
컨테이너를 구성하는 대표적인 리눅스 기술 세 가지를 알아보자.
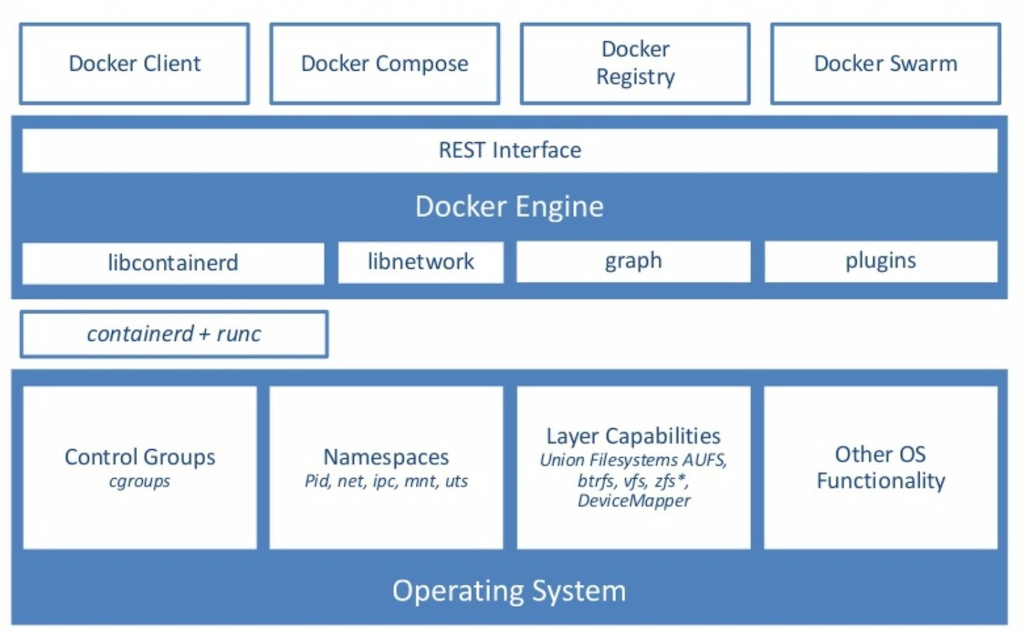
- Control groups : 리소스 사용량 결정
- Namespaces : 자원을 격리(공개 범위를 결정)
- Union mount file system : 컨테이너를 효율적으로 관리
Cgroup(Control group)
Cgroup은 프로세스들이 사용하는 시스템의 자원의 사용 정보를 수집하고, 제한시키고, 격리시키는 리눅스 커널 기능(모든 프로세스에 대해 리소스 사용 정보를 수집함)을 한다.
- 제한 가능한 자원
- CPU : 스케줄러를 사용하여 해당 cgroup에 속한 프로세스 CPU 사용 시간을 제어함
- memory : 해당 cgroup에 속한 프로세스의 메모리 사용량을 제어함
- 초과 시 oom 발생(oom_control로 관리할 수 있음)
- freezer : cgroup의 작업을 일시중지하거나 다시 시작함
- 마치 도커의 pause/unpause와 같은 역할
- blkio : cgroup의 BlockI/O(Block device(SSD, USB, HDD 등)에 대한 제한을 설정
- net_cls : 네트워크 패킷을 클래스 식별자(classid)로 태그하여 Linux 트래픽 컨트롤러 (tc
)가 특정 cgroup에서 발생하는 패킷들을 식별할 수 있게 함 - cpuset : 개별 CPU 및 메모리 노드를 cgroup에 바인딩 하기 위한 서브시스템. 리눅스의
testset명령과 유사하게 CPU 코어를 할당 할 수 있는 서브시스템임. - cpuacct : cgroup이 사용한 CPU 자원에 대한 보고서를 생성
- devices : cgroup 작업 단위로 장치에 대한 엑세스를 허용하거나 거부
- ns : namespace 서브시스템
- …
- 활용 사례
- runc, YARN (Hadoop), Android 등
- ex) Android에서는 cgroup을 이용해서 애플리케이션을 foreground / background로 나누고 background의 CPU 점유율을 낮추고 있음.
