Java의 JIT(Just-In-Time) 컴파일러: 개요 및 동작 방식
JIT 컴파일러란?
Java는 플랫폼 독립성을 보장하기 위해 바이트코드라는 중간 형태로 컴파일된 후 인터프리터 방식으로 JVM에서 실행됩니다.
JIT(Just-In-Time) 컴파일러는 인터프리터 방식의 한 줄씩 해석하고 실행하기 때문에 성능이 떨어질 수 있는 이 성능 문제를 해결하기 위해 도입된 기술입니다.
핫스팟(Hotspot)을 찾아내고, 해당 코드를 네이티브 기계어로 컴파일하여 성능을 최적화합니다.🌝
JIT 컴파일러의 동작 방식
인터프리팅 및 프로파일링
JVM은 처음에는 바이트코드를 인터프리터 방식으로 한 줄씩 실행합니다. 동시에 JVM은 메서드 호출 빈도를 모니터링하여 자주 호출되는 메서드나 반복되는 루프는 핫스팟으로 감지하여 JIT 컴파일러가 네이티브 코드로 변환하게 됩니다.
JIT 컴파일과 최적화
네이티브 기계어로 변환하는 과정에서 다양한 최적화 기법인 인라이닝, 루프 언롤링, 가상 메서드 호출 최적화 등을 적용합니다.
(가상메서드란? 다형성을 지원하기 위해 런타임에 객체의 실제 호출할 메서드를 결정하는 메서드)
- 인라이닝(Inlining): 자주 호출되는 메서드의 코드를 그 호출 지점에 직접 삽입하여 메서드 호출하는기법
- 루프 최적화(Loop Optimization): 자주 반복되는 루프의 구조를 분석하여 불필요한 연산을 줄이거나, 루프를 펼쳐서(하드 코딩) 성능을 최적화하는 기법
- 데드 코드 제거(Dead Code Elimination): 실행되지 않는 코드를 제거하여 리소스 낭비를 줄임
- 디버추얼라이제이션(Devirtualization): 자주 호출되는 가상 메서드를 정적 메서드 호출로 변환하여 동적 디스패치 오버헤드를 줄이는 최적화 기법입니다.
티어드 컴파일(Tiered Compilation)
Java 7버전부터 JVM은 티어드 컴파일(Tiered Compilation)이라는 방식을 사용합니다. 이는 JVM이 인터프리터, C1 컴파일러, C2 컴파일러를 함께 사용해 성능을 점진적으로 최적화하는 방식입니다.
Tier 0: 인터프리터는 프로그램을 빠르게 실행할 수 있지만 성능이 낮습니다.
Tier 1~3: C1 컴파일러는 경량 최적화를 적용하여 성능을 향상시키면서도 빠른 컴파일을 제공합니다. 주로 자주 호출되지 않는 코드나 클라이언트 애플리케이션에 적합합니다.
Tier 4: C2 컴파일러는 더 깊이 있는 분석과 고급 최적화를 적용합니다. 서버 애플리케이션처럼 장시간 실행되는 프로그램에 주로 사용됩니다.
티어 전환 플로우
- 프로그램 시작 → 인터프리터(Tier 0) → 빠른 실행 시작, 프로파일링 수행
- 핫스팟 발견 → C1 컴파일러(Tier 1) → 경량 최적화 적용 및 프로파일링 데이터 수집
- 자주 호출되는 코드 → C1 컴파일러(Tier 2~3) → 프로파일링 기반 최적화 적용
- 핫스팟 집중 최적화 필요 → C2 컴파일러(Tier 4) → 고급 최적화 적용 및 성능 극대화
여기서 궁금한 점이 생겼습니다.💡
핫스팟의 기준이 되는 자주 호출되는 메소드의 횟수와 최적화를 진행한다면 호출 횟수가 적어진(디옵티마이제이션) 시점은 언제인지가 궁금해졌고 위의 개념들을 더 이해하기 위해 실습을 통해 알아보도록 하겠습니다.
실습
테스트 환경입니다.

