
'서울시 열린데이터 광장'의 주민등록인구 (구별) 통계를 활용하여 EDA를 수행하고자 한다.
1. Data Frame 불러오기 & 전처리
1) Import data
- 아래와 같이 .txt파일로 되어 있는 데이터를 불러들였다.
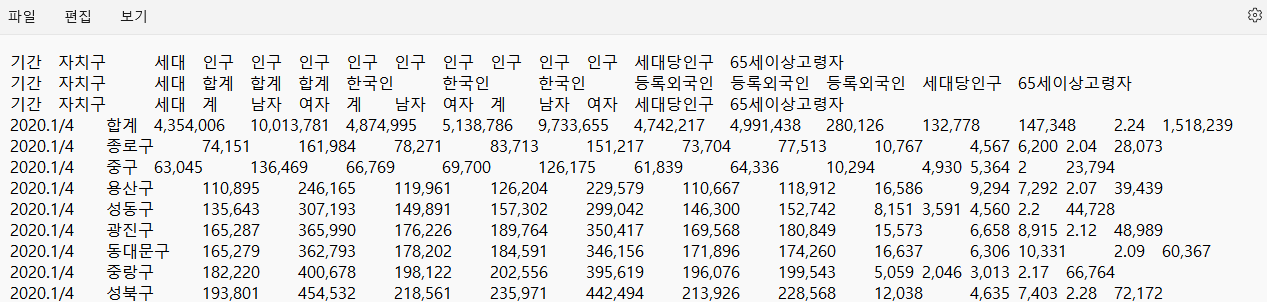
# Load DataFrame
import pandas as pd
df_target = pd.read_csv('../datas/report.txt', sep='\t')
df_target.head()
2) Index 수정
- 0, 1, 2번 index 제거 후 초기화
df2 = df_target.drop(index = [0, 1, 2])
df2.head(2)
df3 = df2.reset_index(drop = True)
df3.head(2)
3) columns name 변경
- 현재 컬럼: ['기간', '자치구', '세대', '인구', '인구.1', '인구.2', '인구.3', '인구.4', '인구.5', '인구.6', '인구.7', '인구.8', '세대당인구', '65세이상고령자']
- 수정 컬럼: ['기간', '자치구', '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '세대당인구', '65세이상고령자']
df3.rename(columns = {'인구':'합계',
'인구.1':'남자',
'인구.2':'여자',
'인구.3':'한국인 계',
'인구.4':'한국인 남자',
'인구.5':'한국인 여자',
'인구.6':'등록외국인 계',
'인구.7':'등록외국인 남자',
'인구.8':'등록외국인 여자'},
inplace = True)
df3.head(2)
4) 천 단위 구분자 "," 제거 후, data type 변경
- 변경 X: '기간', '자치구'
- 천단위 구분자 "," 제거 및 int로 타입 변경: '세대', '합계', '남자', '여자', '한국인 계', '한국인 남자', '한국인 여자', '등록외국인 계', '등록외국인 남자', '등록외국인 여자', '65세이상고령자'
- float으로 타입 변경: '세대당인구'
for i in range(len(df3)):
df3['세대'][i] = df3['세대'][i].replace(',','')
df3['합계'][i] = df3['합계'][i].replace(',','')
df3['남자'][i] = df3['남자'][i].replace(',','')
df3['여자'][i] = df3['여자'][i].replace(',','')
df3['한국인 계'][i] = df3['한국인 계'][i].replace(',','')
df3['한국인 남자'][i] = df3['한국인 남자'][i].replace(',','')
df3['한국인 여자'][i] = df3['한국인 여자'][i].replace(',','')
df3['등록외국인 계'][i] = df3['등록외국인 계'][i].replace(',','')
df3['등록외국인 남자'][i] = df3['등록외국인 남자'][i].replace(',','')
df3['등록외국인 여자'][i] = df3['등록외국인 여자'][i].replace(',','')
df3['65세이상고령자'][i] = df3['65세이상고령자'][i].replace(',','')df4 = df3.astype({'세대':int,
'합계':int,
'남자':int,
'여자':int,
'한국인 계':int,
'한국인 남자':int,
'한국인 여자':int,
'등록외국인 계':int,
'등록외국인 남자':int,
'등록외국인 여자':int,
'65세이상고령자':int,
'세대당인구':float})
df4.dtypes
2. 원하는 정보 얻기
1) 권역 column 추가
- 서울시는 아래와 같이 5개의 권역으로 구분된다.
