저어엉말 오랜만에 글을 작성해본다.
이번에는 LSM 트리에 대해 알아보자.
https://www.cs.umb.edu/~poneil/lsmtree.pdf
위의 논문 자료를 Google Notebooklm으로 분석한 결과를 바탕으로 작성되었습니다!
LSM 트리란?
Log Structured Merge Tree로 쓰기 성능 최적화를 위한 트리 기반 인덱싱 구조
LSM 트리는 B 트리와 비교했을 때 쓰기에 큰 강점을 가진다. 즉, 쓰기가 압도적으로 많은 워크로드 (로그성 데이터, 시계열 데이터) 상황에서 적절한 선택지가 될 수 있다.
LSM 트리의 기본 구조와 동작 과정
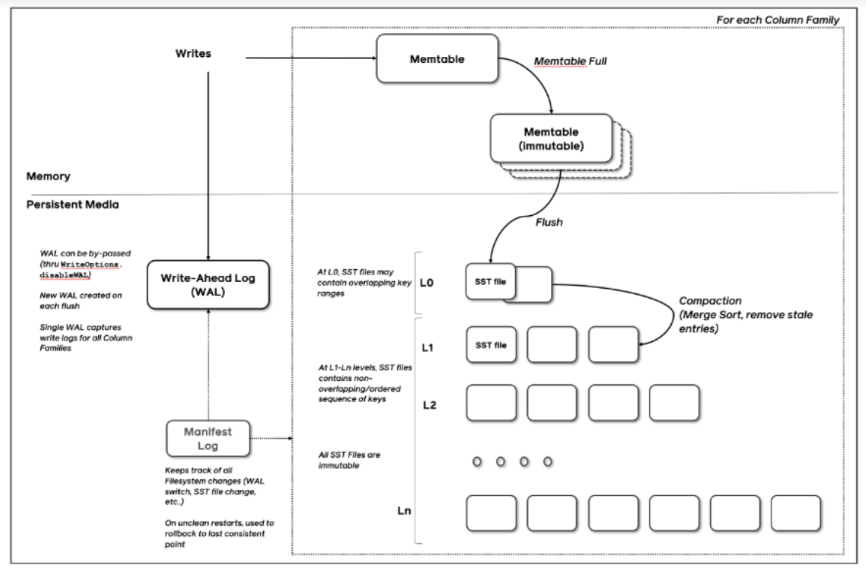
LSM 트리는 크게 2개 이상의 트리 컴포넌트로 이루어져 있다.
CO 트리(memtable, 메모리 상주 컴포넌트)
삽입할 데이터가 들어왔을 때 가장 먼저 기록되는 곳이다. 메모리 상에 유지되는 자료구조이며, 주로 AVL 트리, (2, 3)트리 red-black 트리 등 balaneced tree 자료구조를 사용한다.
간단한 삽입 순서는 다음과 같다.
- 데이터 생성 시, 복구용 로그(Sequential log)를 먼저 기록한다.
- 데이터를 자료구조에 삽입한다.
- 일정 임계치 이상으로 크기가 커지면, immutable table로 변환 후 디스크로 데이터를 롤링 머지한다.
C1, C2...CK 트리(sstable, 디스크 상주 컴포넌트)
C0보다 크기가 큰 디스크에 존재하는 트리이다.
B 트리와 유사한 구조를 갖고 있으나, 순차적인 디스크 접근에 최적화되어 있어 빈 공간 없이 100% 채워진다.
memtable에서 데이터가 일정량 이상 차면 이 sstable로 데이터가 머지된다.
디스크 암(Disk arm)의 움직임을 최소화하여 효율성을 높이기 위해, 루트 노드를 제외한 하위 레벨의 단일 페이지 노드들의 연속열은 다중 페이지 디스크 블록(Multi-page disk blocks)으로 묶여서 디스크에 저장된다.