- ex) 페이스북에서는 워크로드를 core workload, non-core services 등으로 나누고 cgroup을 지정하여 리소스를 관리(가장 중요한 core workload에 영향을 최소화시킴)
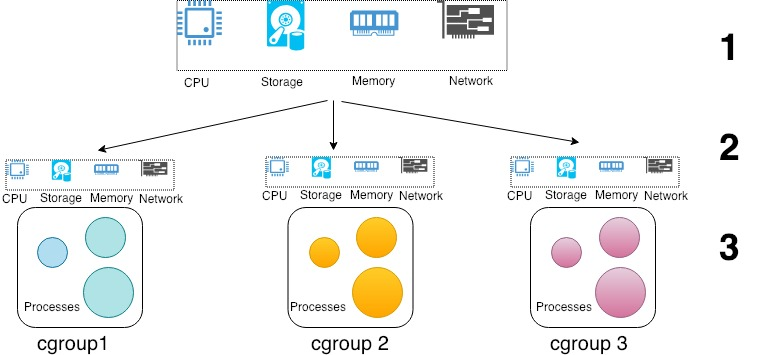
Cgroup v1 vs v2

Cgroup은 두 가지 버전으로 나눠지며, 두 버전은 위 그림처럼 계층 구조가 다르다.
- cgroupv1 : control 대상이 되는 리소스들을 기준으로 control 그룹들을 나눔
- cgroupv2 : control 대상이 되는 워크로드들을 기준으로 control 그룹들을 나눔
Cgroup 실습해보기 : CPU 사용량 제한
Cgroup으로 CPU 사용량을 제한하는 실습을 해보자.
(본 실습에는 cgroupv2가 사용됨)
- 먼저
stress실험을 위해 stress 패키지를 설치해주었다.
sudo apt update && apt install -y stress- 다음 명령어로 내가 어떤 cgroup 버전을 가졌는지 확인할 수 있다.
grep cgroup /proc/filesystems
# 만약 시스템이 cgroupv2를 지원한다면, 다음과 같이 출력이 됩니다.
# 만약 시스템이 cgroupv1만 지원한다면, 아래 출력에서 'cgroup2' 부분은 보이지 않습니다.
- 현재 쉘의 pid가 어떤 cgroup인지 먼저 확인해보자.
cat /proc/$$/cgroup
-
이제
/sys/fs/cgroup경로로 가서 시스템에 설치된 cgroup 목록을 확인해보자.- cgroup목록은 (이전에 배운 proc처럼)실제 파일은 아니지만, 파일처럼 보임
-
이제 test용 부모 디렉토리를 만들어보자.
mkdir test_cgroup_parent && cd test_cgroup_parent
ls
# cgroup 디렉토리와 마찬가지로 cgroup.controllers, cgroup.subtree_control 등의 파일이 보임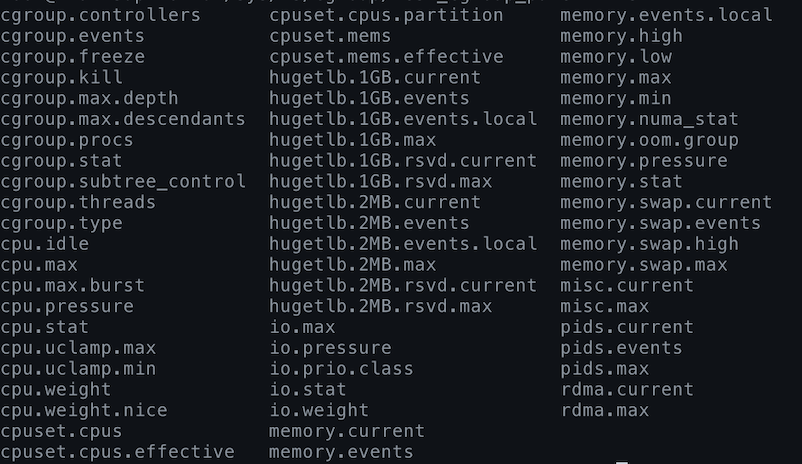
- (
cat cgroup.controllers명령어로 어떤 것들을 컨트롤할 수 있는지 확인할 수 있다.)- (출력 ->) cpuset cpu io memory hugetlb pids rdma misc
- 이제, cpu를 subtree이 추가하여 컨트롤 할 수 있도록 설정한다.