- 도심권: ['종로구', '중구', '용산구']
- 동북권: ['성동구', '광진구', '동대문구', '중랑구', '성북구', '강북구', '도봉구', '노원구']
- 서북권: ['은평구', '서대문구', '마포구']
- 서남권: ['양천구', '강서구', '구로구', '금천구', '영등포구', '동작구', '관악구']
- 동남권: ['서초구', '강남구', '송파구', '강동구']
- ref: 서울시-도시계획체계
regions = []
for gu in df4['자치구']:
if (gu == '종로구') | (gu == '중구') | (gu == '용산구'):
regions.append('도심권')
elif (gu == '성동구') | (gu == '광진구') | (gu == '동대문구') | (gu == '중랑구') | (gu == '성북구') | (gu == '강북구') | (gu == '도봉구') | (gu == '노원구'):
regions.append('동북권')
elif (gu == '은평구') | (gu == '서대문구') | (gu == '마포구'):
regions.append('서북권')
elif (gu == '양천구') | (gu == '강서구') | (gu == '구로구') | (gu == '금천구') | (gu == '영등포구') | (gu == '동작구') | (gu == '관악구'):
regions.append('서남권')
else:
regions.append('동남권')
df4['권역'] = regions
df4.head()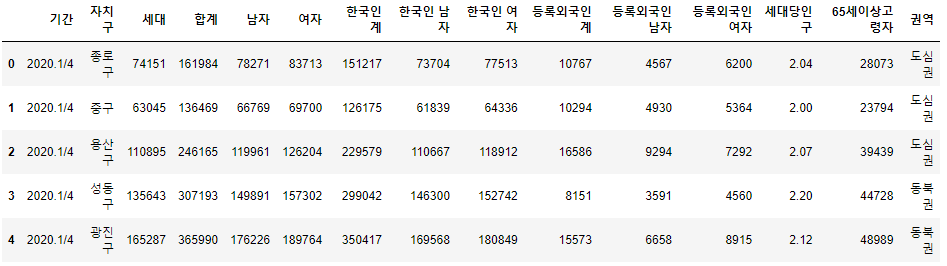
2) 각 권역별 아래 값의 합을 구하고, '합계'를 기준으로 내림차순 정렬
- pivot_table 활용
- 구할 값: ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자']
pivot1 = df4.pivot_table(index = '권역',
values = ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자'],
aggfunc = np.sum,
)
pivot1 = pivot1.sort_values(by = '합계', ascending = False)
pivot1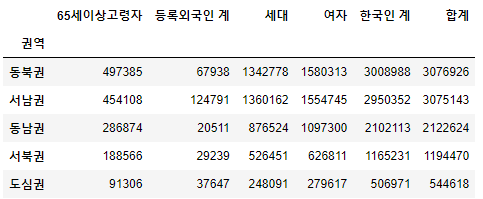
3) 각 권역별 ['고령자비율', '외국인비율', '여성비율', '세대당인구'] 컬럼을 만들어 아래와 같이 값을 입력하고 '외국인비율'을 기준으로 오름차순 정렬
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