C0 트리에서 병합된 새 데이터들은 버퍼에 있는 다중 페이지 블록의 빈 공간에 왼쪽에서 오른쪽 방향으로 차례대로 채워지며, 블록이 가득 차면 디스크상에 계속 증가하는 키 시퀀스 순서(Ever increasing key-sequence order)로 기록된다.
Rolling Merge(compaction)
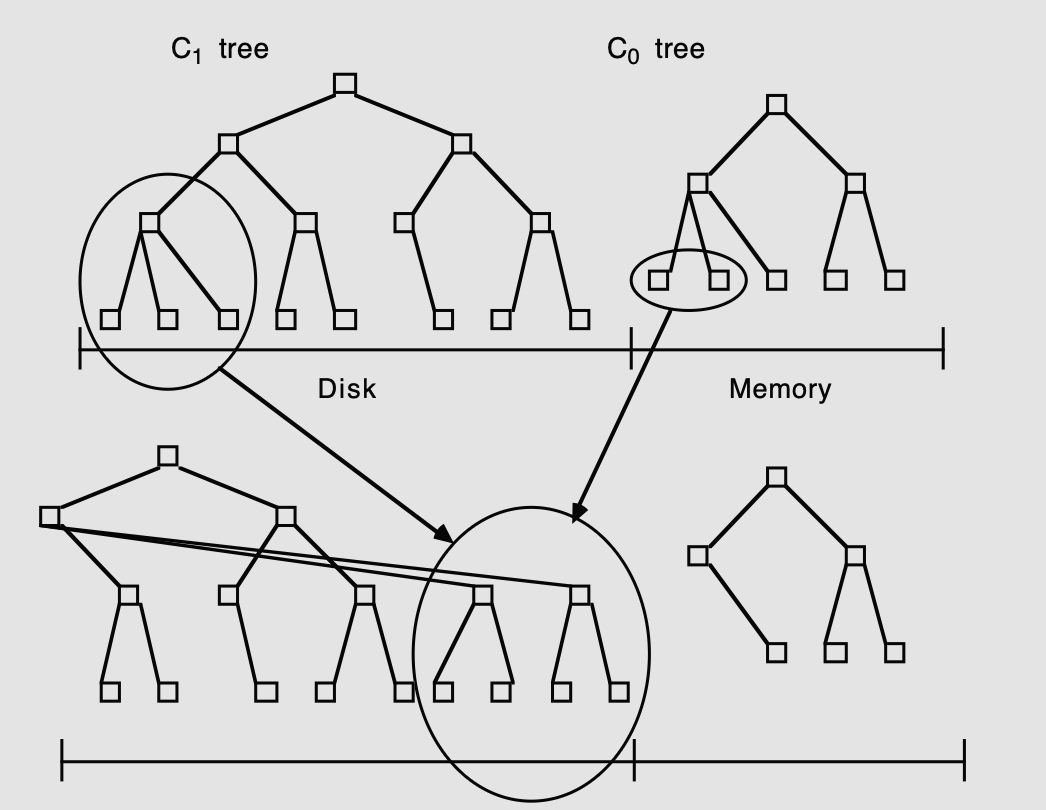
앞서 C0(memtable)에 쌓인 데이터가 임계치를 넘으면 sstable로 병합된다고 했다.
과정은 다음과 같다.
-
개념적 커서(Conceptual Cursor)가 존재하며 이는 C0 트리와 C1 트리의 동일한 키 값을 따라 서서히 이동한다.
이 커서는 머지 대상이 되는 양쪽 트리의(ex C0, C1) 가장 작은 키 값부터 가장 큰 키 값까지 순차적으로 이동하며, C0 트리에 있는 인덱싱 데이터를 디스크의 C1 트리로 뽑아내는 역할을 한다.
*최대 값에 도달하면 병합은 다시 가장 작은 값부터 새롭게 시작한다. -
다중 페이지 블록(Multi-page Block)의 읽기 및 분리 병합이 진행될 위치의 C1 트리 리프 노드들을 포함하고 있는 연속된 다중 페이지 블록을 디스크에서 메모리 버퍼로 한 번에 읽어온다.
