S3는 AWS에서 사용할 수 있는 객체 스토리지 서비스입니다. 무한대로 확장 가능하고 사용자에게 고가용성과 높은 보안, 성능을 제공하며 저장된 객체의 사용 빈도나 접근 빈도에 따라 스토리지 클래스를 조정하여 비용 최적화가 용이합니다. 정적 웹 호스팅이 가능하여 웹 서비스를 제공하는 할 때 활용할 수 있고 그 밖에 백업 및 복원, 재해복구, 빅데이터, 콘텐츠 전송, 금융, 디지털 마케팅, 전자상거래 같은 분야에서도 활용할 수 있습니다.
Use case
| Use case | 설명 |
|---|---|
| 백업 및 복구 | 뛰어난 내구성과 확장성을 제공하며, 버전 관리 기능을 통한 데이터 보호 기능 제공과 하이브리트 구성을 통해 기업 내 데이터 백업 및 복원 기능을 제공할 수 있음 |
| 재해 복구 | S3의 내구성과 안정성이 뛰어난 글로벌 인프라를 활용하여 데이터 보호 및 다른 리전으로 교차 리전 복제(CCR) 서비스를 제공 |
| 아카이브 | 중요한 장기 데이터 보관에 유용 Nasdaq에서 7년 분량의 데이터를 S3 Glacier에 저장 |
| 하이브리드 클라우드 스토리지 | AWS Storage Gateway와 연계하여 온프레미스 환경에서 클라우드 스토리지를 활용할 수 있으며, 데이터 백업 및 재해복구를 원활하게 수행 가능 |
| 애플리케이션 호스팅 | 서버 설정 및 관리 없이 간단하게 애플리케이션을 배포 및 확장 가능 높은 가용성과 저렴한 비용이 장점이지만 복잡한 애플리케이션 실행에 적합하지 않고 일부 리전에서만 사용가능 |
| 미디어 호스팅 | 사진이나 영상과 같은 미디어 컨텐츠를 S3에 저장하고 CDN을 활용해 호스팅 가능 |
| 데이터레이크 & 빅데이터 분석 | 제약 또는 재무 데이터, 사진, 영상과 같은 멀티미디어 파일처럼 어떠한 형태의 데이터든 빅데이터 분석용 데이터 레이크로 활용 가능 Sysco는 자체 데이터 분석과 비즈니스 인사이트를 얻는다. |
| 소프트웨어 배포 | |
| 정적 웹 호스팅 | 정적 웹 페이지를 S3에 저장하고 웹 호스팅 기능을 사용하면 S3에서 제공하는 앤드포인트로 웹 사이트 접속 가능 |
S3 Bucket
S3 Bucket은 S3에 객체를 저장하는데 사용되며 상위 레벨 디렉토리로 표시합니다. 버킷은 객체를 저장하고 있어 버킷 정책을 사용해 객체에 접근할 수있는 권한을 설정할 수 있으며 버킷 정책은 IAM 정책과 구별됩니다. 버킷을 생성할 때 리전 수준에서 생성되며 버킷의 이름은 AWS 전체 네트워크에서 고유해야합니다. 버킷의 이름을 설정할 때는 아래와 같은 규칙을 따라야합니다.
- 이름 규칙
- 대문자나 밑줄이 없어야한다.
- 3~63자 사이의 길다
- IP 주소 형식 금지
- 소문자나 숫자로 시작
- 몇가지 접두사 및 접미사 제한
- 문자, 숫자, 하이픈만 허용
S3 Object
Object는 키-값 형식의 객체로 아래와 같은 특징을 가지고 있습니다.
| 특징 | 설명 |
|---|---|
| 키는 객체의 경로 | 각 객체는 키를 가지고 있고 키는 파일의 전체 경로를 의미 s3://my-bucket/my_file.txt s3://my-bucket/my_folder1/another_folder/my_file.txt |
| 키는 접두사 + 객체이름으로 구성 | my_folder1/another_folder : 접두사 → 디렉토리 주소로 보이는 것들이 접두사 my_file.txt : 객체 이름 S3 자체로는 디렉토리의 개념이 없다. |
| 객체의 값은 본문의 내용 | 최대 객체 크기는 5TB 5GB보다 큰 파일이 업로드되면 파일을 “multi-part upload”를 사용해야한다. |
| 메타데이터 | 객체의 키-값 쌍 리스트 |
| 태그 | 유니코드 키-값 쌍은 최대 10개까지 가능 보안과 수명 주기에 유용 |
| 버전 ID | 버전 관리를 활성화 하면 버전 ID를 가진다. 버전 관리를 통해 이전 버전으로 복원이 가능하다. |
Security & Bucket Policies
Security
- User-Based
- IAM 정책 : 어떤 API 호출이 특정 IAM 사용자를 위해 허용되어야 하는지 승인
- Resource-Based
- Bucket 정책 : S3 콘솔에서 직접 할당할 수 있는 전체 버킷 규칙
- 가장 일반적으로 사용한다.