- 세대당인구: (합계 - 등록외국인 계) / 세대
pivot1['고령자비율'] = pivot1['65세이상고령자'] / pivot1['합계'] * 100
pivot1['외국인비율'] = pivot1['등록외국인 계'] / pivot1['합계'] * 100
pivot1['여성비율'] = pivot1['여자'] / pivot1['합계'] * 100
pivot1['세대당인구'] = (pivot1['합계'] - pivot1['등록외국인 계']) / pivot1['세대']
pivot1 = pivot1.sort_values(by = '외국인비율', ascending = True)
pivot1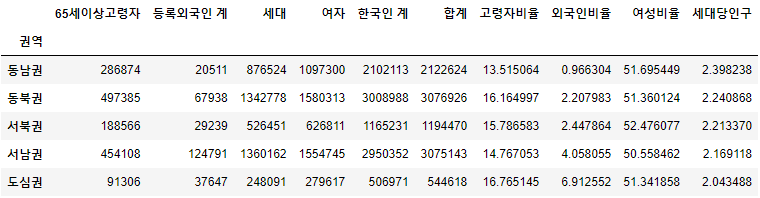
4) 각 구별 ['고령자비율', '외국인비율', '여성비율'] 컬럼을 만들어 아래와 같이 값을 입력하고 '세대당인구'을 기준으로 내림차순 정렬
- 고령자비율: 65세이상고령자 / 합계 * 100
- 외국인비율: 등록외국인 계 / 합계 * 100
- 여성비율: 여자 / 합계 * 100
# 구별
pivot2 = df4.pivot_table(index = '자치구',
values = ['합계', '세대', '여자', '한국인 계', '등록외국인 계', '65세이상고령자'],
aggfunc = np.sum,
)
pivot2 = pivot2.sort_values(by = '합계', ascending = False)
pivot2['고령자비율'] = pivot2['65세이상고령자'] / pivot2['합계'] * 100
pivot2['외국인비율'] = pivot2['등록외국인 계'] / pivot2['합계'] * 100
pivot2['여성비율'] = pivot2['여자'] / pivot2['합계'] * 100
pivot2['세대당인구'] = (pivot2['합계'] - pivot2['등록외국인 계']) / pivot2['세대']
pivot2 = pivot2.sort_values(by = '세대당인구', ascending = False)
pivot2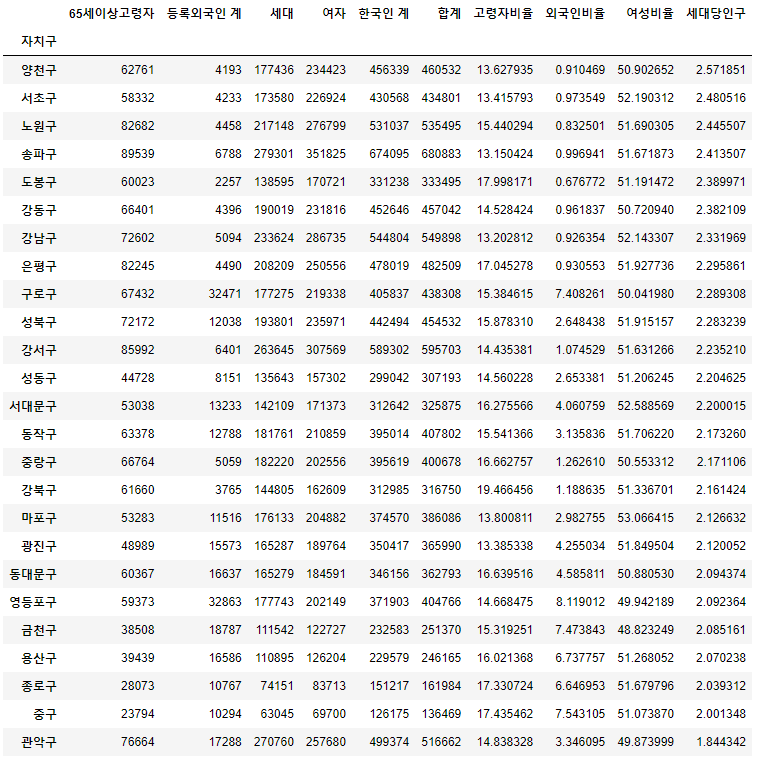
df4.loc[df4['자치구'] == '양천구', '고령자비율'] = 13.627935
df4.loc[df4['자치구'] == '서초구', '고령자비율'] = 13.415793
df4.loc[df4['자치구'] == '노원구', '고령자비율'] = 15.440294
df4.loc[df4['자치구'] == '송파구', '고령자비율'] = 13.150424
df4.loc[df4['자치구'] == '도봉구', '고령자비율'] = 17.998171
