공부하게 된 배경
https://programmers.co.kr/learn/courses/30/lessons/12906
위 문제를 푸는데 unique와 erase의 조합 한 줄 만으로 해결하는 코드가 있었다. 문제를 풀 때는 생각이 안났으나 두 함수 모두 대강 알고있던 함수였다. 그 중 unique함수가 어떻게 작동하는지 제대로 알고싶어서 공식문서를 참조해서 공부해보았다.
unique()
공식문서에서는 unique 함수를 "Remove consecutive duplicates in range" 라고 설명하고 있다. 대충 해석해보면 범위내에 연속적으로 존재하는 요소들을 삭제해준다. 라는 뜻같다.
consecutive가 중요한데,
예로, 10 10 20 30 20 10 10 라는 배열을 10 20 30 20 10 으로 바꾸어준다는 뜻이다.
또한 이 함수에서 중요한 부분은 정렬후에 배열의 사이즈를 바꾸어주지 않는것이다. 아래 코드를 참조해보자.
#include <bits/stdc++.h>
using namespace std;
int main(void) {
vector<int> arr = { 10,10,20,30,20,10,10 };
unique(arr.begin(), arr.end()); //range가 parameter로 들어간다.
for (int val : arr) cout << val << " ";
cout << '\n';
}결과 : 10 20 30 20 10 10 10
이 코드를 실행해보면 우리가 생각한 결과와 다르게 출력된다. 앞 부분은 원하던대로 10 20 30 20 10 이 나왔으나, 뒷부분에 불필요한 10까지 출력되고 있다. 이러한 이유때문에 unique는 보통 erase나 resize함수와 같이 쓰이게 되는데, 어떻게 작동하기에 이런 결과가 나오는지 알아보겠다.
작동방식
unique함수는 parameter로 range를 받는다. iterator형식으로 범위의 시작인 first와 범위의 끝인 last 2개를 받는다. 이때 last는 마지막 요소 그 다음을 의미한다.(그래서 마지막 요소 다음을 가리키는 end함수를 자주 사용한다.)
그렇게 first와 last iterator를 받고나서 unique가 작동되는데 작동원리는 아래와 같다.
template <class ForwardIterator>
ForwardIterator unique (ForwardIterator first, ForwardIterator last)
{
if (first==last) return last;
ForwardIterator result = first;
while (++first != last)
{
if (!(*result == *first)) // or: if (!pred(*result,*first)) for version (2)
*(++result)=*first;
}
return ++result;
} //출처 : https://www.cplusplus.com/reference/algorithm/unique/위 코드의 과정을 그림과 함께 따라가보겠다.
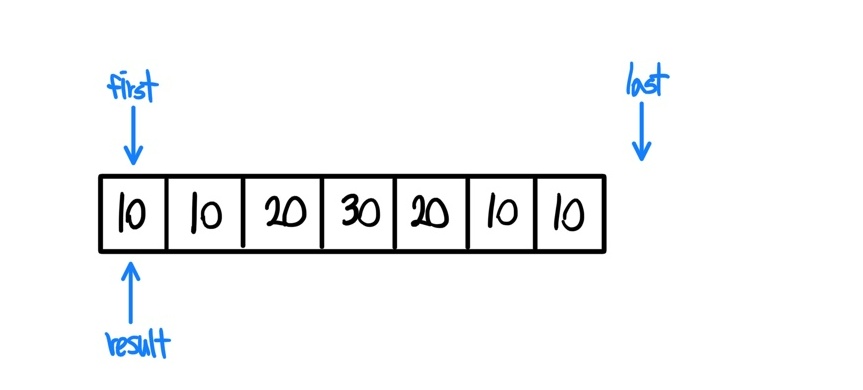
- 가장 기초상태이다. result라는 iterator까지 만들어서 first와 같은 주소를 가리키고 있는 형태이다.
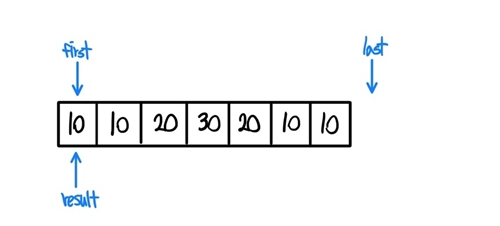
-
이후에
while (++first != last)를 실행하면서 first를 옮긴다. -
이후
if (!(*result == *first))구문을 실행한다. 이 구문은 result가 가리키는 값과 first가 가리키는 값이 다르면 참을 반환한다. 현재는 값이 10으로 같기 때문에 false를 반환하고 다시 while문으로 이동한다.
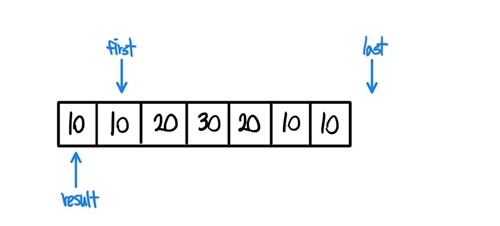
- 1번과 같은 과정으로 first를 옮기고 last와 다른지 검사한다.
