인덱스(index)
테이블의 데이터를 빠르게 검색하기 위해 사용되는 자료구조.
- 책의 맨앞혹은 맨뒤에 있는 색인, 영어사전의 알파벳순 정렬을 인덱스의 실생활상의 예시로 들 수 있다.
- 데이터베이스의 테이블의 데이터가 점점 커질수록 데이터를 검색(조회)함에 시간이 오래걸릴 수 있기 때문에 인덱스라는 데이터와 데이터의 위치를 포함한 자료구조를 생성하여 빠르게 검색하도록 한다.
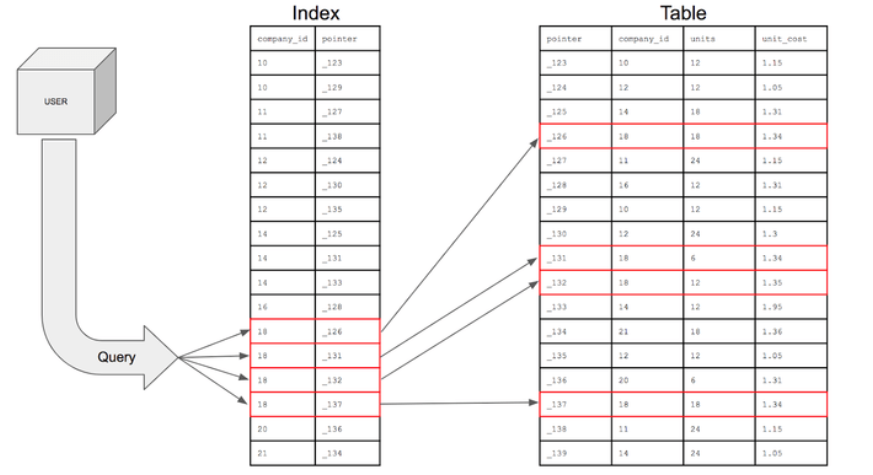
인덱스의 구조
- 인덱스는 여러 자료구조를 이용하여 구현할 수 있는데 그중 대표적으로 B-Tree와 B+Tree, 해시 테이블 자료구조를 사용하여 구현한다.
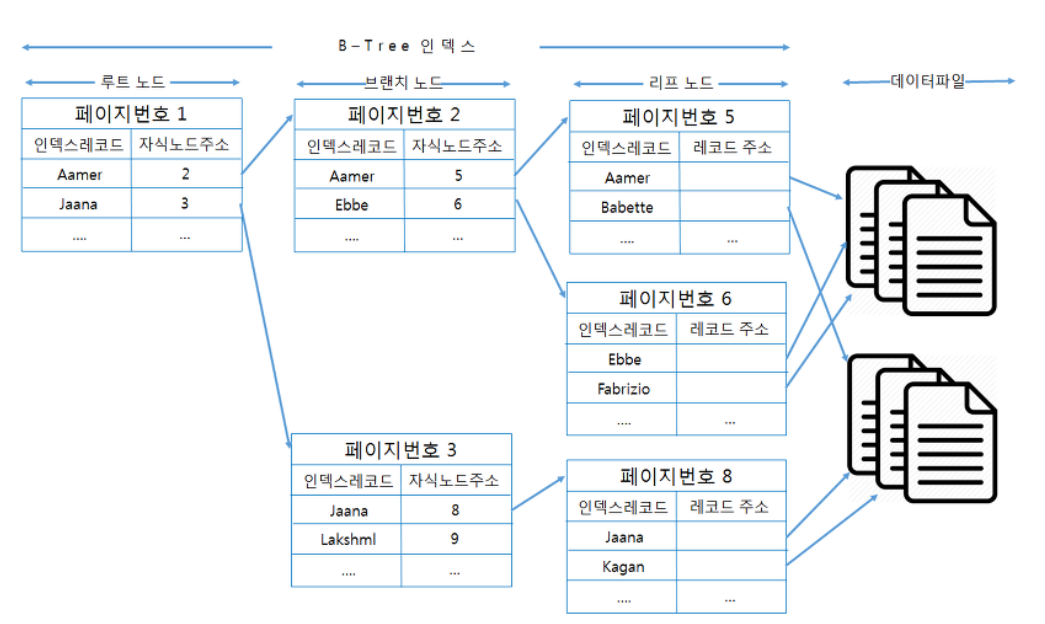
B-tree(Balanced Tree)
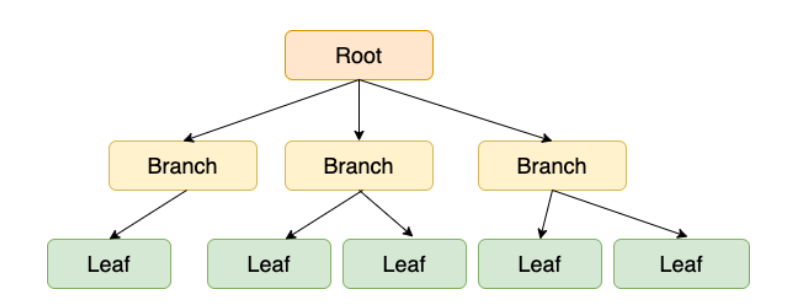
- 인덱스 구현시 보편적으로 많이 사용되는 자료구조
- 최상단 노드를 루트 노드(Root Node), 중간 노드들을 브랜치 노드(Branch Node), 최하위 노드들을 리프 노드(Leaf Node)라고한다.
