)들이 disk로부터 언제 올라오고, 언제 내려가는지 등을 컨트롤하는 프로그램(Job(command) Control)
Child Process를 생성하기 위한 과정들은 다음과 같음.
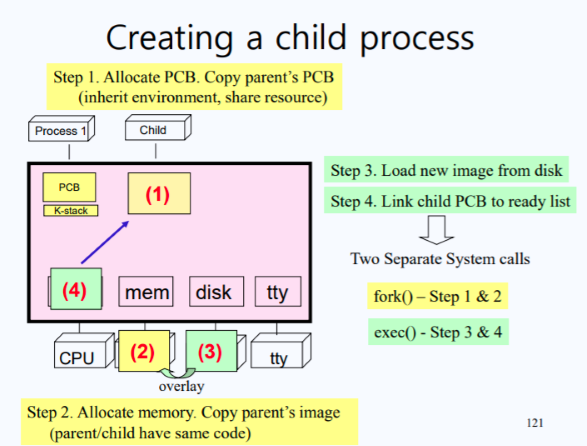
-
PCB 공간을 만들어 주고, 초기 값으로 Parent Process의 PCB 값을 복사해옴
- Parent가 사용하던 Resource들을 자식도 공유함(Parent Process의 실행 환경이 Child Process의 실행 환경이 됨)
-
Child Process가 올라올 메모리 공간을 확보함
- 이를 위해 커널은 Memory의 Data Structure에 가서 빈 공간을 찾아 지정해줌
- 이때, 빈 공간에 Child Process를 올리기 전에 먼저 Parent Process의 image를 똑같이 복사해옴.
- 즉, 부모와 자식은 동일한 코드를 가지게 됨
-
디스크로부터 Child Process에 새로운 image를 로드함
- 즉, 실제 디스크에서 원하는 프로그램을 가져옴
-
새로 생긴 Child Process의 PCB를 CPU의 ready queue에 등록하여 CPU를 사용할 수 있게 준비함
- 이는 아직 CPU를 부모 프로세스가 사용하고 있기 때문
→ 1번과 2번 과정을 통틀어서
fork()라고 부름 (부모와 동일하게 만듦)
→ 3번과 4번 과정을 통틀어서exec()라고 부름 (새로운 이미지를 가져옴)
fork()
fork란 1, 2단계. 즉, 부모 프로세스의 PCB와 이미지 정보를 그대로 자식 프로세스에 복사하는 것임. 이때 기억해야 할 것은 fork는 한 번 호출하면 두 번 리턴한다는 것임
main()
{ int pid;
pid = fork();
if (pid == 0) /* this is child */
printf(“I am child! \n”);
else /* this is parent */
printf(“I am parent!\n”);
}-
첫 번째 리턴 : 부모가 자신의 프로세스를 그대로 자식에게 복사하고, CPU의 ready queue에 자식을 등록시키고 다시 부모 프로세스로 리턴하는 과정
→ 부모 프로세스에게 자식 프로세스의 PID 값을 리턴(자식 프로세스의 pid값을 리턴 받음으로써 부모 프로세스는 자식 프로세스를 알고 통제할 수 있음)
→ (위 알고리즘에서) 부모는 자식의 PID 값을 가지고 있으므로, “i am parent!” 를 출력 -
두 번쨰 리턴 : 자식이 fork로 생성되면 queue에서 기다리다가 CPU를 점유하며 실행이 되게 됨. 이때 자식은 부모 프로세스를 그대로 복사했기 때문에 부모 프로세스와 똑같은 프로그램을 실행하게 됨
- 자식은 부모의 PCB도 복사해왔기 때문에 ‘상태 벡터 저장 공간(state vector save area)’도 전부 동일하게 가지고 있음(어디서부터 실행해야할지 알려주는 PC(Program Counter)와 SP(Stack Pointer) 등 또한 복사됨).
- 따라서 자식 프로세스의 코드가 실행될 때는 맨 처음부터 실행되는 것이 아니라
fork()중간에서부터 다시 진행하게 됨(fork가 진행중이었던 부분부터 다시 진행이 됨).
