본 글은 빅데이터를 지탱하는 기술을 읽고 정리한 내용입니다.
2-1 크로스 집계의 기본
트랜잭션 테이블, 크로스 테이블, 피벗 테이블
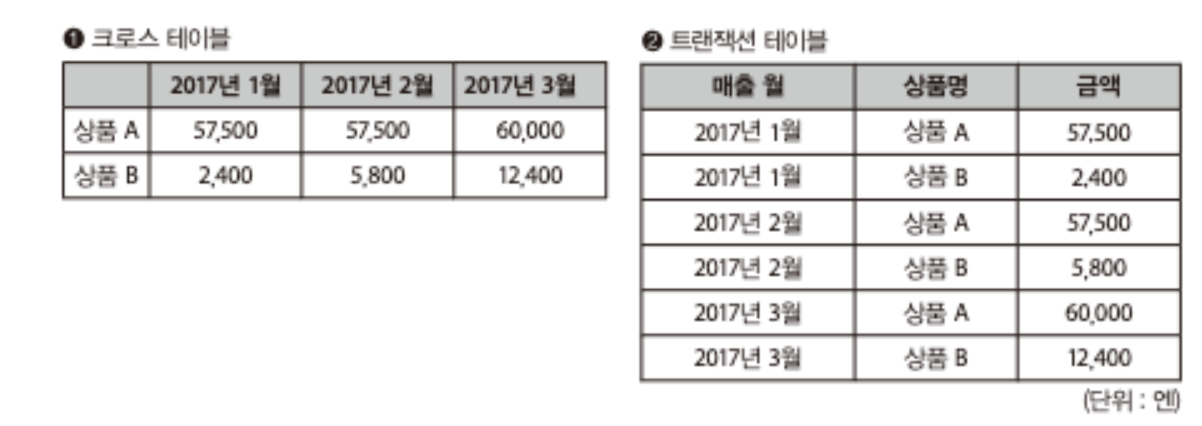
- 크로스 테이블 : 어떤 기간에 어떤 상품의 판매 ‘집계’ 등을 테이블로 만든 것
- 사람들이 보기 편함
- 그러나 데이터베이스에서는 다루기 어려운 형식
- 트랜잭션 테이블 : DB의 record에 해당하는 데이터를 저장하는 테이블.
- 데이터베이스 등에서 다뤄지는 형식
- 새로운 데이터는 새로운 행이 추가되는 식으로 기록됨
- 크로스 집계 : 트랙잰션 테이블에서 크로스 테이블로 변환하는 과정
- 스프레드시트의 피봇 테이블
- Pandas의
pivot_table() - SQL의 집계 합수를 이용(대량의 데이터)
데이터 집계 → 데이터 마트 → 시각화
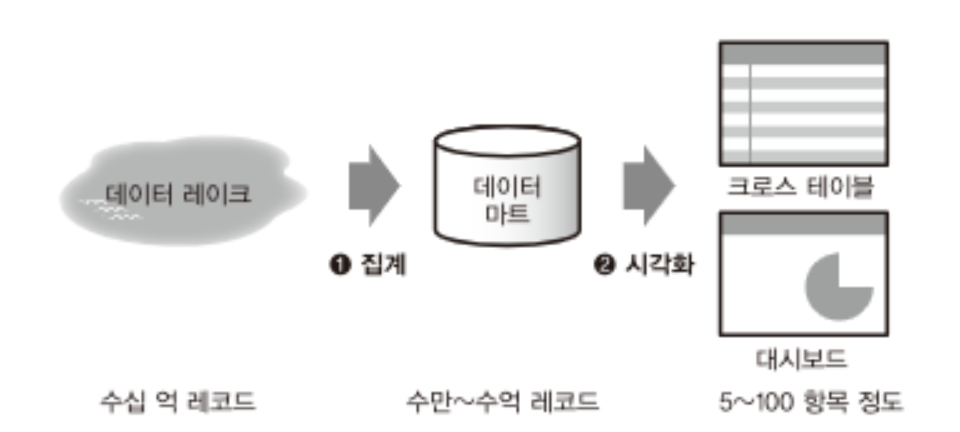
- 일반적으로 데이터 마트가 작을수록 시각화하는 것이 간단하지만, 동시에 원래 데이터에 포함된 정보를 잃어버리게 되어 시각화의 프로세스에서 할 수 있는 것이 적어질 수 있음.
- 반대로 데이터 집계에서 정보를 많이 남기게 되면, 데이터 마트가 거대화되어 좋은 시각화를 할 수 없게 될 우려가 있음.
- 이들은 trade-off 관계에 있으며, 이 ‘데이터 마트의 크기’에 따라 시스템 구성이 결정됨.