- 이진검색트리와 비슷하지만 한 노드당 자식노드를 2개 이상 가질 수 있다는 차이점이 있다.
- B-tree 사용시 어떤 데이터를 조회하던지, 이에 사용하는 조회 과정의 비용 및 시간이 균등하다. 균일성을 보장한다고 볼 수 있다.
- 데이터 조회시 맨위 루트 노드부터 탐색이 일어나고 브랜치 노드를 거쳐 리프 노드까지 도착한다.
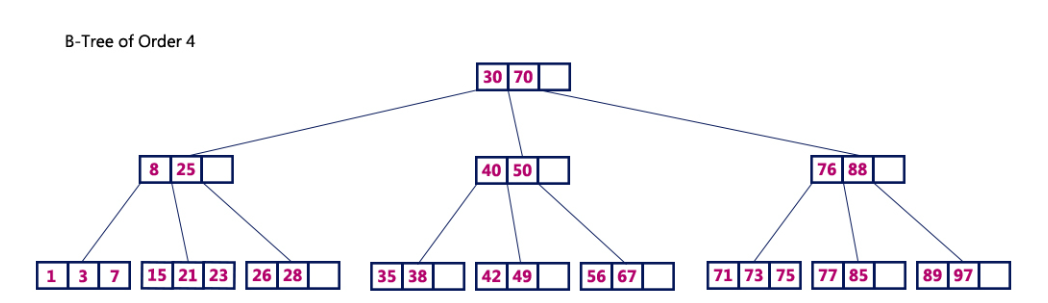
B-tree 특징(추가)
- 각 노드의 자료는 정렬되어 있다.
- 자료는 중복되지않는다.
- 모든 리프노드는 같은레벨에 있다.
- 루트노드는 자신의 리프노드가 되지않는 이상 적어도 2개이상의 자식을 가진다.
- 루트노드와 리프노드를 제외한 노드들은 최대 M개부터 최소 M/2 개까지의 자식을 가질수 있다.(M차 B-tree)
- 노드의 키는 최대 M-1개부터 최소 (M/2)-1개의 키가 포함될 수 있다.
- 자식 수의 하한값을 t라고 하면 M = 2t-1을 만족한다.
- 균형이진트리의 연속으로 최악의 경우라도 O(logN)의 시간복잡도를 가진다.