예시코드
package org.example;
public class OptimizationExample {
public static Long num = 0L;
public static void main(String[] args) {
OptimizationExample example = new OptimizationExample();
Parent parent = new Child();
// 핫스팟 유발 지점 (인라이닝이 발생할 가능성)
for (int i = 0; i < 10000; i++) {
example.inlinedMethod();
// num이 100000일때 부모 객체로 변경
if(num == 100000) {
parent = new Parent();
}
parent.doSomething();
num++;
}
}
// 1. 인라이닝 가능 메서드: 자주 호출되며, 간단한 연산이 포함
public void inlinedMethod() {
int a = 5 + 10; // 간단한 연산
}
}
// 가상 메서드 최적화 테스트용 부모 클래스
class Parent {
public int doSomething() {
return 1;
}
}
// 가상 메서드 최적화 테스트용 자식 클래스
class Child extends Parent {
@Override
public int doSomething() {
return 2;
}
}예시)

각 칸의 의미는
8661 => 컴파일 순서
3050 => 호출 횟수
3 => 티어
티어 확인
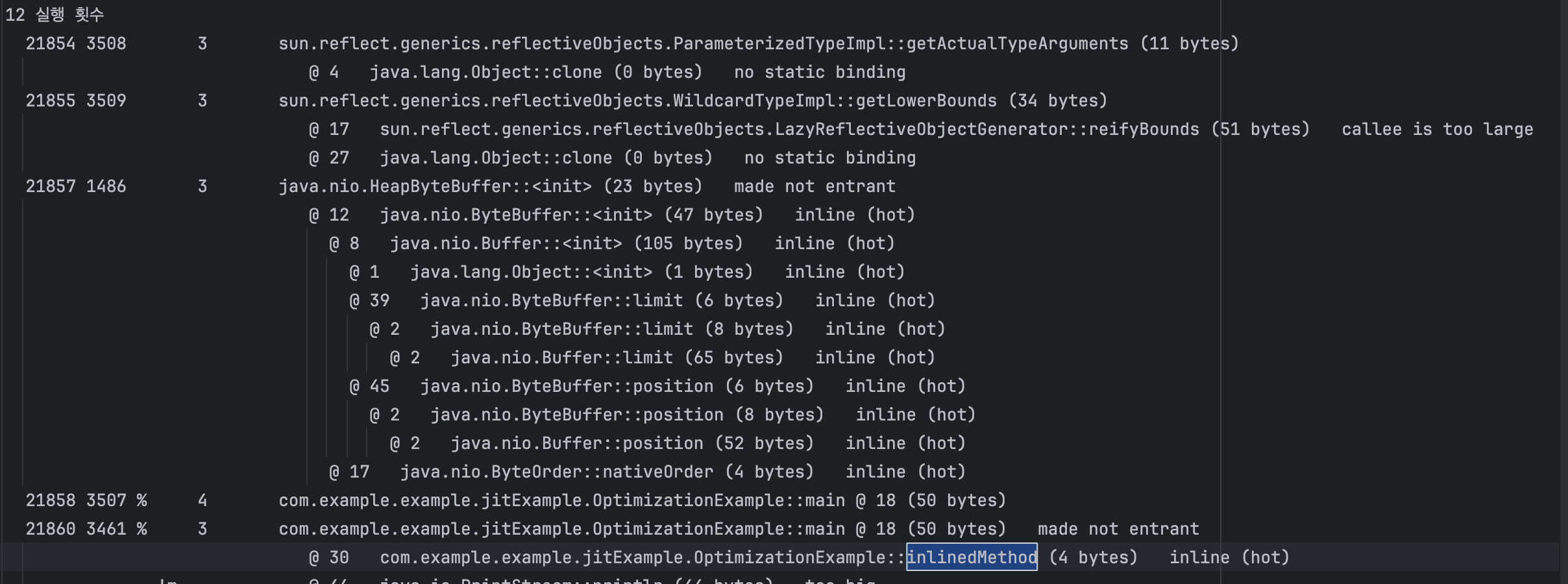
JIT컴파일러에 의해 컴파일 되고 현재 3Tier인 상태입니다. 반복문 횟수는 약 3천번
1만4천번의 반복문으로 호출한 끝에 4Tier로 올라가며 C2컴파일러를 사용하여 더욱더 고급최적화가 적용된걸 볼 수 있습니다.

mode not entrant 문구의 경우 티어가 올라가거나 내려갈때 사용되는 문구입니다.
인라이닝
7천번의 반복문에 인라이닝이 발동되어 inline이라는 문구가 붙은걸 확인할 수 있음