- 특정 사용자가 들어올 수 있게 하거나 다른 계정의 사용자를 허용할 수 있다. → 교차 계정 액세스
- Object ACL - Access Control List : 보다 세밀한 보안으로 활성화/비활성화 선택 가능
- Bucket ACL - 덜 일반적인 보안
- Bucket 정책 : S3 콘솔에서 직접 할당할 수 있는 전체 버킷 규칙
- IAM 정책이 S3 객체에 액세스 할 수 있나?
- IAM 권한이 이를 허용하거나 리소스 정책이 허용하는 경우에 가능
- 명백한 거부는 존재하지 않으며 IAM 원칙이 특정 API 호출 시 S3 객체에 액세스할 수 있다.
- 암호키를 사용하여 객체를 암호화
S3 Bucket Policies
- JSON 기반 정책
- Resources : 정책이 허용되는 버킷과 객체
- Effect : 허용 / 거부 설정
- Action : 허용이나 거부되는 API 집합
- Principal : 정책이 적용되는 계정이나 사용자
- 사용하는 곳
- Bucket의 공개 액세스 허용
- 객체 업로드 시 강제 암호화
- 다른 계정으로의 업로드 허용
Bucket setting for Block Public Access
- 기업 데이터 유출을 방지하기 위한 추가 보안 계층으로 AWS에서 개발
- S3 버킷 정책을 설정하여 공개로 만들더라도 이 설정이 활성화되어 있으면 버킷은 절대로 공개되지 않는다.
- 계정 수준에서 설정할 수 있다.
Static Web site
- Amazon S3를 사용하여 인터넷에서 액세스 가능한 정적 웹 사이트를 호스팅 할 수 있다.
- 웹 사이트의 URL은 리전에 따라 다를 수 있다.
- 버킷에서 공개 읽기가 활성화되지 않은 경우에는 호스팅이 되지 않을 수 있다.
- 403 Forbidden 오류가 발생하면 공개를 허용하는 S3 버킷 정책을 첨부해야한다.
버전 관리
- 버킷 수준에서 활성화하는 기능으로 파일에 버전을 기록할 수 있다.
- 파일을 업로드할 때마다 키에 버전이 생성된다.
- 동일한 키에 파일을 덮어쓰는 경우 버전이 올라가면서 생성된다.
- 버전 관리를 활성화하는 것이 좋다.
- 의도치 않은 삭제에서 파일을 보호할 수 있다.
- 한 파일을 삭제하는 경우에는 사실 삭제 마커를 추가한 것이므로 이전 버전으로 복구하면 삭제한 파일이 복구된다.
- 이전 버전으로 쉽게 롤백이 가능하다.
- 주의 사항
- 버전 관리 활성화하기 전에 버전 관리가 적용되지 않은 모든 파일은 null 버전을 가진다.
- 버전 관리를 중단해도 이전 버전을 삭제하지는 않는다.
S3 Replication
Replication
- S3 복제를 하기 위해서 소스 버킷과 복제 대상 버킷 모두 버전 관리 기능이 활성화되어 있어야 한다.
- S3에 올바른 IAM 권한 - 읽기/쓰기 권한을 부여해야한다.
- 서로 다른 AWS 계정간에 비동기식 복제가 가능
- 복제는 백그라운드에서 이루어진다.
- Use Case
- CRR - 컴플라이언스 - 법규나 내부 체제 관리, 다른 리전간 지연 시간 감소, 계정 간 복제
- SRR - 다수의 S3 버킷간의 로그 통합, 개발 환경이 별도로 있어 운영 환경과 개발 환경간의 실시간 복제를 필요로 할 때
CRR - Cross Region Replication
- 소스 버킷과 복제 대상 버킷의 리전이 달라야 한다.
