최근 동아리 프로젝트를 진행하면서 엘라스틱서치에 도전해보고 있다. 관련해서 지식이 부족하다는 생각에 엘라스틱 서치 실무 가이드 책을 통해 관련 지식을 습득하고 내용을 정리해보자!
검색 시스템이란?
엘라스틱 서치에 대해 알아보기 전에 검색 시스템에 대한 간단한 이해가 필요할 것 같다.
검색 시스템이란?
대용량 데이터를 기반으로 신뢰성 있는 검색 결과를 제공하기 위해 검색엔진을 기반으로 구축된 시스템을 통칭하는 용어
여기서 엘라스틱서치는 검색엔진에 해당하는 기술이다. 그리고 이 검색 시스템을 이용해서 다양한 서비스를 제공하는 것을 검색 서비스라고 한다. 즉 정리하면
검색 서비스 > 검색 시스템 > 검색 엔진
이렇게 생각해볼 수 있다.
검색 시스템의 구성 요소
수집기
웹사이트, 블로그, 카페 등 웹에서 필요한 정보를 수집하는 프로그램으로 크롤러, 스파이더, 웜, 웹 로봇 등으로 불린다.
스토리지
데이터를 저장하는 물리적인 저장소로 검색엔진은 색인한 데이터를 스토리지에 저장한다.
색인기
다양한 형태소 분석기를 조합해 정보에서 의미 있는 용어를 추출하고 검색에 유리한 역색인 구조로 데이터를 저장한다.
검색기
사용자 질의를 입력받아 색인기에서 저장한 역색인 구조에서 일치하는 문서를 찾아 결과로 반환한다. 검색기 또한 색인기와 마찬가지로 형태소 분석기를 이용해 사용자 질의에서 유의미한 용어를 추출해 검색한다.
엘라스틱 서치에 대하여

엘라스틱 서치는 아파치 재단의 루씬(Lucene)을 기반으로 개발된 오픈소스 검색 엔진이다.
먼저 대표적인 장점에 대해 알아보자.
- 전문검색
PostgreSQL, MongoDB 등과 같은 데이터베이스는 기본 쿼리 및 색인 구조의 한계로 기본적인 텍스트 검색 기능만 제공한다. - 통계 분석
비정형 로그 데이터를 수집하고 한 곳에 모아 통계 분석을 할 수 있다. - 스키마리스
정형화 되지 않은 다양한 형태의 문서도 자동으로 색인하고 검색할 수 있다. - RESTful API
엘라스틱 서치는 RESTful API를 지원하고 JSON 형식을 사용하여 다양한 환경에서 제약없이 사용 가능하다. - 멀티테넌시
서로 상이한 인덱스일지라도 검색할 필드명만 같으면 여러 개의 인덱스를 한번에 조회할 수 있다. 이를 이용해 멀티테넌시 기능을 제공할 수 있다. - 역색인
안에 존재하는 내용을 색인하여 value 값으로 해당 문서 id를 갖고 있기 때문에 모든 문서의 내용을 다 훑을 필요 없이 곧바로 문서에 접근할 수 있어 검색 속도가 빠르다.
이번엔 약점에 대해 알아보자.
- 준실시간
검색 요청을 보내자마자 곧바로 결과가 나오지는 않는다. 이는 초실시간성을 요구하는 환경에서 약점으로 작용할 수 있다. - 트랜잭션과 롤백 기능 제공 X
엘라스틱 서치는 기본적으로 분산 시스템으로 구성된다. 따라서 전체적인 클러스터 성능 향상을 위해 롤백과 트랜잭션을 지원하지 않는다. - 데이터 업데이트 제공 X
엘라스틱 서치의 기본 용어
엘라스틱 서치를 구성하는 다양한 개념과 관련 용어들에 대해 알아보자
인덱스(Index)
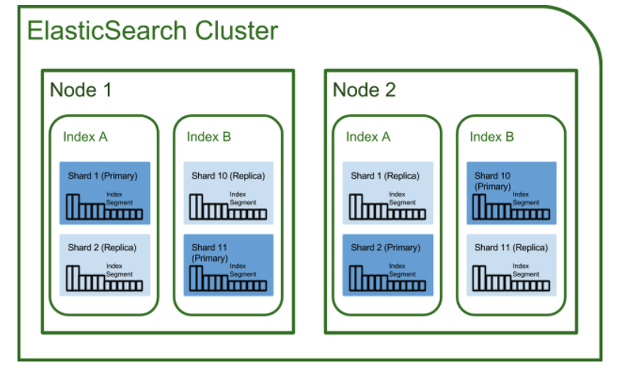
인덱스는 데이터 저장 공간으로 하나의 인덱스는 하나의 타입만 가지며, 하나의 물리적인 노드에 여러 개의 논리적인 인덱스를 생성할 수 있다. 분산환경에서는 여러 개의 노드에 걸쳐 인덱스가 저장되므로 고가용성, failover 등 분산에 따른 장애환경에 대응할 수 있는 장점을 얻을 수 있다.
