들어가기 앞서
프로그래밍 언어가 어떻게 메모리 자원을 관리하고 저장하는지 궁금한 계기가 생겼고 C언어의 맛을 살짝 보았다.
그래서 새롭게 알게 된 지역 변수,전역 변수, 상수 그리고 스택, 힙 영역등 메모리 구조를 통해서 바라본 변수 타입에 대한 내용을 기록하려한다.
그런데 왜 C언어가 아닌 자바로 키워드를 잡았을까?
그 이유는 바로 Java에는 독특한 타입인 String 이 있었기 때문이다.
서론을 끝마치고 어서 알아보자!
메모리의 구조
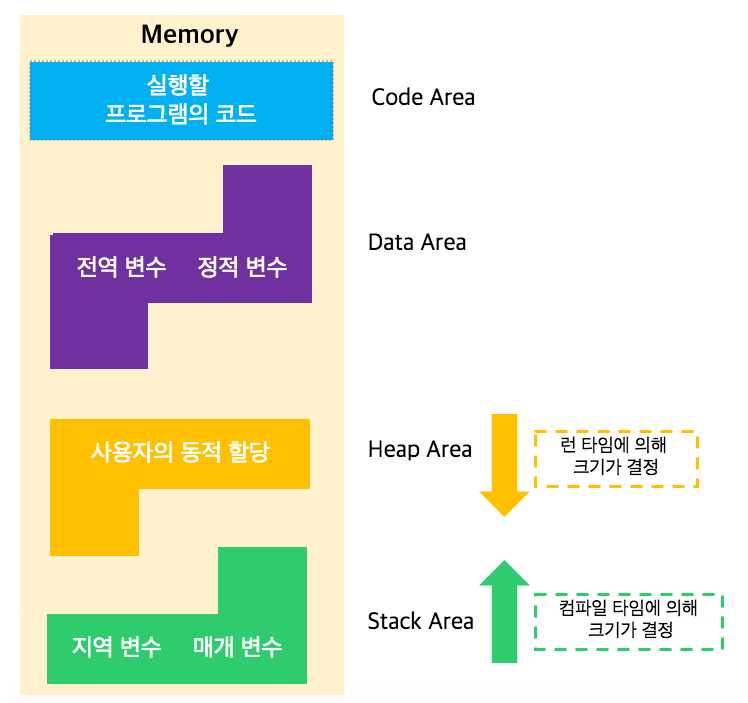
위의 이미지로 대략적인 흐름을 이해할 수 있는데
메모리 구조에서는 총 4개의 메모리 공간을 확인할 수 있다.
1. 코드 영역 (Code Area)
- 작성된 코드가 저장되는 공간
- cpu는 코드 영역에서 작성된 코드(텍스트)를 읽어옴.
2. 데이터 영역(Data Area)
- 정적 데이터들이 담긴다.
- 상수, static , 전역 변수 들이 저장되는 공간으로 프로그램이 종료 될 때까지 소멸되지 않고 남아있다.
여기서 핵심적인 부분은 데이터 영역에 저장된 데이터는 프로그램이 종료될 때 까지 남아있다는 것입니다.
전역 변수가 지역 변수와 달리 선언된 함수 외부에서도 호출될 수 있는건 할당받는 메모리 공간의 해제 작업이 일어나기 않고 남아 있기때문(종료까지 소멸되지 않으므로)
이러한 부분을 응용한다면 우리가 코드를 상수로 선언하는 이유를 알 수 있다.
2.1 상수로 선언하는 이유?
// 정수형 상수 선언
public static final int MAX_VALUE = 100;
// 문자열 상수 선언
public static final String COMPANY_NAME = "ABC Corporation";위와 같이 상수를 선언하는 이유는 가독성,불변성(수정 허용 x)의 이유도 있지만 메모리에서 얻는 이점을 말하면 이렇다.
장점
- 데이터 영역에 저장된 상수는 컴파일 타임에 메모리에 할당되므로 값을 읽는 과정이 빠르다.
