페이징에 대한 고찰
현재 페이징 기능 구현에서 PageImpl을 사용 중이며, 반환 할 때 조건에 따른 조회 쿼리 뿐만 아니라 count 쿼리도 함께 실행된다. (offset 방식)
그렇다면 첫 번째 페이지와 마지막 페이지 같은 경우에는 Count 쿼리를 줄일 수는 있지 않을까?
offset 기반 방식
offset 기반 방식이란 페이지 번호를 이용해 가져올 데이터의 위치를 파악하는 방식
클라이언트에서 넘겨받는 페이지 번호와 페이지 사이즈를 가지고 서버에서 오프셋 값을 구한다. 오프셋 = (페이지 번호 - 1) * 페이지 사이즈 이기 때문에 페이지 사이즈가 20인 경우 아래와 같이 오프셋 값이 늘어나게 된다.
현재 상황
현재 코드는 다음과 같고,
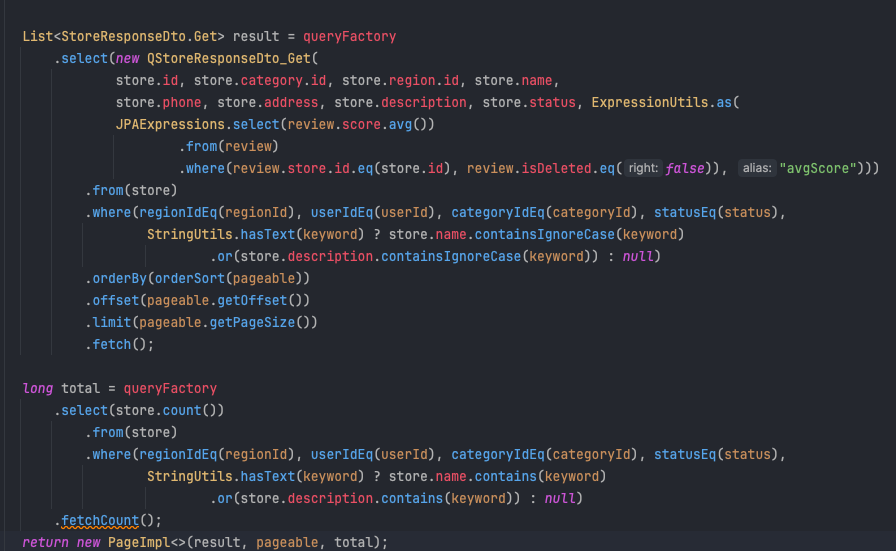
실행 시에는 어떠한 조건이든 무조건 count Query가 발생한다.
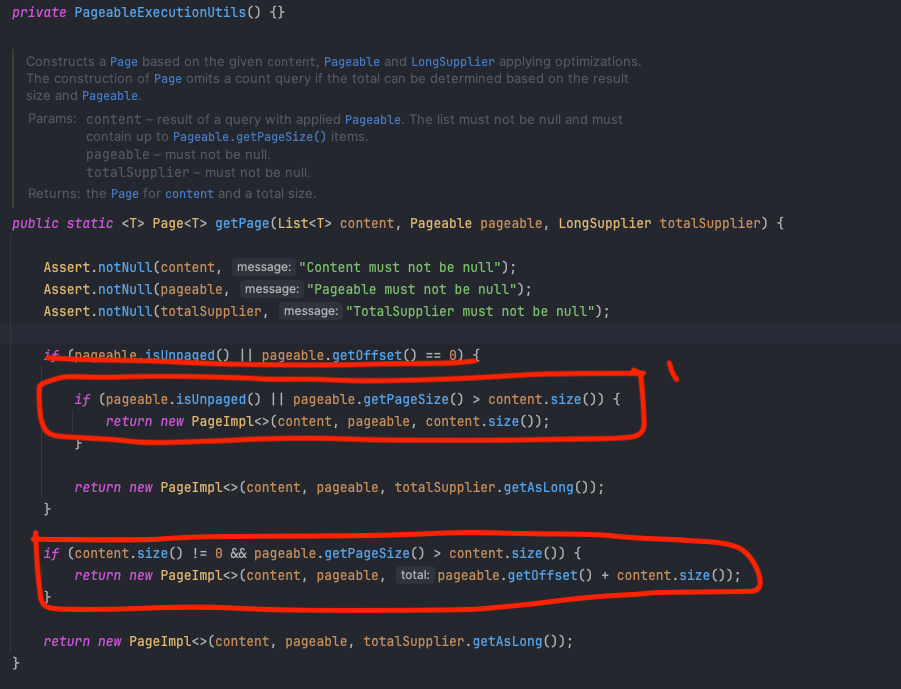
PageableExecutionUtils
아래의 자바의 공식 문서를 따르면 PageableExecutionUtils을 사용하면 단순 new PageImpl()을 사용했을 때 보다 성능 최적화 이점이 있다는 것을 볼 수 있다.