→ 자식 프로세스에게 0값을 리턴
→ (위 알고리즘에서) 자식 프로세스의 pid는 보통 0을 가지므로, if문을 실행하게 됨.
exec()

exec()시스템 콜 관련 참고해야 할 내용들
- 리눅스에는
exec~로 시작하는 함수(시스템 콜)가 존재함. 이 함수들은 모두 공통적으로 프로그램을 실행한다는 특징을 갖고 있음.
exec를 사용하게 되면 기존의exec를 실행시킨 프로세스는exec가 실행한 프로그램으로 대체됨.
덧붙여 설명하면,exec계열 함수가 호출되면 그 즉시 현재의 프로세스의 기본적인 정보(file, mask, pid 등)만 유지한 채exec함수의 인자로 받은 실행파일(바이너리 이미지 파일 → 디스크로부터 가져옴)이라는 새로운 실행 프로세스(이미지)로 교체됨.
- 대체 된 이후에는
exec로 새로 실행한 프로그램의main()으로 넘어가게 됨- 이때, 새로운 프로세스가 생기는 것은 아니기 때문에 exec를 실행시킨 프로세스 ID와 exec로 실행된 프로세스 ID는 같음
- 다만, 프로세스를 구성하는 코드와 데이터, 힙, 그리고 스택 영역의 값들이 exec으로 발생하는 새로운 프로그램의 것으로 바뀌게 됨
- 시스템 콜
exec()안에/bin폴더는 바이너리(binary) 파일만 모아둔 폴더를 의미함
- 그 안에는 바이너리 프로그램들이 여러 개 존재함(ls, cat, …)
-
위 코드를 보면, 자식 프로세스는
fork()에서 0 값을 리턴받았으므로, if문 안으로 들어가게 됨- if 문에서
printf()를 실행하고,execlp()로 자신의 프로세스를exec가 실행할 프로세스로 대체함 - 이후
exec의 인자로 왔던 date 프로그램의main()으로 넘어가게 됨.
→ 한 마디로, 기존 작업하던 것을 자신의 프로그램으로 덮어 씌우고, 자신의 프로그램을 가동시킴
- if 문에서
wait()
부모 프로세스가 자식 프로세스를 생성하는 작업 등을 하면, wait() 시스템 콜이 호출됨. 이때, wait()시스템 콜(sys_wait())을 호출한 프로세스는 CPU 사용권한을 박탈당하게 됨.
-
만약 A라는 (부모) 프로세스가 wait 시스템 콜을 호출하면, trap에 걸려 커널 영역으로 가고, 커널 내부에 존재하는
sys_wait()함수가 호출됨- 이때 시스템은
wait()시스템 콜을 호출한 프로세스로부터 CPU를 빼앗게 됨 - 다시 말해, 자신의 일을 다 하고 나면 호출한 프로세스의 유저 모드로 돌아가야 하는데, cpu를 뺴앗기기 때문에 돌아가지 못하게 되고, 기다리게 된다(sleep)는 것임.
- 이때 시스템은
-
이후 커널은 ready queue(cpu에 링크를 걸어두고 기다리는 곳)로 가서 준비된 프로세스 중 우선순위가 가장 높은 프로그램의 PCB를 찾아서 PC(Program Counter)를 알아낸 후, PC가 가르키는 쪽으로 CPU를 넘겨주게 됨
-
** PC(Program Counter) : 다음에 실행될 명령어의 주소를 가지고 있어, 다음에 실행할 기계어 코드의 위치를 가르키는 역할을 함
→ 이러한 과정을 preempt라고 부름
-
-
이후 자식 프로세스의 수행이 끝나면서 특정 시그널을 보내면, 그때서야 부모 프로세스의 sleep이 풀리면서 ready queue로 들어가게 됨

위 코드를 해석하면, 다음과 같은 순서로 흘러감
- 부모 프로세스
fork()를 통해 자식 프로세스를 생성else로 빠지게 되며wait()을 호출하고, sleep상태에 빠지게 됨.- CPU는 부모에게서 자식으로 감
- 자식 프로세스
if로 빠지게 되며exec를 호출하여 일을 다 수행하고, 자식 프로세스는 종료될 것임- 자식 프로세스는 종료될 때 특정 시그널을 보내게 됨
- 다시 부모 프로세스
- 자식 프로세스가 종료되면(수행이 끝나며 특정 시그널을 보내면) CPU는 자식 프로세스로부터 부모 프로세스를 찾게 됨
- 바로 이때
wait()시스템 콜이 풀리게 되며 부모 프로세스를 ready queue에 등록시킴 - 부모 프로세스는 이후 CPU를 받게 되고, 자신의 남은 일을 진행하게 됨
exit()
메인함수 main()이 끝날 떈 반드시 exit()시스템 콜이 존재함.
