네트워크 레이어의 TCP/IP protocol은 host-to-host datagram delivery에 적합하다.
18.1 Network-Layer Sevices
Network layer의 가장 큰 역할로는 source host와 destination host간의 connecting devices(Router, switches)를 이용하여 통신하는 것이다. Internet은 LANs, WANs의 조합이라고 보면 된다. 이는 Connecting devices를 통해 서로 연결되어 있다.
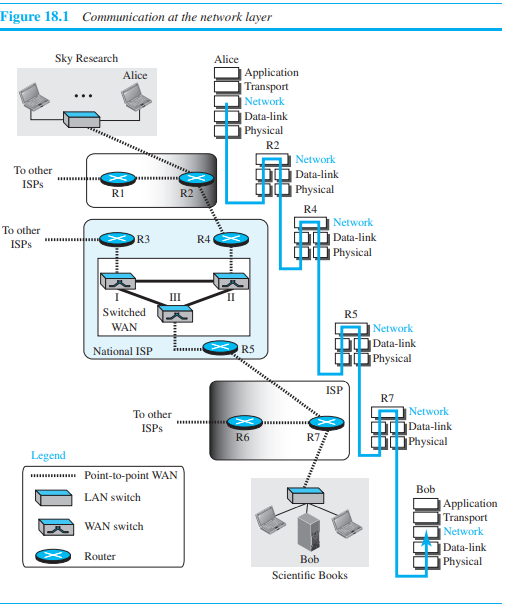
위의 그림에서 보듯이, 네트워크 계층은 source host와 destination host, path가운데 routers들을 포함한다. Source host(Alice)는 transport layer로 부터 패킷을 받은 후에, 하여 패킷을 datagram에 encapsulte하여 data-link 계층으로 전달한다. Destination host(Bob)은, datagram을 decapsulate하여서, 패킷을 추출하고 transport layer에게 전달한다. Router는 패킷을 하나의 네트워크에서 받아 다른 네트워크로 전달하는 역할을 한다.
18.1.1 Packetizing
Network layer의 제1의 역할은 packetizing이다. 즉, Encapsulating을 통해 패킷을 만들고 목적지에서 decapsulating을 통해 패킷을 다시 추출한다. 즉, payload(data received from upper layer)을 source에서 destination으로 변조/사용 없이 전달하는 것이다. 마치 우체부처럼 패키지 내용물의 변화/사용 없이 sender에서 recevier에게 전달하는, carrier의 역할을 하는 것이다.
-
Source host는 payload를 상위 계층으로부터 받아서, 헤더파일을 추가한다. 헤더파일에는 source와 destination의 주소와, 네트워크 계층서 필요한 정보들을 포함한다. 이후, 패킷을 data-link 계층에 전달한다
-
Destination host는 네트워크 계층 패킷을 data-link 계층에서 받아서, decapuslate를 하여 패킷을 뽑아내고, payload를 해당되는 상위 계층에 전달한다
-
Router는 중간에 패킷을 decapsulate 할 수 없으며, source와 destination의 주소를 변경할 수도 없다. 하지만, 만약 패킷이 쪼개진다면, 헤더를 복하하며, changes가 필요하다.
18.1.2. Routing and Forwarding
Network layer의 다른 역할로는, rounting과 forwarding이 있다.
Routing
네트워크 계층은 source에서 destination까지 패킷을 전달하는데 책임이 있다. Physical layer는 networks(LANs, WANs)와 router들의 조합으로 되어있다. 이로 인하여 souce에서 destination까지 갈 수 있는 route가 다양하며, network layer는 최적의 route를 찾아야 한다. Internet의 경우 routing protocol을 사용한다고 함. 이 방법서는 특히 tables(표)를 사용하여 찾는 경우가 많다.
Forwarding
Routing이 각 router들의 decision-making을 위한 표를 만들기 위해서 전략을 적용하고 routing protocols의 실행을 하는 것이라면, forwarding은 라우터에 패킷이 도달하면 취할 action을 말한다. router의 decision-making을 위한 표를 forwarding table혹은 routing table이라 부른다. 라우터가 패킷을 수신하면, 다른 네트워크로 forward(전달)해야 한다. 이 때, packet header에 들어있는 정보를 사용하여 destination-address를 파악한다.

18.2 Packet switching
실제로 라우터는 input port와 output port를 연결해준다. Packet Switching은 packet을 전달한다는 의미로서, 크게 circuit switching과 packet swtiching 방법으로 나뉜다. circuit switching은 주로 physical layer에서 사용. 이 챕터서는 packet switching에 초점을 두어 설명한다.
네트워크 계층에서, 상위 계층으로부터의 메시지들은 관리가능한 여러개의 패킷들로 쪼개지고, 각 패킷은 네트워크를 통해 전송된다. Source에서는 패킷이 한개씩 전송되며, destination은 한개씩 패킷을 수신한다. Destination은 같은 메시지 소속의 패킷 모두 수신하기 전까지, 상위 계층에 전달하지 않는다. 오늘날, packet-switched network는 packet을 route하는데 2가지의 전략을 사용할 수 있다.
18.2.1 Datagram Approach : Connectionless Service
초기 인터넷에서는, 네트워크 계층은 connectionless(연결 설정 및 해제 필요x)한 service 제공을 위해 설계되었다. 네트워크 계층의 프로토콜들은 각각의 패킷을 서로 연관이 없는 것처럼 독립적으로 다루었다. 이 접근방법서는, 메시지 속의 패킷들은 destination으로 가는 길이 같거나 다를 수 있다.
