
배경
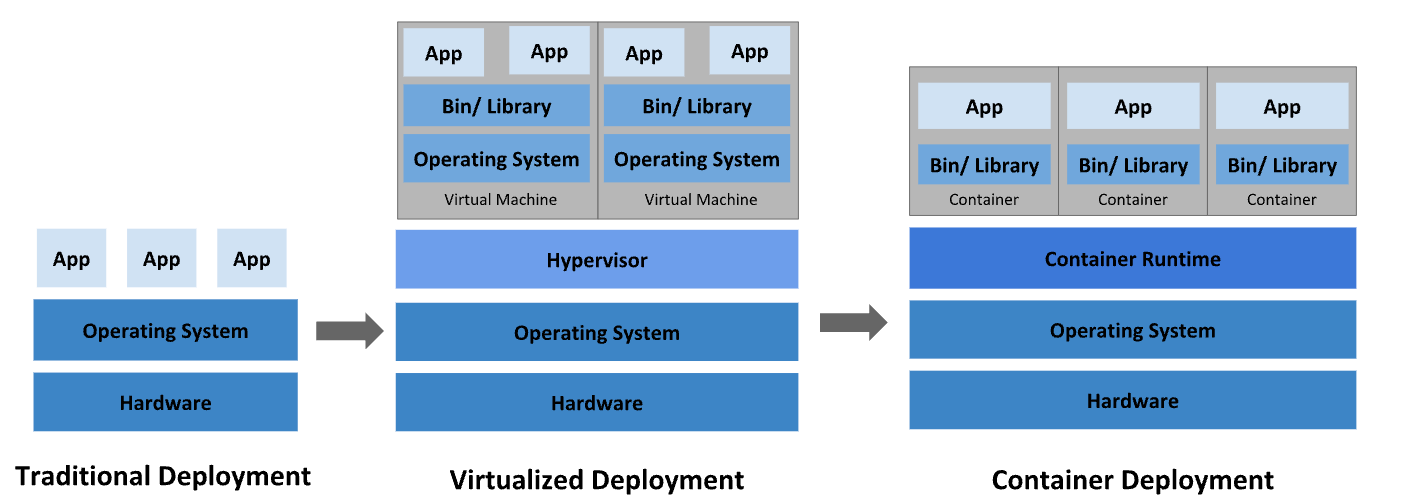
전통적인 배포 시대
- 전통적인 배포 때에는 애플리케이션을 물리 서버에서 실행했습니다.
- 그러나 한 물리 서버에서 여러 애플리케이션의 한계를 정의할 방법이 없었게 때문에 이에 대대 리소스 할당 문제가 발생했습니다.
- ex) 물리 서버 하나에서 무거운 인스턴스를 돌리게 되면, 다른 인스턴스에 대한 성능은 저하될 수 있습니다.
- 따라서 당시 개발자들은 서로 다른 여러 물리 서버에서 각 애플리케이션을 실행하며 이러한 문제를 해결하였습니다.
- 그러나 이는 많은 물리 서버를 유지해야 하기 때문에 (남는 서버 공간은 그대로 방치됨) 조직에게 많은 비용을 요구하였죠. 즉, 안정적이지만 비효율적인 구조였던 것입니다.
(하이퍼바이저 기반) 가상화된 배포 시대
- 이러한 해결책으로 ‘가상화된 배포 시대’가 도래하엿습니다.
- 가상화된 배포 시대에는 단일 물리 서버의 CPU에서 여러 가상 시스템(Virtual Machine)을 실행할 수 있게 하였습니다.
- 그러나 하나의 Host OS 위에 OS를 여러 개 실행시킨다는 점에서 VM은 리소스를 많이 잡아먹기 때문에 무겁다는 단점이 있었죠.
컨테이너 개발 시대
- 컨테이너는 VM과 유사지만, 가상화를 좀 더 경량화된 프로세스의 개념으로 만든 기술을 의미합니다.