df4.loc[df4['자치구'] == '강동구', '고령자비율'] = 14.528424
df4.loc[df4['자치구'] == '강남구', '고령자비율'] = 13.202812
df4.loc[df4['자치구'] == '은평구', '고령자비율'] = 17.045278
df4.loc[df4['자치구'] == '구로구', '고령자비율'] = 15.384615
df4.loc[df4['자치구'] == '성북구', '고령자비율'] = 15.878310
df4.loc[df4['자치구'] == '강서구', '고령자비율'] = 14.435381
df4.loc[df4['자치구'] == '성동구', '고령자비율'] = 14.560228
df4.loc[df4['자치구'] == '서대문구', '고령자비율'] = 16.275566
df4.loc[df4['자치구'] == '동작구', '고령자비율'] = 15.541366
df4.loc[df4['자치구'] == '중랑구', '고령자비율'] = 16.662757
df4.loc[df4['자치구'] == '강북구', '고령자비율'] = 19.466456
df4.loc[df4['자치구'] == '마포구', '고령자비율'] = 13.800811
df4.loc[df4['자치구'] == '광진구', '고령자비율'] = 13.385338
df4.loc[df4['자치구'] == '동대문구', '고령자비율'] = 16.639516
df4.loc[df4['자치구'] == '영등포구', '고령자비율'] = 14.668475
df4.loc[df4['자치구'] == '금천구', '고령자비율'] = 15.319251
df4.loc[df4['자치구'] == '용산구', '고령자비율'] = 16.021368
df4.loc[df4['자치구'] == '종로구', '고령자비율'] = 17.330724
df4.loc[df4['자치구'] == '중구', '고령자비율'] = 17.435462
df4.loc[df4['자치구'] == '관악구', '고령자비율'] = 14.838328df4.loc[df4['자치구'] == '양천구', '외국인비율'] = 0.910469
df4.loc[df4['자치구'] == '서초구', '외국인비율'] = 0.973549
df4.loc[df4['자치구'] == '노원구', '외국인비율'] = 0.832501
df4.loc[df4['자치구'] == '송파구', '외국인비율'] = 0.996941
df4.loc[df4['자치구'] == '도봉구', '외국인비율'] = 0.676772
df4.loc[df4['자치구'] == '강동구', '외국인비율'] = 0.961837