SRR - Same Region Replication
- 소스 버킷과 복제 대상 버킷의 리전이 달라야 한다.
Note
- 복제를 활성화한 후에는 새로운 객체만 복제대상이 된다.
- 기존의 객체를 복제하기 위해서는 S3 Batch Replication 기능을 사용해야한다.
- 기존 객체부터 복제에 실패한 객체까지 복제할 수 있는 기능
- 작업 삭제
- 소스 버킷에서 대상 버킷으로 삭제 마커를 복제
- 버전 ID로 삭제하는 경우 버전 ID는 복제되지 않는다.
- 영구적인 삭제여서 악의적으로 한 버킷에서 다른 버킷으로 ID 삭제 마커를 복제해서는 안되기 때문
- 체이닝 복제는 불가능
- 1번 버킷의 복제가 2번 버킷이고 2번 버킷의 복제가 3번 버킷일 때 1번 버킷의 객체가 3번으로 복제되지는 않는다.
S3 Storage Classes
Classes
- Amazon S3 Standard - 범용
- Amazon S3 Standard-Infrequent Access (IA)
- Amazon S3 One Zone-Infrequent Access
- Amazon S3 Glacier Instant Retrieval
- Amazon S3 Glacier Flexible Retrieval
- Amazon S3 Glacier Deep Archive
- Amazon S3 Intelligent Tiering
- 객체를 수동으로 스토리지 클래스 정할 수도 있고 수명주기관리를 통해 스토리지 클래스간 자동으로 이동시킬 수 있다.
S3 Durability & Availability
- Durability
- 내구성은 Amazon S3로 인해 객체가 손실되는 횟수를 나타낸다.
- Amazon S3는 99.999999999%의 매우 뛰어난 내구성을 보장한다.
- 1천만개의 객체가 저장되어 있을 때 평균적으로 1만년에 한번 객체 손실이 일어나는 비율
- 내구성은 모든 스토리지 클래스가 동일하게 보장한다.
- Availability
- 서비스가 얼마나 용이하게 제공되는지를 나타낸다.
- 스토리지 클래스에 따라 다르다.
- S3 Standard = 99.99% → 1년 중 약 53분 동안은 서비스를 사용할 수 없다.
S3 Standard - 범용
- 99.99% 가용성
- 자주 액세스하는 데이터에 사용된다.
- 지연 시간이 짧고 처리량이 높다.
- AWS에서의 2개의 기능 장애를 동시에 버틸 수 있다.
- Use case
- 빅 데이터 분석
- 모바일과 게임 애플리케이션, 콘텐츠 배포
IA - Infrequent Access
- 자주 액세스하지 않지만 필요한 경우 빠르게 액세스 해야하는 데이터를 저장
- S3 Standard보다 비용이 적게 든다.
- 데이터를 검색하는데 비용이 든다.
- S3 Standard IA
- 99.9% 가용성
- Use case
- 재해 복구와 백업
- S3 One Zone-IA
- 단일 가용 영역 내에서는 높은 내구성을 갖지만 가용 영역이 파괴되면 데이터를 모두 잃게 된다.
- 99.5%의 가용성
- Use Case
- 온프레미스 데이터를 2차 백업
- 재생성 가능한 데이터를 저장
S3 Glacier Storage Classes
- 콜드 스토리지
- 아카이빙과 백업을 위한 저비용 객체 스토리지
- 스토리지 비용과 검색 비용이 발생한다.
- Amazon S3 Glacier Instant Retrieval
- ms 단위로 데이터 검색이 가능
- 분기에 한 번 액세스 하는 데이터에 적합
- 최소 보관 기간 : 90일
- Amazon S3 Glacier Flexible Retrieval - 이전에 Amazon S3 Glacier
- Options
- Expedited : 1~5분 이내의 데이터 검색 시간
- Standard : 3~5시간 이내의 데이터 검색 시간
- Bulk : 5~12시간 이내의 데이터 검색 시간, 무료
- 최소 보관 기간 : 90일
- Options
- Amazon S3 Glacier Deep Archive - 장기 보관 스토리지
- Options
- Standard : 12시간의 데이터 검색 시간
- Bulk : 48시간의 데이터 검색 시간
- 저장 비용이 가장 저렴
- 최소 보관 기간 : 180일
- Options
S3 Intelligent-Tiering
- 객체의 사용 패턴에 따라 액세스된 티어 간에 객체를 이동할 수 있게 한다.