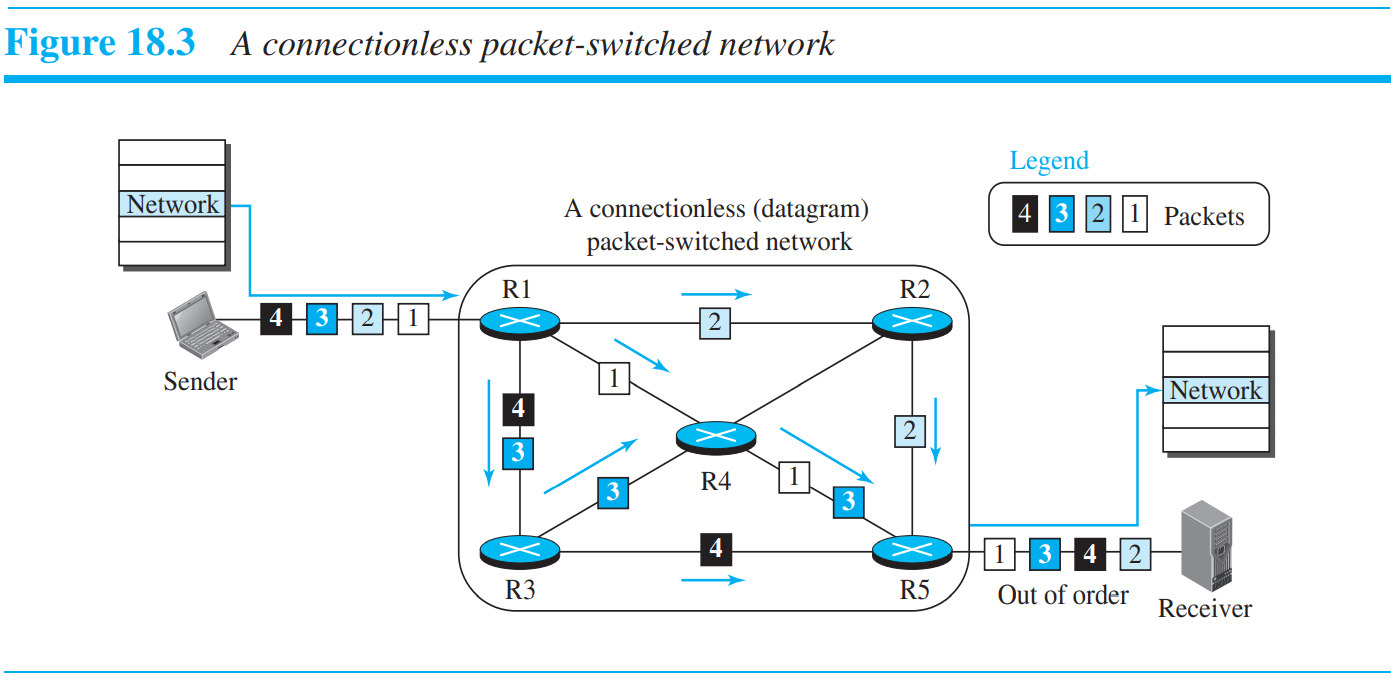
네트워크 계층이 connectionless한 서비스를 제공하면, 각 패킷은 서로 독립적인 객체처럼 인터넷을 떠돈다. 같은 메시지의 패킷들도 관계가 없어 보일 수 있다. 이 때, 이러한 네트워크의 switches를 router라고 부른다. 각각의 패킷은 또한 패킷의 헤더에 포함된 source, destination의 주소를 이용하여 route한다. 라우터는 destination 주소를 확인하여 패킷을 보낸다. source 주소는 error message를 보낼때 사용. 마지막으로 보낼때의 packet 순서와 destination의 recieve 순서는 다를 수 있으며, '대장'이 없는 distributed system이므로 robust하다.

위와 같이 destination address를 살펴본 이후, output interface(port)를 결정하며, 주변 라우터들과 정보교환등의 이유로, 출력이 그때그때마다 다를 수 있다!
18.2.2 Virtual-circuit Approach : Connection-oriented service
Connection-oriented service에서는 한 메시지 안의 패킷들은 서로 연관이 있다. Datagrams이 전송되기 전에, virtual connection이 미리 설정이 되어 path를 지정하고 있어야 한다. connection이 설정되면, datagrams이 같은 path를 따른다. 이러한 서비스를 위해서는 패킷은 source/destination address뿐만 아니라, flow label(virtual circuit identfier-> 패킷이 가야할 virtual path를 알려주는 역할)이 있어야 한다
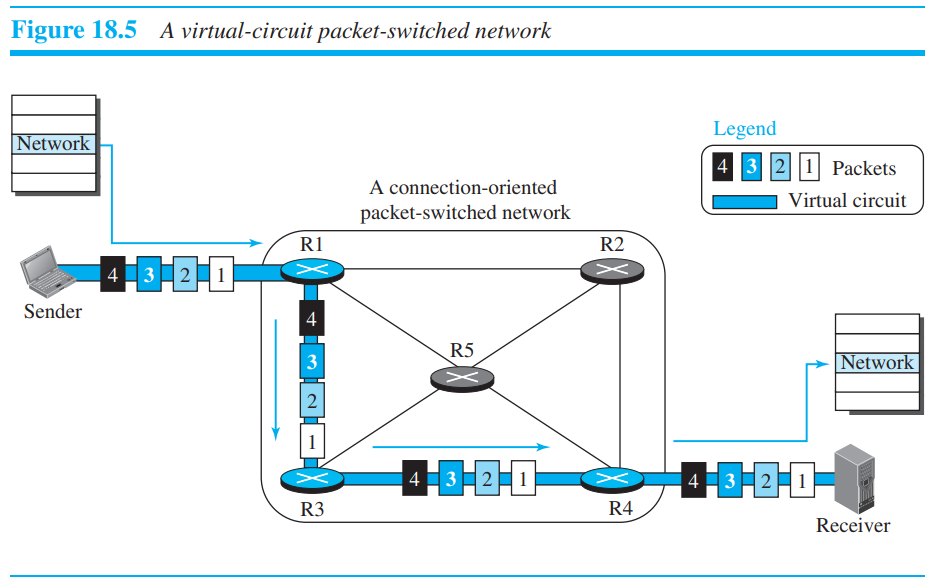
각각의 패킷은 패키속의 라벨에 따라 진행된다. 마치 기차같이 순서대로 정해진 길을 따라 destination으로 전달된다.
Data-Setup 단계
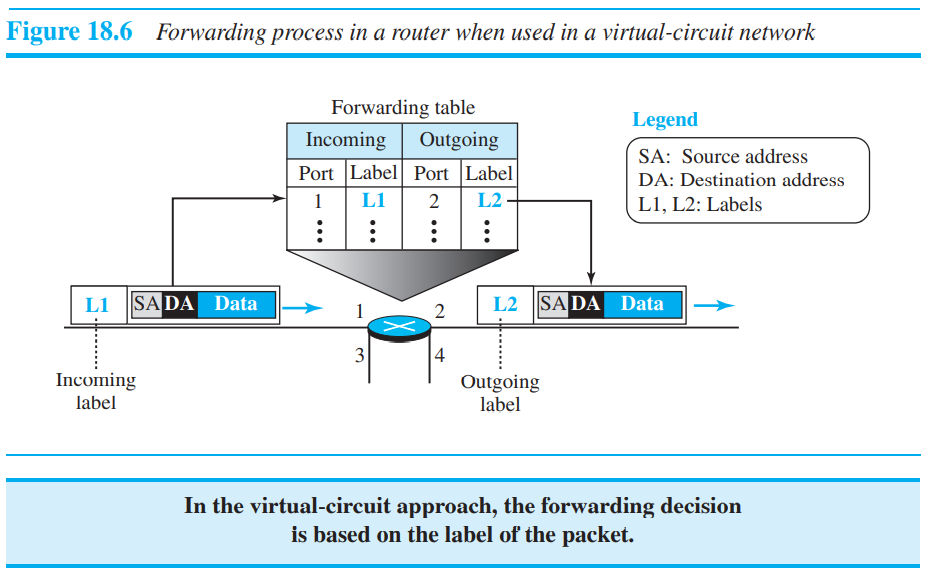
위의 그림처럼 router에서는 Incoming label의 값을 outgoing label로 바꿔준다. Decision-making은 incoming label을 이용하여, 포트번호를 바꾼다. Datagram 방식보다 단순하다고 할 수 있다.(주변 고려x)

1)단계: A에서 R1에게 request packet이 보내진다.