B+tree
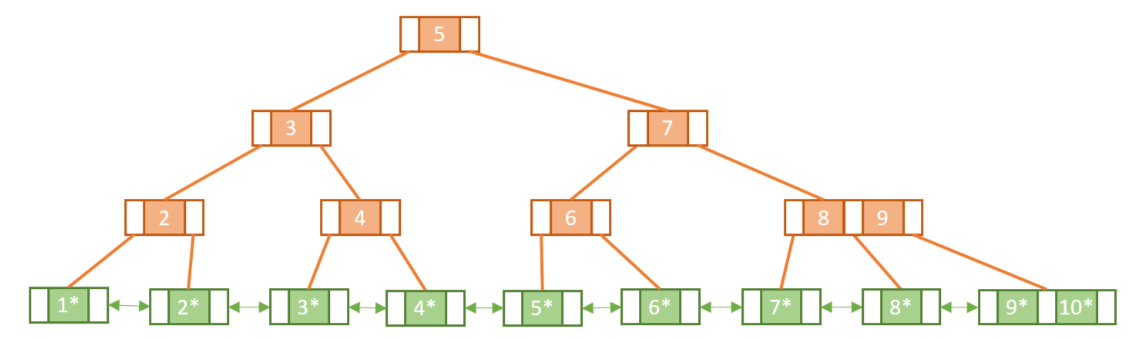
- 기존 B-tree의 단점을 개선시킨 자료구조.
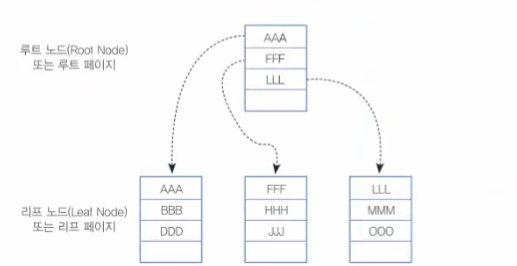
- 리프노드에만 키값과 데이터값을 저장하고, 나머지 노드들은 데이를 위한 key값만을 가진다. 이때 리프노드는 데이터 노드, 리프노드가 아닌노드는 인덱스 노드라고 한다.
- 리프노드들은 이중연결리스트(doubly-linked list)로 연결되어있다.
- 같은레벨 노드들은 키값에 따라 정렬되어있다.
위두가지 특징으로 인해 B-tree대비 순차접근, 범위검색이 보다 더 효율적으로 수행될 수 있다. - 데이터값을 가진 리프노드만 중복을 허용하지 않으며, 이외 key값만을 가지는 노드들은 중복될 수 있다.
한 노드당 더많은 key값을 보유할 수 있으므로, 더 적은 수의 노드로 검색할수있기에 레벨비례 검색이 더빠르게 수행 될 수 있다.
InnoDB에서 사용된 B+tree
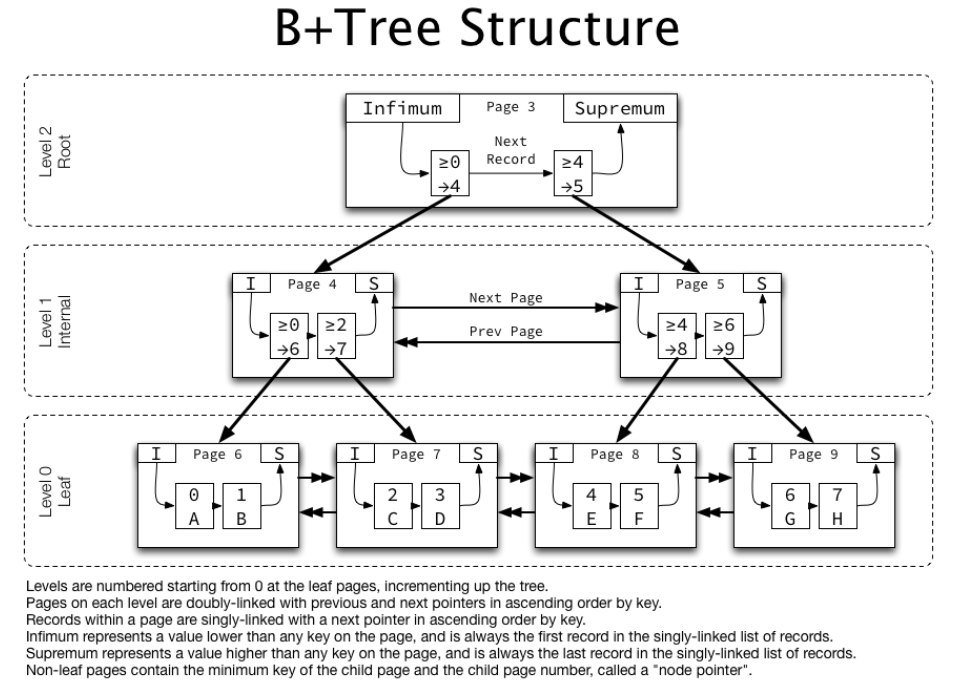
- B+tree 를 좀더 복잡하게 구현
- 리프노드만 연결리스트(이중)로 연결된 기존 B+tree와 달리 리프노드외 루트노드를 제외한 다른 자식노드들도 단일연결리스트로 연결됬다는 차이점
해시 테이블(Hash Table)
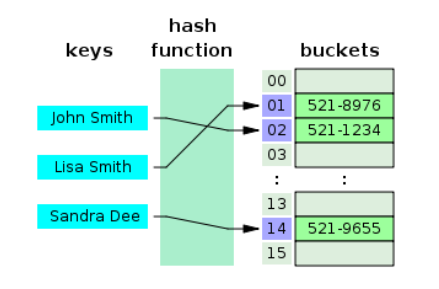
- 해시 테이블은 (Key,Value)로 데이터를 저장하는 자료구조로 빠른 데이터 검색이 필요할때 유용하다.
- O(1)의 시간복잡도를 가지며 매우 빠른 검색을 지원한다.
- 해시값이 1이라도 달라지면 완전히 다른 해시값으로 변형되는 특징때문에 동등비교(=)검색에는 최적화 되어있지만 범위를 검색(>, <=등)하거나 정렬된 결과를 가져오는 목적으로는 사용하기가 힘들다.