+는 추가를,-는 삭제를 의미한다.- 현재 디렉토리는 부모 디렉토리이다.
echo "+cpu" >> /sys/fs/cgroup/test_cgroup_parent/cgroup.subtree_control- 이제, cpu.max를 통해 제한을 걸어본다.
- cpu.max의 첫 번쨰 값은 허용된 시간(마이크로초) 할당량임. 이 시간에는 하위 그룹의 모든 프로세스를 전체적으로 실행할 수 있음. 두 번째 값은 총 기간 길이를 지정함.
- 이번 실습에서는 1000000마이크로초(1초) 중에 100000 마이크로초만 실행되게끔 제한을 걸어보자(1/10만 실행하도록 설정)
- 현재 디렉토리는 부모 디렉토리이다.
- optional) cpu.weight로는 테스크별 가중치를 조절할수도 있다.
- cpu.weight 컨트롤러의 파일 값은 백분율이 아니라 절대값임.
- 예를 들어, task1이 100이고, task2가 200이라면, task2의 가중치가 두 배 더 높음
echo 100000 1000000 > /sys/fs/cgroup/test_cgroup_parent/cpu.max
# cat으로 잘 설정되었는지 확인할 수 있다.- 실험을 하기에 앞서, CPU에 부하를 걸어본다.
stress -c 1
# 다른 쉘에서 사용량을 확인해본다.
top
# cpu가 100% 사용중
- 이제 test용 자식 디렉토리를 생성하고, pid를 추가하여 제한을 걸어본다.
- pid는 자식 디렉토리에서 추가한다.
# 부모(test_cgroup_parent) 위치에서 자식 생성 && 자식으로 이동
mkdir test_cgroup_child && cd test_cgroup_child
# 현재 쉘의 pid를 cgroup.procs에 추가
# 현재 pid는 echo $$ 를 통해 알 수 있음
echo $$ > /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child/cgroup.procs- 이제 다시 (해당 쉘에서) CPU에 부하를 걸어보자.
stress -c 1
# 다른 쉘에서 사용량을 확인해본다.
top
# cpu가 10%만 사용중임을 확인할 수 있다.
- 마지막으로 현재 쉘 pid가 어떤 cgroup에 속하는지 다시 한 번 확인해보자.
cat /proc/$$/cgroup
- 실험이 완료되었으니 cgroup을 삭제해주자. cgroup을 삭제할 때에는 깊은 곳부터 순차적으로 삭제해준다.
sudo rmdir /sys/fs/cgroup/test_cgroup_parent/test_cgroup_child
sudo rmdir /sys/fs/cgroup/test_cgroup_parentcgroupv1일 경우
: cgroup폴더 내 cpu 폴더에서 위와 비슷하게 진행하면 된다.
- 단,
cpu.max가 아니라cpu.cfs_quota_us(허용 시간)와cpu.cfs_period_us(총 시간)를 사용한다.
Namespace
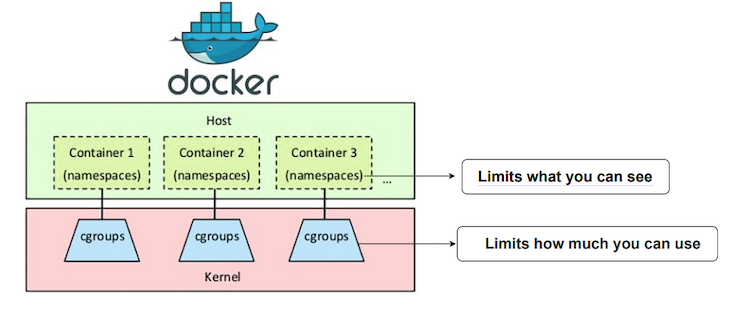
Namespace는 프로세스별로 별도의 커널 자원을 분할하는 리눅스 커널의 기능이다.
- namespace 종류
- Process ID(pid) : pid 정보를 격리함. 네임스페이스 외 다른 프로세스에 접근이 불가.