2)단계: R1은 request packet을 받는다. 라우터는 A->B로 가기위에서는 3번포트로 나가야한다는 것을 알고 있다고 가정. 라우터는 virtual circuit의 table을 만드는데, 3가지를 채울 수 있어야 한다. 라우터는 ⑴incomming port를 할당하며, ⑵가능한 incomming label을 선택하며 ⑶outgoing port를 정한다. 그러나 outgoing label을 알수 없으며, port3을 통해 router R3에게 패킷을 전송한다
3)단계: R3는 setup request를 수신하며, 표의 3개의 열을 채워서 R4에게 전달
4)단계: R4 역시 setup 패킷을 수신하여, 3개의 열을 채우고 port4를 통해 B에 전달
5)단계: B가 setup 패킷을 수신하면, A로부터 전송받을 준비가 되었다. label은 packet이 다른 sources가 아닌 A에서 온것을 알려준다.
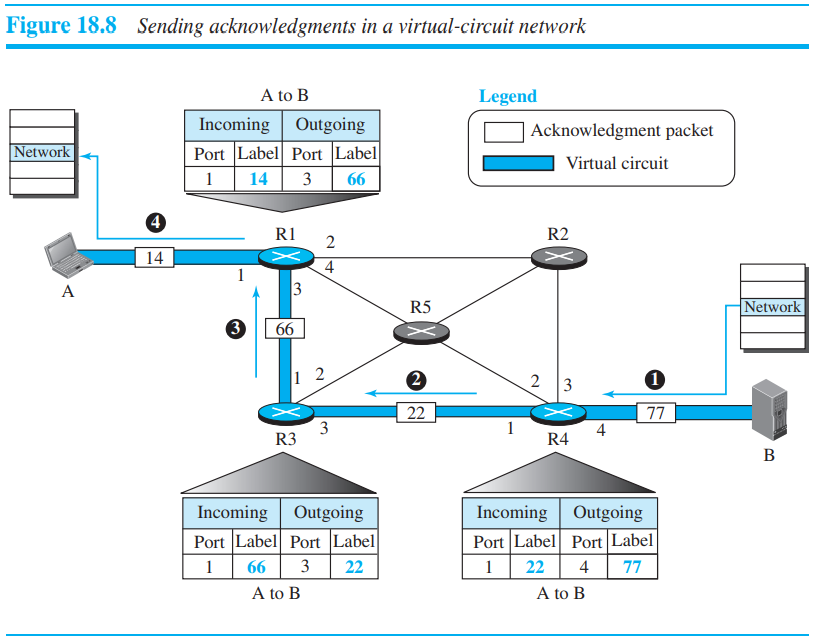
Acknowlegement packet을 통해서 전체적인 표를 완성할 수 있다.
1)단계: Destination이 R4에게 acknowlegement를 보낸다. source/destination 주소를 통해 어떤 router의 table이 채워져야하는지 알 수 있다. 또한 Label 77을 R4에게 전달.
2)단계: R4는 R3에게 ack를 보내며, label 22전달
3)단계: source에게 R1이 ack를 보내며, label값을 전달하며, source가 이를 outgoing label값으로 이용한다.
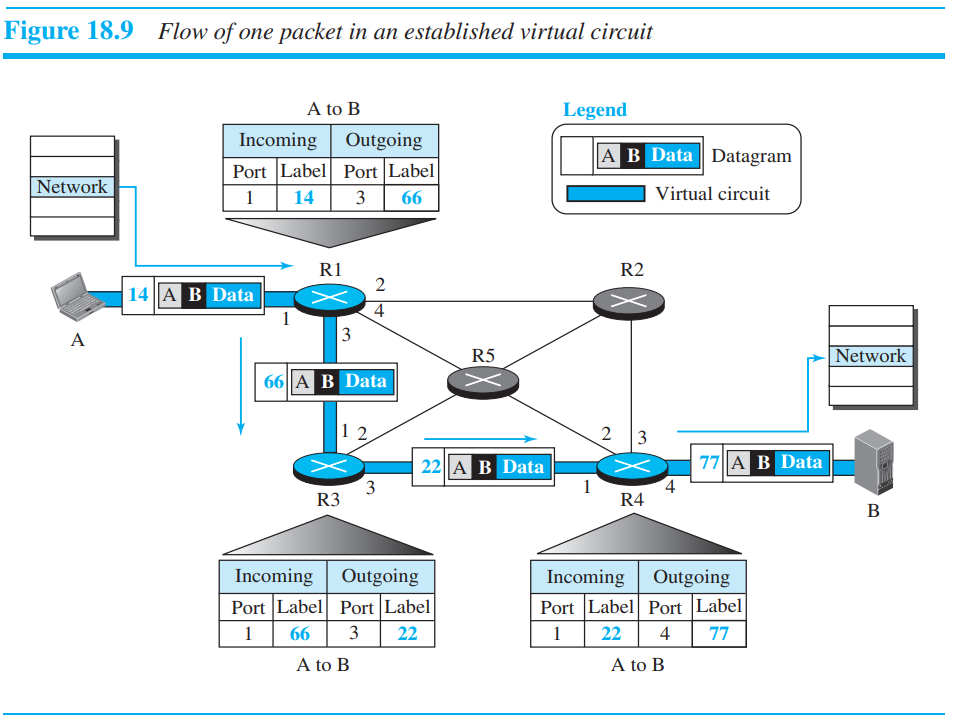
Data-Transfer 단계
모든 라우터들은 forwarding table을 가지고 있으며, 이를 이용하여 같은 메시지의 패킷을 보낼 수 있다. 메시지속 모든 패킷들은 같은 label, order를 가진다
Teardown 단계
모든 패킷을 보낸후, A에서 B에게 teardown packet을 보내게 되며, B는 conformation packet을 답한다. 경로상의 모든 라우터들은 tables을 지운다.
18.3 Network-Layer performance
Network 계층의 성능을 정량적으로 측정하기 위해, delay, throughput, packet loss의 지표를 사용한다. Congestion control 은 성능 개선을 위한 중요한 이슈이다.
18.3.1 Delay
Source에서 Destination까지 도달하는데 delay가 발생한다. Delay는 즉, 소스에서 목적지까지 걸리는 시간이라 생각하면 될 듯. Total delay = (n + 1) (Delaytr + Delaypg + Delaypr) + (n) (Delayqu)
Transmition Delay
기술적으로 존재하는 전송 속도 제한에 의해 발생하는 지연이다. Delay(tr) = (Packet length) / (Transmission rate). Sender가 송신을 빠르게 하면, delay가 짧아진다.
Propagation Delay
Source에서 media까지 걸리는데 전송 매체에 의해 발생하는 지연을 말한다. Propagation에 걸리는 시간에 의해 발생하는 지연으로, 매체의 전송속도에 의존적이다. Delay(pg) = (Distance) / (Propagation speed). 예를 들어 진공상태서 propagation의 속도는 매우 빨라서, delay가 줄어들 것이다
Processing Delay
host가 패킷을 받아서, 헤더를 제거하고, 에러 검출을 하고, 패킷을 output 포트에 전달하고, 패킷을 상위 계층에 전달하는 과정들에서 발생하는 지연이다. 패킷마다 값이 다를 것이며, 평균으로 계산한다. Delay(pr) = Time required to process a packet in a router or a destination host
Queing Delay
라우터에서 흔히 발생하는 지연으로, 패킷이 input/output 포트에서 대기하며 발생하는 지연이다. Delay(qu) = The time a packet waits in input and output queues in a router
18.3.2 Throughput
간단히 말해, "줄이 얼만큼의 속도를 지원가능한가?"에 관한 개념이다.