2-2 열 지향 스토리지에 의한 고속화
메모리에 다 올라가지 않는 정도의 대량의 데이터를 집계하려면, 미리 데이터를 집계에 적합한 형태로 변환하는 것이 필요함. 2-2에서는 집계효율이 높은 데이터베이스의 구조를 살펴본다.
데이터베이스의 지연을 줄이기
- 데이터 양이 증가함에 따라 집계에 걸리는 시간은 길어짐
- 따라서 초 단위로 데이터를 집계하려면 이를 위한 시스템을 설계하여야 한다.
- 주로 다음과 같은 3계층의 시스템을 만듦
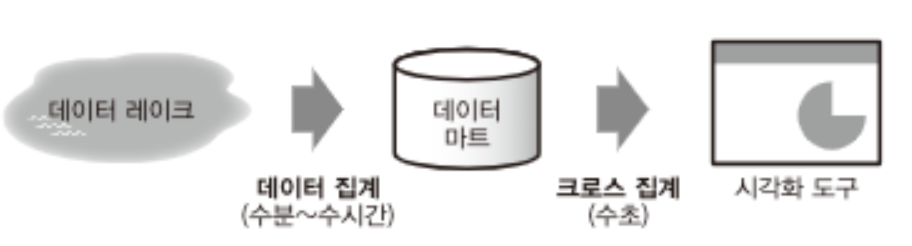
- 원 데이터는 용량적인 제약이 적고, 대량의 데이터를 처리할 수 있는 데이터 레이크(혹은 데이터 웨어하우스)에 저장한다. 여기서 원하는 데이터를 추출하여 데이터 마트를 구축하고, 데이터 마트에서는 항상 초 단위의 응답을 얻을 수 있도록 한다.
데이터 처리의 지연 : 지연이 적은 데이터 마트 작성을 위한 기초 지식
- 지연을 해결하기 위한 가장 간단한 방법은 모든 데이터를 메모리에 올리는 것이다.
- 모든 데이터를 메모리에 올릴 수 있는 정도의 양이라면, MySQL이나 PostgreSQL과 같은 일반적인 RDB가 데이터마트에 적합하다. (RDB는 지연이 적고 많은 클라이언트의 동시 접속을 감당할 수 있음)
- 그러나, RDB는 메모리가 부족하면 급격히 성능이 저하됨.
- 수억 레코드를 초과하는 집계에서는 항상 디바이스 I/O가 발생하게 됨.
- 이를 어떻게 효율화할 것인지가 중요한 key.
‘압축’과 ‘분산’에 의해 지연 줄이기 - MPP 기술
- 데이터를 가능한 한 작게 압축하고, 그것을 여러 디스크에 분산함으로써 데이터의 로드에 따른 지연을 줄일 수 있다.
- 분산된 데이터를 읽어들이려면 멀티 코어를 활용하면서 디스크 I/O를 병렬처리하는 것이 효과적이다.
- 이러한 아키텍처를 MPP(Massive Parallel Processing: 대규모 병렬 처리)라고 부른다.
- MPP 아키텍처는 데이터 분석을 위해 데이터베이스에서 널리 사용되고 있다.
- ex) Amazon Redshift, Google BigQuery, …
열 지향 데이터베이스 접근
빅테이터로 취급되는 데이터의 대부부은 디스크에 있기 때문에 쿼리에 필요한 최소한의 데이터를 가져옴으로써 지연이 줄어들게 된다. 이를 위해 사요오디는 방법이 ‘칼럼 단위로의 데이터 압축’이다.
행 지향 데이터베이스 - 각 행이 디스크 상에 일련의 데이터로 기록됨
- 행 지향 데이터베이스에서는 테이블의 각 행을 하나의 덩어리로 디스크에 저장한다.
- 이렇게 하면, 새 레코드를 추가할 때 파일의 끝에 데이터를 쓸 뿐이므로 빠르게 데이터를 추가할 수 있다.
- 즉, 대량의 트랜잭션을 지연 없이 처리하기 위한 데이터 쓰기 작업을 효율적으로 할 수 있음
- 행 지향 데이터베이스에서는 데이터 검색을 고속화하기 위해 인덱스(index)를 사용한다.
- 만약 인덱스가 없다면 검색을 위해 모든 데이터를 로드해야하므로 많은 디스크 I/O가 발생하여 성능이 저하됨.
- ❗️반면 데이터 분석에서는 어떤 칼럼이 사용되는지 미리 알 수 없기 때문에 인덱스를 사용하여도 큰 도움이 되지 않음. 따라서 디스크I/O를 효율화하기 위한 다른 고속화 기술이 필요함
열 지향 데이터베이스 - 칼럼마다 데이터를 모아두기
- 열 지향 데이터베이스에서는 데이터를 미리 칼럼 단위로 정리해둠으로써 필요한 칼럼만을 로드하여 디스크I/O를 줄임
- 예를 들어, 점포의 총 매출액을 알고 싶을 땐 고객의 정보는 필요 없음. 행 지향 데이터베이스에서는 레코드 단위로 저장되기 때문에 디스크로부터 필요 없는 열까지 로드하게 됨.