- 호스트 OS 위에 컨테이너 엔진을 설치하고, 애플리케이션 작동에 필요한 바이너리, 라이브러리 등을 하나로 모아 각자가 별도의 서버인 것처럼 사용하는 환경입니다.
- 컨테이너는 호스트 OS와 커널을 공유하므로, 이전보다 빠르고 가볍게 가상화를 구현할 수 있게 되었으며, 유연하고 자유로운 마이크로서비스를 관리하기 용이하게 해 주었습니다.
- 마이크로 서비스: 앱이 작고 독립적인 단위로 쪼개져서 동적으로 배포되고 관리되는 것
탄력적인 컨테이너 운용을 위한 솔루션: 쿠버네티스

제목에서 설명하듯, 쿠버네티스는 탄력적인 컨테이너 운용을 위한 솔루션입니다.
- 만약, 서비스 중에 컨테이너가 다운되어 다른 컨테이너를 띄어야 하는 상황이 온다면 어떻게 해야 할까요?
- 개발자가 24시간 대기하면서 서비스 상황을 체크하지 않는 이상(심지어 그렇다고 하더라도) 문제를 바로 해결하는 것은 정말 힘든 문제입니다.
- 그런데 만약 컨테이너가 다운되면, 시스템이 복제해두었던 다른 컨테이너를 다시 실행하는 방식으로 이러한 문제를 해결한다면 어떨까요?
이것이 컨테이너 오케스트레이션 도구가 등장한 이유입니다.
- 컨테이너 오케스트레이션 : 일반적으로 애플리케이션은 의도에 따라 애플리케이션이 실행되게 하기 위해 네트워킹 수준에서 정리가 필요한 개별적으로 컨테이너화된 구성 요소(주로 마이크로 서비스로 칭함)로 구성됩니다. 이러한 방식으로 다수의 컨테이너를 정리하는 프로세스를 컨테이너 오케스트레이션이라고 합니다.
쿠버네티스는 이러한 컨테이너 오케스트레이션 도구 중 가장 널리 사용되는 오픈소스 툴입니다.
- 같은 역할을 하는 도구로서 도커 스웜(Docker Swarm), 아파치 메소스(Apache Mesos), 노마드(Nomad) 등이 대규모 컨테이너의 효율적 제어라는 동일한 목적 아래 발전되어 왔으나, 2022년 현재는 쿠버네티스가 컨테이너 기반 인프라 시장에서 사실상의 표준으로 자리 잡은 상태입니다.
쿠버테티스 기능
서비스 디스커버리와 로드 밸런싱
- 쿠버네티스는 (별도의 DNK 구성 없이) DNS 이름을 사용하거나 자체 IP 주소를 사용하여 컨테이너를 노출할 수 있습니다.
- 트래픽이 많아지면, 쿠버네티스는 자동으로 네트워크 트래픽을 로드밸런싱하여, 배포가 안정적으로 이루어질 수 있도록 합니다.
스토리지 오케스트레이션
- 쿠버네티스를 사용하면 로컬 저장소, 공용 클라우드 등과 같이 원하는 저장소 시스템을 자동으로 탑재할 수 있습니다.
자동화된 롤아웃과 롤백
- 배포된 컨테이너의 원하는 상태를 서술(선언, Desired State)할 수 있으며, 상태를 원하는 상태로 설정한 속도에 따라 변경할 수 있습니다.
- 장애 시 애플리케이션의 롤백도 지원합니다.
자동화된 빈 패킹(bin packing)
- 컨테이너화된 작업을 실행하는데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공합니다.
- 각 컨테이너가 필요로 하는 CPU와 메모리를 쿠버네티스에 지시하면, 쿠버네티스는 컨테이너를
시크릿(secret)과 구성(config) 관리
- 시크릿과 애플리케이션 구성을 안전하게 배포하고 업데이트할 수 있습니다.
- 시크릿된 정보들은 암호화되어 저장됩니다.
자가 치유
- 오류가 발생하거나 노드가 죽었다면, 컨테이너를 재시작하고 다시 스케쥴링 해줍니다.