- 만약 소스에 해당 시스템 콜이 없다고 하더라고, 컴파일러가 알아서 이를 추가함

- 위 코드를 보면
- 자식 프로세스는 if로 빠지게 되고,
exec()가 실행되면서 인자로 주어진 프로세스(/bin/date)로 현재 프로세스를 덮어 씌우게 됨 - 이후 해당 프로세스의
main()을 실행시키게 되며 끝날 떈exit()를 반드시 실행시킴exit()는 다음과 같이 동작함exit()이후로 들어오는 신호들을 전부 무시- 파일들이 열려있다면, 닫음
- 메모리 영역에서 해당 프로세스가 차지하고 있는 부분(image)을 해제
- 부모 프로세스에 시그널을 보냄(통보)
exit()를 호출한 프로세스의 상태를 좀비(ZOMBIE) 상태로 설정
- 또한
exit()가 호출되면 커널은 다음과 같이 동작함- CPU를 빼앗고, ready queue에 있는 다른 프로세스에 넘겨줌
- 이를 스케쥴링(scheduling)이라고 함
exit()함수는 커널 함수schedule()를 호출하여 위와 같은 작업을 함
- CPU를 빼앗고, ready queue에 있는 다른 프로세스에 넘겨줌
정리 - fork() exec() wait() exit()
- fork() : 부모의 리소스를 복제하여 자식을 만듦
- exec() : 복제한 자식 프로세스 위에 실행하려는 새로운 프로세스 이미지를 덮어씌우고, 해당 프로세스의
main()으로 감 - wait() : wait 시스템 콜을 호출한 프로세스를 (자식 프로세스가 끝날 때까지) sleep 시킴
- exit() : (자식 프로세스의) 리소스들을 모두 하제하고, 부모에게 알림
Context Switch by wait() & exit()
이번에는 wait()와 exit()의 상호작용을 중심으로 Child process 생성 과정을 다시 살펴봐보자.
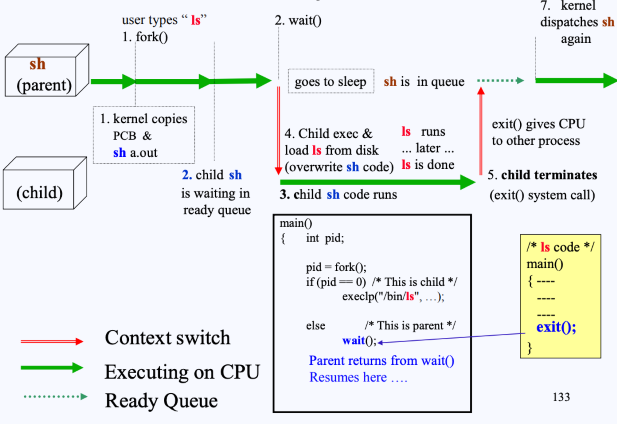
- 유저가 쉘에 명령어
ls를 입력함- 쉘은 이를 실행시키기 위해
fork()를 실행함 (쉘이 부모 프로세스). fork()가 동작하며 쉘의 PCB와 이미지 정보를 복사- 그러나 아직 CPU는 쉘에 할당되어 있음 → 따라서 ls가 실행되지는 않음
- 쉘은 이를 실행시키기 위해
- 부모 프로세스인 쉘은
wait()를 호출하게 되고, 쉘은 잠들게 됨.- 잠들면서 자식 프로세스는 CPU의 ready queue에 들어가게 됨
- 자식 프로세스가 CPU를 받고나면
- 자식은 부모의 리소스들으 똑같이 물려받았으므로,
fork()중간에서 동작을 시작하게 됨 - 이때,
fort()로부터 리턴된 값은 자식 프로세스를 뜻하는 PID값 0이므로, 자식 프로세스는exec~를 실행하게 될 것임
- 자식은 부모의 리소스들으 똑같이 물려받았으므로,
- 자식 프로세스에서 exec가 실행되면 디스크로부터
ls를 로드하고, 부모 프로세스(쉘)로부터 복사해왔던 이미지 위에 그대로 덮어씌우게 된다. 이후ls의main()으로 가게 됨 ls가 끝나면exit()시스템 콜을 하게 됨- 자식 프로세스의 리소스들을 모두 하제하고, 부모에게 알림
- 이제 CPU는 ready queue에 있던 다른 프로세스에 할당 될 것임 → 이때 부모 프로세스의
wait()콜이 끝난 것으로 인지하게 됨(부모가 sleep에서 깨어남)
- (그림에서 7번) 이후 부모 프로세스(쉘)는 ready queue에 등록되어 차례를 기다리다가, CPU를 다시 받으면 다시 돌아와서 일을 시작하게 됨
위 과정을 도식화하면, 다음과 같이 User-mode와 Kernel-mode를 왔다갔다 하며 context switching을 하는 것을 알 수 있다.

