
0. 시작
사전 관리 도구엔 기본적으로 사전을 관리하시는 분께서 색인 어휘가 이미 등록되어 있는지, 등록할 어휘가 형태소 분석이되었을 때 어떻게 결과가 나와야하는지 알아야 한다. 따라서 ElasticSearch에 _search 요청으로 색인 여부를 응답받고 _analyze 요청으로 형태소 분석 결과를 응답받아 검색 사전 관리자에게 알려줘야 한다.
1. Nori 형태소 분석기
Nori 형태소 분석기는 Elasticsearch에서 한국어 텍스트를 처리하기 위해 설계된 플러그인이다. Nori는 Lucene 기반의 텍스트 분석 툴로, 한국어에 특화된 분석을 제공하며 다음과 같은 주요 특징과 기능을 갖추고 있다.
주요 특징
1. 한국어 전용 분석기
Nori는 한국어를 위해 특별히 설계되었다. 한국어의 복잡한 문법과 구조를 고려하여 높은 수준의
텍스트 분석 성능을 제공한다.
2. Mecab-ko-dic 기반
Nori는 Mecab-ko-dic 사전을 기반으로 사용한다. Mecab-ko-dic은 일본어 형태소 분석기인 MeCab을 한국어에 맞게 수정한 것으로, 한국어의 다양한 어근, 접미사, 조사 등을 효과적으로 처리할 수 있다.
3. 사용자 사전 지원
사용자가 직접 사전에 단어를 추가할 수 있는 기능을 제공한다. 이를 통해 업데이트가 필요한 전문 용어나 신조어 등을 쉽게 반영할 수 있다.
4. 복합 명사 분해
한국어에서는 복합 명사가 자주 사용된다. Nori는 이러한 복합 명사를 자동으로 분해하여 각각의 독립된 명사로 분석할 수 있다.
5. 다양한 토크나이저 옵션
Nori는 사용자가 분석의 정밀도를 조정할 수 있도록 여러 토크나이저 옵션을 제공한다. 예를 들어, decompound_mode는 복합 명사의 처리 방식을 조정할 수 있으며, discard_punctuation 옵션을 사용하여 문장 부호를 제거할 수 있다.
ElasticSearch 공식 블로그 / 공식 한국어 분석 플러그인 “노리”
Nori는 한국어 검색 엔진에서 가장 널리 사용되는 플로그인이 되었으며, 자세한 내용은 상단의 ElasticSearch 공식 블로그에서 확인할 수 있다.
2. 검색 사전 등록
// 'nori_index' 인덱스 재생성 및 Nori 사용자 사전 설정
PUT /nori_index
{
"settings": {
"index": {
"analysis": {
"analyzer": {
"nori": {
"type": "custom",
"tokenizer": "nori_user_tokenizer"
}
},
"tokenizer": {
"nori_user_tokenizer": {
"type": "nori_tokenizer",
"decompound_mode": "none",
"user_dictionary": "/usr/share/elasticsearch/config/userdict_ko.txt"
}
}
}
}
}
}검색 사전은 Kibana Dev Tools에서 위의 요청을 보내 설정할 수 있다.
2-1. 사전을 등록하기 전에!