- 또한 열 지향 데이터베이스는 데이터의 압출 효율도 우수함.
- 같은 칼럼에는 종종 유사한 데이터가 나열됨.
- 특히 같은 문자열의 반복은 매우 작게 압축할 수 있음
- 열 지향 데이터베이스는 압축되지 않은 행 지향 데이터베이스와 비교하면 (대략) 1/10 이하로 압축할 수 있음
MPP 데이터베이스의 접근 방식
- 행 지향 데이터베이스에서는 보통 하나의 쿼리는 하나의 스레드에서 실행됨.
- 행 지향 데이터베이스의 경우, 각 쿼리는 충분히 짧은 시간 안에 끝나는 것으로 가정하므로, 하나의 쿼리를 분산 처리하는 상황은 가정하지 않음.
- 반면, 열 지향 데이터베이스는 한 번의 쿼리도 실행 시간이 길어짐. 또한 압축된 데이터의 전개 등으로 CPU 리소스를 필요로하므로 멀티 코어를 활용하여 고속화하는 것이 좋음
- MPP에서는 하나의 쿼리를 다수의 작은 테스크로 분해하고 이를 가능한 병렬로 실행함
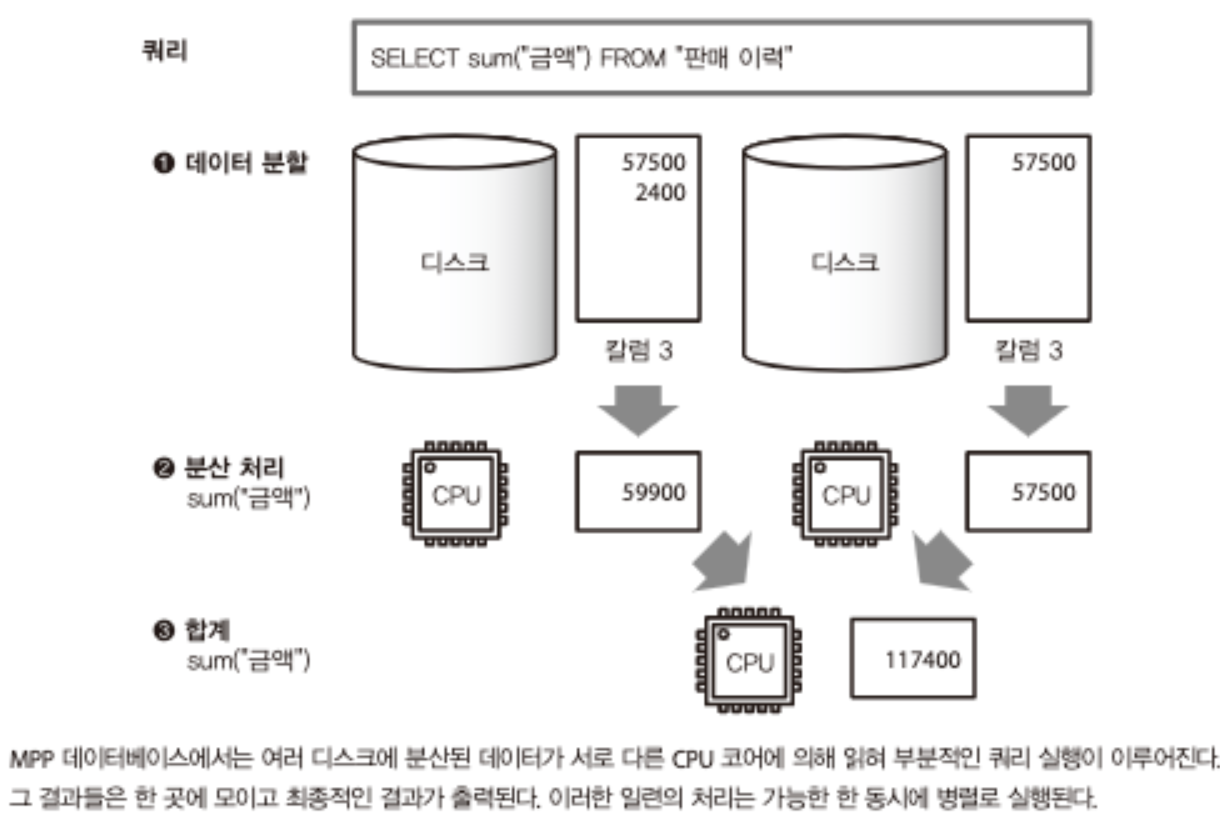
MPP 데이터베이스와 대화형 쿼리 엔진
- 쿼리가 잘 병렬화할 수 있다면, MPP를 사용한 데이터의 집계는 CPU 코어 수에 비례해 고속화됨
- 단, 디스크로부터의 로드가 병목 현상이 발생하지 않도록 데이터가 고르게 분산되어 있어야 함
- MPP는 구조상, 고속화를 위해 CPU와 디스크 모두를 균형 있게 늘려야 함.