또 다시 이를 커널과 CPU 관점에서 보았을 땐 다음 그림과 같이 표현할 수 있다.
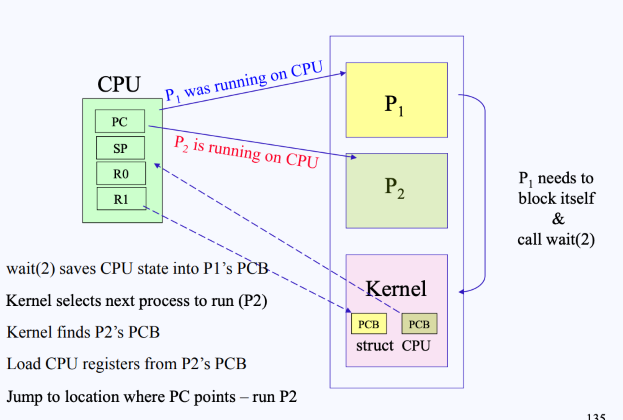
- 그림에서 메모리에는 P1, P2, Kernel이 올라와 있음
- Kernel 안에는 하드웨어 장치의 정보를 담고 있는 Data Structure(struct CPU)와 프로세스의 정보를 담고 있는 PCB가 들어있음
- 이때, P1이 자기 자신을 block시킬 때가 되다면,
wait()시스템 콜을 호출하게 된다.- Kernel-mode로 넘어가며
sys_wait()를 호출하게 됨 - 또한 현재 P1의 상태(state vector)를 PCB에 저장하게 됨
- Kernel-mode로 넘어가며
- P1이 wait하게 됐으므로, 커널은 커널 안에 있는 하드웨어 Data Structure의 ready queue에서 현재 가장 우선순위가 높은 작업을 찾아 CPU를 넘겨주게 됨
- 만약 P2가 다음 우선순위 높은 작업이라면, P2의 PCB로부터 state vector들을 cpu에 로드시키고, PC에 저장된 주소로 이동하면서 P2프로세스가 실행됨
→ 이 과정이 Context Switching이며, 이를 해주는 함수가 schedule()이라는 함수임
→ 다시 설명하면, Context Switch란, CPU가 한 개의 task(process / thread)를 실행하고 있는 상태에서 interrupt 요청에 의해 다른 task로 실행이 전환되는 과정에서 기존의 task 상태 및 Register 값들에 대한 정보(context)를 저장하고, 새로운 task의 정보(context)로 교체하는 작업을 말함.