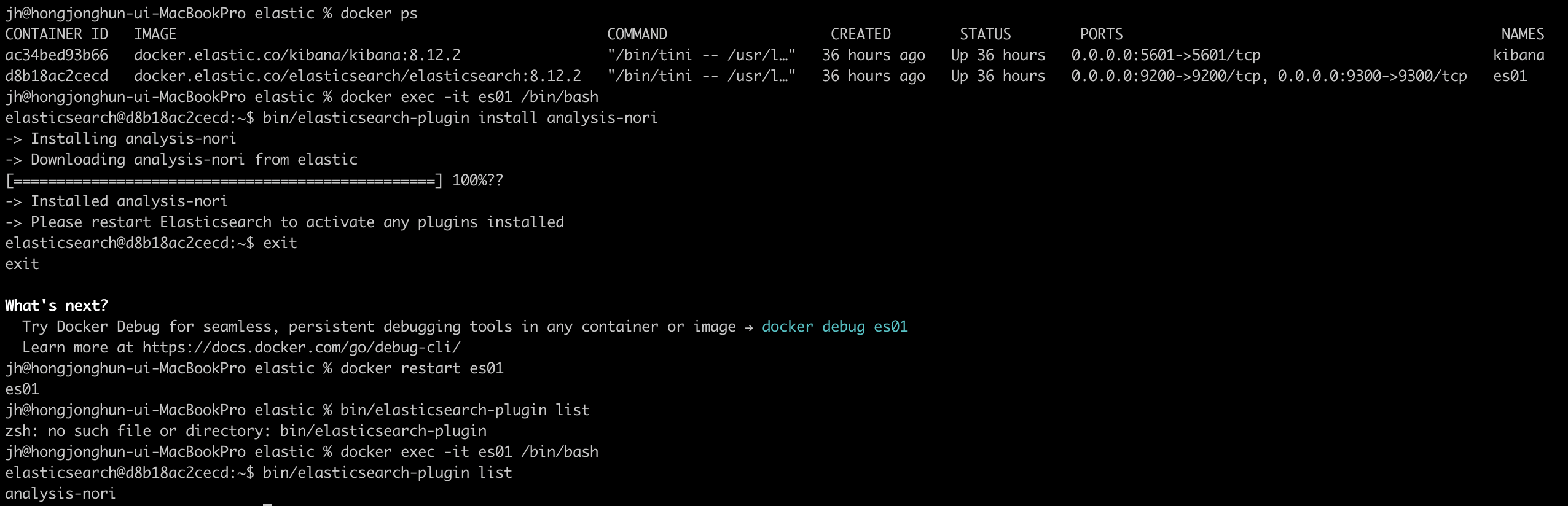
Nori의 경우 ES의 플러그인이기 때문에 ES서버가 켜진 후에 별도로 설치해줘야 한다.
- 먼저
docker exec -it ex01 /bin/bash명령어로 컨테이너에 접속한다. - 컨테이너 내부에서 Elasticsearch 플러그인 설치 명령어를 사용하여 Nori 플러그인을 설치한다. Elasticsearch의 bin 디렉토리로 이동하여 다음 명령어를 실행한다.
bin/elasticsearch-plugin install analysis-nori - 플러그인 설치 후 Elasticsearch 서비스를 재시작해야 한다. 컨테이너 외부로 나와서 es 컨테이너를 재시작해준다.
docker restart es01 - es컨테이너에 접근하여 제대로 설치됐는지 확인하려면 다음의 명령어를 입력한다.
bin/elasticsearch-plugin list
성공적으로 플러그인 리스트에 analysis-nori가 있다면 다음으로 넘어간다!
2-2. 사전 파일 미리 만들어두기
맨 처음의 json파일을 보면
"user_dictionary": "/usr/share/elasticsearch/config/userdict_ko.txt"
부분이 있다. Elasticsearch의 Nori 형태소 분석기에서 사용자 사전을 설정하는 부분이다. 사용자 사전은 형태소 분석기가 기본적으로 제공하는 사전 외에 사용자가 직접 정의한 단어들을 추가할 수 있도록 해준다. 이 기능은 특히 전문 용어, 신조어, 브랜드명 등이 일반 사전에 포함되지 않은 경우에 유용하다.
-
파일 경로
"user_dictionary"는 사용자 사전 파일의 경로를 지정한다. 여기서 "/usr/share/elasticsearch/config/userdict_ko.txt"는 Elasticsearch의 설정 디렉토리 내에 위치한 userdict_ko.txt 파일을 사용자 사전으로 지정하고 있다.
이 파일은 호스트 시스템 또는 ES 컨테이너 내부에 있어야 하며, ES 프로세스가 읽을 수 있는 권한이 설정되어 있어야 한다. -
사전 파일 형식
사용자 사전 파일은 텍스트 파일로, 각 줄에 하나의 단어를 포함하고 있다. 필요에 따라 추가적인 품사 정보를 함께 제공할 수도 있다.