df4.loc[df4['자치구'] == '강남구', '외국인비율'] = 0.926354
df4.loc[df4['자치구'] == '은평구', '외국인비율'] = 0.930553
df4.loc[df4['자치구'] == '구로구', '외국인비율'] = 7.408261
df4.loc[df4['자치구'] == '성북구', '외국인비율'] = 2.648438
df4.loc[df4['자치구'] == '강서구', '외국인비율'] = 1.074529
df4.loc[df4['자치구'] == '성동구', '외국인비율'] = 2.653381
df4.loc[df4['자치구'] == '서대문구', '외국인비율'] = 4.060759
df4.loc[df4['자치구'] == '동작구', '외국인비율'] = 3.135836
df4.loc[df4['자치구'] == '중랑구', '외국인비율'] = 1.262610
df4.loc[df4['자치구'] == '강북구', '외국인비율'] = 1.188635
df4.loc[df4['자치구'] == '마포구', '외국인비율'] = 2.982755
df4.loc[df4['자치구'] == '광진구', '외국인비율'] = 4.255034
df4.loc[df4['자치구'] == '동대문구', '외국인비율'] = 4.585811
df4.loc[df4['자치구'] == '영등포구', '외국인비율'] = 8.119012
df4.loc[df4['자치구'] == '금천구', '외국인비율'] = 7.473843
df4.loc[df4['자치구'] == '용산구', '외국인비율'] = 6.737757
df4.loc[df4['자치구'] == '종로구', '외국인비율'] = 6.646953
df4.loc[df4['자치구'] == '중구', '외국인비율'] = 7.543105
df4.loc[df4['자치구'] == '관악구', '외국인비율'] = 3.346095df4.loc[df4['자치구'] == '양천구', '여성비율'] = 50.902652
df4.loc[df4['자치구'] == '서초구', '여성비율'] = 52.190312
df4.loc[df4['자치구'] == '노원구', '여성비율'] = 51.690305
df4.loc[df4['자치구'] == '송파구', '여성비율'] = 51.671873
df4.loc[df4['자치구'] == '도봉구', '여성비율'] = 51.191472
df4.loc[df4['자치구'] == '강동구', '여성비율'] = 50.720940
df4.loc[df4['자치구'] == '강남구', '여성비율'] = 52.143307
