✅ Precision 과 Recall
- Precision (정밀도)
- 모델이 Positive라고 예측한 것 중 실제 Positive인 비율
- Precision = True Positive / (True Positive + False Positive)
- Recall = Sensitivity (재현율 = 민감도)
- 실제 Positive인 것 중 모델이 Positive라고 예측한 비율
- Recall = True Positive / (True Positive + False Negative)
- True Positive Rate(TPR)
- Specificity (특이도)
- 실제 Negative인 것 중 모델이 Negative라고 예측한 비율
- Recall = True Negative / (True Negative + False Positive)
- True Negative Rate(TNR)
✅ F1 Score
- F1 Score
- Precision(정밀도)과 Recall(재현율)의 조화 평균을 나타내는 지표
- F1 = 2 (Precision Recall) / (Precision + Recall)
- Precision과 Recall은 각각 trade-off 관계에 있음. F1 score는 이 둘의 균형을 잡아주는 단일 지표
- Macro F1 Score
- 각 클래스별 F1 Score를 계산한 후 평균을 내는 방식
- 모든 클래스를 동등하게 취급
- Micro F1 Score
- 모든 클래스의 TP, FP, FN을 합산
- 합산된 값으로 Precision과 Recall 계산
- 이를 바탕으로 하나의 F1 Score 계산
- 데이터셋이 불균형할 때 더 유용, 데이터가 많은 클래스에 더 큰 가중치 부여
- 전체 데이터셋에서의 성능을 하나의 지표로 보고 싶을 때
- Weighted F1 Score
- 각 클래스별로 F1 Score를 계산한 후, 각 클래스의 샘플 수에 비례하여 가중치를 주어 평균을 계산
- 각 클래스의 샘플 수를 고려하여 가중치를 준 F1 Score
- 데이터셋에서 더 많은 샘플을 가진 클래스에 더 높은 가중치 부여
- 클래스별 성능을 개별적으로 보되, 데이터 크기를 고려하고 싶을 때
✅ BA
- Balanced Accuracy
- 분류 모델의 성능을 평가하는 중요한 지표 중 하나
- 특히 클래스 불균형(imbalanced classes)이 있는 데이터셋에서 유용
- 계산 방법
- BA = (민감도(Sensitivity) + 특이도(Specificity)) / 2
- 또는 BA = (True Positive Rate + True Negative Rate) / 2
- BA가 중요한 이유
- 데이터 불균형 상황에서 일반 정확도(Accuracy)보다 더 신뢰할 수 있음
- 각 클래스의 성능을 균등하게 고려
- 0.5는 랜덤 추측 수준, 1.0은 완벽한 예측을 의미
✅ mAP (mean Average Precision)
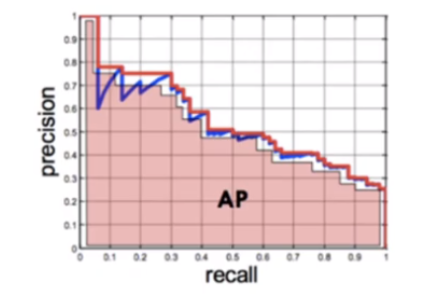
- AP 와 mAP
- mAP: precision과 recall을 그래프로 나타냈을 때의 면적
- 모든 class의 AP에 대한 평균값이 mAP (모든 class에 대하여 Precision/Recall의 값을 avg 취한 것)
[참고] https://artiiicy.tistory.com/25