- Network(net) : 네트워크 장치, IP주소, 포트, 라우팅 테이블 등 네트워크 리소스를 격리하고 가상 네트워크 장치를 할당함.
- Filesystem/mount(mnt) : 프로세스별로 마운트되는 파일시스템을 격리함.
- inter-proc comms(ipc) : inter-process communication을 격리. 다른 프로세스의 접근이나 제어를 방지함.
- UTS : 호스트명, 도메인명을 격리
- User : 프로세스 별로 UID, GID 정보를 격리
- namespace vs cgroup
- cgroup은 해당 프로세스가 쓸 수 있는 사용량을 제한한다.
- namespace는 해당 프로세스가 볼 수 있는 범위를 제한한다.
Namespace 실습해보기 : 네임스페이스 PID 확인해보기
네임스페이스를 생성하여 PID를 격리해보자. 마치 하나의 시스템에서 PID가 2개인 것처럼 프로세스를 만들어보는 것이다.
- unshare 명령어로 새로운 네임스페이스를 생성해보고, 쉘을 실행하여 PID를 확인해보자.
- unshare은 (부모로부터) unshared한 namespace를 생성하는 커맨드이다.
unshare [options] [<program> [<argument>...]]
- 옵션
-p,—pid: pid 생성-m,—mount: mount 생성-i,—ipc: ipc 생성-f,—fork: 자식 프로세스 생성-u,—uts: 호스트명과 도메인 명을 격리할 수 있음-U,—user: 유저 namespace 격리- …
- unshare은 (부모로부터) unshared한 namespace를 생성하는 커맨드이다.
# 유저 격리 & PID 격리
# --map-root-user : 루트 사용자를 네임스페이스에 매핑(새 네임스페이스 안에서 루트 권한이 있음)
# 프로세스 분기(bash)
unshare --user --pid --map-root-user --mount-proc --fork bash
ps -ef
# 다음과 같이 process들이 격리됨을 확인할 수 있다.
Union mount filesystem
Union mount filesystem은 하나의 디렉토리 위치에 여러 개의 디렉토리를 마운트하여도, 하나의 통합된 디렉토리처럼 보이게 하는 방법임
- 원래는 기존 디렉토리 위치에 새로운 파일 시스템을 마운트하면 새롭게 마운트된 내용만 보이게 됨
- UFS에서 사용하는 주요 개념으로 Image Layer와 CoW가 있음.
- 도커는 UFS(Union File System)기반의 Storage driver를 사용하여 컨테이너와 이미지를 관리함.
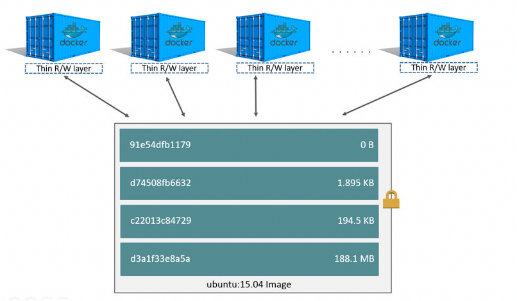
Image Layer
- 도커를 통해 Image Layer의 구조를 알아보자.
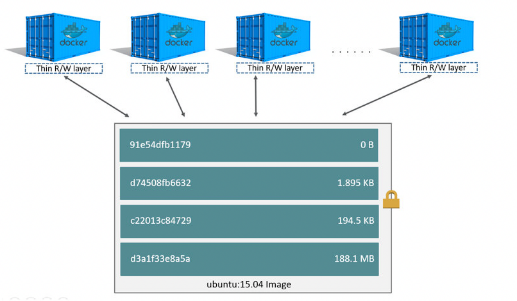
- 위 그림에서 하단에는 Read Only의 이미지 레이어가 존재함.
- 위 그림에서 상단에는 Writable한 컨테이너 레이어가 존재함.
- 이러한 Image Layer는 효율적으로 하나의 도커 이미지로 여러 개의 컨테이너를 생성하고, 각 컨테이너를 사용자의 입맛에 맞게 관리할 수 있게 해줌.