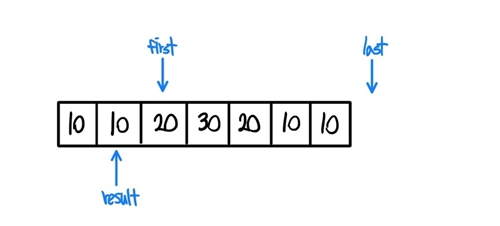
-
이번에는 first와 result가 가리키는 값이 다르기에
if (!(*result == *first))구문이 참을 반환한다. 이후에*(++result)=*first;구문을 실행한다. 우선 ++result를 실행하고,
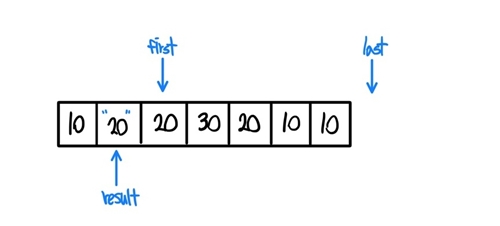
-
곧바로 result값을 first값으로 갱신해준다. 이러한 과정의 반복이다.
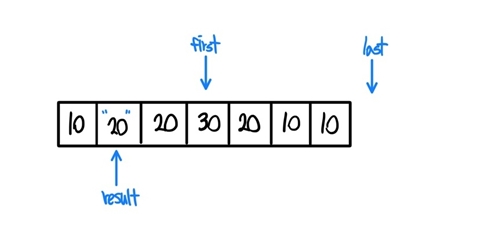
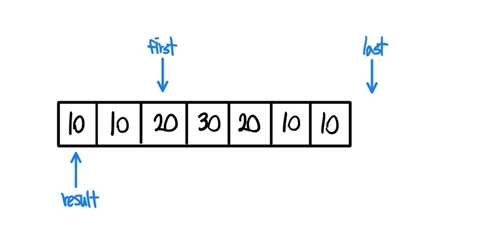
- 조금 더 살펴보자, first는 이동하고 result와 다른지 검사한다.
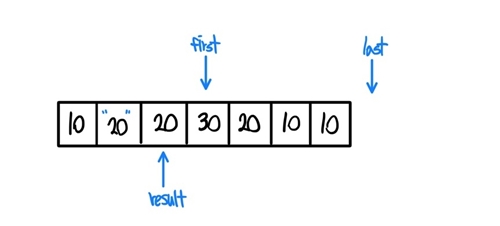
- 값이 20과 30으로 다르기에 if문은 참을 반환하고, result가 한칸 옮겨간다.
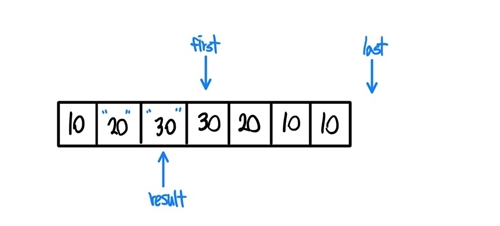
- 이후에 result가 가리키는곳의 값을 first가 가리키는 값으로 갱신한다.
.
.
.
.
.
.
.
.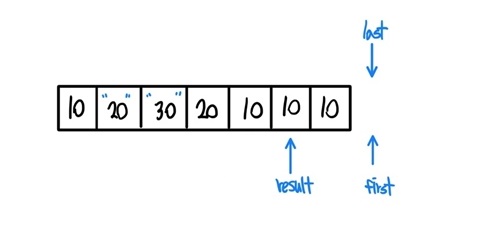
- 이러한 과정을 반복하다보면 위 형태로 끝이나고 result를 반복한다.
정리
위와 같이 unique함수는 값이 다르면 덮어씌우는 식으로 작동된다.
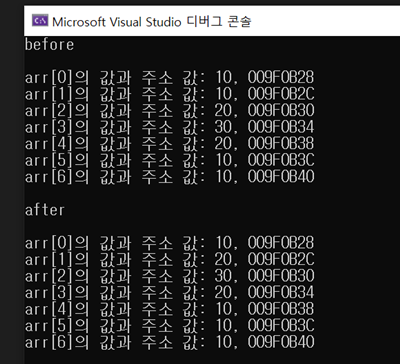
실제로 출력해보면 주소값은 그대로이고, 값이 덮어씌워진걸 볼 수 있다.
배열의 사이즈를 바꿔주거나 하진않지만 끝부분(쓰레기값의 처음) iterator를 반환해주기 때문에 erase나 resize함수를 사용해서 쓰레기값을 처리하기 용이하다.
※ 예시는 정렬을 사용하지 않았는데, unique가 의미하듯이 모든값을 unique하게 가질려면 정렬 실행후에 함수를 실행하면 되겠다.
※ 참고로 앞의 중복된 값이 뒤로 밀려나면서 쓰레기값이 구성된다는 말이 있던데, 이러한 내용은 레퍼런스에 적혀있지도 않을뿐더러, 실행해보면 꼭 그렇지 않다는것도 알 수 있다.
공식 참조문서를 보고 공부하는건 아직 쉽진않지만 작동원리를 정확하게 알 수 있다는 이점이 존재한다. 한글로 되어있는 문서와 조금씩 비교하면서 읽어나가다 보면 점점 적응이 가능할 것 같다.