- 즉, 사용자가 정의한 상태에 따라 서비스를 준비하고 제공합니다.
배치 실행
- 배치(실시간으로 처리하는 것이 아니라, 일괄적으로 모아서 한 번에 처리하는 것) 단위 작업을 실행할 수 있도록 하며, 주기적인 배치 작업도 실행할 수 있습니다.
오토 스케일링
- 자동으로 애플리케이션의 스케일을 넓히거나 줄일 수 있습니다(Horizontal Scailing)
쿠버네티스 핵심 컨셉
선언형 인터페이스와 Desired State
- 쿠버네티스에서는 명령형 인터페이스가 아닌 선언형 인터페이스를 사용합니다.
- 어떤 동작을 지시하는 것이 아니라 원하는 상태를 선언하는 것.
- 이러한 방식을 “쿠버네티스 네이티브”하다고도 함.
- ex) “우리집 온도가 25도로 유지됐으면 좋겠다.”
- 쿠버네티스는 현재 상태와 선언된 상태(desired state)가 일치하는지를 지속적으로 체크압니다. 만약 두 상태가 다르다면, 선언된 상태에 맞게 복구될 수 있도록 필요한 조치를 취하게 됩니다.
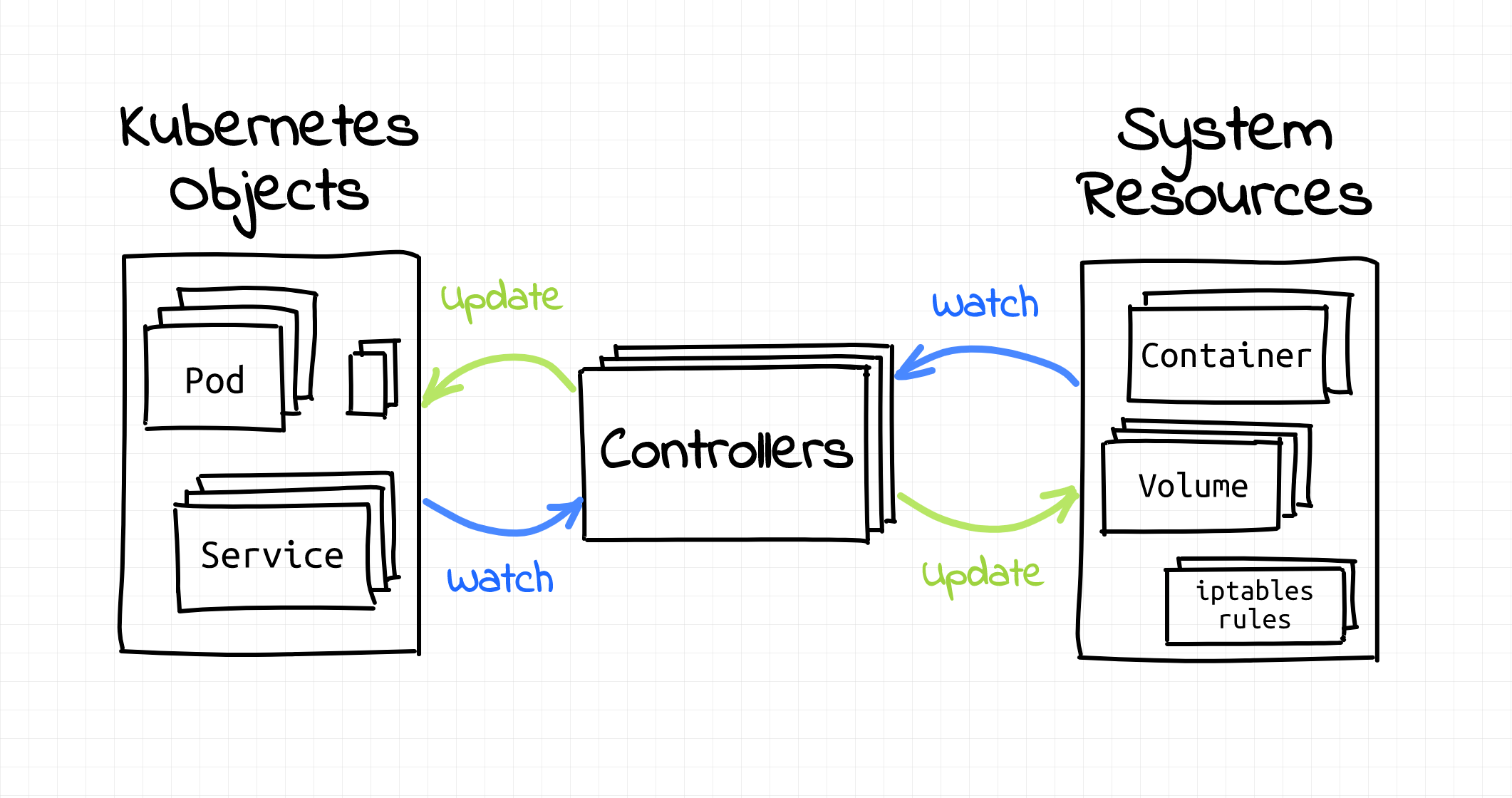
- 조금 더 자세하게 설명하면, 쿠버네티스의 모든 것은 Objects와 Controller를 중심으로 돌아갑니다.
- 쿠버네티스는 클러스터의 상태를 나타내기 위해 이 Objects 이용합니다(클러스터의 상태를 나타내는 단위입니다.).
- 즉, Objects는 사용자의 의도를 담은 레코드입니다. → Objects를 생성함으로써 클러스터의 워크로드를 어떤 형태로 보이고 싶은지를 효과적으로 쿠버네티스에게 전달할 수 있습니다.
- ex) 어떤 컨테이너화된 애플리케이션이 동작 중인지, 어떤 상태인지, 그 애플리케이션이 이용할 수 있는 리소스, 어떤 의도로 작성되었는지 등