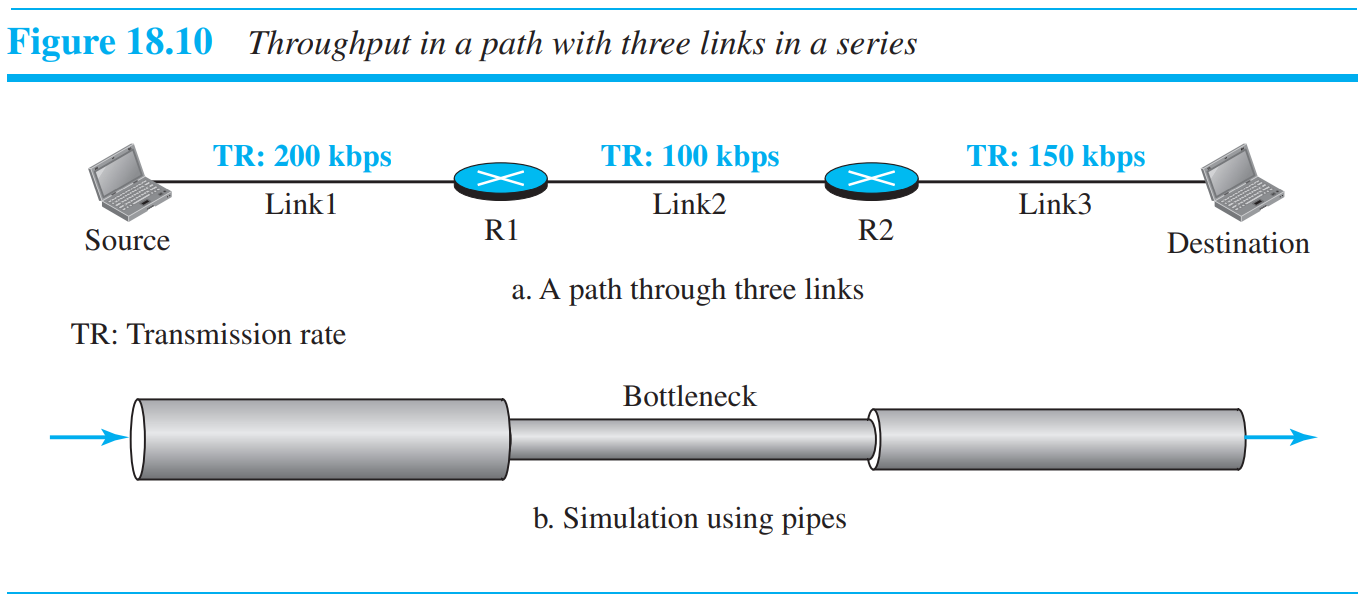
Throughput의 정의로는, 어느 점에서 데이터의 transmission rate를 나타낸다. 패킷은 속도가 다른 네트워크를 지나갈 것이다. 위의 경우에서는, Link2의 속도가 가장 느리므로, Link2의 속도를 throughput이라 할 수 있다. 보통 n개의 links들의 연속에서, Throughput = minimum {TR1, TR2, . . . TRn}.로 정의할 수 있다.
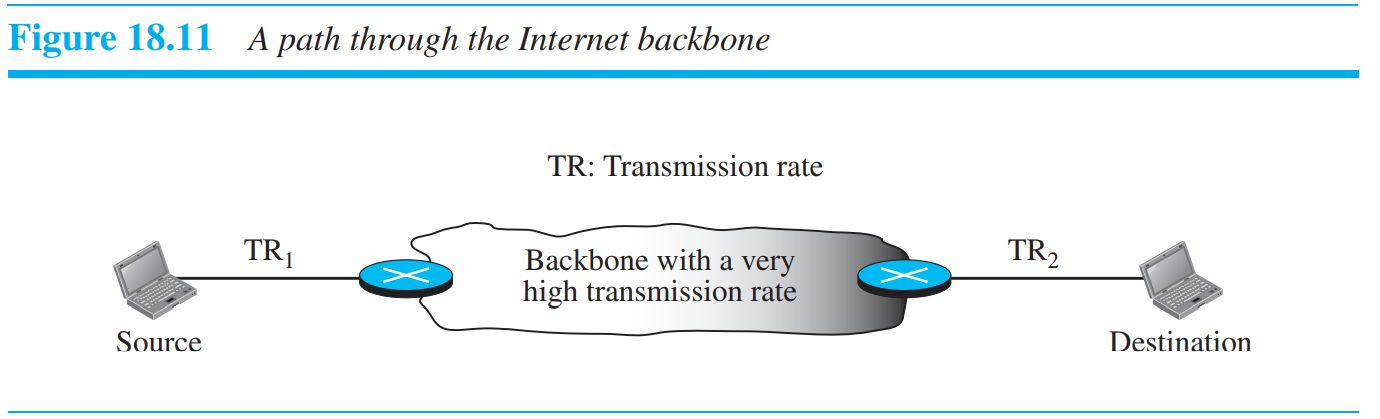
인터넷에서는 위의 경우처럼, 일반적으로 2개의 네트워크와 사이를 잇는 Internet Backbone으로 연결되어 있다. Internet backbone은 대게 빠르므로, 일반적으로 throughput은 Backbone 양끝에 붙어있는 네트워크의 속도에 의해 결정되는 경우가 많다.
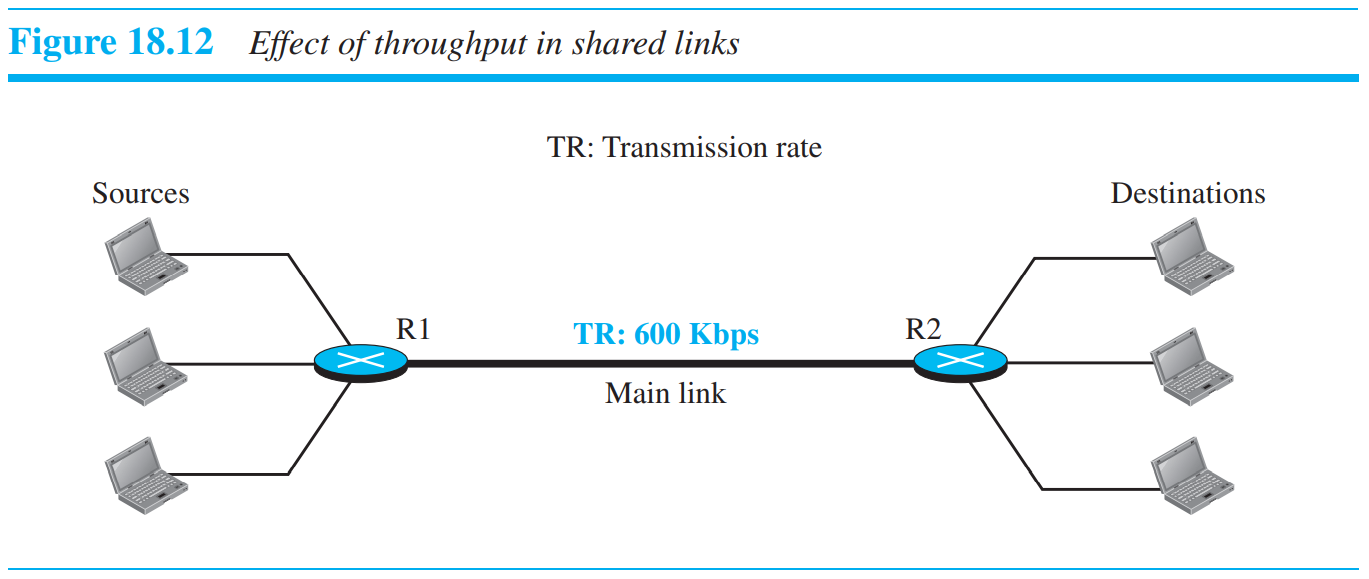
router에 sources이 여러개가 있는 경우도 존재한다. 위의 경우 2개의 라우터 사이의 transmission rate은 600/3 = 200kbps가 될 것이다. 이처럼 공유하는 경우, 그만큼 전송 속도가 감소할 것이다.