- Read Only의 이미지 레이어와 Writable한 컨테이너 레이어와의 Union으로 최종 컨테이너들을 생성하는 방식
- 즉, 이미지를 레이어 형식으로 쌓는 Image Layer 구조를 가짐
- 이떄 효울적인 Write를 위해 CoW 전략을 사용함
CoW(Copy on Write), RoW(Redirect on Write) 전략
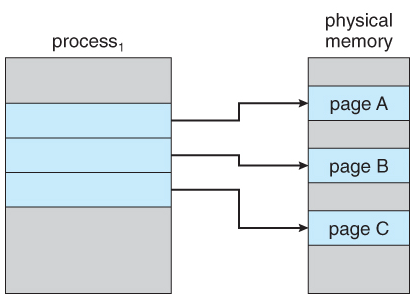
- 다음 이미지와 같이 Process1은 physical memory로부터 page A, B, C를 사용하고 있다.
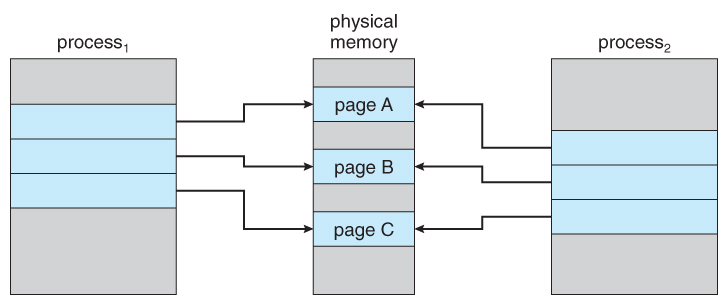
- 이때, page A, B, C에 대해 읽기 작업을 수행하는 새로운 Process 2가 생성된다면, 다음 그림처럼 Process 2는 그저 physical memory에 접근하여 파일들의 내용을 그저 읽으면 된다.
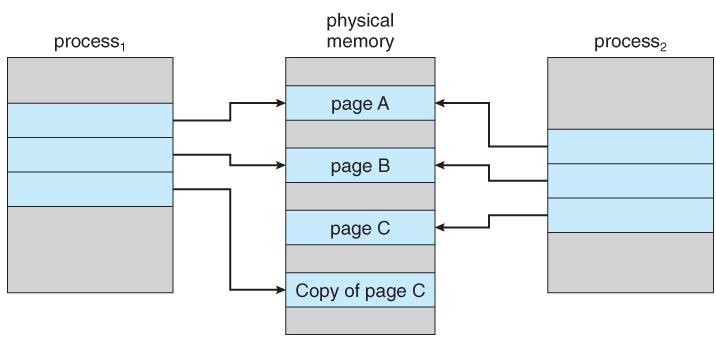
- 그러나 process가 기존 파일들에 쓰기 작업을 해야 할 경우, 상황이 조금 달라짐. 원본 파일을 유지하면서 쓰기를 저장할 수 있어야 하기 때문이다.
- 이를 해결하기 위해, 쓰기 요청을 수행해야 할 경우에는 다음 그림처럼 physical memory에서 원본 파일을 복사(Read & Write)한 뒤 요청을 반영하게 됨. 이것이 바로 Copy on Write 전략이다.
- RoW는 CoW와 비슷하지만, 쓰기 작업 시 Copy(Read & Write)를 하는 것이 아니라, 변경점만을 저장(Write)한다는 차이가 있음. 따라서 CoW와는 다르게 한 번의 쓰기 작업만 일어난다.
- 이제 위에서 살펴봤던 도커 storage driver의 구조를 다시 한 번 봐보자.
- 도커에서 아래 Image Layer들은 위 예시에서 '원본 파일'에 해당한다..
- 만약 새로운 컨테이너를 생성하는 등 변경사항이 생긴다면 Container Layer에 변경점을 저장하게 된다.
- 만약 변경된 내용으로 새로운 이미지를 build하게 된다면,
원본 파일 + 변경점이 하나의 원본 파일(layer)이 될 것이다.
- 도커는 드라이버에 따라 CoW 또는 RoW 개념을 사용한다. 이제 도커에서 사용하는 Union FileSystem을 지원하는 대표적인 드라이버(AUFS, OverlayFS)에 대해서 알아보자.