이때 메모리 상의 작업 공간은 아래와 같이 두 가지 상태의 블록으로 나뉜다.
비워지는 블록(Emptying block): 병합되기 전의 기존 C1 트리 노드들을 담고 있으며, 커서가 지나가면서 항목들이 고갈되는 블록
채워지는 블록(Filling block): 병합이 완료되어 새롭게 만들어진 리프 노드들이 왼쪽에서 오른쪽으로 차례대로 > 쓰일 완전히 새로운 버퍼 블록 -
개별 노드 단위의 병합 단계(Merge Step): 버퍼에 위치한 비워지는 블록에서 단일 페이지 크기의 C1 리프 노드를 읽어 들인다.
그 다음 이 리프 노드의 데이터와 C0 트리의 리프 레벨에서 가져온 데이터 항목들을 하나로 합친다.(병합)
이 과정을 통해 C0 트리의 데이터는 삭제되어 크기가 줄어들며, 병합된 결과물은 100% 꽉 채워진 새로운 C1 트리의 리프 노드가 되어 채워지는 블록에 순서대로 기록된다.
병합 작업을 수행하여 개별 노드의 구조가 변경되는 동안에는 해당 노드에 잠금(Lock)이 걸려 다른 접근이 차단되지만, 노드 처리가 끝나면 잠금 해제된다. -
새로운 디스크 위치에 다중 페이지 블록 쓰기(Write-out): 새로운 리프 노드들로 채워지는 블록이 버퍼에서 가득 차게 되면, 이 블록은 디스크의 기존 위치에 덮어쓰이는 것이 아니라 완전히 새로운 빈 디스크 공간(New free area)에 한꺼번에 기록
덮어쓰지 않는 이유: 이전 데이터가 담긴 다중 페이지 블록을 덮어쓰지 않고 새로운 위치에 쓰는 것은 시스템 충돌(Crash) 시 복구(Recovery)를 위한 데이터를 보존하기 위함
공간 재사용: 새로운 위치에 성공적으로 데이터가 기록되면 더 이상 필요 없어진 기존 블록의 데이터는 무효화(Invalidated)되고, 나중에 이 공간은 블록 단위로 묶여서 추가적인 I/O 비용 없이 통째로 재사용 -
디렉토리 노드 업데이트 및 잔류 항목 처리 C1 트리의 리프 레벨이 새롭게 재구성되었으므로, 이를 가리키는 C1 트리의 상위 디렉토리(부모) 노드들 역시 변경된 리프 구조를 반영하여 업데이트
업데이트된 디렉토리 노드들은 디스크 I/O를 최소화하기 위해 즉시 디스크에 쓰이지 않고 버퍼에 오랫동안 유지
또한, 기존의 리프 노드가 비워지는 시점과 새로운 노드가 채워지는 시점이 정확히 일치하지 않기 때문에 언제나 자투리 데이터(Leftover entries)가 남게 되며, 이 잔류 항목들 역시 다음 블록이 디스크에 기록될 때까지 메모리 버퍼에 잠시 대기하게 된다.
결과적으로 롤링 병합은 C0의 메모리 데이터와 C1의 디스크 데이터를 메모리 버퍼 상에서 합친 뒤, 거대한 다중 페이지 블록 단위로 한 번에 새로운 디스크 공간에 밀어 넣는 방식을 취한다. 이를 통해 무작위 디스크 접근(Random access) 없이 순차적인 디스크 접근(Sequential access)만으로 트리를 성장시킬 수 있다.
이러한 롤링 머지 과정은 꼭 C0, C1 사이에서만 일어나는게 아니라, 인접한 트리에서 독립적으로 일어난다. 이를 통해 데이터가 처음 인입되면, 이후 머지 과정을 거쳐 점점 거대한 트리로 이동하게 된다.
그런데 병합 과정에서 옮겨진 데이터들은 어떻게 삭제될까? 또한 데이터가 단순히 삭제되는 경우에는 어떻게 동작할까?