- 소액의 모니터링 비용과 티어링 비용이 발생
- 데이터 검색 비용이 발생하지 않는다.
- Tier
- Frequent Access Tier (Automatic) : 기본 티어
- Infrequent Access Tier (Automatic) : 30일 동안 액세스하지 않은 객체 전용 티어
- Archive Instant Access Tier (Automatic) : 90일 동안 액세스하지 않은 객체 전용 티어
- Archive Access Tier (Optional) : 90에서 700일 이상까지 구성 가능
- Deep Archive Access Tier (Optional) : 180일에서 700일 이상까지 구성 가능
- 객체의 티어를 알아서 관리해주므로 사용하기 편한 스토리지다.
Lifecycle
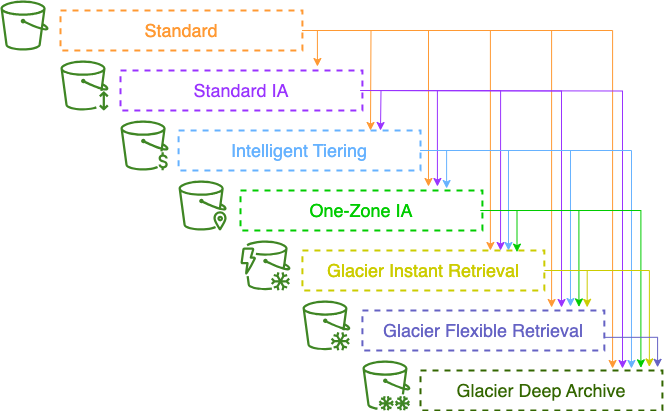
Lifecycle Rules
- Transition Actions : 다른 스토리지 클래스로 이전하기 위해 객체를 설정
- 객체가 생성된지 60일이 지나면 Standard IA로 이전
- 6개월이 지나면 아카이빙을 위한 Glacier 클래스로 이전
- Expiration Actions : 일정 시간이 지나면 객체를 만료시켜 삭제하도록 설정
- 액세스 로그파일을 365일 뒤에 삭제
- 버전 관리를 활성화 했을 경우 이전 버전의 파일을 삭제
- 불완전한 멀티파트 업로드를 삭제 - 업로드를 시작한지 일정 시간이 지났는데도 완료되지 않으면 삭제
- 접두어나 태그 규칙을 설정할 수 있다.
S3 Analytics
- 객체를 다른 클래스로 이전할 최적의 일수를 결정할 수 있는 방법
- S3 Standard나 Standard IA에 관한 추천사항을 제시
- One-Zone IA나 Glacier와는 호환되지 않는다.
- 매일 결과가 업데이트되고 데이터 분석 결과는 24시간에서 48시간이 지난 뒤에 볼 수 있다.
Requester Pays
- 일반적으로 버킷 소유자는 버킷과 관련된 모든 Amazon S3 스토리지 및 데이터 전송 비용을 지불
- 데이터를 요청하는 사용자가 데이터를 받는데 사용되는 네트워킹의 비용도 소유자가 지불
- 용량이 큰 파일이 많고 일부 사용자가 이를 다운로드하려고 할 때 요청자 지불 버킷을 활성화해야한다.
- 버킷 소유자가 아닌 객체를 다운로드하는 요청자가 다운로드 비용을 지불
- 대량의 데이터 셋을 다른 계정과 공유할 때 매우 유용
- 요청자는 익명을 사용할 수 없으며 AWS 인증을 받은 요청자만 가능
Event Notification
- S3 이벤트는 객체가 생성, 삭제, 복구, 복제 등과 같은 작업이 발생하는 것을 의미
- 이벤트 필터링 가능
- Use case
- S3에 일어나는 특정한 이벤트에 자동으로 반응하려고 할 때 사용
- 업로드된 모든 이미지의 섬네일을 생성
- 원하는 만큼 S3 이벤트를 만들 수 있고 원하는 타겟에도 전송할 수 있다.
- 이벤트들은 통상적으로 몇 초안에 대상으로 전달되지만 간혹 몇 분이 걸릴 수도 있다.
IAM Permission
- S3에서 데이터를 SNS 토픽에 전송하기 위해서 SNS 리소스 정책을 첨부
- SQS를 사용할 경우 SQS 리소스 액세스 정책을 만들어야 한다.