- 이처럼 하드웨어 수준에서 데이터 집계에 최적화된 DB를 ‘MPP 데이터베이스’라고 함
- MPP의 아키텍처는 Hadoop과 함께 사용되는 대화형 쿼리 엔진으로도 채택되고 있음.
- 그러나, 데이터를 열 지향으로 압축하지 않는 한 MPP 데이터베이스와 동등한 성능은 되지 못함.(하둡 상에서 열 지향 스토리지를 만들기 위해 여러 라이브러리가 개발되고 있음)
| 집계 시스템 종류 | 스토리지의 종류 | 최적의 레코드 수 |
|---|---|---|
| RDB | 행 지향 | ~수 천만 |
| MPP 데이터베이스 | 열 지향(하드웨어 일체형) | 수억~ |
| 대화형 쿼리 엔진 | 열 지향(분산 스토리지에 보관) | 수억~ |
2-3 애드 훅 분석과 시각화 도구
Jupyter Notebook에 의한 애드 훅 분석
-생략-
대시보드 도구 - 정기적으로 집계 결과를 시각화하기
- 대시보드 도구와 BI 도구의 차이는 그다지 엄밀하진 않음
- 대시보드는 새로운 그래프를 쉽게 추가할 수 있는 것이 중시된다면
- BI 도구는 보다 대화형 데이터 탐색이 중요시 됨.
- ex) 그래프를 클릭하여 상세한 표시로 전환하거나, 집계에 기반이 되는 로우 데이터를 표시하는 등 시간을 들여 차분히 데이터를 보고 싶은 경우 BI 도구가 더 적합함
- 대시보드 도구에서는 최신의 집계 결과를 즉시 확인할 수 있길 기대한다.
- 따라서 정해진 지표의 일상적인 변화를 모니터링하고 싶은 경우에는 대시보드가 적합함
- 대표적인 오픈소스 대시보드(혹은 실시간 시각화) 도구는 다음이 있다.
- Redash : 다수의 데이터 소스에 대응하는 파이썬 기반 대시보드 도구
- 장점
- SQL에 의한 쿼리의 실행 결과를 그대로 시각화하는 데 적합
- 대시보드의 작성이 직관적임
- 데이터 소스 등록
- 쿼리를 실행하여 표와 그래프를 만듦
- 그래프를 대시보드에 추가함
- 쿼리는 정기적으로 실행되어 그 결과가 Redash 자신의 데이터베이스에 저장된다. 따라서 별도 데이터 마트를 만들 필요가 없음
- 단점
- BI 도구만큼 대량의 데이터를 처리할 수 없음
- Redash에서 그래프의 수만큼 쿼리를 실행하게 되고, 대시보드가 증가함에 따라 백앤드 DB의 부하가 높아짐
- 장점
- Superset : 대화형(interactive) 대시보드를 작성하기 위한 파이썬 기반 웹 어플리케이션.
- 장점
- 시계열 데이터에 대응한 열 지향 스토리지인 ‘Druid’를 표준으로 지원하며, 스트리밍 형의 데이터 전송과 조합시킴으로써 실시간 정보를 취급할 수 있음.
- 단점
- 내장 스토리지 시스템을 갖고 있지 않아 데이터의 집계는 외부 데이터 저장소에 의존함.
- BI 도구와 마찬가지로 시각화를 위한 데이터 마트를 먼저 만들어두어야 함
- 장점
- Kibana : 자바스크립트로 만들어진 대화식 시각화 도구(특히 실시간 대시보드를 만들 목적으로 자주 사용됨.).
- Kibana는 Elasticsearch 이외의 데이터 소스에는 대응하고 있지 않아 시각화하려는 데이터는 모두 Elasticsearch에 저장해야 함.
- Elasticsearch는 ‘전체 텍스트 검색’에 대응한 데이터 스토어임. 따라서 키워드로 텍스트 데이터를 검색하려는 경우 특히 그 힘을 발휘함.
- 시각화를 위한 데이터 스토어로 Elasticsearch를 채용하는 경우 최선의 선택이 될 수 있음.
- 차분히 시간을 들여 데이터를 탐색하는 것보다는 검색 조건에 맞는 데이터를 빠르게 시각화하는 데 적합한 도구임
- Kibana는 Elasticsearch 이외의 데이터 소스에는 대응하고 있지 않아 시각화하려는 데이터는 모두 Elasticsearch에 저장해야 함.