예: 단어, 품사 태그 (예: 테이블 NNG) -
Nori 토크나이저 설정
Nori 토크나이저의 설정에서 user_dictionary 경로를 제공함으로써, Nori는 이 파일에 지정된 단어들을 사전에 추가하여 분석 과정에서 사용한다. 이렇게 함으로써, 분석 과정에서 사용자 사전에 포함된 단어들은 분리되지 않고 하나의 토큰으로 인식될 수 있다.
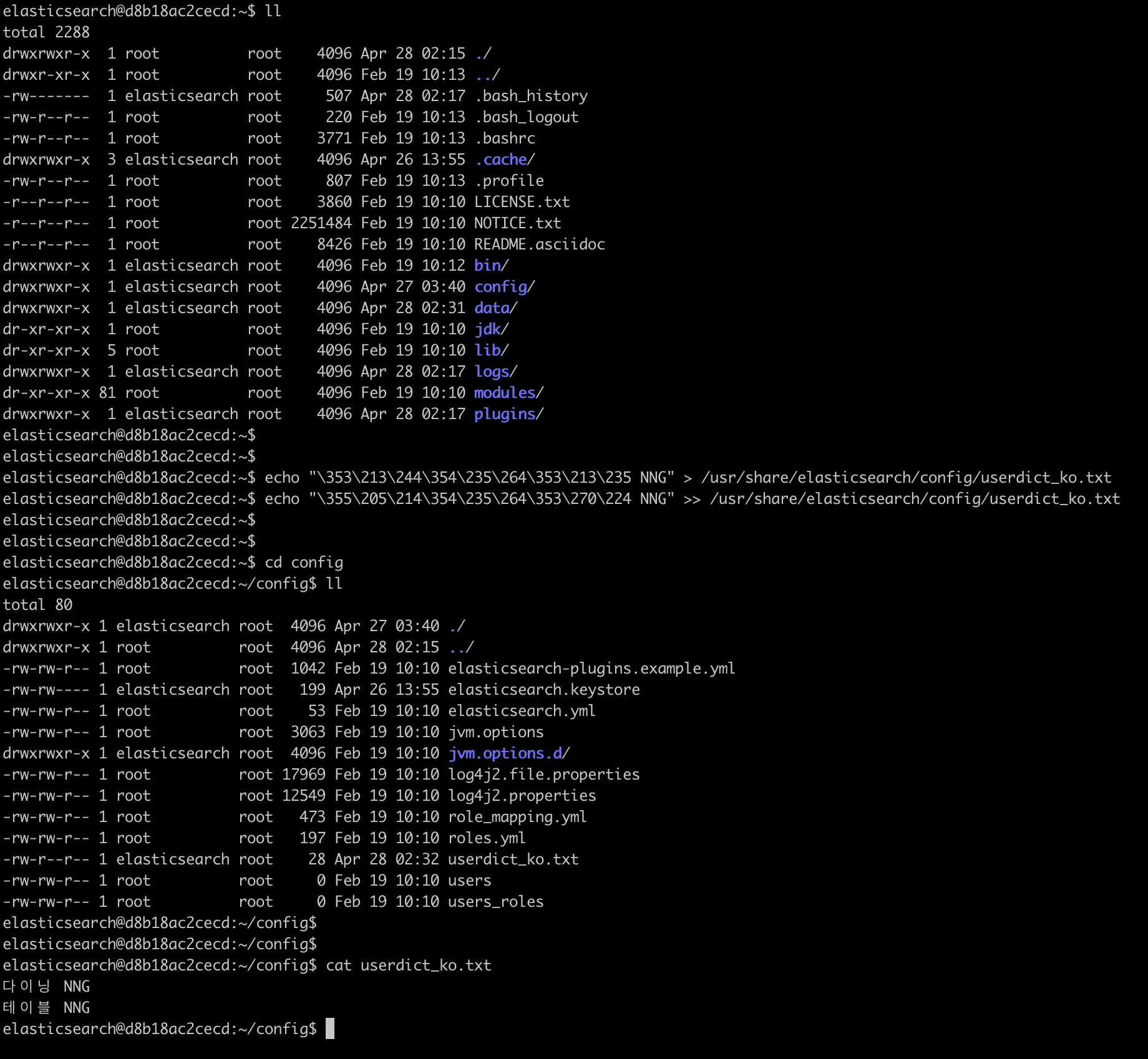
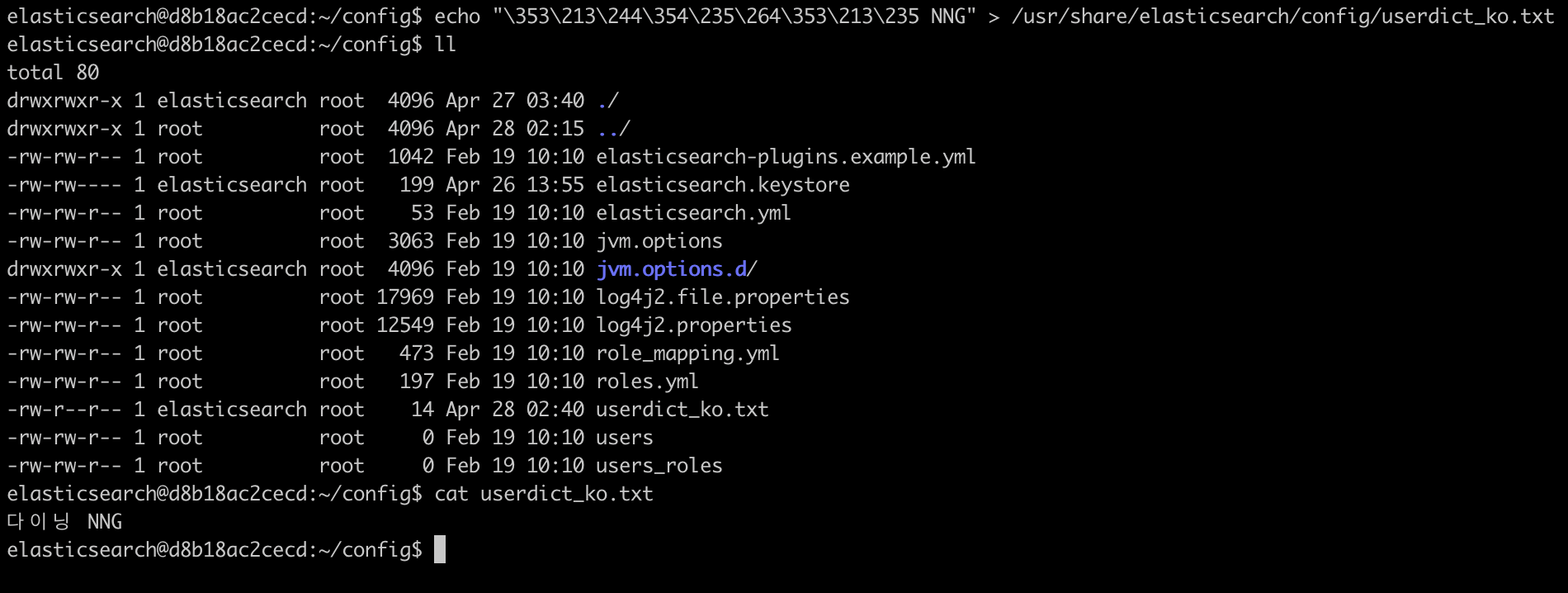
검색 사전의 경우 .txt 파일을 통해 관리하는데, ElasticSearch 컨테이너엔 vim이나 nano가 설치되어있지 않아 echo 명령어를 통해 txt 파일을 생성했다.
echo "다이닝 NNG" > /usr/share/elasticsearch/config/userdict_ko.txt
echo "테이블 NNG" >> /usr/share/elasticsearch/config/userdict_ko.txt2-3. 'nori_index' 인덱스 생성 및 Nori 사용자 사전 설정하기
이제 Nori 사용자 사전을 등록할 차례다. Kibana Dev Tools에서 요청을 보낸다.
