AWS
1.[AWS] AWS 공부

2.[AWS] AWS S3버킷에 이미지 저장하기

그동안은 Cloudinary를 사용하여 이미지를 업로드 했지만, 오늘은 S3버킷을 사용해 이미지를 업로드하는 방법을 배웠다.해당 코드는 업로드! 버튼을 누르면 파일을 선택할 수 있는 Finder가 팝업되고, 이미지를 선택했을 때 아마존 S3버킷에 파일이 업로드되는 코드
3.[AWS] Mac OS AWS EC2인스턴스 생성, 접속하기
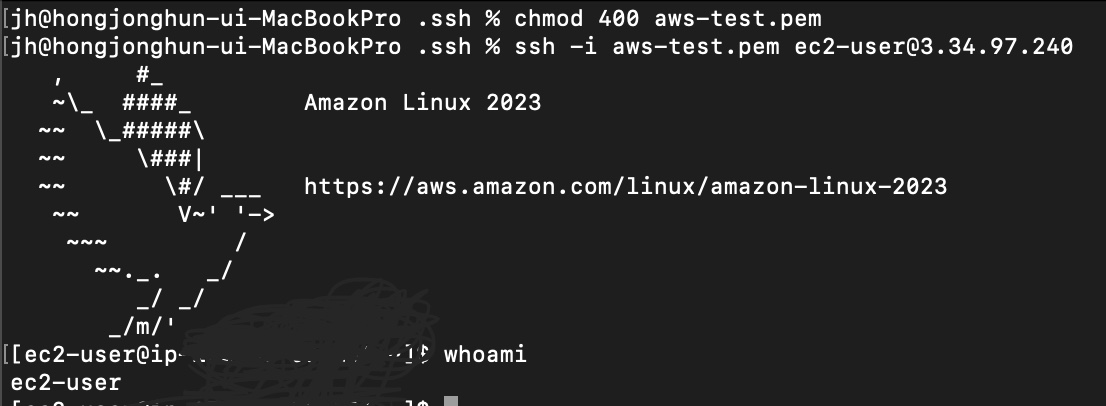
AWS의 주요 서비스 중 하나인 EC2를 생성해봤다.AWS콘솔에 접속 후 EC2 를 선택하면 화면 중앙에 주황색 버튼 하나가 있다.인스턴스 시작을 누르면 EC2 인스턴스를 생성할 수 있다.인스턴스 시작을 누르면 이름을 정할 수 있고프리티어로 사용 가능한 Amazon L
4.[AWS] EC2 인스턴스에 웹 서비스 설치하기
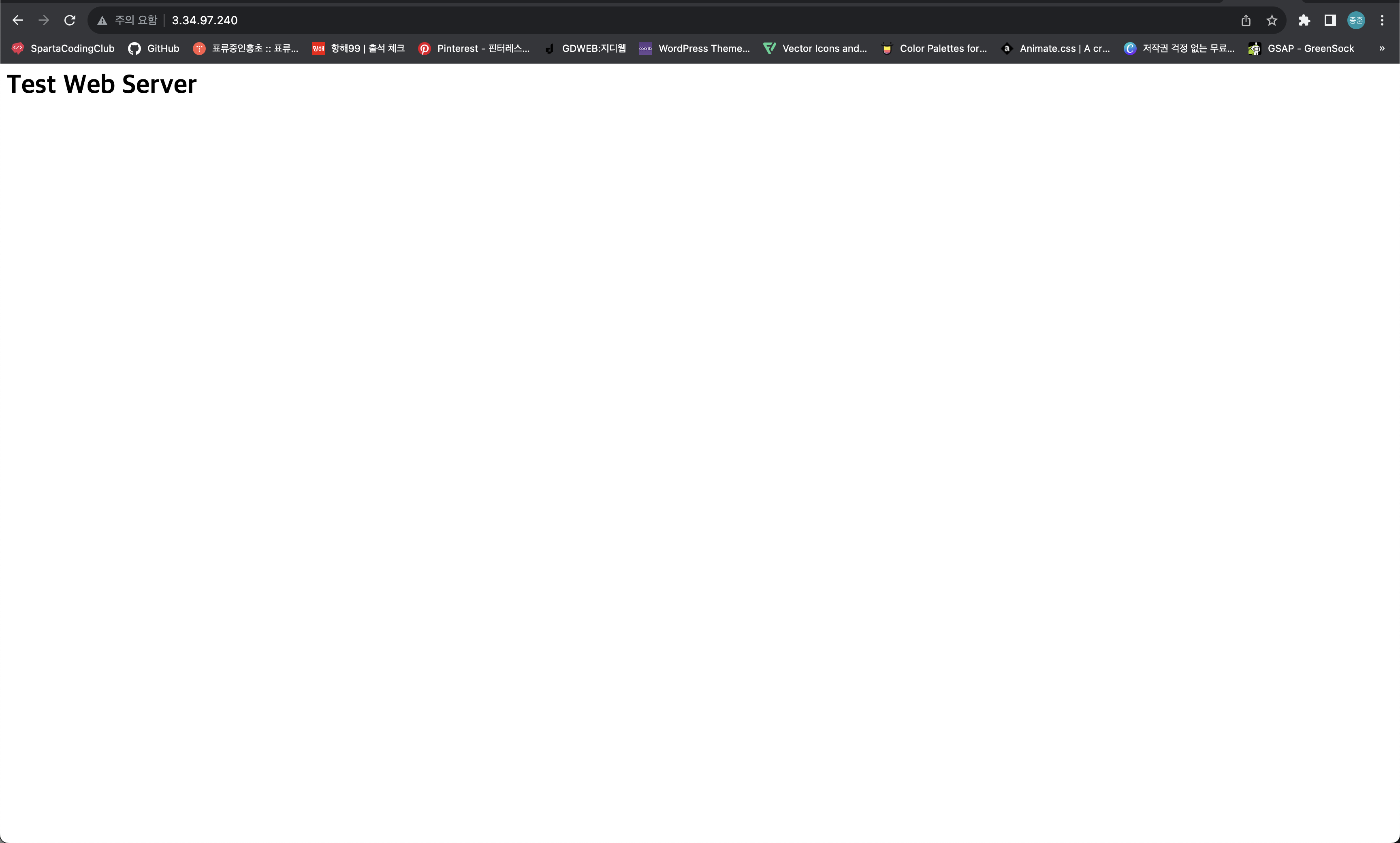