Throughput의 또다른 정의로는, '밀어넣었는데 얼만큼 버려지는가?'도 존재한다. 만약 100을 넣었는데, 30만 나오면 0.3이 된다. 주로 소숫점이 나오며, 1이 나오는 경우는 들어간만큼 나온다는 것이다.
18.3.3 Packet Loss
Communication performance의 또다른 issue로는 전송과정중에 상실되는 패킷의 갯수이다. 라우터가 패킷을 수신하면, 일단 input buffer에 저장하며, 처리되기를 기다린다. 하지만 input buffer는 제한된 크기를 가진다. 이렇게 계속 쌓이다 보면, 언젠가는 버퍼가 가득 찰 것이고, 버려지는 패킷이 발생할 것이다. 패킷이 소실되면, 다시 재전송 되어야하고, 이는 시스템에 부담을 주어 더 많은 packet loss를 야기할 것이다. 이를 방지하기 위해서 Congestion control을 사용하여 buffer overflow를 해결.
18.3.4 Congetstion Control
Congestion(혼잡)은 네트워크 계층에선, throughput과 delay와 연관되어 있다. Buffer를 제거하는 역할을 한다. Delay는 buffer와 연관되어 있으며, load량이 capacity보다 많을때 delay는 infinite해진다. 또한 이는 더 많은 loss를 야기한다.
2계층도 하는데 3계층서도 하는 이유?
: IP에서 loss의 발생은 피할 수 없으며, Service 신뢰성을 위해서 필수적이다. 2계층에서의 congestion control은 1,2계층의 loss, congestion 방지하는 것이며, 4계층에서의 congetstion control은 3계층 및 그 이하의 에러 검출 및 복구, congestion를 방지하는 것이다
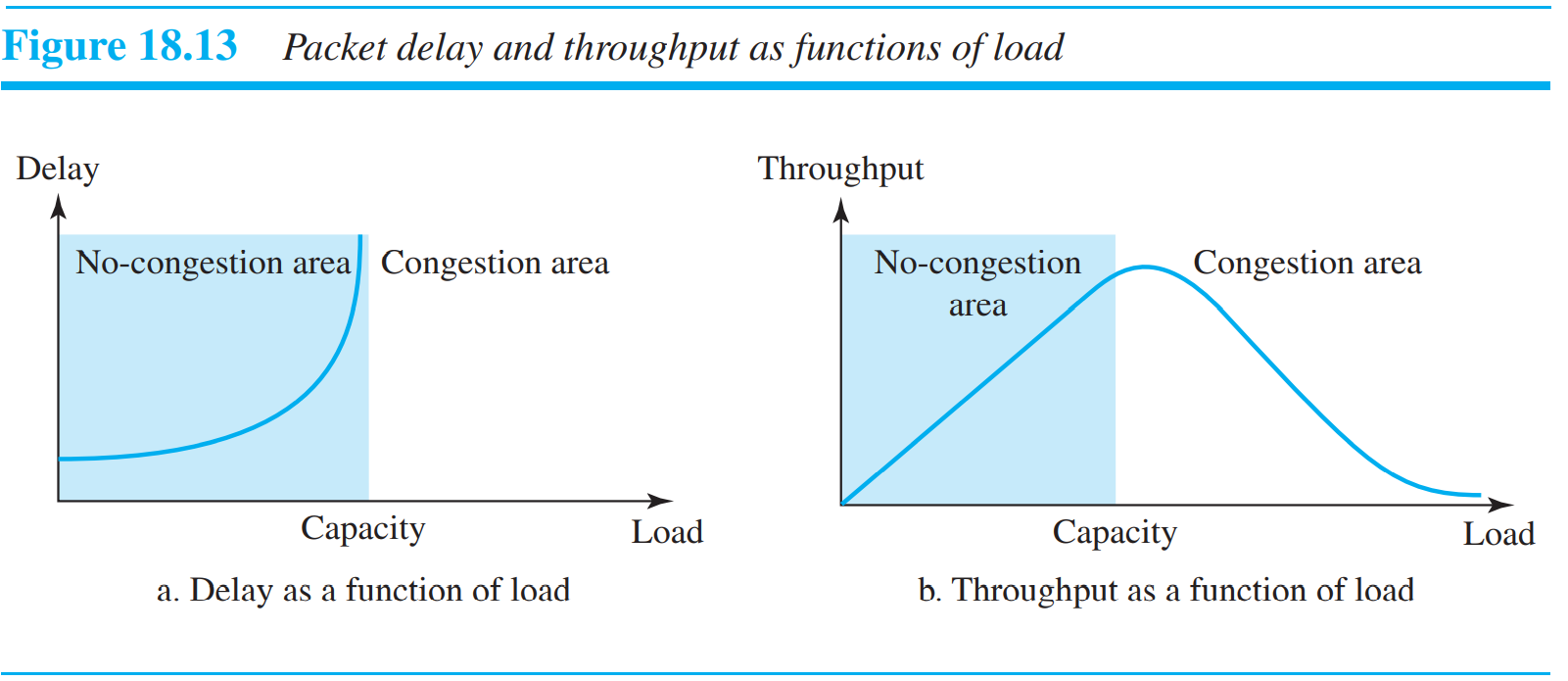
위의 그림처럼 load가 capacity를 초과할 때, buffer가 무한하면 시스템이 과부하된다. 반면에 buffer가 유한적이면, peak이후는 unpredictable하다.
18.4 IPV4 Addresses
IP에서 사용되는 Tcp/IP protocol에서 각 장치들이 인터넷에 연결되는 connection의 identifier를 Internet address 혹은 IP address라 한다. IPV4 주소는 32비트 단위의 주소로, 고유한 주소를 가지며 보편적으로 Internet의 host, router의 연결을 정의한다. IP 주소는 connection(줄)의 주소이지, host나 router의 주소는 아니다. 만약 장치가 다른 네트워크로 이동하면, IP 주소는 바뀌기 때문이다.