실제 Spring 내부 구현 코드를 해석해보면, 첫번째 페이지면서 content의 크기가 한 페이지의 사이즈보다 작을 때와 마지막 페이지일 때는 totalSupplier 대신 content의 size와 offset 값을 사용하는 것을 볼 수 있다.
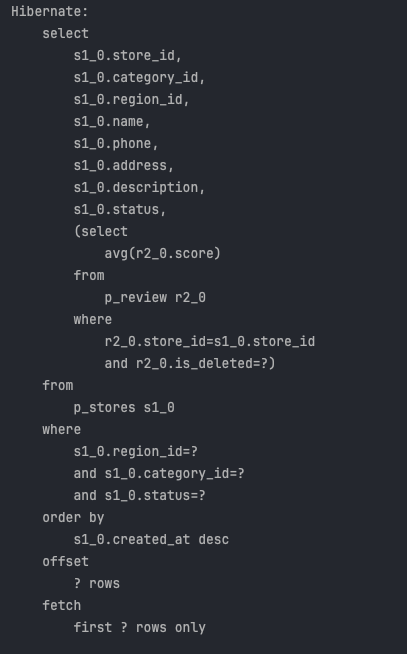
실제로 조건에 따른 테스트를 진행해보자.
1. Size = 30 , Page = 0 , 총 컨텐트 : 21개 일 때 count 쿼리는 실행되지 않는다.
-
Size = 15, page = 1 , 총 컨텐트 : 21개일 때 , 마지막 페이지의 컨텐트 개수가 페이지 사이즈 보다 작아 count 쿼리는 실행되지 않는다.
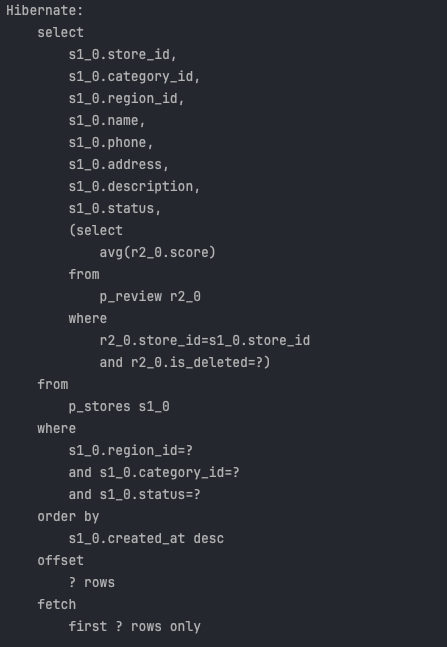
-
Size = 10 , page = 1 , 총 컨텐트 : 21개 일 때 , count 쿼리가 실행된다.
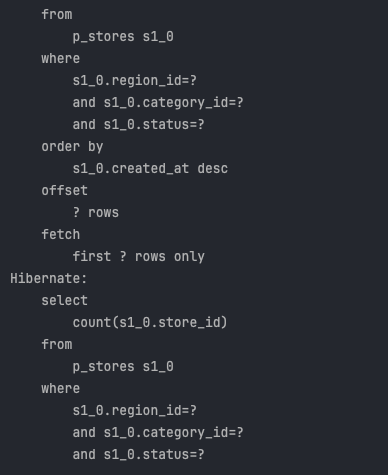
-
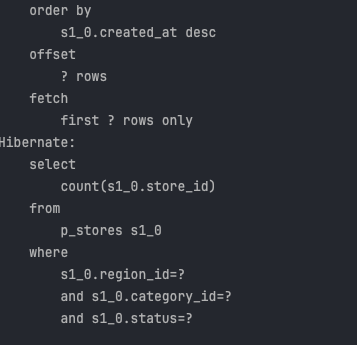
pageImpl<> 사용하고, Size = 30 , Page = 0 , 총 컨텐트 : 21개 일 때 count 쿼리가 실행된다.