- 더 많은 드라이버에 대한 정보 👉 공식 문서
AUFS Driver
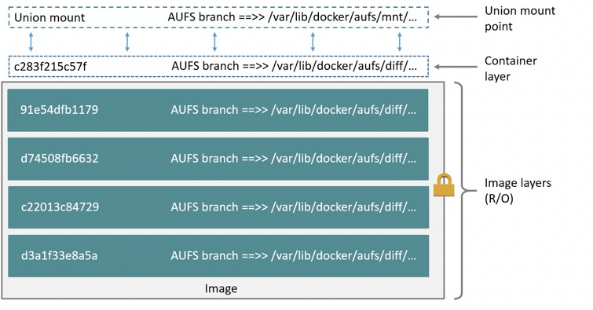
- AUFS는 Container에서 원본 파일을 변경해야 한다면, 컨테이너 레이어로 전체 파일을 복사하고, 이 파일을 변경함으로써 변경사항을 반영한다.
- 이미지 레이어는 계층형태로 되어있으며, 복사할 파일을 찾기 위해 가장 위의 레이어부터 찾기 시작하게 됩니다. 따라서 복사할 파일이 이미지 레이어의 아래쪽에 있다면, 시간이 더 오래걸릴 수 있다.
OverlayFS Driver
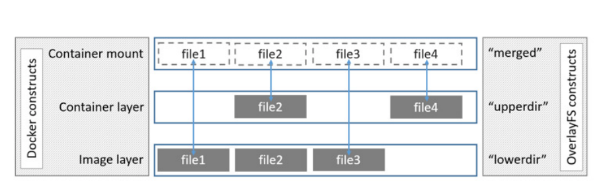
- OverlayFS는 AUFS와 비슷한 원리로 동작하지만, 이미지 레이어에 계층이 없는 구조로 되어있다.
(overlay2는 현재 지원되는 모든 Linux배포판에 대해 선호되는 스토리지 드라이버임) - AUFS와 유사하게 (파일 변경점에 대해)lowedir(이미지 레이어)에 존재하는 file을 upperdir에 복사하여 사용한다.
- 그러나 AUFS와는 다르게 계층화된 레이어 구조가 아니기 때문에 복사할 파일을 찾는 과정이 AUFS보다 빠름
- upperdir에는 container에서 발생한 변경 사항을 담고 있음(overlayfile 파일이 존재).
docker diff명령어를 통해, lowerdir로부터 upperdir에 어떤 변화가 있었는지를 확인할 수 있음
- A: 추가됨
- C: 변경됨
- D: 삭제됨
Union mount filesystem 실습해보기 : docker에서 OverlayFS를 출력해보기
도커 이미지의 overlayFS 정보를 확인해보자.
cat /proc/mounts | grep overlay
# 다음과 같이 overlay 타입, lowerdir, upperdir, wordir(fs에서 관리 목적으로 사용) 등을 확인할 수 있다.
Reference
- https://www.nextplatform.com/2018/07/13/microsofts-container-strategy-continues-to-evolve/
- https://medium.com/some-tldrs/tldr-understanding-the-new-control-groups-api-by-rami-rosen-980df476f633
- https://www.lightnetics.com/topic/17326/what-are-control-groups-in-linux
- redhat_docummentation
- https://bikramat.medium.com/namespace-vs-cgroup-60c832c6b8c8
- https://velog.io/@whattsup_kim/DockerStorage-driver-데이터-관리
- https://www.nginx.com/blog/what-are-namespaces-cgroups-how-do-they-work/

2개의 댓글

Sí, siempre y cuando elijas casinos online confiables que ofrezcan este juego con licencia oficial de Pragmatic Play https://thesweetbonanza.com/ve/sweet-bonanza-1000-ve/ . En Venezuela hay plataformas internacionales que permiten registrarse y jugar legalmente en moneda local o en criptomonedas, con total seguridad.
안녕하세요! 컨테이너에 대해서 공부하면서 찾아본 블로그들 중에 제일 정리를 깔끔하고 깊게 하신거 같네요! 멋지시고 좋은 글 작성해주셔서 감사합니다.