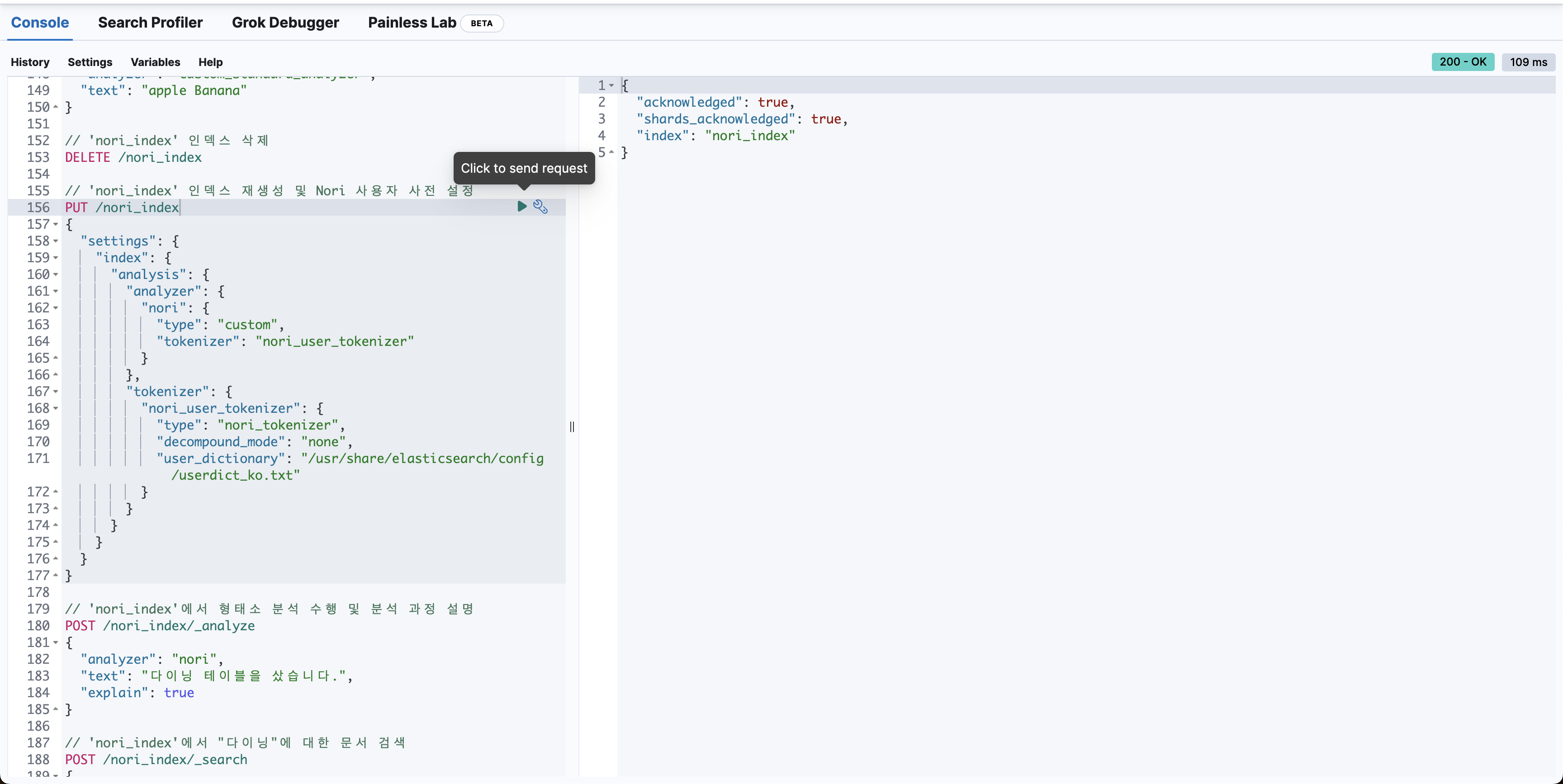
성공적으로 생성됐다는 결과를 받을 수 있다. 다음에 형태소 분석 요청을 보내면
// 'nori_index'에서 형태소 분석 수행 및 분석 과정 설명
POST /nori_index/_analyze
{
"analyzer": "nori",
"text": "다이닝 테이블을 샀습니다.",
"explain": true