IPv4주소는 각 줄의 인터넷과의 연결에서 고유한 주소를 갖는다. 만약 장치가 인터넷과의 2개의 network를 통한 2개의 connections이 있다고 하면, 이것은 2개의 IPv4주소값을 가질 것이다. 인터넷과 연결하기 위해서 가장 보편적으로 사용되는 addressing system이다.
Address Space
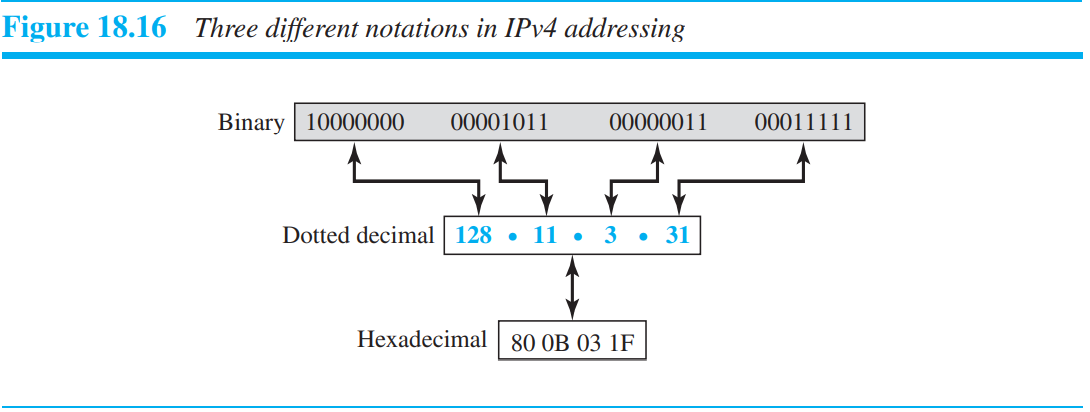
Address space는 프로토콜에 의해 사용되는 주소의 총 갯수를 의미한다. 만약 프로토콜이 b비트를 주소에 사용하면, 2의 b승만큼의 주소 공간을 갖게 된다. IPv4는 32bit 주소를 사용하며, 2의 32승개의 주소값을 가질 수 있다. 4 billion개의 장치들이 인터넷과 연결될 수 있다. IPv4 address를 표현하는 방법은 3가지가 있다. Binary notation, dotted-decimal notation, hexadecimal notation이다.
Hierarchy in Addressing
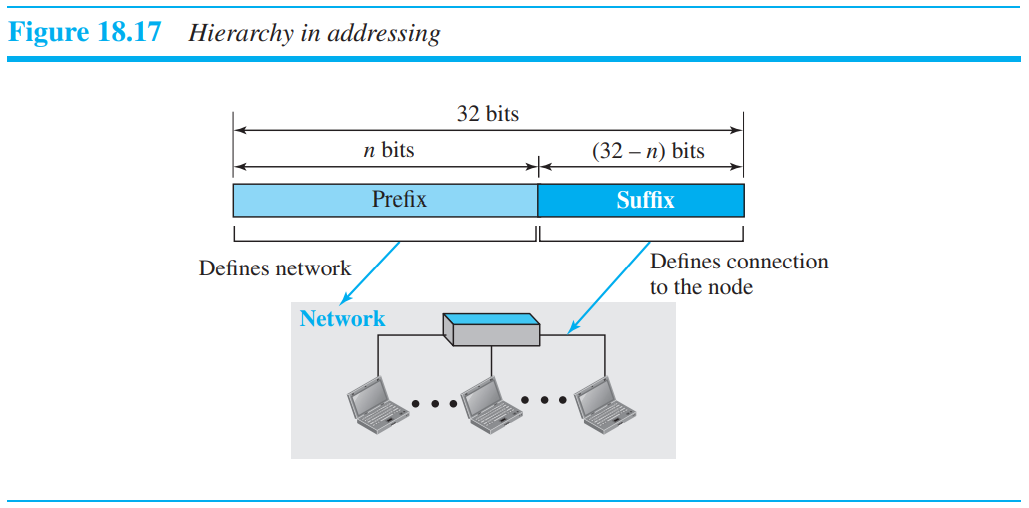 32bit IPv4주소는 계층적이며, 2개의 부분으로 나눠진다. 앞쪽 부분의 prefix라 부르는데, 네트워크를 정의한다. prefix는 주로 네트워크를 할당받은 기관/조직의 주소값을 나타낸다. 뒷부분은 suffix라 하는데, 기관/조직 안에서의 다시 세부적인 주소값을 가진다. 만약 prefix가 n bit이면, suffix는 32-n bit가 된다. prefix의 길이는 고정적이거나 가변적일 수도 있다. 고정적인 prefix길이를 가지는 방법은 classful addressing이라 하며, 가변적인 길이를 가지는 것을 classless addressing라 한다.
32bit IPv4주소는 계층적이며, 2개의 부분으로 나눠진다. 앞쪽 부분의 prefix라 부르는데, 네트워크를 정의한다. prefix는 주로 네트워크를 할당받은 기관/조직의 주소값을 나타낸다. 뒷부분은 suffix라 하는데, 기관/조직 안에서의 다시 세부적인 주소값을 가진다. 만약 prefix가 n bit이면, suffix는 32-n bit가 된다. prefix의 길이는 고정적이거나 가변적일 수도 있다. 고정적인 prefix길이를 가지는 방법은 classful addressing이라 하며, 가변적인 길이를 가지는 것을 classless addressing라 한다.