1만2천번의 반복문에 해당 인라인이 핫스팟으로 판별되어 inline(hot)문구를 붙은걸 확인할 수 있음
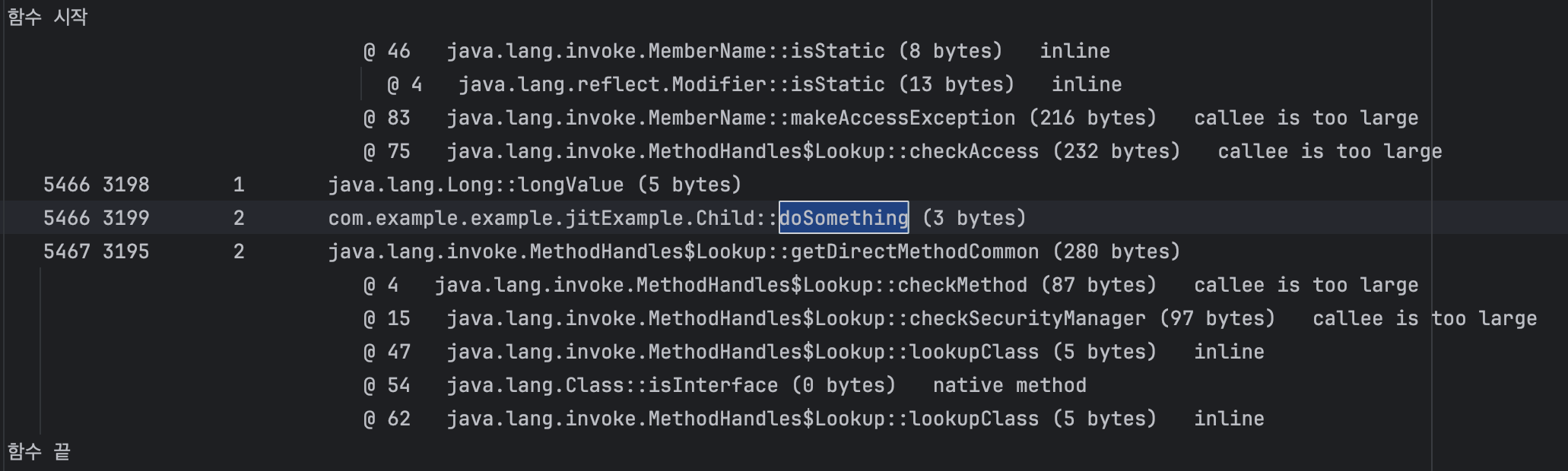
디버추얼라이제이션
위 예시코드의 num이 100000까지는 childe의 doSomthing을 호출하다가 그 이후에는 parent의 doSomthing을 호출에 대한 가상 메소드 최적화 부분을 보도록 하겠습니다.
가상테이블의 정적메소드로 호출됨
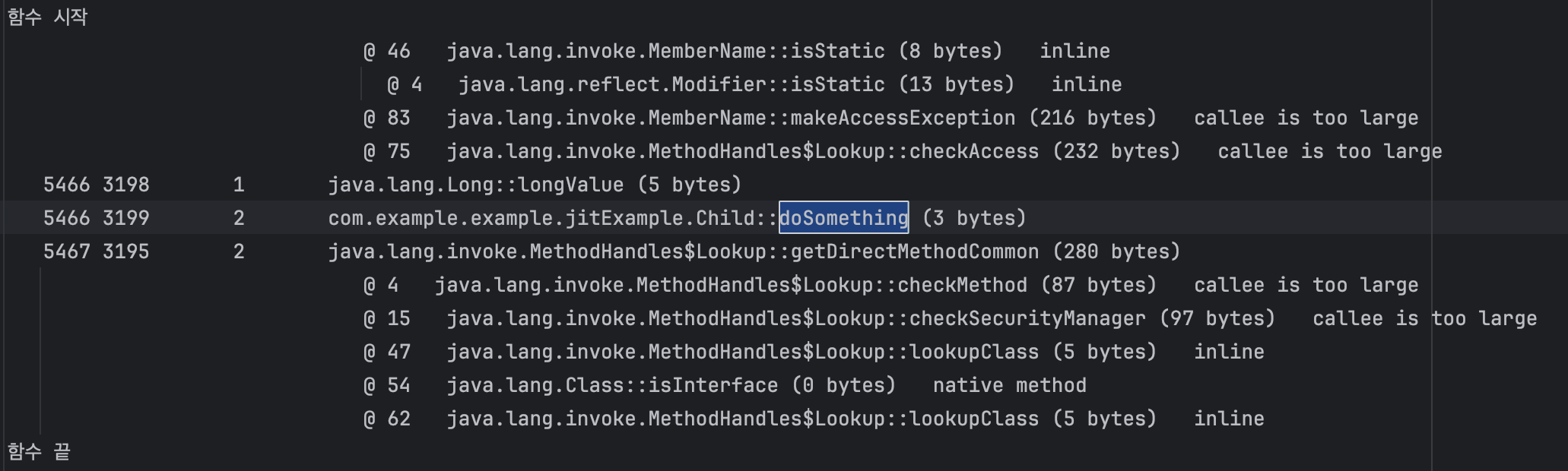
C2컴파일러로 격상하며 아직 child의 doSomthing이 호출되는것을 확인