- 람다 함수의 경우 람다 리소스 액세스 정책을 만들어야 한다.
Amazon EventBridge
- S3에서 발생한 모든 이벤트는 Amazon EventBridge로 이동한다.
- EventBridge도 사용자가 규칙을 설정할 수 있다.
- 18가지 서비스에 이벤트를 전송할 수 있다.
- JSON 규칙을 사용해서 고급 필터링 옵션을 사용할 수 있다.
- 메타데이터
- 객체 사이즈
- 이름
- 필터링 후 한꺼번에 다수의 대상에 전송가능
- 아카이빙, 이벤트 중계, 안정적인 전달과 같은 기능을 제공
Performance
- 기본적으로 S3는 요청이 많을 때 자동으로 성능이 확장되며 지연시간은 100~200ms로 매우 짧다.
- 접두사마다 초당 3500개의 PUT/COPY/POST/DELETE와 5500개의 GET/HEAD 요청 처리할 수 있다.
- 버킷 내 접두사의 개수는 제한이 없다.
- 만일 4개의 접두사에 읽기 요청을 균등하게 분산하면 초당 22000개의 GET/HEAD 요청을 처리할 수 있다.
Multi-Part upload
- 100MB가 넘는 파일은 멀티파트 업로드를 사용하는 것이 좋다.
- 5GB가 이상의 파일은 멀티파트 업로드를 반드시 사용해야한다.
- 병렬 전송을 사용하므로 대역폭을 최대화하여 전송 속도를 높일 수 있다.
- S3에 업로드과 완료되면 다시 하나의 파일로 합친다.
S3 Transfer Acceleration
- 파일을 AWS 엣지 로케이션으로 전송해서 전송 속도를 높이고 데이터를 대상 리전에 있는 S3 버킷으로 전달
- 엣지 로케이션은 리전보다 수가 많으며 계속 수가 증가하고 있다.
- 전송 가속화는 멀티파트 업로드와 같이 사용할 수 있다.
- 엣지 로케이션으로 데이터를 보내는 것은 공용 연결을 사용하지만 엣지 로케이션에서 S3 버킷으로 보내는 것은 AWS 사설 네트워크를 사용하는 것이므로 사설 네트워크의 사용량을 최대화한다.
S3 Byte-Range Fetches
- S3 바이트 범위 가져오기
- 파일에서 특정 바이트 범위를 가져와서 GET 요청을 병렬화
- 특정 바이트 범위를 가져오는 것이 실패하더라도 더 작은 바이트 범위에서 재시도하므로 실패에 대한 복원력이 높다.
- Use case
- 다운로드 속도를 높일 때 사용, 모든 요청을 병렬화 된다.
- 파일의 일부만 검색
S3 Select & Glacier Select
- 데이터를 검색한 후에 필터링을 하면 너무 많은 데이터를 사용하게 된다.
- 만일 서버 측에서 필터링을 하면 필요한 데이터만을 사용할 수 있다.
- SQL 문으로 간단하게 행과 열로 필터링 할 수 있다.
- 네트워크 전송이 줄어들기 때문에 데이터 검색과 필터링에 드는 클라이언트 측의 CPU 비용이 줄어든다.
- 최대 400% 빨라지고 80% 저렴해진다.
Batch Operation
- 단일 요청으로 기존 S3 객체에서 대량 작업을 수행하는 서비스
- Use case
- 한 번에 많은 S3 객체의 메타데이터와 속성을 수정할 수 있다.
- S3 버킷 간 객체를 복사
- S3 버킷 내 암호화되지 않은 모든 객체를 암호화할 수 있다.
- ACL이나 태그를 수정
- S3 Glacier에서 한 번에 많은 객체를 복원
- 람다 함수를 호출하여 S3 Batch Operation의 모든 객체에서 사용자 지정 작업을 수행할 수 있다.
- 작업은 객체의 목록, 수행할 작업, 옵션 매개 변수로 구성
- 스크립트 대신 S3 Batch Operation을 사용하는 이유는 재시도를 관리할 수 있고 진행 상황을 추적하고 작업 완료 알림을 보내고 보고서 생성이 가능하다.
- S3 Inventory 기능을 사용해 객체 목록을 가져오고 S3 Select를 사용해 객체를 필터링
참고 자료

오늘은 무엇을 배웠니?