인덱스의 대수확장성(index Scalability)
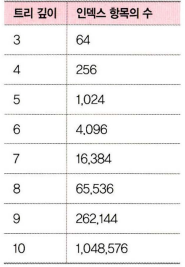
- 트리깊이가 리프 노드 수에 비해 느리게 성장하는 것
- 트리의 깊이가 한 깊이씩 증가하면 최대 인덱스의 수가 최대 4배 증가하는 것을 의미한다.
- 실제 인덱스는 훨씬 효율적이며, 인덱스가 효율적인 이유라고 들 수 있는 이유중 하나.
인덱스를 만드는 방법
MySQL기준
MySQL은 데이터를 한곳에다가 모두 저장하는것이 아닌 페이지(page)단위로 쪼개어 저장하는 특징이 있다.
클러스터인덱스와 보조인덱스로 나뉜다.
클러스터 인덱스(Clustered-index)
- 특정 나열된 데이터들을 일정 기준상으로 정렬해주는 인덱스.
영어사전을 예로들 수 있으며, 생성시 데이터 페이지 전체가 다시 정렬된다. - 해당 정렬특징때문에 이미 대용량의 데이터가 입력된 상태면 클러스터형 인덱스 생성은 심각한 시스템 부하를 초래할 수 있다.
- 한개의 테이블에 한개씩만 만들 수 있다.
MySQL에서는 기본키가 있다면 기본키를 클러스터 인덱스로, 기본키가 없을시엔 unique not null 옵션의 컬럼을 클러스터 인덱스로 지정한다. - 본래 인덱스는 생성 시 데이터들의 배열정보를 따로 저장하는 공간을 사용하나, 클러스터 인덱스는 따로 저장하는 정보공간을 적게 사용하면서 테이블 공간 자체를 활용한다.
인덱스 자체의 리프페이지가 곧 데이터이기에 인덱스 자체에 데이터가 포함되어있다고 볼 수 있다. - 보조인덱스 보다 검색속도는 빠르나 입력,수정,삭제는 더 느리다.
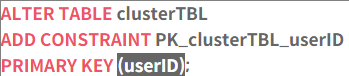
- 클러스터형 인덱스는 ALTER TABLE문을 이용하여 생성할 수 있다.