}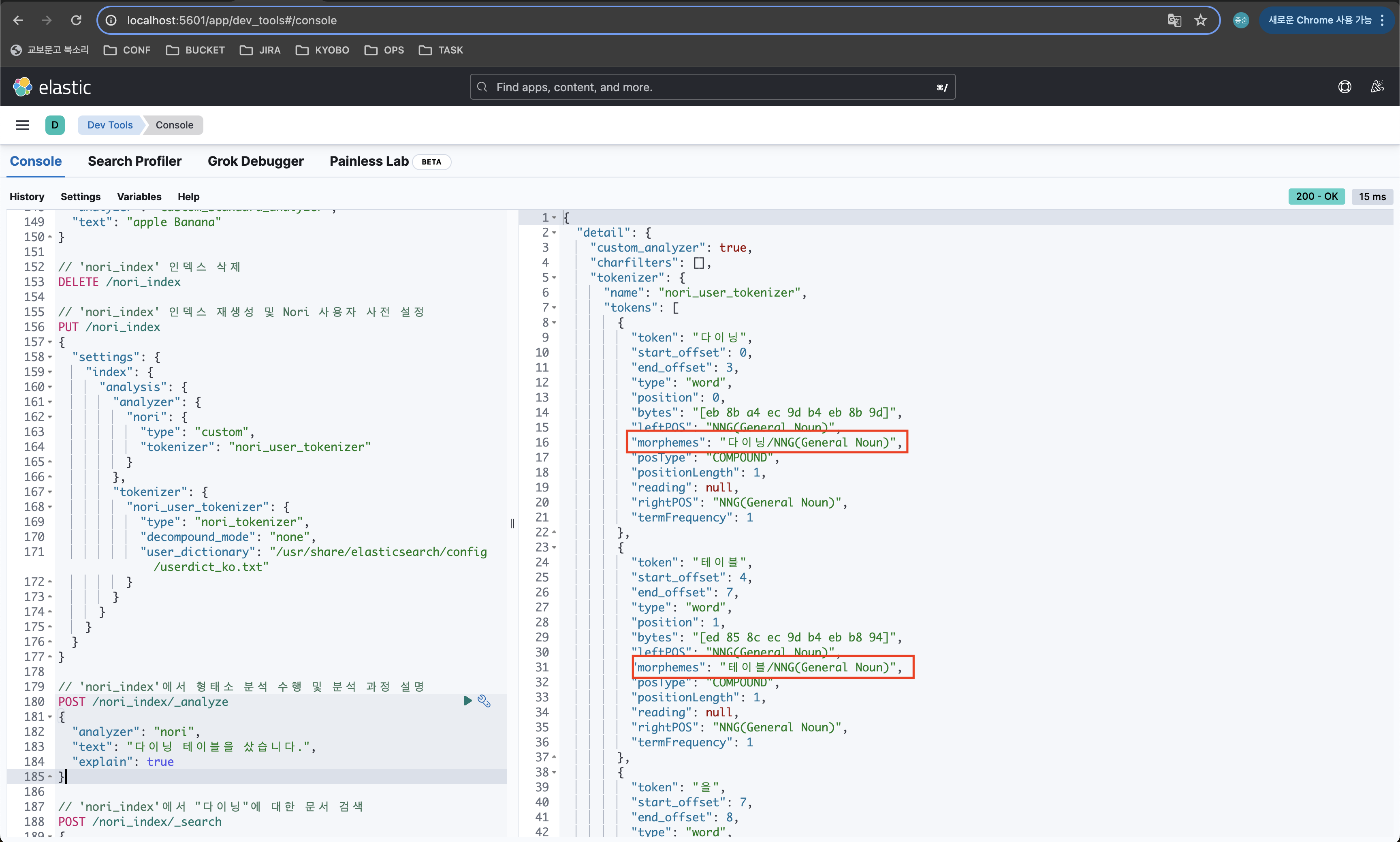
등록한 다이닝, 테이블이 전부 일반명사로 등록됐다는 결과를 받아볼 수 있다.
2-4. 'nori_index' 인덱스 생성 및 Nori 사용자 사전 설정하기
정확하게 '다이닝'과 '테이블'이 모두 제대로 단어로 등록된것인지 확인해보기 위해 userdict_ko.txt에서 '테이블'을 제외해봤다.