18.4.2 Classful Addressing
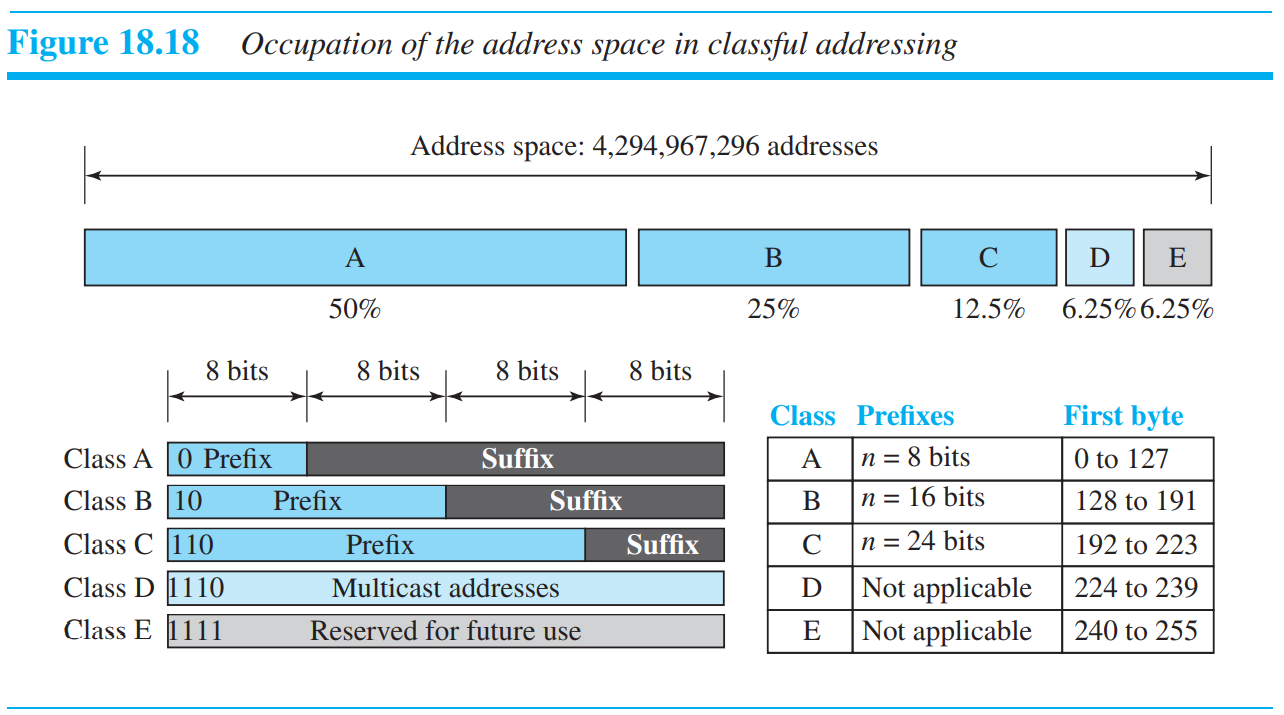
초창기 인터넷이 시작했을때, 크고 작은 규모의 네트워크를 수용하기 위해서, 3가지 크기(n=8,16,24)로 고정된 prefix를 가지는 방향으로 설계가 되었다. 이러한 방법은 classful addressing이라 하며, 요즘에는 잘 사용되지 않느다고 한다. 위의 그림은 prefix 크기별 전체 IPv4를 차지하는 비율을 나타낸 것이다. A의 경우 앞은 8bit를 prefix하면, 뒤의 24bit는 기관 내에서 자유롭게 할당이 가능하였다. 이 방법의 장점으로는 prefix와 suffix를 구분할 때 추가적인 정보가 필요치 않으며, prefix를 바로 찾을 수 있다는 것이다.
18.4.3 Classless Addressing
주소 공간이 점점 커짐에 따라, IP 주소의 길이는 증가하여야 했고, IP 패킷의 포맷이 변화해야 하였다. IPv6가 개발되기도 하였지만, 주로 신흥국들이 사용하고 있고, 기존의 IPv4를 재사용하기 위해(기존 장치를 계속해서 사용하기 위함)서, 같은 주소공간을 사용하지만 각 단체마다 공정하게 주소배분을 하기 위해서 classless addressing이 고안되었다.
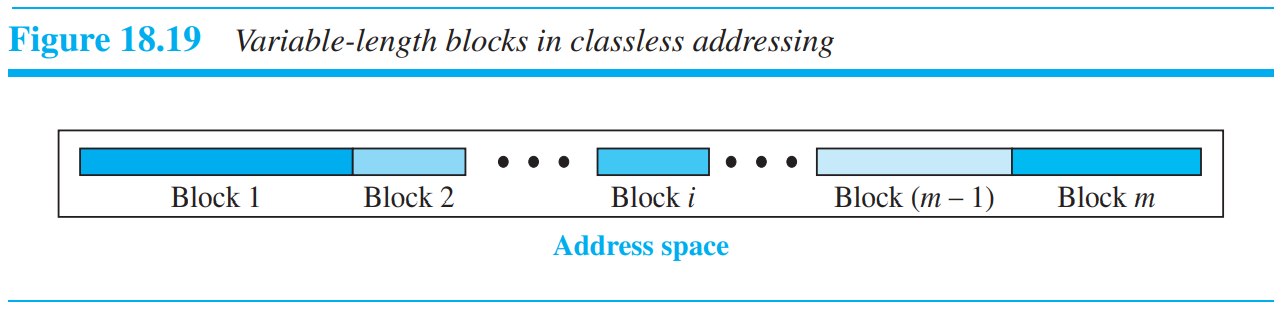
1996년 인터넷 관리단체서 classless addressing이라는 새로운 아키텍쳐를 공표하고, 이것은 가변적인 block길이를 사용하여, 어떤 class에도 속하지 않게 만들었다. prefix의 길이도 가변적이게 되면서,
0부터 32사이의 길이값을 가지게 되었다. 보통 네트워크의 사이즈는 길이에 반비례한다. 큰 네트워크는 작은 prefix를, 작은 네트워크는 긴 prefix를 가진다. classful addressing은 또한 classless addressing에 포함된다.
prefilx Length : Slash Notation

/ 뒤에 숫자를 붙여서, prefix의 길이를 알려주어 router에게 prefix,suffix구분을 위한 정보를 알려준다.

18.4.4 Network address
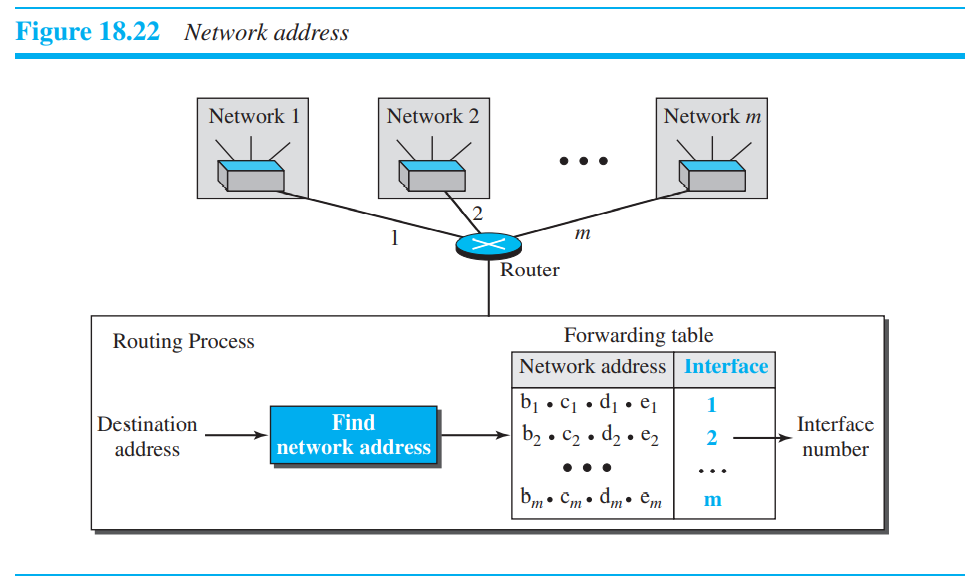
block에는 모든 정보가 담겨있다. 첫번째 주소인, network address는 매우 중요한데, 이는 이것이
destination까지 패킷을 라우팅하기 때문이다. Router가 소스에서 패킷을 받으면, 어떤 네트워크에 패킷을 보내줘야 하는지 알아야 한다. Network address는 각각의 네트워크의 identifier역할을 한다
18.4.5 Network aggregation
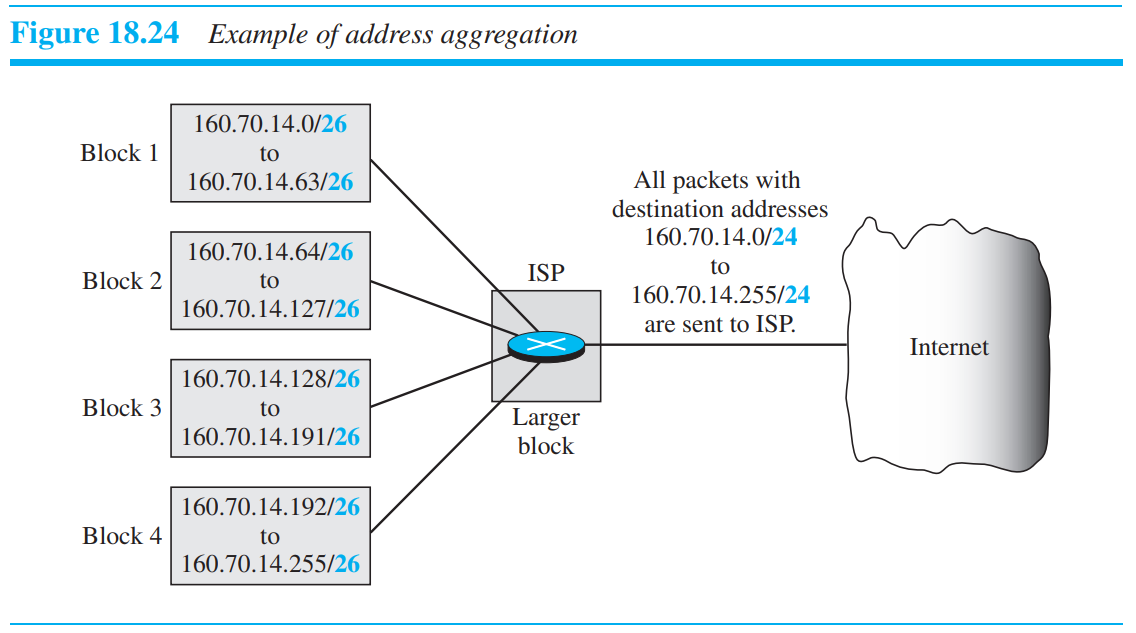
