다음 주면 CKAD스터디도 벌써 4주차이다.
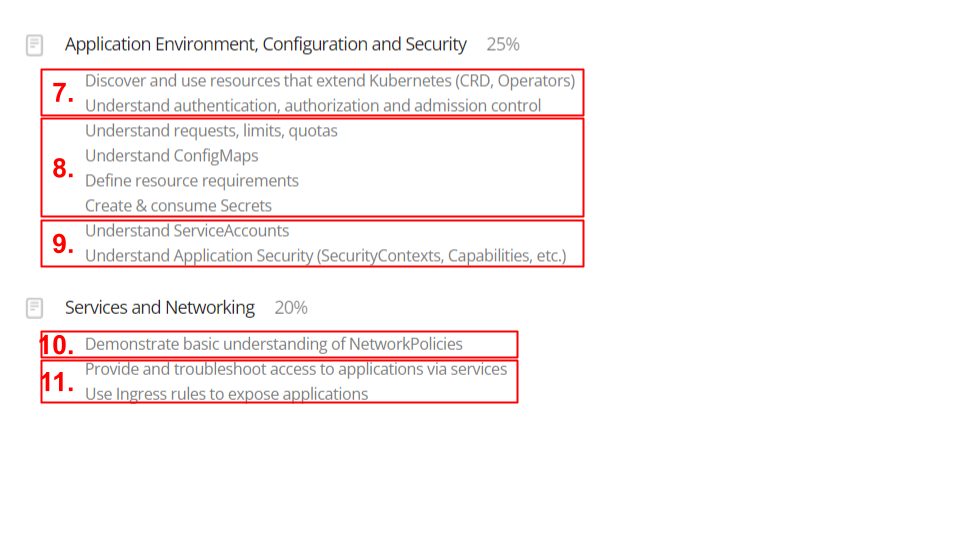
나는 8번항목에 있는 내용들에 대해 조사하고 발표하게 되었다.
Request, Limit
파드가 실행 중인 노드에 사용 가능한 리소스가 충분하면, 컨테이너가 해당 리소스에 지정한 request 보다 더 많은 리소스를 사용할 수 있도록 허용된다. 그러나, 컨테이너는 리소스 limit 보다 더 많은 리소스를 사용할 수는 없다.
예를 들어, 컨테이너에 대해 256MiB의 memory 요청을 설정하고, 해당 컨테이너가 8GiB의 메모리를 가진 노드로 스케줄된 파드에 있고 다른 파드는 없는 경우, 컨테이너는 더 많은 RAM을 사용할 수 있다.
해당 컨테이너에 대해 4GiB의 memory 제한을 설정하면, kubelet(그리고 컨테이너 런타임)이 제한을 적용한다. 런타임은 컨테이너가 구성된 리소스 제한을 초과하여 사용하지 못하게 한다. 예를 들어, 컨테이너의 프로세스가 허용된 양보다 많은 메모리를 사용하려고 하면, 시스템 커널은 메모리 부족(out of memory, OOM) 오류와 함께 할당을 시도한 프로세스를 종료한다.
제한은 반응적(시스템이 위반을 감지한 후에 개입)으로 또는 강제적(시스템이 컨테이너가 제한을 초과하지 않도록 방지)으로 구현할 수 있다. 런타임마다 다른 방식으로 동일한 제약을 구현할 수 있다.
1. 리소스 타입
CPU 와 메모리 는 각각 리소스 타입 이다. 리소스 타입에는 기본 단위가 있다. CPU는 컴퓨팅 처리를 나타내며 쿠버네티스 CPU 단위로 지정된다. 메모리는 바이트 단위로 지정된다. 리눅스 워크로드에 대해서는, huge page 리소스를 지정할 수 있다. Huge page는 노드 커널이 기본 페이지 크기보다 훨씬 큰 메모리 블록을 할당하는 리눅스 관련 기능이다.
예를 들어, 기본 페이지 크기가 4KiB인 시스템에서, hugepages-2Mi: 80Mi 제한을 지정할 수 있다. 컨테이너가 40개 이상의 2MiB huge page(총 80MiB)를 할당하려고 하면 해당 할당이 실패한다.
CPU와 메모리를 통칭하여 컴퓨트 리소스 또는 리소스 라고 한다. 컴퓨트 리소스는 요청, 할당 및 소비될 수 있는 측정 가능한 수량이다. 이것은 API 리소스와는 다르다. 파드 및 서비스와 같은 API 리소스는 쿠버네티스 API 서버를 통해 읽고 수정할 수 있는 오브젝트이다.
2. 쿠버네티스의 리소스 단위
2-1. CPU 리소스 단위
CPU 리소스에 대한 제한 및 요청은 cpu 단위로 측정된다. 쿠버네티스에서, 1 CPU 단위는 노드가 물리 호스트인지 아니면 물리 호스트 내에서 실행되는 가상 머신인지에 따라 1 물리 CPU 코어 또는 1 가상 코어 에 해당한다.
요청량을 소수점 형태로 명시할 수도 있다. 컨테이너의 spec.containers[].resources.requests.cpu를 0.5로 설정한다는 것은, 1.0 CPU를 요청했을 때와 비교하여 절반의 CPU 타임을 요청한다는 의미이다. CPU 자원의 단위와 관련하여, 0.1 이라는 수량 표현은 "백 밀리cpu"로 읽을 수 있는 100m 표현과 동일하다. 어떤 사람들은 "백 밀리코어"라고 말하는데, 같은 것을 의미하는 것으로 이해된다.
CPU 리소스는 항상 리소스의 절대량으로 표시되며, 상대량으로 표시되지 않는다. 예를 들어, 컨테이너가 싱글 코어, 듀얼 코어, 또는 48 코어 머신 중 어디에서 실행되는지와 상관없이 500m CPU는 거의 같은 양의 컴퓨팅 파워를 가리킨다.