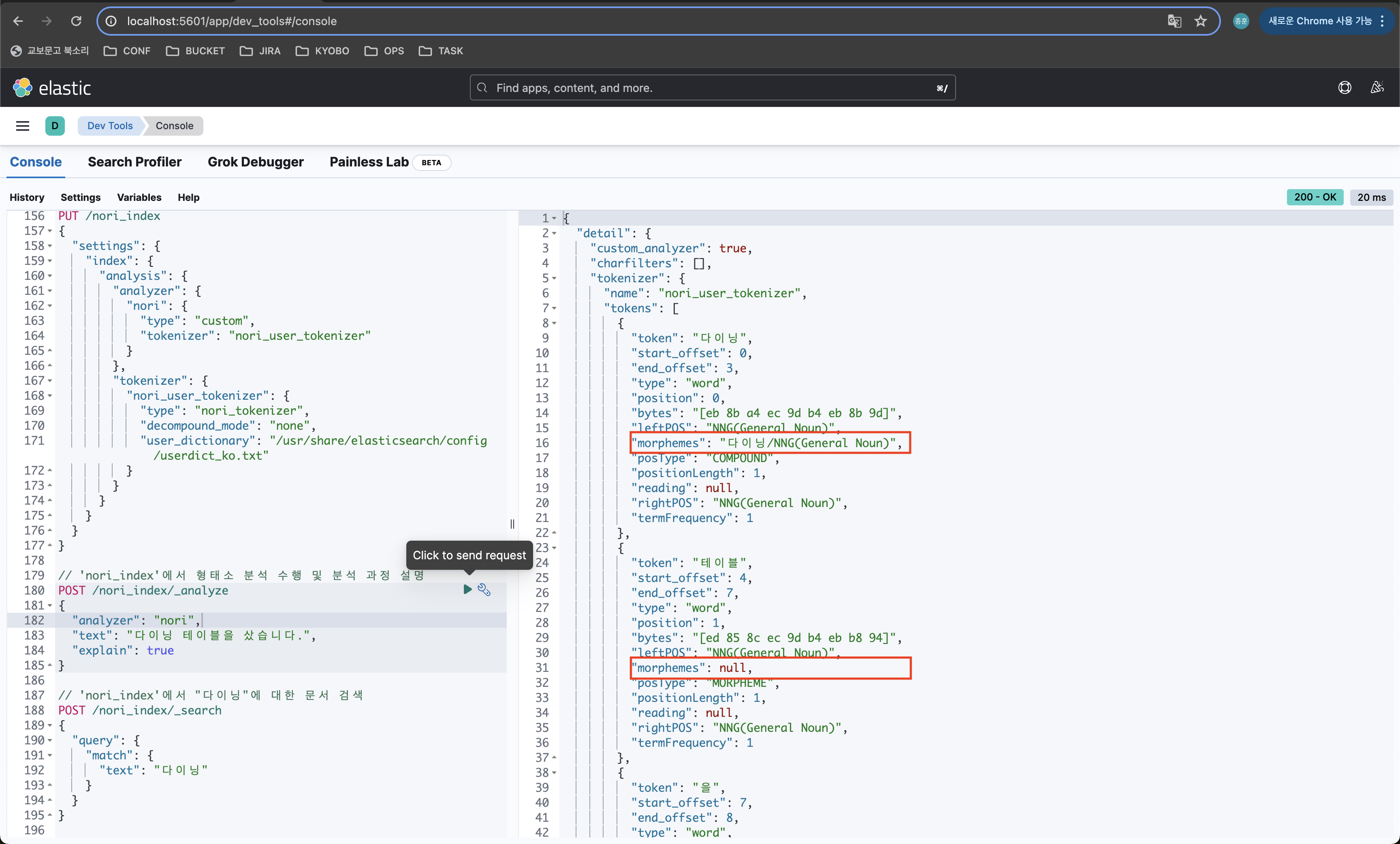
테이블의 "morphemes": null 을 확인할 수 있었다. 이로써 '사전 관리 도구'의 기능 중
'색인 어휘 추출' 기능과 '형태소 분석' 기능을 구현할 수 있게됐다.