- 주요 Objects로는 Pod, ReplicaSet, Deployments, Service, Volume 등이 있습니다.
- Pod : 쿠버네티스에서 배포할 수 있는 가장 작은 단위로, 한 개 이상의 컨테이너와 스토리지, 네트워크 속성을 가집니다. Pod에 속한 컨테이너는 스토리지와 네트워크를 공유하고, 서로 localhost로 접근할 수 있습니다.
- ReplicaSet : Pod를 한 개 이상 복제하여 관리하는 Object입니다. ReplicaSet은 복제할 개수, 개수를 체크할 라벨 선택자, 생성할 Pod의 설정 값 등을 가지고 있습니다. 이를 직접적으로 사용하기보다는 Deployments 등 다른 오브젝트에 의해 사용되는 경우가 많습니다.
- Service : 네트워크와 관련된 오브젝트입니다. Pod를 외부 네트워크와 연결해주고, 여러 개의 Pod를 바라보는 내부 로드밸런서를 생성할 떄 사용합니다. 내부 DNS에 서비스 이름을 도메인으로 등록하기 떄문에 서비스 디스커버리 역할도 합니다.
- Volume : 저장소와 관련된 오브젝트입니다. 호스트 디렉토리를 그대로 이용하거나 클라우드 스토리지를 동적으로 생성하여 사용할 수 있습니다.
- Objects에 대한 명세(Spec)은 주로 YAML로 정의합니다.
- 오브젝트의 종류와 원하는 상태를 입력합니다.
- 이러한 명세는 생성, 조회, 삭제로 관리할 수 있기 때문에 REST API로 쉽게 노출할 수 있습니다.
- 애플리케이션을 배포하기 위해선 원하는 상태(desired state)를
- 즉, Objects는 사용자의 의도를 담은 레코드입니다. → Objects를 생성함으로써 클러스터의 워크로드를 어떤 형태로 보이고 싶은지를 효과적으로 쿠버네티스에게 전달할 수 있습니다.