- Redash : 다수의 데이터 소스에 대응하는 파이썬 기반 대시보드 도구
BI 도구 - 대화적인 대시보드
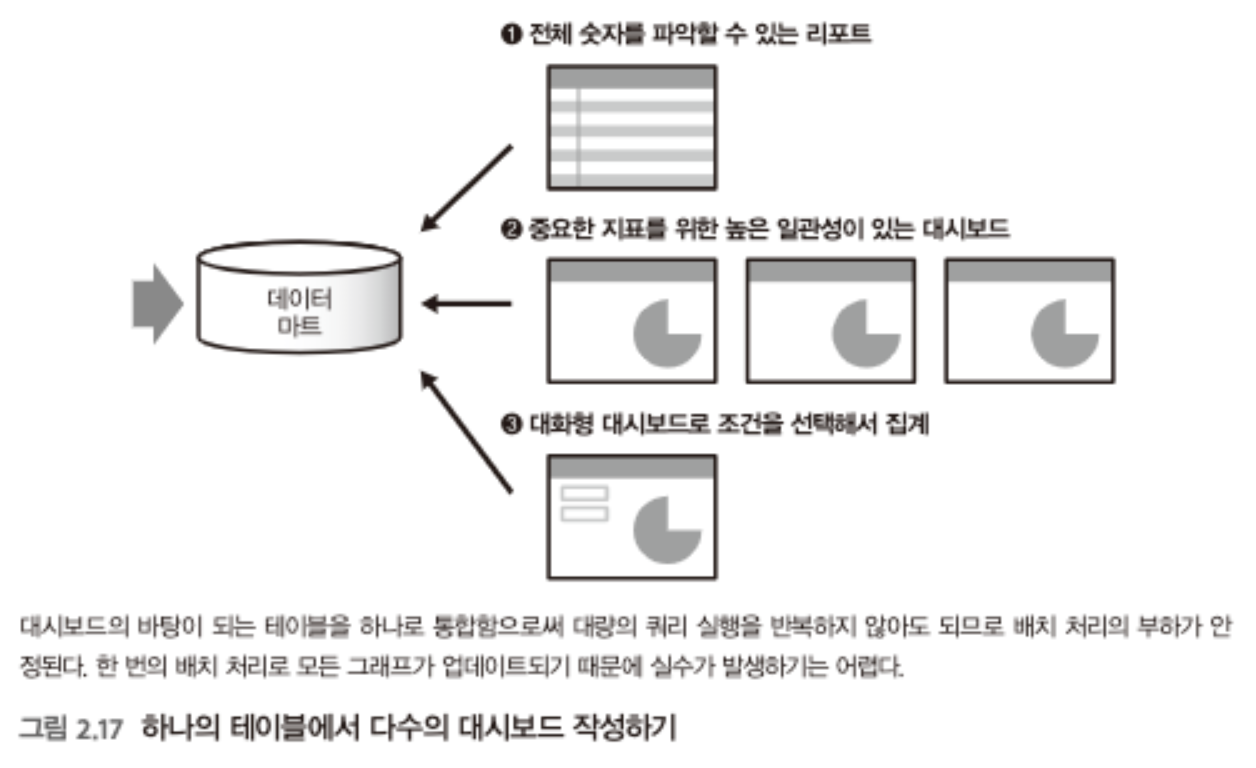
- 몇 개월 단위의 장기적인 데이터의 추이를 시각화하거나, 집계의 조건을 세부적으로 바꿀 수 있는 대시보드를 만들려면, BI 도구를 사용하는 것이 적합할 수 있음.
- BI 도구에서는 이미 있는 데이터를 그대로 가져올 뿐 아니라 , 시간을 들여 데이터를 분석하기 쉽도록 가공하는 일이 자주 있음. 따라서 시각화에 적합한 데이터 마트를 만들어 읽고 쓰는 것을 전제로 함
- 대화형 대시보드를 만들기 위해선 그 바탕이 되는 데이터를 모두 포함하는 하나의 테이블을 작성하고, 이 테이블을 사용해 다수의 대시보드를 만든다.
- 알고 싶은 것이 늘어날 때마다 데이터 마트에 테이블을 만들고, 거기에서 파생된 다수의 대시보드가 생겨나는 것이 BI 도구의 시각화 과정임
2-4 데이터 마트의 기본 구조
시각화에 적합한 데이터 마트 만들기 - OLAP
- BI 도구에 있어 핵심적인 개념 중 하나로 OLAP(Online Analytical Processing)라는 구조가 있음
다차원 모델과 OLAP 큐브
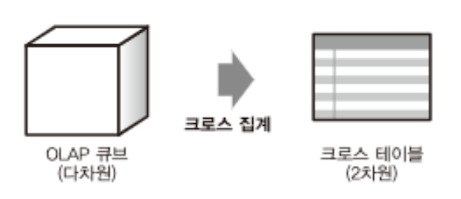
- OLAP는 데이터 집계를 효율화하는 접근 방법 중 하나임.