parent의 doSomthing으로 바뀌며 아직 동적으로 선택됨 no static binding 문구를 확일할 수 있음
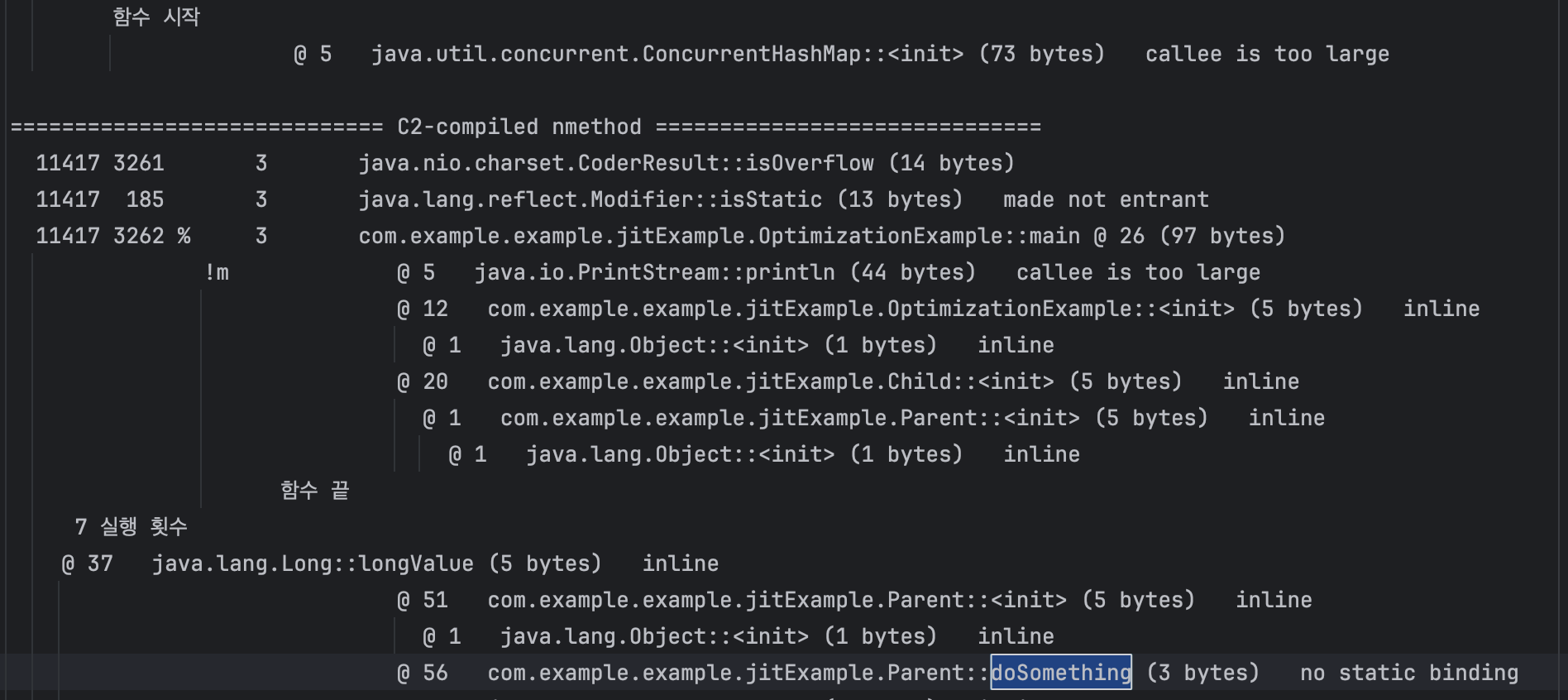
no static binding으로 바뀌며 정적으로 선택되는것을 확인

child와 parent의 doSomthing이 아직 inline(hot)문구가 보이는것을 확인

결론
JIT컴파일러가 어떤식으로 인터프리팅 되는 어떤 방식으로 어떤 동작으로 최적화를 해줄 수 있는지 약간은 공부가 된 것 같습니다. 실습의 경우 루프 최적화와 데드코드 최적화의 경우 아직 프로파일링이 익숙하지 않아 몇시간의 삽질 끝에 포기를 하게 되었는데요 추후에 확인이 가능해지면 업데이트 하도록 하겠습니다.
실제로 실습을 진행하면서 최적화가 될때와 안될때 통신을 테스트 해봤을때 꽤 많은 성능차이가 났던걸로 기억합니다. 이 내용을 지금 생각하면 다 알아야 하나? 라는 생각이 들기도 했지만 앞으로 개발을 할때 어느정도 예상을 하며 개발을 하면 더 성능적인 부분에서 이점을 살리며 코드를 칠 수 있을 것 같습니다.
알게 모르게 성능 최적화를 해주는 JIT컴파일러에 감사💫
