오늘은 딥러닝의 필수, 기본 이론인 경사하강법에 대해 공부한 것을 정리해보려고 한다.
개요
기본적으로 딥러닝은 가중치(파라미터)를 조정하면서 신경망이 원하는 출력을 내보낼 수 있도록 최적의 가중치를 학습하는 과정이다.
과정은 크게 3가지로 구분된다.
-
forward propagation yields an inferred 𝑦 for x
-
loss function used to calculate difference between
real 𝑦 and predicted 𝑦 -
weights are adjusted during backward propagation
1~3번 과정을 repeat 하면서 신경망이 데이터를 학습한다.
3번 과정에서 파라미터를 조정하는 방법은 학습에 있어서 굉장히 중요한 과정인데 여기서 경사하강법이 사용된다.
즉, 신경망이 미리 정해진 파라미터로 출력을 내보내는 과정(foward propagation - 순전파)을 거치고, 출력을 통해 계산된 목적함수(== 손실함수, 비용함수)로 다시 파라미터를 조정하는 과정(backward propagation - 역전파)이 '학습(training)'인데 이 학습과정에서 최적화된 파라미터를 찾기위해 경사하강법이 사용되는 것이다.
경사하강법
경사하강법은 아래 그림처럼 함수의 기울기(경사)를 구하고 경사의 절댓값이 낮은 쪽으로 계속 이동시켜 극값에 이를 때까지 반복시킨다.
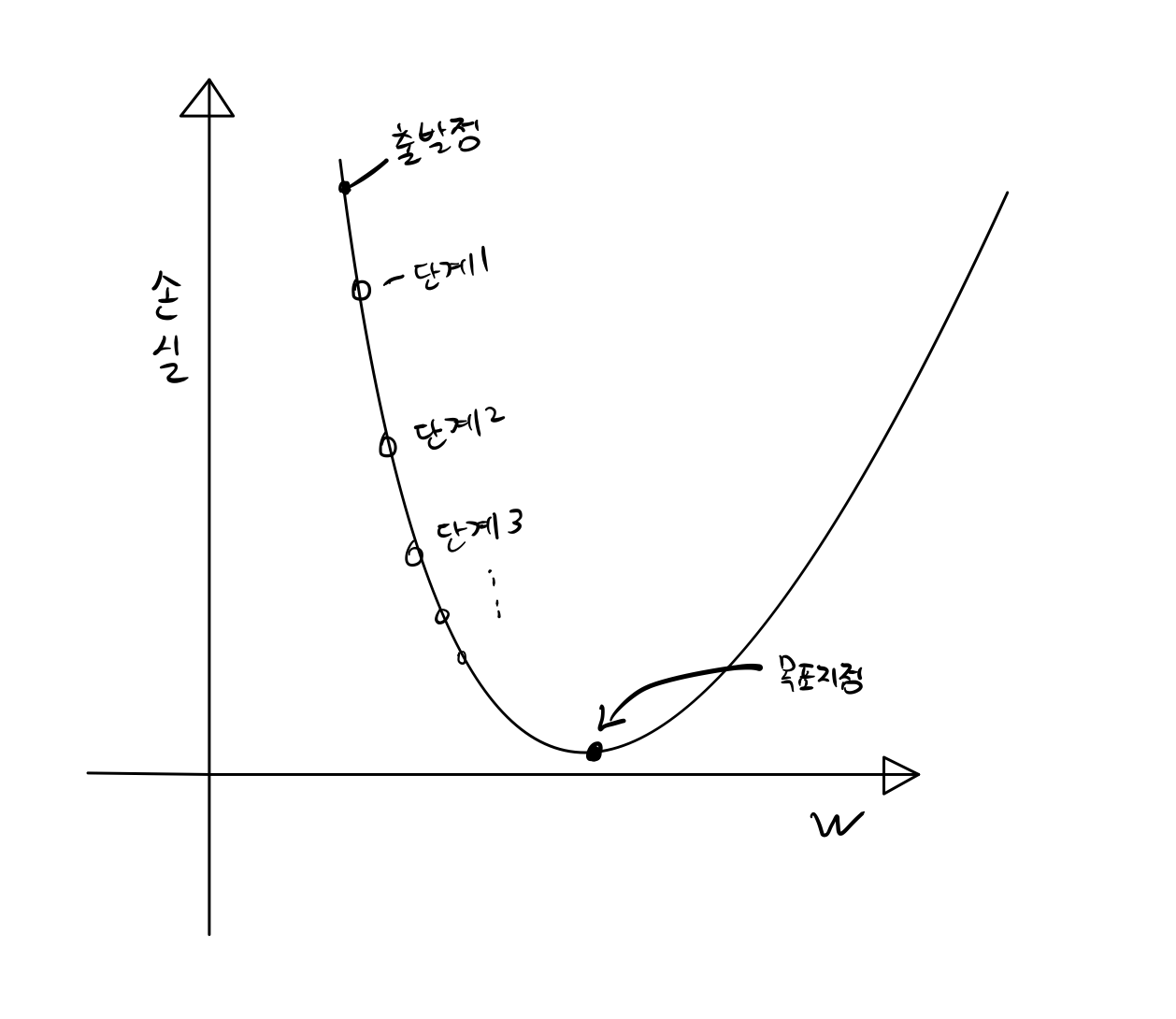
위와 같이 목표지점(minima)에 도착하면 손실을 최소화하는 파라미터 w를 가진 신경망이 되는 것이다.
파라미터를 업데이트 하는 식은 아래와 같다.(아래의 x == 위의 w, 둘다 파라미터를 뜻한다.)