- 일반적으로 RDB는 표 형식으로 모델링된 데이터를 SQL로 집계하는 반면, OLAP에서는 ‘다차원 모델’의 데이터 구조를 ‘MDX(MultiDimensional eXpressions)’ 등의 쿼리 언어로 집계함.
- 데이터 분석을 위해 만들어진 다차원의 데이터를 ‘OLAP 큐브’라고 부르며, 이것을 집계하는 구조가 OLAP임
- 이전에는 컴퓨터 성능이 높지 않아, 데이터 편집에 많은 시간이 걸렸으므로 OLAP를 고속화하려면 여러 아이디어가 필수적이었음
- ex) 크로스 집계의 모든 조합을 미리 계산하여 캐싱해두기
- BI 도구는 본래 OLAP 구조를 사용하여 데이터를 집계하기 위한 것이었고, 따라서 이전에는 데이터 마트도 OLAP 큐브로 작성되었음
MPP 데이터베이스와 비정규화 테이블
- 최근에는 MPP 데이터베이스 등의 보급으로 BI와 MPP 데이터베이스를 조합하여 크로스 집계하는 경우가 증가하고 있음 (미리 계산 x).
- BI 도구로 생각한대로의 그래프를 만들기 위해서는 이미 존재하는 테이블을 그대로 시각화하려고 하는 것이 아니라, 만들고 싶은 그래프에 맞춰 ‘다차원 모델’을 설계함.
- 그러나 MPP 데이터베이스에는 다차원 모델의 개념이 없기 때문에 이를 대신해 ‘비정규화 테이블’을 준비함
- 비정규화 테이블을 활용하여 BI 도구에서 OLAP와 동등한 시각화를 실현할 수 있음
테이블을 비정규화하기
- 데이터베이스 설계에서는 종종 테이블을 ‘마스터’와 ‘트랜잭션’으로 구분함 → 관계형 모델!
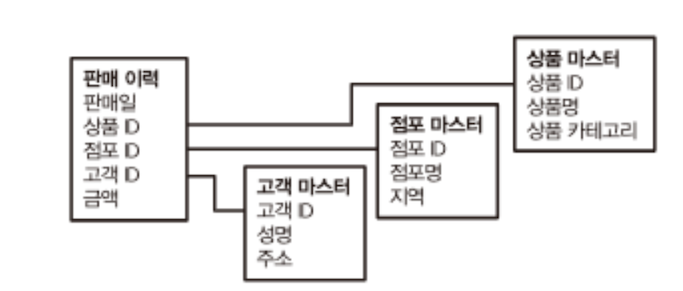
- 트랜잭션 : 시간과 함께 생성되는 데이터를 기록한 것
- 한 번 기록되면 변화하지 않음
- 마스터 : 트랜잭션에서 참고되는 각종 정보
- 상황에 따라 다시 쓰일 수 있음
- 트랜잭션 : 시간과 함께 생성되는 데이터를 기록한 것
- 데이터 분석에서는 이러한 정규화된 관계형 모델에서 출발해서 그와는 반대의 작업을 실행함
팩트 테이블과 디멘전 테이블
- 데이터 웨어하우스의 세계에서는 트랜잭션처럼 사실이 기록된 것을 ‘팩트 테이블’이라고 하고, 거기에 참고되는 마스터 데이터 등을 ‘디멘전 테이블’이라고 함
- 팩트 테이블 : 집계의 기반이 되는 숫자 데이터(ex. 판매액 등)
- 디멘전 테이블 : 테이블을 분류하기 위한 속성값
스타 스키마
- 데이터 마트를 만들 땐, 팩트 테이블을 중심으로 여러 디멘전 테이블을 결합하는 것이 좋다 (스타 스키마)
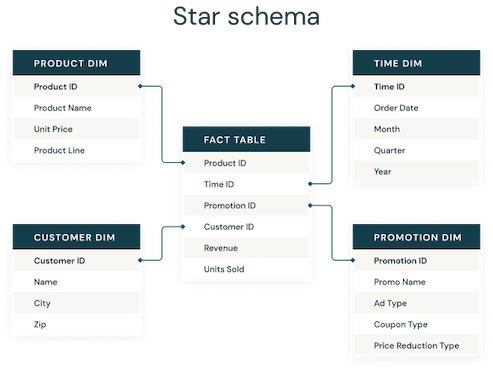
- 디멘전 테이블을 작성하려면 정규화에 의해 분해된 테이블을 최대한 결합하여 하나의 테이블로 정리한다 (비정규화)
- 그 결과로 데이터가 중복되어도 괜찮음(팩트 테이블만 정규화가 되어 있음)
- 스타 스키마의 장점
- 스타 스키마와 같은 팩트/차원 모델은 단순하므로 이해하고 구현하기가 쉬움.