(런타임 단계 X 컴파일 단계 O) - 값이 변경되지 않으므로 CPU 캐시에 상수 데이터가 캐시 될 가능성이 높아져 메모리 접근 시간을 단축시킬 수 있다.
단점
- 종료 시까지 메모리 자원을 해제할 수 없으므로 많은 양의 데이터가 적재시에 문제가 될 수 있다.
상수 선언의 이유를 데이터 영역을 이해함으로서 메모리에서 얻을 수 있는 이점과 연관시킬 수 있는것을 확인했습니다.
3. 스택(Stack) 영역 과 힙 영역(Heap)
스택(Stack)
- 지역변수,매개변수 가 LIFO(Last In Fisrt Out)의 형태로 적재되고 소멸된다.
- 각 스레드들이 독립적으로 가지고 있다.
- 함수가 호출될 때 메모리에 적재되며 함수가 종료되는 시점에서 사라진다.
힙(Heap)
- 객체,동적 배열등 동적으로 할당되는 메모리를 저장하는 영역이다.
- 스택에 주소 값이 참조되어 있으며 힙 영역은 각 스레드에게 공유되는 특성이있다.
- GC(Garbage Collector) 가 없다면 직접 수동으로 메모리를 해제해야 한다.
(번외) 힙 영역은 왜 스레드들에게 공유되는 구조일까?
스택(Stack)과 달리 힙 영역은 사용자가 동적으로 메모리를 할당하는 공간이다.
즉, 메모리의 크기가 일정하지 않을뿐더러 스택에 비해 차지하는 공간의 크기 또한 크다.
즉, 하나의 객체를 여러 참조 변수에서 공유해서 사용한다면
메모리를 효율적으로 관리할 수 있기 때문이아닐까
생각해 보았다.
3.1 매개 변수가 참조 타입이라면 ?
그렇다면 참조 타입의 경우 매개변수로서 어떻게 동작되는지 궁금하였다.
결론부터 말한다면 CallByValue 형식으로 값이 전달된다.
(CallByReference가 아닌 CallByValue 인 이유는
[자바가 언제나 Call By Value인 이유]
글을 참고했습니다.)
즉, 객체 자체가 전달되는 것이 아닌 객체의 참조 값(Reference)의 복사본이 전달되는것이다.
예시 코드
class MyClass {
int value;
MyClass(int value) {
this.value = value;
}
}
public class Main {
public static void main(String[] args) {
MyClass obj = new MyClass(10);
modifyObject(obj);
System.out.println(obj.value); // 출력 결과: 20
}
public static void modifyObject(MyClass obj) {
obj.value = 20; // 객체의 속성 값을 변경
}
}
그렇기 때문에 객체가 매개 변수로 전달되어도 복사된 참조 값이 넘어오기에 동일한 객체를 수정하는 것과 같으나
함수 호출과 종료시 생성되고 소멸되는 것을
알 수 있습니다.
4. 자바에서 String은 어떻게 동작되는가?
자바(Java)에서 String 을 생성하는 방식은 총 2가지가 있다.
바로 리터럴("") 생성 방식과 new 연산자 생성 방식이다.
public class Main {
public static void main(String[] args) {
// 리터럴로 생성된 문자열
String str1 = "hello";
// new 키워드를 사용하여 새로운 String 객체 생성
String str2 = new String("hello");
}
}
2가지 방식에서 주목해야 할 부분은 리터럴로 생성된 str1이다.
예를 들어서 다음과 같은 예시 코드를 살펴보자.
public class Main {
public static void main(String[] args) {
String a = "hello";
String b = "hello";
System.out.println("a 주소: " + System.identityHashCode(a));
// a 주소: 1072591677
System.out.println("b 주소: " + System.identityHashCode(b));
// b 주소: 1072591677
a = a + " world";
System.out.println("a 값: " + a); // a 값: hello world
System.out.println("b 값: " + b); // b 값: hello
}
}
위 예시 코드에서 두 개의 변수가 동일한 문자열 리터럴을 가리키며 동일한 주소값을 가진다.