위 수식에서 Xi+1은 update된 parameter이고, ri는 학습률, f'(xi)는 손실함수 f(x)에 대해서 xi를 편미분 한 값이다.
Loss에 대해서 xi를 편미분하게 되면 기울기를 얻을 수 있는데, 기울기는 항상 손실 함수 값이 가장 크게 증가하는 방향을 향한다. 따라서 경사하강법 알고리즘은 가능한 한 빨리 손실을 줄이기 위해 기울기의 반대 방향으로 이동하는 방법으로 진행되고, 이것이 xi에서 편미분 한 값을 '빼는' 이유이다.
편미분과 기울기에 대해 더 학습해보기 > https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent?hl=ko#expandable-1
학습률(learning rate)
학습률은 인간이 임의로 정할 수 있다. 학습률은 편미분 값이 너무 크게 되면 update된 파라미터 xi+1의 값이 너무 커지거나, 작아지는 문제가 생기기 때문에 값을 적당히 줄여 학습을 원활하게 할 수 있도록 돕는 역할을 한다.
학습률을 어떻게 조정하느냐에 따라 학습속도에 영향을 미친다. 학습률이 낮으면 앞선 그림의 단계1,단계2...로 진행되는 구간이 굉장히 촘촘해지고 그에 따라 탐색해야 할 영역도 많아지기 때문에 학습속도가 느려질 수 있다.
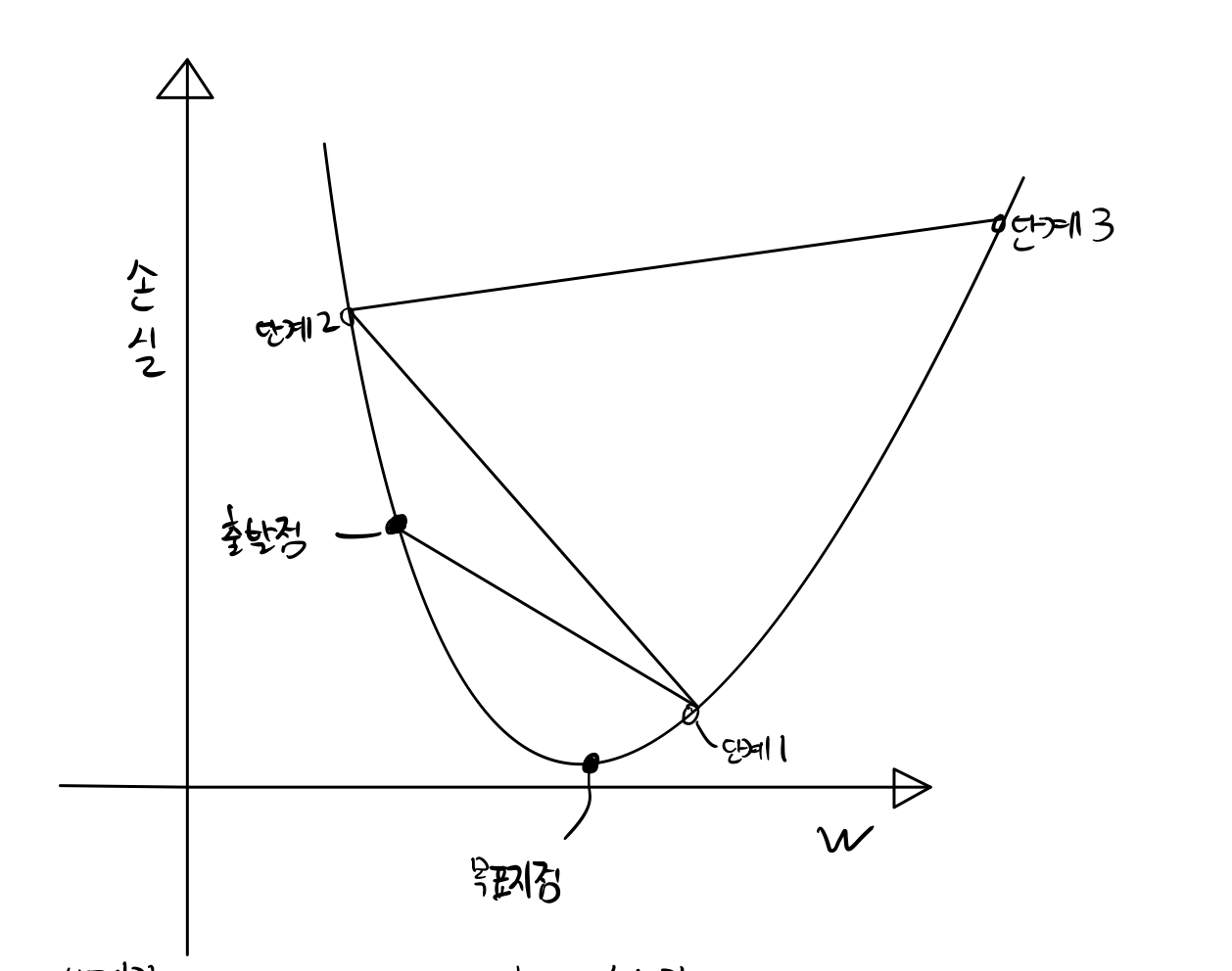
반면, 학습률이 높으면 아래 그림처럼 minima에 수렴하지 못하고 목표지점을 지나친 채 발산할 수 있다. 따라서 학습률을 적절하게 조절하는 것이 필요하다.
reference
https://developers.google.com/machine-learning/crash-course/reducing-loss/gradient-descent?hl=ko#expandable-1
https://ko.wikipedia.org/wiki/%EA%B2%BD%EC%82%AC_%ED%95%98%EA%B0%95%EB%B2%95