df4.loc[df4['자치구'] == '은평구', '여성비율'] = 51.927736
df4.loc[df4['자치구'] == '구로구', '여성비율'] = 50.041980
df4.loc[df4['자치구'] == '성북구', '여성비율'] = 51.915157
df4.loc[df4['자치구'] == '강서구', '여성비율'] = 51.631266
df4.loc[df4['자치구'] == '성동구', '여성비율'] = 51.206245
df4.loc[df4['자치구'] == '서대문구', '여성비율'] = 52.588569
df4.loc[df4['자치구'] == '동작구', '여성비율'] = 51.706220
df4.loc[df4['자치구'] == '중랑구', '여성비율'] = 50.553312
df4.loc[df4['자치구'] == '강북구', '여성비율'] = 51.336701
df4.loc[df4['자치구'] == '마포구', '여성비율'] = 53.066415
df4.loc[df4['자치구'] == '광진구', '여성비율'] = 51.849504
df4.loc[df4['자치구'] == '동대문구', '여성비율'] = 50.880530
df4.loc[df4['자치구'] == '영등포구', '여성비율'] = 49.942189
df4.loc[df4['자치구'] == '금천구', '여성비율'] = 48.823249
df4.loc[df4['자치구'] == '용산구', '여성비율'] = 51.268052
df4.loc[df4['자치구'] == '종로구', '여성비율'] = 51.679796
df4.loc[df4['자치구'] == '중구', '여성비율'] = 51.073870
df4.loc[df4['자치구'] == '관악구', '여성비율'] = 49.873999df5 = df4.sort_values(by = '세대당인구', ascending = False)
df5.head()
5) ['고령자비율', '외국인비율', '여성비율', '세대당인구']간의 피어슨 상관계수 행렬(Correlation matrix)를 구하기
pivot1.dtypes
cols = ['고령자비율', '외국인비율', '여성비율', '세대당인구']
corr = pivot1[cols].corr(method = 'pearson')
corr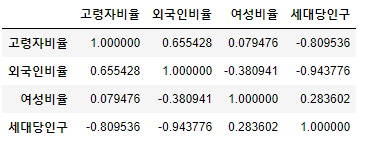
3. 시각화
# 한글 설정
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
%matplotlib inline
plt.rcParams['axes.unicode_minus'] = False