- 팩트 테이블은 실시간 데이터이므로 시간이 지날수록 매우 많아진다. 따라서 디맨젼 테이블을 최대한 늘림과 동시에 팩트 테이블의 사이즈를 최소화하는 것이 디스크 I/O를 줄일 수 있는 방법이다.
비정규화 테이블
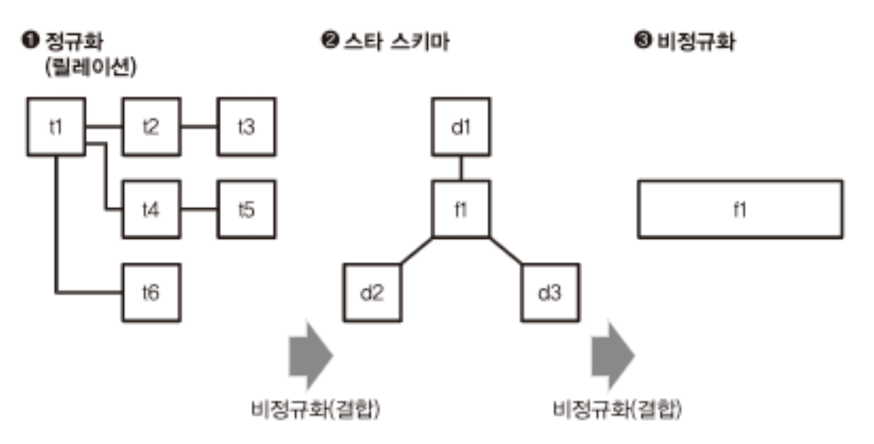
- MPP 데이터베이스와 같은 열 지향 스토리지를 갖는 시스템이 보급됨에 따라, 칼럼의 수가 아무리 늘어나도 성능에 영향을 주지 않게 됨.
- 또한 많은 계산을 요구하는 조인을 피하려고 하므로 정규화된 데이터에 비해 쿼리 성능이 향상됨.
- 따라서 처음부터 펙트 테이블에 모든 칼럼을 포함해두고, 쿼리의 실행 시에는 테이블 결합을 하지 않는 ‘비정규화 테이블’을 사용하는 것이 대부분의 경우 가장 단순하며 효율적인 방법임.
데이터 웨어하우스와 스타 스키마
- 데이터 마트가 아니라 ‘데이터 웨어하우스’의 데이터 구조로는 스타 스키마가 우수함
- 따라서 보통 데이터를 축적하는 단계에서는 펙트 테이블과 디멘전 체이블로 분리해두고, 이를 분석하는 단계가 된 후에 결합해 비정규화 테이블을 만ㄷ름
다차원 모델 시각화에 대비하여 테이블을 추상화하기
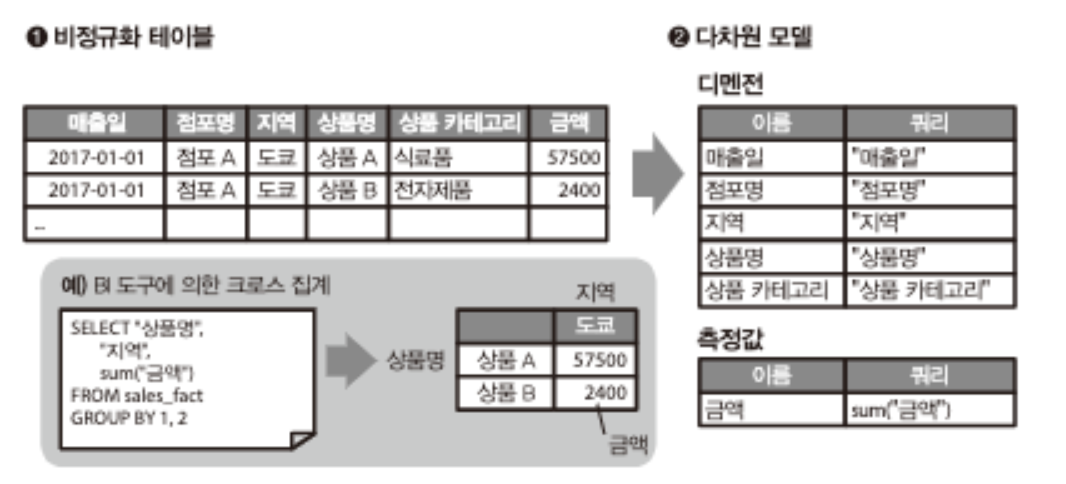
- 비정규화 테이블을 준비했다면 그것을 ‘다차원 모델'에 의해 추상화한다.
