
지난 포스팅에서 설명한 것과 같이 Byte 단위 입출력 클래스는
InputStream, OutputStream 이라는 추상 클래스를 상속 받는다.
그래서 Byte 단위 입출력 클래스의 이름은 모두
InputStream이나 OutputStream 으로 끝난다.
예를 들어서 파일로부터 1byte 씩 읽고,
파일에 1byte씩 저장하는 프로그램 예시 코드를 보자.
FileInputStream
FileInputStream은 파일로 부터 읽어오기 위한 객체다.
아래와 같이 io 패키지에서 import 하고 선언해야 한다.
package level2;
import java.io.FileInputStream;
public class ByteExam1 {
public static void main(String[] args) {
FileInputStream fis = null;
fis = new FileInputStream("경로");
}
}("") 안에는 어떤 파일에서부터 읽어올 것인지에 대해 적어야 한다.
그러니까 읽어들일 파일이 있는 경로와 파일명을 적어야 한다.
프로젝트가 현재 경로인 것을 기준으로하여 작성한다.
예시는 "src/level2/ByteExam1.java" 와 같다.
그런데 해당 경로에 파일이 없을 경우 발생하는 Exception에 대해
아래와 같이 예외처리를 해주어야 한다.
package level2;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class ByteExam1 {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
try {
fis = new FileInputStream("src/level2/ByteExam1.java");
} catch (Exception e){
e.printStackTrace();
}
}FileOutputStream
FileOutputStream은 파일에 쓸 수 있게 해주는 객체다.
import와 선언, 예외처리는 FileInputStream 과 동일한 방식으로 한다.
다만 new FileOutputStream(""); 의 ("")안에는
생성될 파일의 경로와 이름을 적는데,
아무런 경로를 입력하지 않으면 프로젝트 밑의 위치에 생성된다.
package level2;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class ByteExam1 {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("src/level2/ByteExam1.java");
fos = new FileOutputStream("byte.text");
} catch (Exception e){
e.printStackTrace();
}
}read(), write() 메소드
먼저, FileInputStream의 read() 메소드는 이름처럼 읽는 역할을 한다.
그리고 정수 4바이트 중 마지막 바이트에 읽어들인 한 바이트를 저장한다.
바이트를 리턴한다면 끝을 나타내는 값을 표현할 수 없기 때문에 int값을 리턴한다.
음수의 경우 맨 왼쪽 비트가 1이 되며, 읽어들일 것이 있다면 항상 양수를, 없다면 -1을 리턴한다.
그리고 FileOutputStream의 write() 메소드는 이름처럼 쓰기 역할을 한다.
이들을 활용해서 아래와 같이 반복문으로 데이터를 끝까지 읽어낼 수 있다.
package level2;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
public class ByteExam1 {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("src/level2/ByteExam1.java");
fos = new FileOutputStream("byte.text");
int readCount = -1;
while((readCount = fis.read()) != 1){
fos.write(readCount);
}
} catch (Exception e){
e.printStackTrace();
}
}close() 메소드
그리고 IO의 모든 객체들은 인스턴스화를 하고 나면 반드시 닫아줘야하기에
finally 블록을 열고, close() 메소드를 사용한다.
close 메소드는 InputStream, OutputStream 모두 존재한다.
그리고 close() 메소드도 Exception을 발생시켜 예외 처리를 해야 한다.
package level2;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
public class ByteExam1 {
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
FileOutputStream fos = null;
try {
fis = new FileInputStream("src/level2/ByteExam1.java");
fos = new FileOutputStream("byte.text");
int readCount = -1;
while((readCount = fis.read())!= -1){
fos.write(readCount);
}
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}finally{
try {
fos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
try {
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
그리고 나서 프로그램 실행 후, 프로젝트 경로에서 새로고침을 하면
내가 읽고자 했던 파일이, 내가 지정한 경로에 지정한 이름으로 생성된 것을 알 수 있다.
512 byte씩 읽기
그동안 1바이트씩 읽었다면, 이번에는 512byte씩 읽는 코드를 작성한다.
아래 코드는 이전 예시에서 일부만 수정한 것이다.
byte[] buffer = new byte[512];
while ((readCount = fis.read(buffer)) != -1){
fos.write(buffer,0,readCount);
}while 구문 위에 512byte 배열을 선언하는 코드 한줄을 추가하고,
while 구문 내에서는 512byte로 선언한 buffer 크기만큼을 읽어와서
buffer의 0부터, -1까지를 쓰는 코드를 작성했다.
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
.
.
.
long endTime = System.currentTimeMillis();
System.out.println(endTime - startTime);
}그리고 아래와 같이 long 타입의 System.currentTimeMillis() 메소드를 사용해서
메인 메소드 첫줄에 시작 시간을 알 수 있는 변수를 만들고,
메인 메소드 끝에는 끝나는 시각을 알 수 있는 변수를 만들어
끝난 시간에서 시작 시간을 빼면 프로그램 작동시간을 알 수 있도록 해보았다.
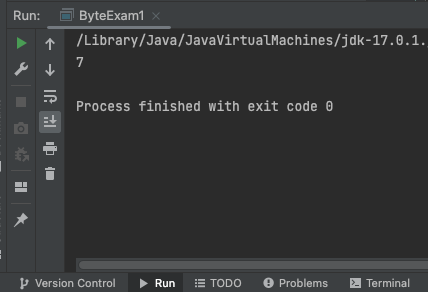
그 결과, 1byte씩 읽은 ByteExam1은 수행시간이 7/1000초로 나왔고
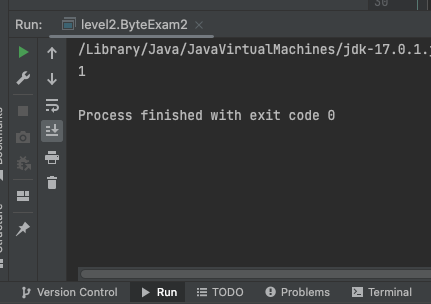
512byte씩 읽은 ByteExam2는 수행시간이 1/1000초로 확인됐다.
🤔 왜 이렇게나 큰 속도 차이가 나는 걸까?
운영체제(OS)는 1byte씩 읽어오라는 명령을 받아도 512byte씩 읽어온다.
그러니까, 1byte를 두번 읽어오라고 하면
512byte를 가져와서 1byte만 읽은 다음에 511byte는 버린다.
그리고 또 512byte를 가져와서 1byte만 읽은 다음에 511byte는 버린다.
어차피 OS에서 512 byte씩 가져오기때문에 우리가 명령을 할 때에도
512byte의 배수로 배열 크기를 잡아주는 것이 성능상 좋다.