1\. sudo su -편리를 위해서 root계정으로 전환했다. 2\. yum install httpd -y웹 서비스를 설치한 뒤3\. systemctl start http웹 서비스를 실행한다. 4\. echo "<h1>Test Web Server</h1>"
5.[AWS] AWS EC2 인스턴스에 git 설치하고 프로젝트 클론하기
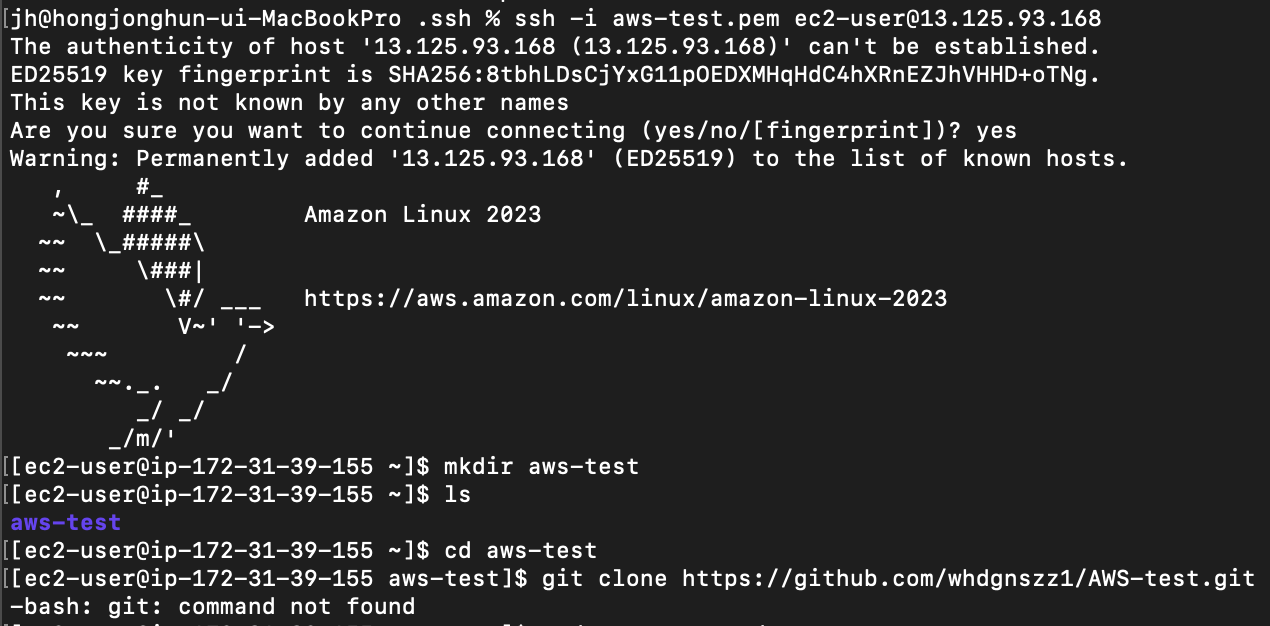
새로 만들어진 EC2에 프로젝트를 클론하려고 하니 git이 설치되어 있지 않아git: command not found가 떴다.이번엔 생성된 EC2 인스턴스에 git을 설치하고 프로젝트를 클론받아봤다.다음 명령어로 git을 설치한다.git이 잘 설치되었는지 확인한다.$
6.[AWS] EC2 인스턴스에 python flask 서버 띄우기

이번엔 파이썬의 flask로 만든 서버를 EC2 인스턴스에 띄워봤다.$ python3 -m venv venv$ source venv/bin/activate$ pip install \[설치패키지1 설치패키지2 설치패키지3]$ python3 app.py
7.[AWS] Github Actions를 이용한 EC2로의 Flask CI/CD