실제로 1000개의 데이터를 기준으로 마지막 페이지 조회 시 속도 차이를 한번 비교해보자
-
변경 전
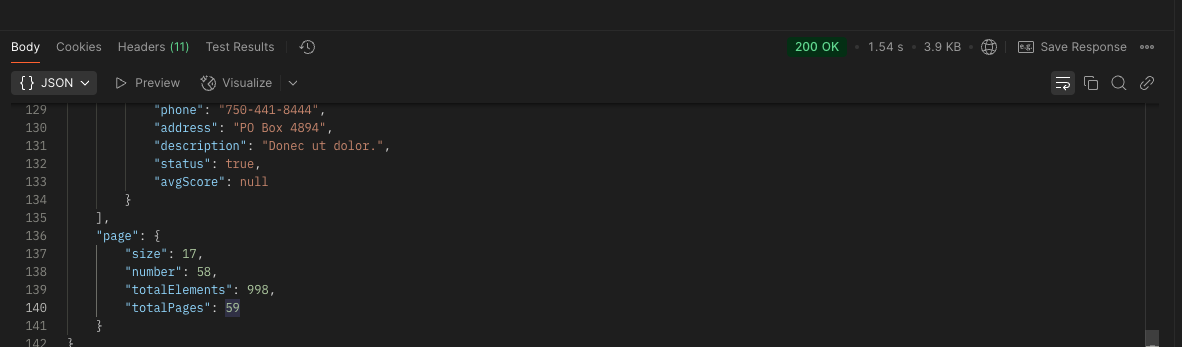
-
변경 이후
1.54s -> 1.35로 개선된 것을 볼 수 있다.
좀 더 개선하기
앞선 개선 방법은 조건에 따른 방안이다. 그렇다면 실질적인 페이징 쿼리 성능을 올리는 방법은 없을까?

NoOffset과 커버링 인덱스 방법이 있다. 우선적으로 NoOffset은 페이지가 없는 UI에 적용이 가능하므로, 배제하고 커버링 인덱스에 대해서 살펴보자.
보편적으로 성능 개선 방법에 대해 생각하면 인덱싱 작업이 있다. 그러면 커버링 인덱스는 어떤 것일까?
커버링 인덱스는 쿼리를 충족시키는 데 필요한 모든 데이터를 갖고 있는 인덱스를 의미한다. 즉, select, where, order by, limit 등 모든 컬럼이 index 칼럼 안에 다 포함하는 경우다. 커버링 인덱스를 사용하면 어느정도 필터가 된 데이터 내에서만 검색하기 때문에 전체 조회보다 훨씬 효율적이다.
인덱스 설정 시에, 무차별적으로 모든 칼럼을 넣는 경우는 비효율적이기 때문에 검색 where에 사용되는 칼럼과 order by에 사용되는 칼럼 그리고 select하는 칼럼을 포함하여 index작업을 진행했다.
현 프로젝트를 기준으로 아래와 같이 index를 설정했다.
CREATE INDEX idx_store_covering
ON p_stores (region_id, category_id, user_id, status, name, description, id, phone, address);아래와 같이 설정하면, 직접적인 테이블 조회없이 인덱스만으로 데이터를 가져올 수 있다.
기존의 테이블에 Index를 추가하기 위해 Flyway 마이그레이션을 사용했다. 아래와 같이 Index 설정을 하는 Sql을 작성하고,
CREATE INDEX idx_store_covering
ON p_stores (region_id, category_id, user_id, status, name, description, id, phone, address);
CREATE INDEX idx_review_store
ON p_reviews (store_id, score, is_deleted);이전의 조회 함수를 다음과 같이 수정했다.
@Override
public Page<StoreResponseDto.Get> searchStores(Long userId
, Long regionId, Long categoryId, String keyword
, Boolean status, Pageable pageable) {
QStore store = QStore.store;
// Store와 Review를 JOIN하여 평균 별점 조회
List<StoreResponseDto.Get> result = queryFactory
.select(new QStoreResponseDto_Get(
store.id, store.category.id, store.region.id, store.name,
store.phone, store.address, store.description, store.status,
review.score.avg())) // 별점 평균 추가
.from(store)
.leftJoin(review).on(review.store.id.eq(store.id).and(review.isDeleted.eq(false))) // JOIN으로 별점 가져오기
.where(regionIdEq(regionId), userIdEq(userId), categoryIdEq(categoryId), statusEq(status),
StringUtils.hasText(keyword) ? store.name.containsIgnoreCase(keyword)
.or(store.description.containsIgnoreCase(keyword)) : null)
.groupBy(store.id) // GROUP BY 추가
.orderBy(store.id.asc()) // 인덱스를 활용한 정렬
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
JPAQuery<Long> total = queryFactory
.select(store.count())
.from(store)
.where(regionIdEq(regionId), userIdEq(userId), categoryIdEq(categoryId), statusEq(status),
StringUtils.hasText(keyword) ? store.name.contains(keyword)
.or(store.description.contains(keyword)) : null);
return PageableExecutionUtils.getPage(result, pageable, total::fetchOne);
}여기서 leftJoin으로 수정하고, review 테이블에도 index를 추가했다.
서버 실행 시 아래와 같이 생성이 잘된 것을 확인 할 수 있다.

그렇다면 Covering index 작업 이후에는 얼마나 개선되었는지 Test 해보자.
위와 같이 같은 조건 기준으로 조회 시, 1.03s만큼 개선된 것을 볼 수 있다.
참고 자료