- 반면에 Controller는 클러스터의 실제 상태와 원하는 상태를 관찰하는 무한 루프입니다. 이 두 상태가 벌어지면 컨트롤러는 클러스터의 현재 상태를 원하는 상태에 더 가깝게 만들기 위해 변경을 시작합니다.
- 쿠버네티스는 클러스터의 상태를 나타내기 위해 이 Objects 이용합니다(클러스터의 상태를 나타내는 단위입니다.).
클러스터와 마스터-노드
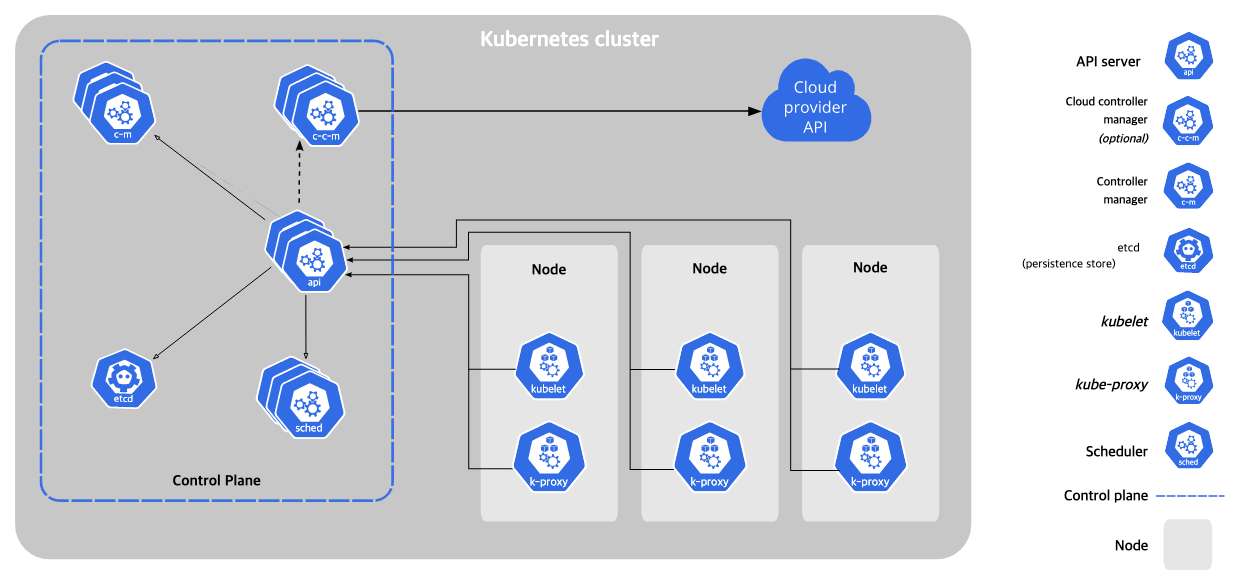
- 쿠버네티스에서는 전체 물리 리소스를 클러스터 단위로 추상화하여 관리합니다.
- 사용자는 이 클러스터 단위로 쿠버네티스를 사용하여, 물리적으로는 여러 대의 서버가 분리되어 있어도, 사용자의 입장에서는 하나의 서버를 사용하는 것처럼 사용할 수 있게 됩니다.
- 쿠버네티스 클러스터는 즉, 컨테이너화된 애플리케이션을 실행하는 노드(워커)들의 집합입니다.
- 모든 클러스터는 최소 한 개의 워커 노드를 가집니다.
- API 서버는 json 또는 protobuf 형식을 사용하여 http 통신을 지원하지만, 편하게 사용하기 위해 주로
kubectl이라는 CLI 도구를 사용합니다. - 클러스터 내부에는 클러스터의 구성 요소들에 대해 제어 권한을 가진 컨트롤 플레인(Control Plane) 역할의 마스터 노드(Master Node)를 두게 되며, 관리자는 이 마스터 노드를 이용하여 클러스터 전체를 제어합니다.