의도적으로 삭제하는 경우
우선 논리적인 관점에서는 삭제할 데이터가 C0에서 곧바로 발견되지 않는다면, 삭제될 데이터라는 의미로 C0 트리의 적절한 위치에 해당 키 값과 식별자를 명시한 Delete node entry를 삽입한다. 이 노드는 기존의 데이터와 동일한 대우를 받아, 실제 데이터가 존재하는 곳을 만나기 전까지는 동일하게 병합 과정을 거친다.
또한 이 삭제 마킹을 통해 해당 데이터가 물리적으로 삭제되기 전까지 조회 시 결과에서 제외될 수 있도록 필터링한다.
이후 병합을 진행하다가 삭제할 데이터가 존재하는 트리를 만나게 되면 채워지는 노드로의 이동에서 해당 데이터를 의도적으로 누락시킨다. 또한 원래 존재하고 있던 트리에서도 해당 데이터를 물리적으로 해제시켜 데이터를 완전히 삭제한다.
병합에 의해 필요없어진 데이터를 없애는 경우
C0 트리에서 C1으로 옮겨진 데이터의 삭제 동작 과정
메모리에 유지되고 있는 C0 트리에서 디스크로 옮겨진 데이터는 배치로 메모리 상에서 삭제된다. 여기서 C0의 트리는 리밸런싱을 하지 않고 우선 데이터를 전부 삭제한 뒤 병합 과정이 끝나면 한번에 리밸런싱을 하여 CPU 연산 비용을 최소화한다.
C1 이상 트리(디스크 위치)에서 데이터의 삭제 동작 과정
병합 과정에서 병합된 노드들은 invalidated된다. 또한 C1 디렉토리에서 삭제된 후 다음 병합 단계에서 해당 공간이 물리적으로 해제된다.
정리하면, 삭제를 하는 경우 LSM에서는 단순히 C0에 삭제 엔트리만 추가하면, 롤링 병합 과정에서 자연스럽게 데이터가 삭제된다. 이를 통해 디스크 I/O를 최소화하여 성능을 높일 수 있다.
* 추가로 조건부 삭제도 가능하다. -> 나중에 관련 내용 추가
데이터 조회 과정
LSM 트리에서 데이터를 조회하는 과정에 대해서도 간략하게 알아보자.
- 기본적으로 데이터 조회를 위해서는 C0 -> C1 -> C2 ... 와 같이 각 트리의 데이터들을 전부 조회해야 한다.
- 삭제된 데이터에 대한 정보는 C0에 유지되고 있으므로 조회 시 삭제된 데이터는 필터링을 거친다.
- 순차적으로 트리를 탐색하는 과정에서 데이터를 찾은 경우 이후 트리는 조회하지 않고 바로 반환한다.
(바로 반환해도 되는 이유는 데이터가 업데이트된 경우 반드시 가장 최근에 발견된 데이터가 가장 최신 데이터이기 때문이다.)
동시성 문제
조회 도중 롤링 병합이 일어나는 등의 동시성 문제가 발생할 수도 있다. 아래의 3가지 케이스에 대해 알아보자.
조회와 디스크 병합의 충돌
조회(Find) 작업이 디스크 기반 컴포넌트의 특정 노드에 접근할 때, 동시에 다른 프로세스가 롤링 병합을 수행하며 해당 노드의 내용을 수정하고 있다면 물리적 충돌이 발생한다.
메모리(C0) 내 접근과 병합의 충돌
사용자가 C0 컴포넌트(메모리)에 새로운 데이터를 삽입하거나 조회하려 할 때, 동시에 병합 프로세스가 데이터를 디스크(C1)로 밀어내기 위해 C0 트리의 동일한 부분을 변경하려 한다면 충돌이 발생한다.
병합 커서 간의 속도 차이로 인한 병목(교차 문제)
작은 컴포넌트에서 데이터를 내보내는 커서(예: C i−1에서 Ci로)의 순환 속도는 큰 컴포넌트에서 데이터를 내보내는 커서(예: Ci에서 C i+1로)보다 항상 더 빠르다.