❗️ 참고
인덱스의 이름은 모두 소문자여야 하며, CRUD는 RESTful API로 수행할 수 있다. 인덱스가 없는 상태에서 데이터가 추가된다면 데이터를 이용해 인덱스가 자동 생성된다.
샤드(Shard)
색인된 문서는 하나의 인덱스에 담기는데, 인덱스 내부에 색인된 데이터는 물리적인 공간에 여러 개의 파티션으로 구성된다. 이 파티션을 ES에서는 샤드라고 부른다. 이 샤드 또한 분산되기 때문에 데이터 유실 위험을 줄일 수 있다.
타입(Type)
타입은 인덱스의 논리적인 구조를 의미하며 6.0 버전까지는 하나의 인덱스에 여러 개의 타입을 설정할 수 있었지만, 6.1부터는 인덱스 당 하나의 타입만 설정 가능하다.
문서(Document)
데이터가 저장되는 최소 단위로 기본적으로 Json 포맷으로 데이터가 저장된다. 하나의 문서는 다수의 필드로 구성돼 있는데 각 필드는 데이터의 형태에 따라 용도에 맞는 데이터 타입을 정의해야 한다. 또한 문서 안에 문서를 중첩하여 지정하는 것도 가능하다.
필드
필드는 문서를 구성하기 위한 속성이라고 할 수 있다. 하나의 필드는 목적에 따라 다수의 데이터 타입을 가질 수 있다.
매핑
문서의 필드와 필드 속성을 정의하고 그에 따른 색인 방법을 정의하는 프로세스다. RDB로 따지면 스키마를 정의하는 것과 같다.
마스터노드
인덱스를 생성, 삭제하는 등의 클러스터와 관련된 전반적인 작업을 담당한다.
데이터노드
문서가 실제로 저장되는 노드로 샤드가 배치된다. 색인 작업은 컴퓨팅 리소스를 많이 소모하므로 모니터링이 필요하다. 웬만하면 마스터 노드와 데이터 노드는 분리하는 것이 좋다.
코디네이팅 노드
들어온 요청을 라운드로빈 방식으로 분산시켜주는 노드이다.
인제스트 노드
색인에 앞서 데이터를 전처리하는 노드이다.
노드와 샤드와 레플리카
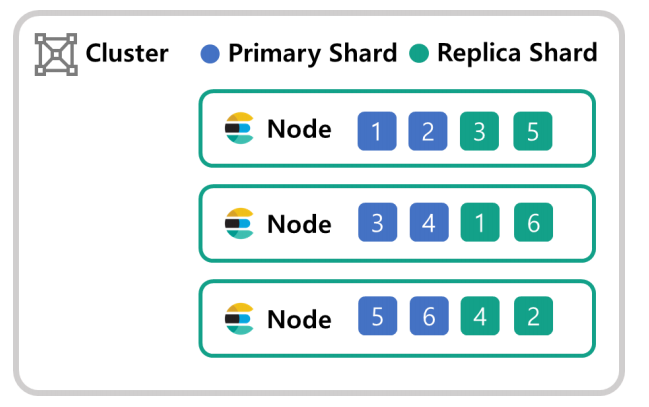
인덱스를 생성할 때 프라이머리 샤드와 레플리카 샤드를 설정하게 되어 있다.
다음 그림처럼 프라이머리 샤드는 2세트 레플리카 샤드도 2세트이다. 레플리카 샤드는 프라이머리 샤드가 다운되면 프라이머리로 승격되어 사용된다. 그림처럼 샤드가 각 노드에 분배되어 데이터가 저장되기 때문에 장애 대응에 효과적이다.
마무리
엘라스틱 서치의 가장 기본적인 용어들과 개념들에 대해 나열식으로 알아보았다. 검색 엔진 특성 상의 역인덱스 개념과 용어들에 대해 정리할 수 있어 좋았고, 결국 분산시스템 근본적으로 엄청나게 다른 것 같지는 않다는 것을 느끼는 것 같다. 다음 포스트에서 좀 더 딥하게 알아보자!