- 모든 명령은 마스터의 API 서버를 호출하고, 노드는 마스터와 통신하면서 필요한 작업을 수행합니다.
- 따라서 마스터 노드에는 엄격한 보안 설정이 필요하며, 고가용성을 위해 여러 대를 구성하기도 합니다.
- Comtrol Plane의 구성은 다음과 같습니다.
- API : kubectl 요청 뿐 아니라 내부 노드까지의 모든 요청을 처리하는 모듈입니다.
- 실제로는 원하는 상태(desire state)를 key-value 저장소에 저장하고, 저장된 상태를 조회하는 일을 합니다.
- 권한을 체크하여 요청을 거부할 수 있습니다.
- 디버거 역할도 수행합니다.
- ❗️Pod을 할당하고 상태를 체크하는 것은 다른 모듈이 합니다.
- etcd : RAFT 알고리즘을 이용한 key-value 저장소입니다.
- 여러 개로 분산하여 복제함으로써 안정성을 높였으며, 속도도 빠릅니다.
- 클러스터의 모든 설정, 상태 데이터는 여기에 저장됩니다. 따라서 etcd만 잘 백업하면 언제든지 클러스터를 복구할 수 있습니다.
- etcd는 오직 API 서버와 통신합니다.
- Scheduler : 할당되지 않은 Pod를 여러가지 조건(자원, 라벨)에 따라 적절한 노드 서버에 할당해주는 모듈입니다.
- CM(Controller Manager) : CM(Controller Manager) : 현재 상태를 desired 상태로 유지하기 위해 쿠버네티스에 있는 거의 모든 오브젝트의 상태를 관리합니다. CM은 내부에 아주 다양한 컨트롤러들을 포함하고 관리하는 데몬이며, 이들 컨트롤러들은 오브젝트별로 철저히 분업화되어 있습니다.
- CCM(Cloud Controller Manager) : 클라우드(AWS, Azure, GCP)에 특화된 모듈입니다. 클라우드별 제어 로직을 포함하고 있으며, 각 클라우드 업체에서 자체 모듈을 만들어서 제공하고 있습니다.
- API : kubectl 요청 뿐 아니라 내부 노드까지의 모든 요청을 처리하는 모듈입니다.
- Node의 구성은 다음과 같습니다.
- kubelet : Control Plane의 API 서버가 전달해준 명령을 받고, 본인 노드의 현재 상태를 다시 API에 전달하는 역할입니다.
- 노드에 할당된 Pod의 생명주기를 관리합니다(컨테이너 생성 등).
- kube-proxy : kublet이 Pod를 관리하면, proxy는 Pod로 연결되는 네트워크를 관리합니다.
- 여러 개의 Pod를 라운드 로빈(RR) 형태로 묶어 서비스를 제공할 수 있습니다.
- kubelet : Control Plane의 API 서버가 전달해준 명령을 받고, 본인 노드의 현재 상태를 다시 API에 전달하는 역할입니다.
Pod 생성 과정
이제 쿠버네티스의 핵심 컨셉을 바탕으로, Pod가 생성될 떄 이것들이 어떻게 작동하는 지를 시퀀스 다이아그램을 통해 알아보도록 하겠습니다.