해당 글은 아래의 tistory를 참고했습니다. https://rachel0115.tistory.com/entry/Github-Actions%EB%A1%9C-CICD-%EA%B5%AC%EC%B6%95%ED%95%98%EA%B8%B0-EC2-S3-CodeDeploy
8.[AWS] S3버킷 파일 zip파일로 묶어서 전송하기
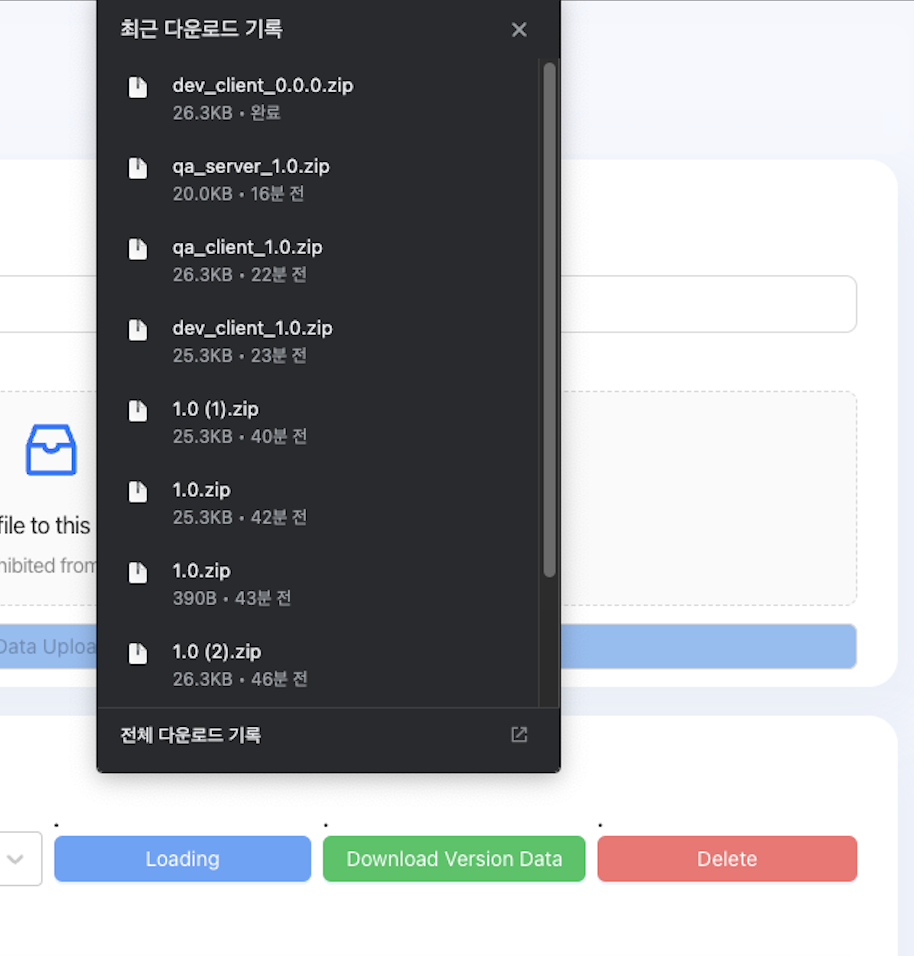
Download All Data 버튼을 클릭했을 때 특정 URL에서 모든 데이터를 다운로드하는 기능을 구현하려면, 먼저 해당 URL에서 사용 가능한 모든 파일의 목록을 가져와야 합니다. 그런 다음, 각 파일에 대해 개별적으로 다운로드 요청을 수행해야 합니다.하지만, 브
9.[AWS] VPC 피어링을 통한 VPC간 ElastiCache 접근

개발을 할 동안에는 로컬에서 Redis를 설치하여 사용하였지만, Prod 단계에선 레디스 인스턴스에 부하가 많이 주어질 예정이기 때문에레디스의 클러스터링, 샤딩을 설정해줘야한다. 하지만 이 작업들을 전부 수작업으로 하기엔 작업 소요가 크기 때문에 AWS에서 제공해주는