f_path = 'C:/Windows/Fonts/malgun.ttf'
font_name = font_manager.FontProperties(fname=f_path).get_name()
rc('font', family = font_name)import warnings
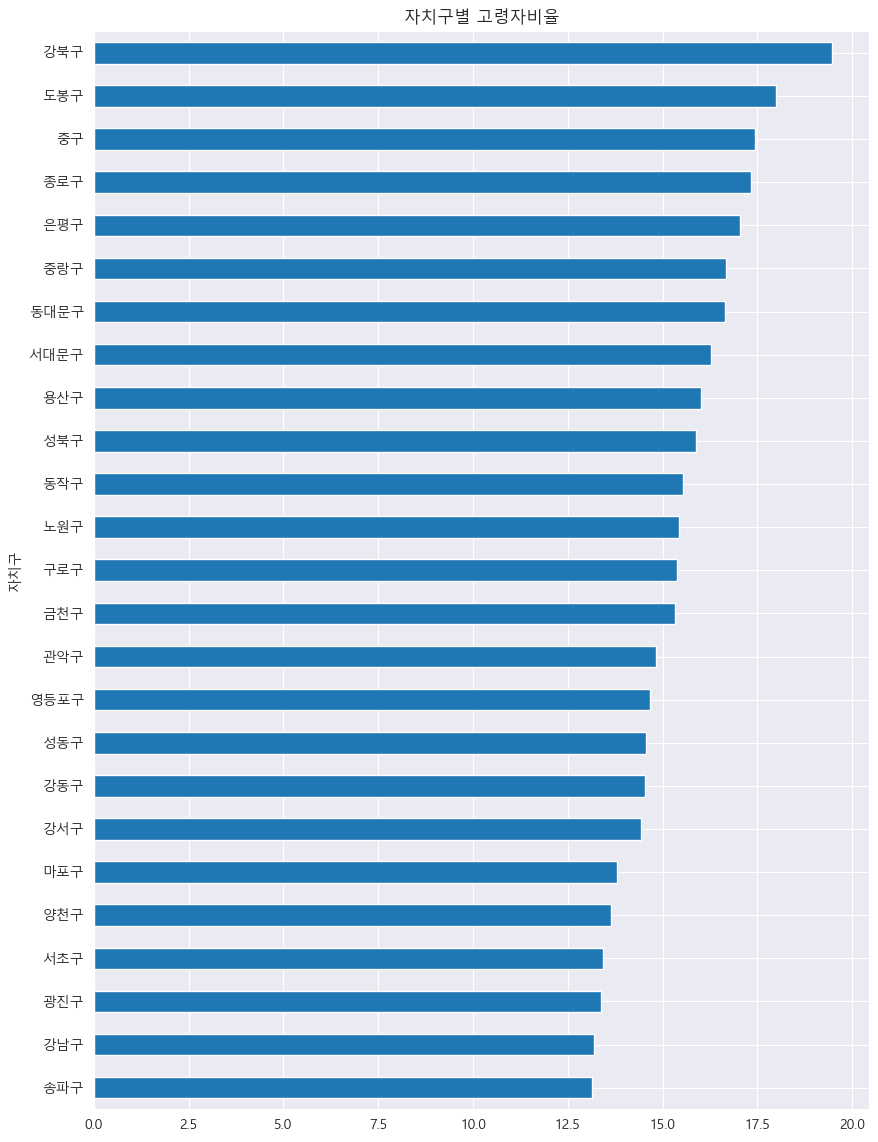
warnings.filterwarnings(action='ignore')1) 자치구별 고령자비율을 내림차순에 따라 barh 그래프로 시각화
# 인덱스를 자치구로 변경(df6)
df6 = df5.set_index('자치구')
df6.head(2)
df6['고령자비율'].sort_values().plot(
kind = 'barh',
title = '자치구별 고령자비율',
grid = True,
figsize = (10, 14)
)
2) 권역별 등록외국인 계를 파이차트로 시각화
pivot3 = df5.pivot_table(index = '권역',
values = ['등록외국인 계'],
aggfunc = np.sum,
)
pivot3
plt.pie(pivot3['등록외국인 계'], labels = pivot3.index)
plt.title('권역별 등록외국인 계')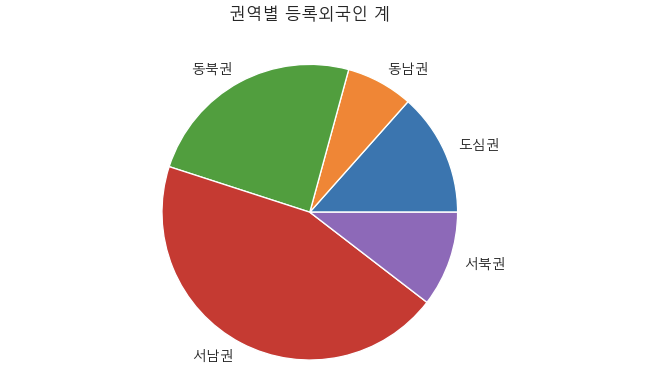
3) 권역별 외국인비율을 Box plot으로 시각화
import seaborn as sns
plt.figure(figsize = (10, 8))
plt.grid(True)
sns.boxplot(x = '권역', y = '외국인비율', data = df5, palette = 'husl')
plt.show()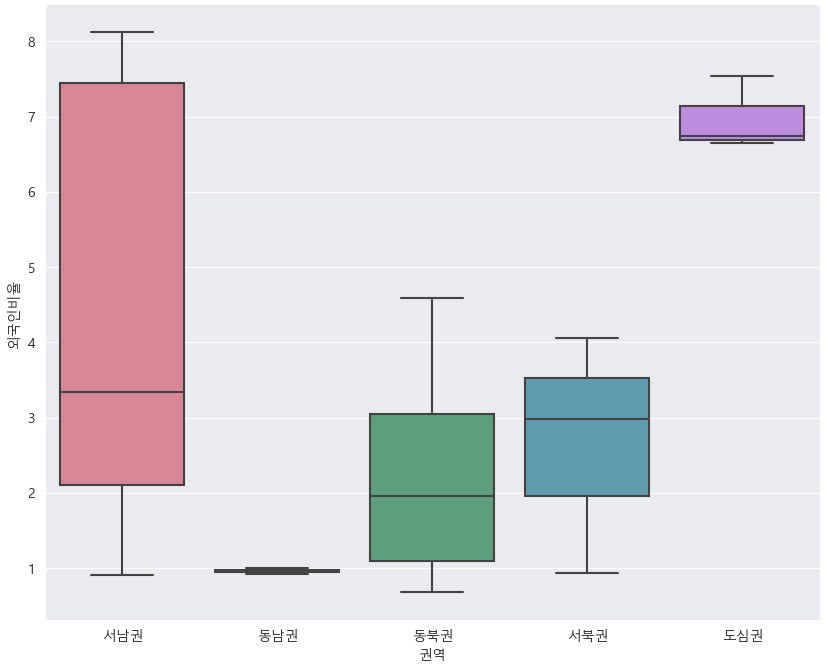
4) 자치구별 외국인비율-세대당인구를 scatter plot에 나타내고, 상관관계에 따른 Regression Line 시각화
# 자치구별 외국인비율과 세대당 인구의 regression plot => hue = '자치구'
sns.lmplot(x = '외국인비율', y = '세대당인구', data = df5, hue = '자치구')
plt.show()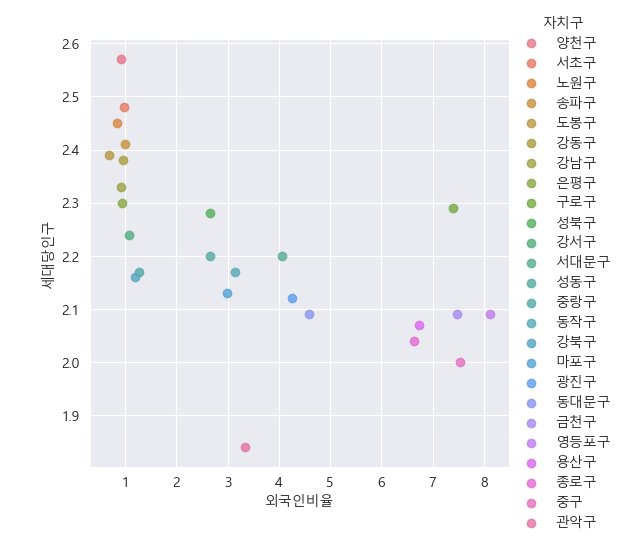
# 구 구분 없이 외국인비율과 세대당 인구의 regression line
sns.lmplot(x = '외국인비율', y = '세대당인구', data = df5)
plt.show()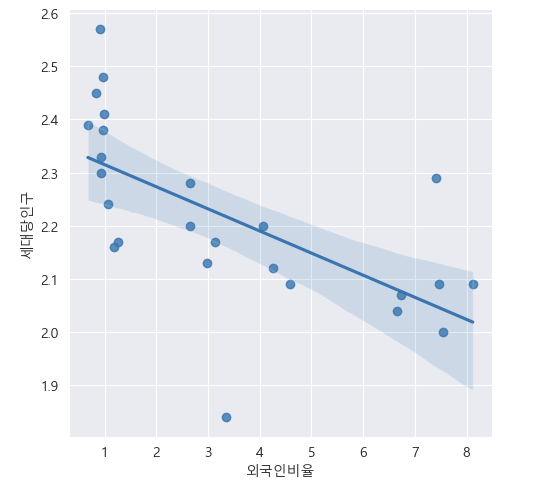

Date Scientist & Data Analyst