[다이아그램 출처 - Core Kubernetes: Jazz Improv over Orchestration]
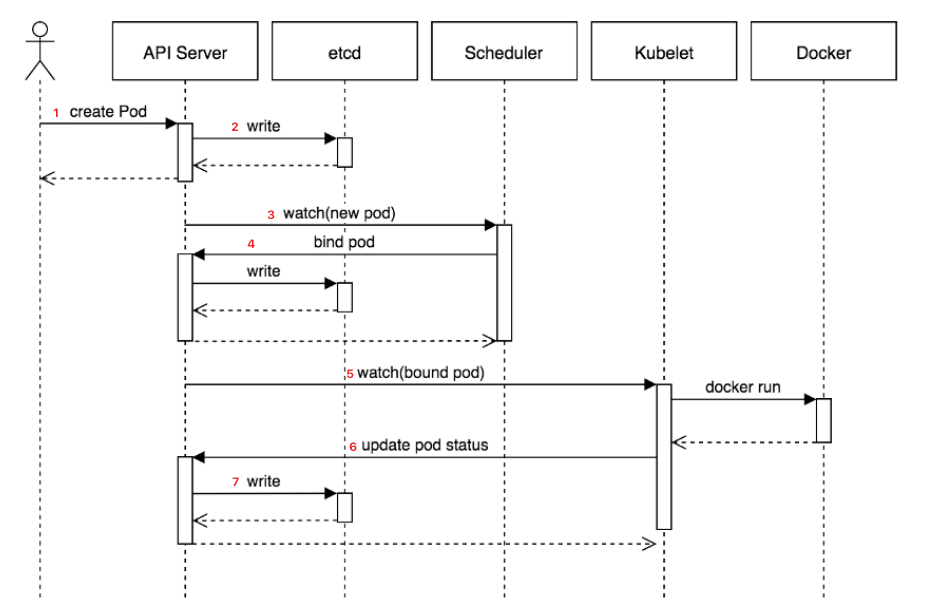
- 사용자의 요청
create Pod이 API Server로 왔습니다. - API는 요청을 etcd에 기록합니다.
- API 서버를 통해 이를 지켜보고 있던 Scheduler는 해당 Pod를 배치할 노드를 선택하고,
- 해당 정보를 다시 API 서버를 통해 etcd에 기록합니다.
- kublet은 API Server를 통해 etcd에 새로운 이벤트가 있다는 것을 감지하고, 이에 맞게 컨테이너를 구동합니다.
- 마지막 API Server를 통해 구동된 컨테이너 정보를 다시 etcd에 기록합니다.
ReplicaSet 생성 과정
이번에는 쿠버네티스의 핵심 컨셉을 바탕으로, ReplicaSet이 생성될 떄 이것들이 어떻게 작동하는 지를 시퀀스 다이아그램을 통해 알아보도록 하겠습니다.
[다이아그램 출처 - Sequential Breakdown of the Process]
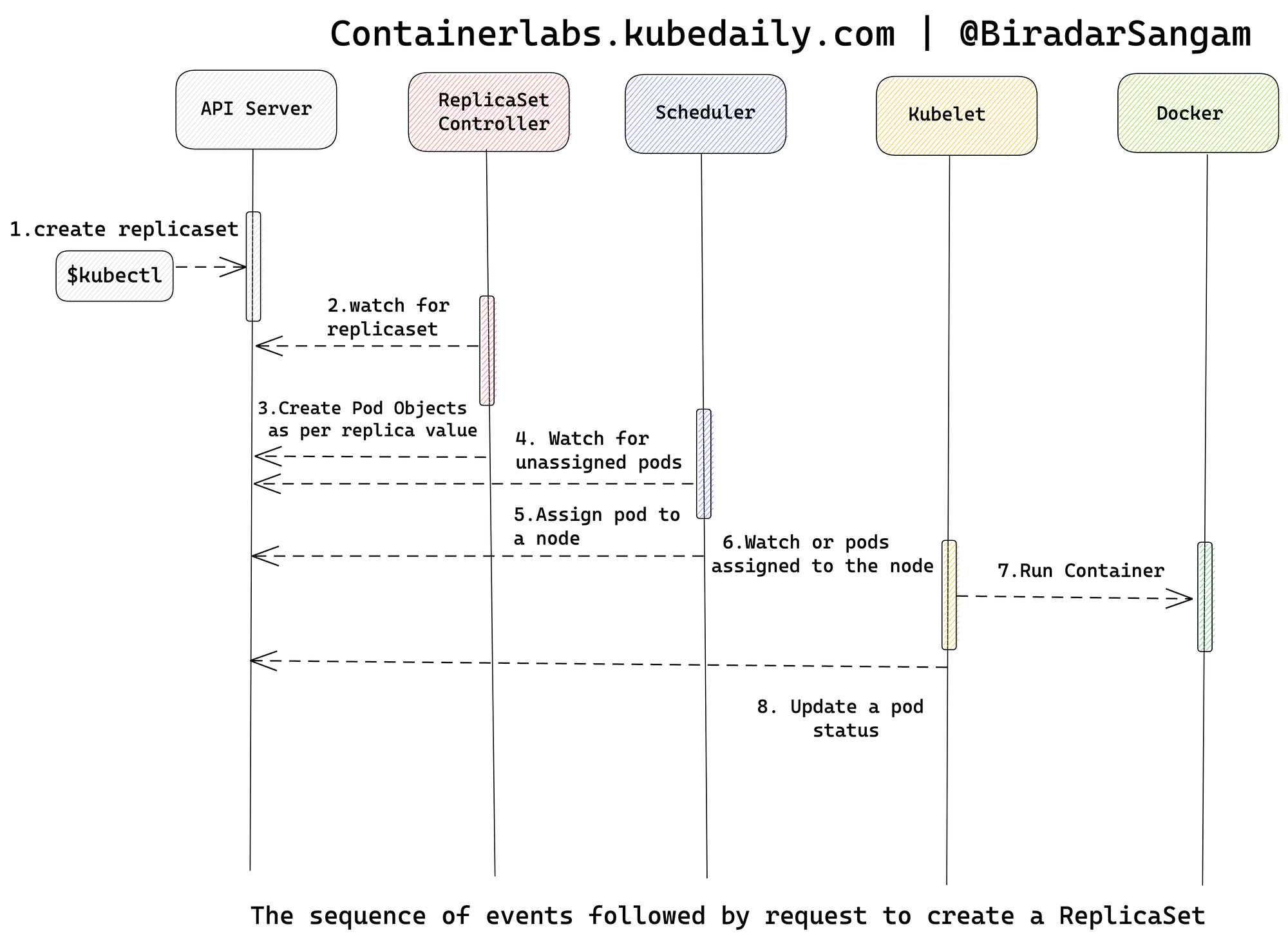
(현재 3개의 Pod가 운영중이라고 가정합니다.)
- Kubernetes 클라이언트는 API Server로
replicaset.yaml파일에 정의된 ReplicaSet생성을 요청합니다. - 해당하는 컨트롤러는(ReplicaSet Controller) 관련 정보를 모니터링 하다가 새로운 ReplicaSet 객체가 있음을 감지하였습니다.
- 파일의 replica 복제본 값이 (예를 들어) 5라고 구성되었기 때문에, 컨트롤러는 Pod를 5개로 정의합니다.
- API 서버를 통해 이를 지켜보고 있던 Scheduler는 할당되지 않은 두 개의 Pod가 있음을 감지하였습니다.
- Scheduler는 Pod를 할당할 노드를 결정하고, 해당 정보를 Api Server에 보냅니다.
- 이를 주시하던 kublet은 API Server를 통해 두 개의 Pod가 새롭게 할당되었음을 감지합니다.
- Kubelet은 Docker에 해당하는 컨테이너 생성을 요청합니다.
- 마지막으로 Kubelet은 API 서버에 업데이트된 Pod 상태를 보냅니다.
Reference
- https://kubernetes.io/ko/docs/concepts/overview/what-is-kubernetes/
- https://seongjin.me/kubernetes-core-concepts/
- https://iximiuz.com/en/posts/kubernetes-operator-pattern/
- https://www.hpe.com/kr/ko/what-is/container-orchestration.html
- https://www.sharedit.co.kr/posts/12040
- https://subicura.com/2019/05/19/kubernetes-basic-1.html?utm_source=subicura.com&utm_medium=referral&utm_campaign=k8s
- https://blog.heptio.com/core-kubernetes-jazz-improv-over-orchestration-a7903ea92ca
- https://www.containerlabs.kubedaily.com/Kubernetes/beginner/Sequential-Breakdown-of-the-Process.html#sequential-breakdown-of-the-process

AI Engineer : Lv 0