
공식 문서 & Github
소개
복잡한 머신러닝 코드를 몇 줄의 코드로 대체해주는 파이썬 라이브러리.
분석하고자 하는 데이터에, 여러 머신러닝들을 적용해본 뒤 가장 적절한 모델을 찾아주는 듯 하다.
실제 소개에서도 cikit-learn, XGBoost, LightGBM 등등 다양한 모델 위의 Layer에서 작동하는 라이브러리라고 되어있다.* 공부 겸 실습 포스팅이므로, 정확하지 않은 정보가 있을 수 있습니다.
설치 및 모델, 데이터 셋업
pip install pycaret[full] or pip install pycaret
설치 후
import pandas as pd
import os
file_path = "파일경로"
filenames = os.listdir(file_path)
filenames = [file for file in filenames if '.csv' in file]파일 경로 지정해주고, 사용할 파일이름들을 필터링했다.
df = pd.read_csv(f"{file_path}/{filenames[0]}")
df.describe()데이터프레임 한번 확인해주고,
from pycaret.classification import *
df_clf = setup(df, target = "타겟 컬럼", session_id=123, log_experiment=True, experiment_name = "Turbo")classification 모델을 사용하기 위해 임포트해주고, setup 실행.
여기서 session_id는 Seed값을 지정해주는거고, log_experiment와 name 파라미터는 학습 로그와 metrics 테이블을 반환해주는 인자.
만일 필요없다면 False, 혹은 무시해도 무관.
Trouble shoot
만일 이전에 Pandas-Profiling 등, pyyaml 버전을 건드릴 일이 생겼다면, 이런 오류가 날 수도 있다.
TypeError: load() missing 1 required positional argument: 'Loader'에러가 난다면 pyyaml 모델을 다운그레이드 해야함.
pip install pyyaml==5.4.1
이후 셋업이 성공했다는 알림과 함께 이런 결과가 나온다.

이후 최적의 모델을 찾는다.
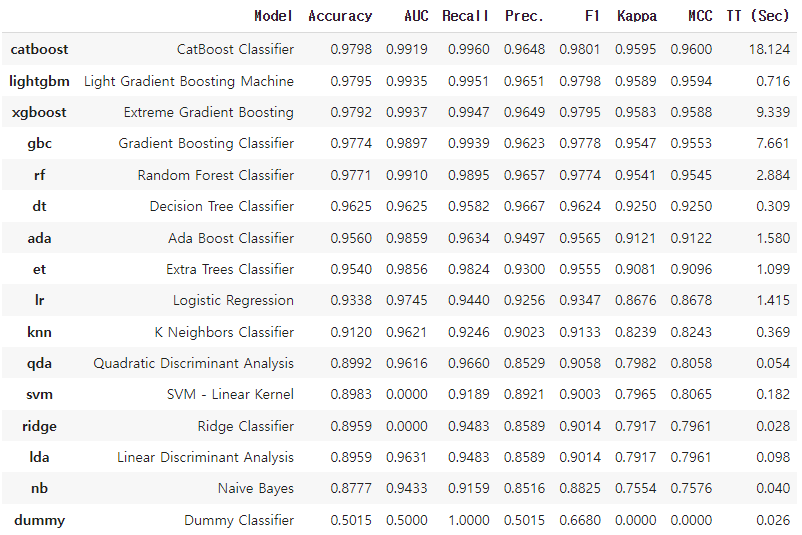
best_model = compare_models()여기선 분류 모델을 사용했으므로, 해당 메소드를 통해 성능 metrics를 평가하고, 훈련된 모델 테이블을 return해준다.
사용된 평가 지표는 다음과 같다는데.
- 분류: 정확도, AUC, Recall, 예측정확도, F1, Kappa, MCC
- 회귀: MAE, MSE, RMSE< R2, RMSLE, MAPE
ref: https://pycaret.org/compare-models/
사실 정확도, AUC, Precision말고 모르겠다.. 공부해야할듯
모델 비교 및 분석.
분석한 모델을 이렇게 한눈에 볼 수 있게 해준다.
밑의 결과는 내가 분석한 데이터 결과이다. 정확도가 높은순으로 정렬해주는듯.
catboost = create_model('catboost')
lightgbm = create_model('lightgbm')과 같이 모델을 생성해준다.
TIP
모델의 약자는 rf, ada, qda등등 다양한데, 잘 모르겠다면 models()를 사용해서 확인하자.