하지만 새로운 문자열을 생성하여 변수 a에 할당하더라도
b의 값은 변하지않는다.
그 이유가 무엇일까?
바로 리터럴로 생성된 문자열은 불변(immutable) 의 속성을 가지기 때문이다.
즉, 불변하기때문에 동일한 문자열에 대해서 값을 새로 생성하지 않으며 변경되더라도 기존 값이 소멸되거나 사라지지않고 불변성을 유지한다.
그리고 String 타입이 불변성을 유지할 수 있는 이유는
Heap 영역에 속한 String pool이 있기 때문이다.
4.1 String pool
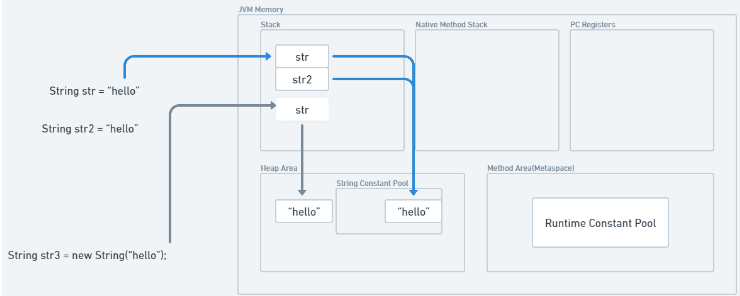
new 연산자로 생성된 String은 Heap Area 에 배치되지만,
리터럴로 생성된 값은 String pool에 배치되는것을 확인할 수 있다.
public class Main {
public static void main(String[] args) {
// String pool 저장
String str = "hello";
String str2 = "hello";
// Heap Area 저장
String str3 = new String("hello");
}
}
자바에서 리터럴로 생성된 문자열이 불변(immutable)의 속성을 지니는 것은 String pool에 의해 관리되기 때문인 것을 알 수 있습니다.
문자열은 new 로 생성하는 것 보다 리터럴로 생성하는 것이 String pool의 내부 최적화의 이점을 얻을 수 있습니다.
4.2 String.intern()
하지만 new 연산자로 생성해도 intern()메서드를 통해
String pool에 저장될 수 있습니다.
public class Main {
public static void main(String[] args) {
String str = "hello";
String str2 = "hello";
// Heap Area -> String pool
String str3 = new String("hello").intern();
System.out.println(str2 == str3); //true
}
}intern() 메서드의 내부 동작은 다음과 같습니다.
- String pool에 문자열이 존재하는지 검색
- 문자열이 존재하지 않는다면 String pool 에 저장 및 주소 전달
- 문자열이 존재한다면 기존에 있는 주소 값 전달
하지만 주의해야 할 점은 intern() 메서드는 String pool 에 값의 유무를 검색하므로 추가적인 로직이 생기며,
동적 문자열등도 String pool 에 input 시킬 수 있기때문에
사용이 권장되지 않습니다.
(번외) String에서 == 이 아닌 equals를 사용하는 이유
String 값 비교할 때에 동일 비교 연산자인 == 대신에 equals()를 사용하는 이유는 무엇일까?
어차피 String pool에 저장되면 동일한 주소 값을 가지므로
동일 연산자== 를 사용해도 되는 것 아닐까?
ORM, DB등에서 조회되는 동적 문자열은 String pool에 저장되지 않는다.
그러므로==보다equals()를 사용하는 것이 더 적합하고 안전한 방식이다.
마무리
- 메모리 구조는 코드 영역,데이터 영역,스택,힙 으로 나눌 수 있다.
- 상수 선언은 데이터 영역에 저장되며 메모리 속도에 이점을 얻을 수 있으나 자주 사용되는 것은 지양해야 한다.
- 스택과 힙은 메모리 자원 할당과 관리에서 결정적인 차이점이 나타난다.
- String의 리터럴은 불변성을 유지하며 String pool에 의해 관리되므로 new 연산자보다 리터럴 생성이 더 이점이 있다.
- new 연산자를 통해 생성되도 intern()메서드로 String pool에 관리될 수 있지만 권장되지않는다.