Context Switch - schedule()
schedule()은 참고로 유저 단에서 시스템 콜로 커널에게 요청함으로써 호출할 수 있는 함수가 아니라, 커널 내부에서만 호출이 가능함 함수임 (즉, 시스템 콜이 아님)
schedule()은read(),wait(),exit()과 같은 함수에 의해서 호출됨schedule()은 CPU를 사용하는 사람이 바뀌어야 할 때 기존 작업의 상태(state vector)를 PCB에 저장해주고, 새로운 작업에 CPU를 할당해주기 위한 내부 작업을 진행해줌
→ 즉, schedule()함수는 CPU의 상태(대여자)가 바뀔 때마다 호출되게 됨
🔥 시스템 콜 총 정리
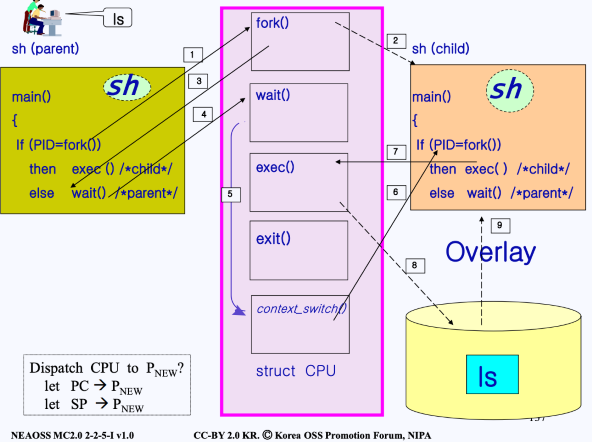
-
터미널을 키면 쉘이 나오게 됨. 쉘은 사용자의 입력을 기다리다가
ls와 같은 명령을 입력받게 되면, 커널에 있는fork()를 호출하게 됨(시스템 콜)** shell: 많은 프로그램들(Utility)들이 disk로부터 언제 올라오고, 언제 내려가는지 등을 컨트롤하는 프로그램(Job(command) Control)
-
fork()를 요청하면, Kernel-mode로 넘어가게 되고sys_fork()가 호출됨.sys_fork()는 현재 쉘 프로세스(부모) 이미지(코드)를 그대로 복사하여 자식을 만듦
-
fork()호출이 끝나면 부모 프로세스인 쉘은 else로 들어가서wait()시스템 콜을 호출하게 됨 -
wait()를 요청하면, 또 다시 Kernel-mode로 넘어가게 됨 -
wait()는 CPU를 잠시 포기하겠다는 것이므로,context_switch()함수를 실행함- CPU에 있던 (부모 프로세스의) state vector 영역의 정보를 PCB에 저장
- CPU의 ready queue에 자식을 등록시킴
- 부모 프로세스는 sleep 상태가 됨(cpu를 양도함)
-
(자식 프로세스가 CPU를 받고나면) 자식 프로세스가 생겨날 때는 부모 프로세스에서
fork()가 진행되던 시점이었으므로, 자식 프로세스의 PC는fork()중간을 가르키고 있음. 따라서 자식 프로세스는fork()지점에서부터 시작하게 됨 -
자식 프로세스는 if로 들어가서
exec()시스템 콜을 호출함 -
exec()는 하드디스크에 저장되어 있는 프로그램 코드(exec()의 매개변수로 준 프로그램 = 이미지)를 로드함 -
(8)에서 로드한 이미지를 현재 진행되고 있던 프로세스 이미지 위에 덮어씌우는 작업을 함
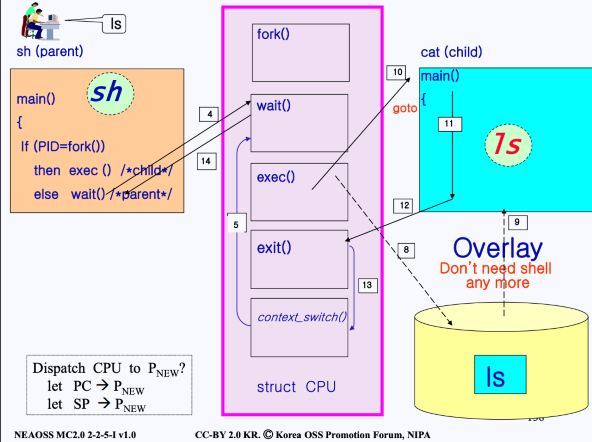
- 이제 덮어 씌어진 이미지의
main()(이미지에서는ls)으로 흐름이 넘어가게 됨 - 해당 이미지의
main()을 전부 실행하고 나면 - 커널에 exit()를 호출하게 됨
- 자식 프로그램의 리소스를 모두 해제하고, 부모에게 알림
exit()는context_switch()함수를 실행시킴- 이때 부모 프로세스도 sleep에서 깨어나게 되며, ready queue에 등록되어 차례를 기다리게 됨
- ready queue에서 기다리던 부모 프로세스가 다시 선택되면, 다시 유저 모드의
wait()시스템 콜 요청 때로 돌아가게 됨- 아까 부모프로세스는
wait()중간에서 switch가 됐었기 때문에 그 부분으로 다시 돌아감
- 아까 부모프로세스는
- 이후 쉘은 다시 사용자로부터 또 다른 명령을 기다리는 상태가 됨
Reference