2-2. 메모리 리소스 단위
memory 에 대한 제한 및 요청은 바이트 단위로 측정된다. E, P, T, G, M, k 와 같은 수량 접미사 중 하나를 사용하여 메모리를 일반 정수 또는 고정 소수점 숫자로 표현할 수 있다. Ei, Pi, Ti, Gi, Mi, Ki와 같은 2의 거듭제곱을 사용할 수도 있다. 예를 들어, 다음은 대략 동일한 값을 나타낸다.
128974848, 129e6, 129M, 128974848000m, 123Mi
접미사의 대소문자에 유의한다. 400m의 메모리를 요청하면, 이는 0.4 바이트를 요청한 것이다.
이 사람은 아마도 400 메비바이트(mebibytes) (400Mi) 또는 400 메가바이트 (400M) 를 요청하고 싶었을 것이다.
3. 컨테이너 리소스 예제
---
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
-name: app
image: images.my-company.example/app:v4
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
-name: log-aggregator
image: images.my-company.example/log-aggregator:v6
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"위의 파드는 두 컨테이너로 구성된다.
각 컨테이너는 0.25 CPU와 64 MiB(226 바이트) 메모리 요청을 갖도록 정의되어 있다.
또한 각 컨테이너는 0.5 CPU와 128 MiB 메모리 제한을 갖는다.
이 경우 파드는 0.5 CPU와 128 MiB 메모리 요청을 가지며, 1 CPU와 256 MiB 메모리 제한을 갖는다.
4. 다른 기능과의 통합
4-1. Horizontal Pod Autoscaler (HPA)
HPA는 실시간으로 애플리케이션의 부하에 따라 파드의 수를 자동으로 스케일링한다.
request 설정을 사용하여 파드에 할당된 CPU 또는 메모리 리소스를 기반으로 HPA는 파드의 수를 증가시키거나 감소시키기 위한 결정을 내린다.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: myapp-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: myapp-deployment
minReplicas: 1
maxReplicas: 10
targetCPUUtilizationPercentage: 50이 예시에서 HPA는 myapp-deployment의 CPU 사용량이 50%를 초과하면 자동으로 파드의 수를 증가시킨다.
4-2. Quality of Service (QoS) 클래스
쿠버네티스는 request와 limit을 기반으로 파드에 Quality of Service(QoS) 클래스를 할당한다.
QoS 클래스는 시스템 리소스가 부족할 때 파드의 우선 순위를 결정하는 데 사용된다.
쿠버네티스는 다음 세 가지 QoS 클래스를 제공한다:
- Guaranteed: 파드 내의 모든 컨테이너에 대해 CPU와 메모리
request와limit이 동일하게 설정되어 있을 때 부여된다. - Burstable: 파드가
Guaranteed요건을 충족하지 않고, 하나 이상의 컨테이너에 CPU 또는 메모리request가 설정된 경우 부여된다. - BestEffort: 파드 내의 컨테이너에 어떠한 CPU 또는 메모리
request또는limit도 설정되지 않았을 때 부여된다.
apiVersion: v1
kind: Pod
metadata:
name: guaranteed-pod
spec:
containers:
- name: guaranteed-container
image: nginx
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "64Mi"
cpu: "250m"이 예시에서는 메모리와 CPU의 request와 limit이 동일하게 설정되어 있어 QoS 클래스가 Guaranteed가 된다.
4-3. 클러스터 리소스 할당 및 보고
클러스터의 리소스 할당 및 사용량 보고를 위해 request와 limit이 사용된다.
이는 클러스터 운영자가 리소스 사용량을 모니터링하고, 예산 설정 및 용량 계획을 수립하는 데 도움을 준다.
apiVersion: v1
kind: Pod
metadata:
name: resource-reporting-pod
spec:
containers:
- name: myapp-container
image: nginx
resources:
requests:
cpu: "500m"
memory: "256Mi"
limits:
cpu: "1"
memory: "512Mi"kubectl top pod <pod-name>
이 설정을 통해 클러스터 운영자는 리소스 사용량을 모니터링하고 애플리케이션의 리소스 요구 사항을 계획할 수 있다.
4-4. Pod Eviction Policy
노드에 할당된 리소스가 부족해지면 쿠버네티스는 QoS 클래스와 request 및 limit 값을 기반으로 파드 축출(eviction) 정책을 결정한다.
이는 시스템의 안정성을 보장하는 데 중요한 역할을 한다.
4-5. Vertical Pod Autoscaler (VPA)
VPA는 파드의 리소스 request와 limit을 자동으로 조정하여, 파드가 필요로 하는 리소스 양을 보다 정확하게 맞출 수 있도록 돕는다.
VPA는 파드의 리소스 사용 패턴을 분석하여 적절한 request와 limit을 설정하는 데 도움을 준다.
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: myapp-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: myapp-deployment
updatePolicy:
updateMode: "Auto"
VPA는 myapp-deployment의 리소스 사용 패턴을 분석하여 적절한 request와 limit 값을 자동으로 설정한다.
4-6. Node Scheduling
request는 파드가 실행될 적절한 노드를 선택하는 데 사용된다.
스케줄러는 파드의 request가 노드에 사용 가능한 리소스를 초과하지 않는 노드를 찾아 파드를 배치한다.
apiVersion: v1
kind: Pod
metadata:
name: node-scheduling-pod
spec:
containers:
- name: myapp
image: nginx
resources:
requests:
cpu: "500m"
memory: "256Mi"이 예시에서 파드는 CPU와 메모리 request를 충족시킬 수 있는 노드에만 스케줄된다.