따라서 빠른 커서가 느린 커서를 앞질러 가야 하는 상황이 필연적으로 발생하는데, 이때 한 병합 프로세스가 다른 프로세스의 작업 위치에 가로막혀 차단(Blocked)될 위험이 있을 수 있다.
동시성 문제 방지 및 해결 메커니즘 이러한 충돌을 방지하고 동시성을 극대화하기 위해 LSM-Tree는 다음과 같은 방법을 사용한다.
-
노드 단위의 읽기/쓰기 잠금(Node-level Locking): LSM-Tree는 물리적 충돌을 피하기 위해 개별 노드(Node)를 잠금의 기본 단위로 사용
- 병합 과정에서 업데이트 구조가 변경되는 노드들에는 쓰기 잠금(Write lock)을 걸고, 조회를 위해 접근하는 노드에는 읽기 잠금(Read lock)을 걸어 두 작업이 서로를 배제하도록 한다.
- 데드락(Deadlock)을 피하기 위한 디렉토리 잠금 기법도 함께 사용
- 조회 시 읽기 잠금은 타겟 잎(Leaf) 레벨의 항목을 스캔한 직후에 즉시 해제
-
양자화된 순간(Quantized instants)의 잠금 해제를 통한 커서 추월 허용
-
세 번째 문제였던 병합 커서 간의 병목을 해결하기 위한 방법으로. 병합 작업을 수행할 때 시스템은 관련된 노드들(내부 및 외부 컴포넌트의 비워지는 노드와 채워지는 노드)에 쓰기 잠금을 건다.
-
이 잠금을 계속 유지하는 것이 아니라, 외부 컴포넌트의 비워지는 노드(Emptying block)가 하나씩 처리가 끝날 때마다 잠시 잠금을 해제하여 양자화된 순간마다 잠금을 풀어줌으로써, 뒤따라오던 더 빠른 커서나 넓은 범위를 조회하는 작업이 차단되지 않고 느린 커서를 무사히 지나쳐(Bypass) 갈 수 있게 한다.
-
여기서 중요한 문제는 느린 커서를 빠른 커서가 추월할 경우 빠른 커서에 의해 느린 커서가 병합 작업 중인 노드의 상태가 변할 수 있다. 이를 위해서 느린 커서의 위치를 재조정하는 등의 후속 작업이 필요하다. 구체적인 알고리즘은 논문에 없는 것 같다....
-
-
C0 트리(메모리)의 전담 CPU 할당 및 일괄 처리
메모리의 C0 트리에서 발생하는 충돌을 최소화하기 위해, C0와 C1 사이의 병합에는 별도의 전담 CPU를 할당하여 다른 접근이 차단되는 시간을 가장 짧게 유지한다. -
병합할 C0 항목들의 범위를 사전에 계산한 뒤 해당 범위 전체에 미리 쓰기 잠금을 걸어둔다.
(예를 들어 C0가 2-3 트리라면 병합 범위에 해당하는 서브트리 전체에 잠금을 걺) -
데이터를 삭제할 때마다 매번 트리의 균형을 맞추지 않고 계산된 항목들을 일괄적으로 삭제(Batch fashion)하여 CPU 시간을 크게 절약한 뒤, 병합 단계가 완전히 끝나면 그때 트리 전체를 한 번에 재균형화(Rebalance)한다.
마무리
지금까지 알아본 것 외에도 시스템 복구 과정, 데이터 온도와 LSM 트리의 경제성, 다중 컴포넌트 트리의 크기 비율 최적화 등 더 많은 내용이 존재한다. 해당 내용은 논문을 통해 확인해봐도 좋을 것 같다.
이상 긴 글 읽어주셔서 감사합니다!
📚 참고자료
https://uiandwe.tistory.com/92234
https://konkukcodekat.tistory.com/275#google_vignette
https://milktea24.github.io/posts/lsm-tree/
