머신러닝에서 예측 데이터를 모델에 거치면 예측값이 산출된다. 이때 예측값이 타겟 데이터와 일치한지 아닌지를 정량적으로 말해주는게 손실 함수다.
를 입력 받아서 class에 대한 score를 확인하는데 이 값을 손실 함수를 통해 score가 어느정도인지 정량적으로 확인할 수 있다.
손실 함수 Multiclass SVM Loss
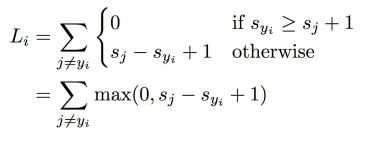
위의 수식을 풀어보자면 다음과 같다.
- = 타겟값 i의 예측 스코어
- = 타겟값 제외하고 나머지의 스코어
- = SVM을 잘 추려내기 위한 옵셋 값
- = loss 값이 음수로 넘어가면 max에 의해 0으로 대치된다

고양이의 이미지를 넣었을 때 cat의 스코어 값은 3.2, car의 스코어 값은 4.9, frog의 스코어 값은 -1.7이 나왔다. 높게 나올수록 해당 모델의 W를 통해 test train이 잘 먹었음을 알 수 있다.
cat의 loss를 위에 수식에 맞춰서 확인하면 다음과 같다.
max(0, 5.1 - 3.2 + 1) + max(0, -1.7 - 3.2 + 1)
= 2.9 + 0 = 2.9그리고 다른것들도 계산하면 car는 0, frog는 12.9의 loss임을 알 수 있다.
이렇게 모델의 loss값 확률만 측정한다.
그러면 셋 다 학습에 loss가 0이 되도록 모델을 조정하면 좋은 것일까?
그렇지 않다 training에 과적합(overfitting)이 된다.
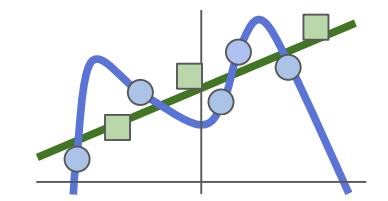
파란색 원형이 train이고 초록색이 target data인 경우의 그래프이다.
loss가 0이 나오도록 파란색 원형을 참고해서 fit을 맞추게 된다면 나중에 target 데이터로 모델을 학습 시켰을 때 overfitting으로 로스율이 크게 나오게 된다.
그래서 초록색 선을 이상적인 지향점으로 두고 test를 고려하는 train의 적절한 loss가 필요하다.
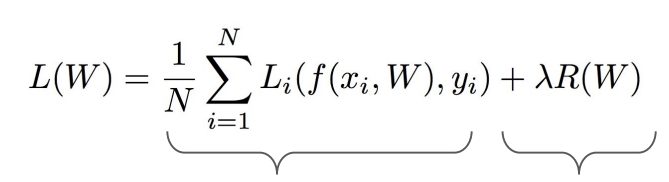
그래서 를 추가하는 Regularization(정규화, 제약)이 필요하다.
여기서 람다 의 값이 높으면 모델이 단순해져서 underfitting의 위험이 있고, 값이 낮으면 overfitting의 위험이 있다.
Regularization
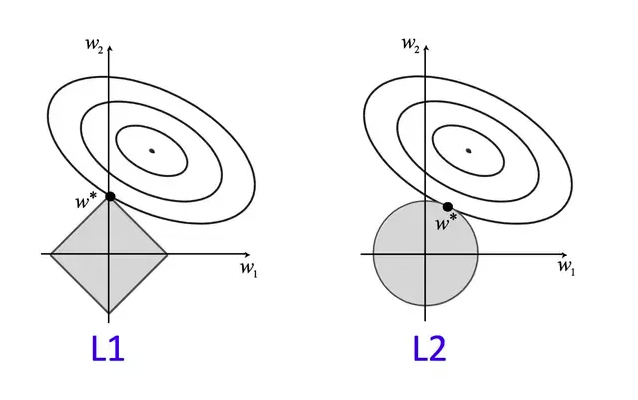
제약을 두는 방법은 여러가지가 있는데 그 중 L1, L2가 가장 많이 쓰인다.
L1은 중요한 가중치만 남기고 작은 가중치는 0으로 수렴하고, L2는 가중치를 0에 가깝게 유도하고 모두 고려하는 특성을 갖고 있다.
손실 함수 Softmax Classfier
각 스코어를 지수화해서 양수로 바꾸고, 정규화를 통해 모든 스코어의 합이 1이 되도록 확률로 만든다. 그리고 타겟 스코어에 를 씌워 loss를 정량적으로 만든다.

둘의 차이점
SVM은 정답과 오답 score의 margin 차이만 넘으면 크게 신경쓰지 않는다.
Softmax는 정답과 오답 score에 의미를 두고 수치화를 한다. 그리고 정답 score를 계속 높이려고 하는 특징이 있다.