- 다차원 모델의 칼럼은 ‘디멘전’과 ‘측정값’으로 분류한다.
- 디멘전은 주로 날짜 및 문자열의 값이 되며, 크로스 집계의 행이나 열로서 사용된다.
- 측정값은 주로 숫자값이 되고, sum()과 max()와 같은 집계 함수와 함께 사용된다.
- 다차원 모델에 의한 데이터의 집계에서는 디멘전과 측정값을 사용하여 SQL의 쿼리가 자동으로 생성된다.
- ex) Tableau Puble에서의 디멘전과 측정값
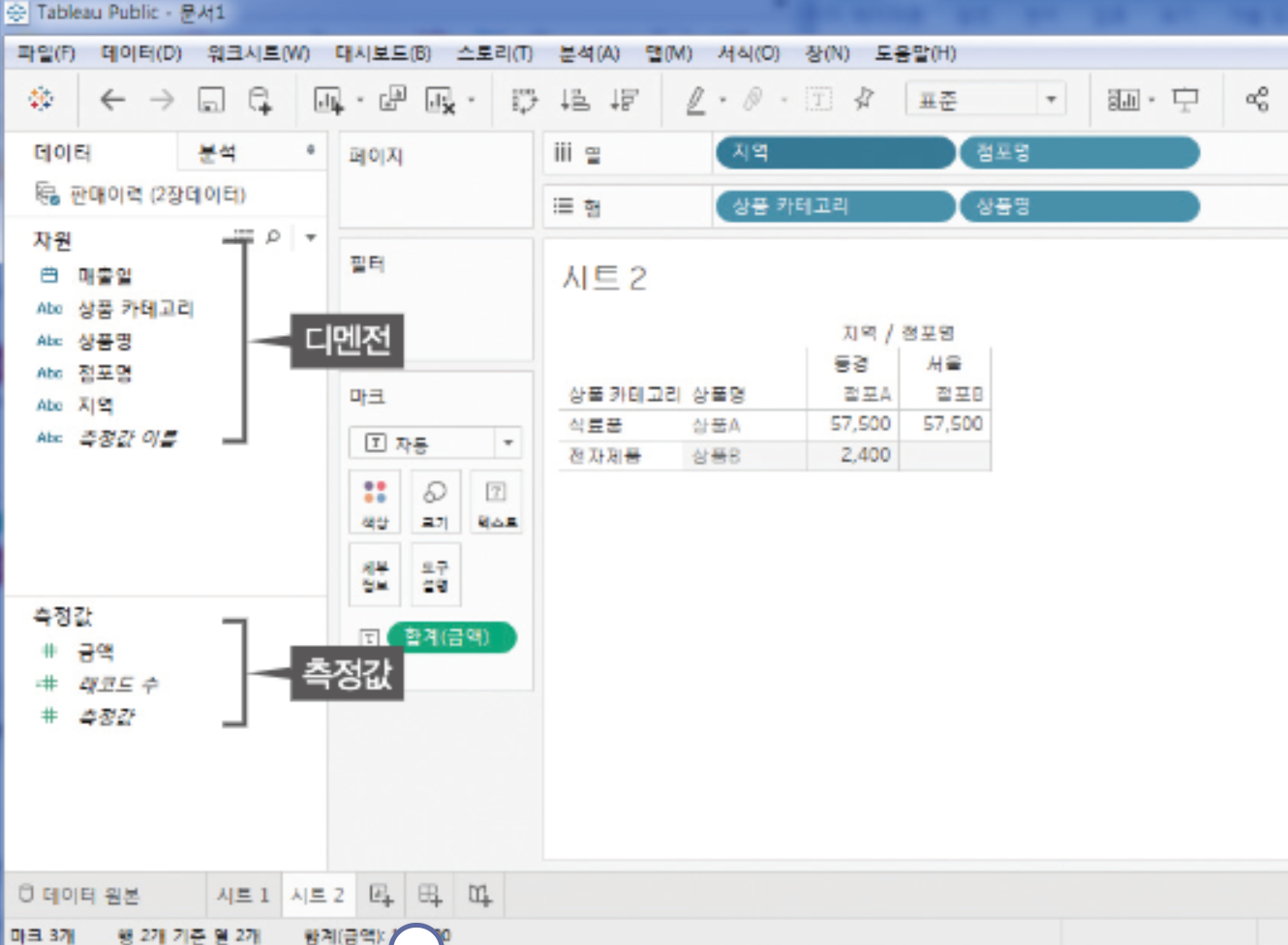
- ex) Tableau Puble에서의 디멘전과 측정값

AI Engineer : Lv 0