보조 인덱스(Secondary Index)
- 논 클러스터 인덱스(non-clusterd index)라고도 불린다.
- 개념적으로 후보키에만 부여할 수 있는 인덱스이다.
- 보조 인덱스는 생성시에 기존 데이터 페이지는 유지한채 별도의 페이지에 인덱스를 구성한다. 별도의 페이지에서 인덱스를 구성하기에, 클러스터와는 달리 자동정령을 하지 않는다.
- 보조인덱스는 여러개 생성할 수 있다. 다만 무분별한 보조 인덱스 생성은 데이터베이스 성능을 떨어뜨릴 수 있다.
- 클러스터 인덱스에 비해 입력,수정,삭제는 빠르나 검색속도는 느리다.
- 각 데이터에 대해서 고유값(unique)들이 있는 목록에 생성 할 수 있는 인덱스
- 보조 인덱스는 CREATE문을 이용하여 생성할 수 있다.

MongoDB기준
- 도큐먼트를 만들면 자동적으로 ObjectID가 형성되며 해당키가 기본키로 설정된다.
기본인덱스라고 한다. - 기본적으로 인덱스 생성시 createindex() 메서드를 사용한다.

- 세컨더리 키도 부가적으로 설정해서 기본키와 세컨더리키를 같이쓰는 복합 인덱스를 설정할 수있다.

인덱스 최적화 기법
데이터 베이스마다 조금씩 다르지만 기본골조는 똑같다.
인덱스는 비용
- 인덱스는 두번 탐색하도록 강요한다.
- 인덱스 리스트, 그 다음 컬렉션 순으로 탐색되기때문에 관련해서 비용이 들어간다.
- 컬렉션 수정시 인덱스도 수정되어야한다.
이때 B-트리기준 높이를 균형있게 조절하는 비용이나, 데이터를 조회시 분산시키는 비용도들어간다 - 무작정 쿼리에있는 필드에 인덱스를 설정하는것은 답이 아니다
- 컬렉션에서 가져와야 하는 양이 많을수록 인덱스 사용은 비효율적이다.
항상 테스트
- 인덱스 최적화 기법은 서비스 특징에 따라 다르다.
서비스에서 사용하는 객체의 깊이, 테이블의 양들이 다르기때문이다. - 그렇기에 항상 테스트 하는 것이 중요하다.
- MySQL 상에서는 EXPLAIN을 사용하여 테스트한다.

복합인덱스는 같음, 정렬 ,다중값, 카디널리티 순으로
- 여러필드를 기반으로 조회시 복합 인덱스를 생성하는데, 이때 생성시에는 순서가 있고 생성 순서에 따라 인덱스 성능이 달라진다.
- 같음을 비교하는 ==이나 equal이라는 쿼리가 있으면 제일 먼저 인덱스로 설정한다.
- 정렬에 쓰는 필드라면 그다음 인덱스로 설정한다.
- 다중값을 출력해야 하는필드, 부등호에 의해 많은값을 출력해야하는 쿼리에 쓰는 필드면 나중에 인덱스를 설정한다.
- 유니크한 값의 정도를 카디널리티라고 하며, 이 카디널리티가 높은 순서를 기반하여 인덱스를 생성해야된다. 카디널리티가 높은 순으로 필터링하여 조회하기 때문이다.
ex) CREATE INDEX index_name ON table_name(주민번호, 계좌번호, 학년 , 성별)
- 카디널리티가 낮은순에서 높은순이였을때와 , 높은순에 낮은순으로 생성했을때 성능차이
-> https://jojoldu.tistory.com/243
참고자료
B-tree, B*tree, B+tree(코딩하는 경제학도)
https://www.baeldung.com/cs/b-trees-vs-btrees
MYSQL 인덱스(index)핵심 설계 &사용문법 총정리(Inpa Dev)
몽고디비 인덱스 정리(Inpa Dev)
https://juntcom.tistory.com/104
클러스터/보조인덱스(JIE0025)
이것이 MySQL이다 - 인덱스의 내부작동1(유투브)

백엔드지망생