위의 그림처럼 인터넷은 어떤 기관의 주소들을 공통적으로 묶어서 관리할 수 있다. 이를 address aggregation이라 하며, 인터넷은 기관으로 보내기만 하면 되므로 ISP의 prefix만 알고 suffix는 알 필요가 없다. 각 ISP당 large block를 할당받으며, ISP는 이를 다시 subblock로 할당해주어 기관내의 각 부서들에게 주소를 할당해주는 역할을 한다.
18.4.6 Dynamic Host Configuration Protocol(DHCP)
DHCP는 client-server 패러다임을 이용한, 사용자 어플리케이션 단계 프로그램이다. 이것은 자동으로 network관련 정보를 구성한다. 이것을 사용하여 IP address의 부족한 문제를 해결할 수 있는데, 필요시 IP 주소를 할당받고 사용이 끝나면 다시 반납하게 되면, 적은 Ip address를 이용하여 여러개의 host를 사용가능하다. 이것은 우리가 매일매일 사용하는데, 예를들어 카페에서 와이파이 연결등이 있다.
Message Format


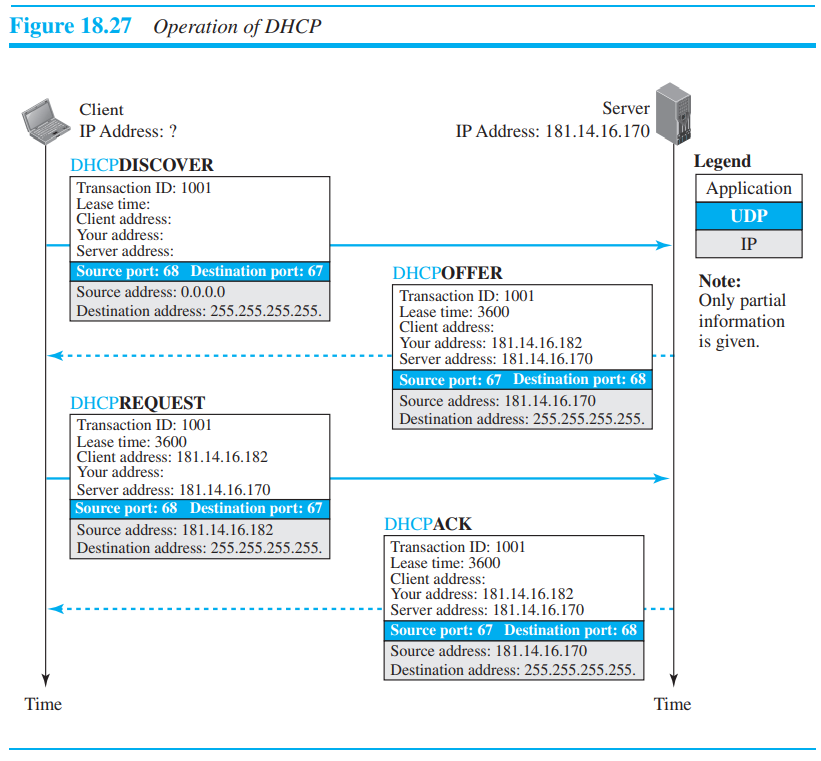
DHCP operation
-
DHCPDiscover : "IP address 줄 서버?". 아이피 주소를 줄 수 있는 서버를 찾는 것이다. Destination은 255.255.255.255(broadcast address)로 광범위하게 전달하는 것이고, Source는 0.0.0.0("this host")로 설정되었다. 소스와 목적지의 주소를 둘 다 모르는 상태이다.
-
DHCPOFFER : "서버가 IP를 호스트에 제공하겠다는 의미". 이 메시지는 서버의 주소를 담고 있으며, 할당해줄 주소와, 할당 최대 허용시간 등의 정보를 담고 있다. 소스 주소는 서버 자신의 주소이며, destination 주소는 여전히 255.255.255.255로 되어있다.
-
DHCPREQUEST : 여러 서버로부터 OFFER를 받으면, 호스트는 가장 좋은 OFFER을 준 서버에게 REQUEST를 보낸다. 소스 주소는 서버가 제공한 IP주소이며, 목적지 주소는 255.255.255.255인데, OFFER한 다른 서버들에게 OFFER를 받아들이지 않았다고 알리기 위함이다
-
DHCPACK : 선택된 서버는 ACK 메시지를 보내어, 제공한 IP가 유효한지 알려준다. 만약 OFFER를 유지 못하면, 서버는 NACK를 보내고 client는 다시 위의 과정을 반복한다. 이 또한 DESTINATION이 광범위한데, 다른 서버들에게 자기가 REQUEST를 받았는지 알리기 위함이다.
18.4.7 Network Address Resolution(NAT)
NAT는 private 네트워크와 universal 네트워크 주소들을 mapping하는 기술로서, 동시에 virtual private network를 지원한다. 이 기술은 private 네트워크들이 서로 내부적으로 통신하는 것과, global Internet address를 통해 외부 세계와 통신하는 것을 지원한다. 내부망은 반드시 NAT 라우터를 통해 global Internet과 연결된 connection이 있는 필요하며, NAT 소프트웨어가 내부망에서 작동한다.
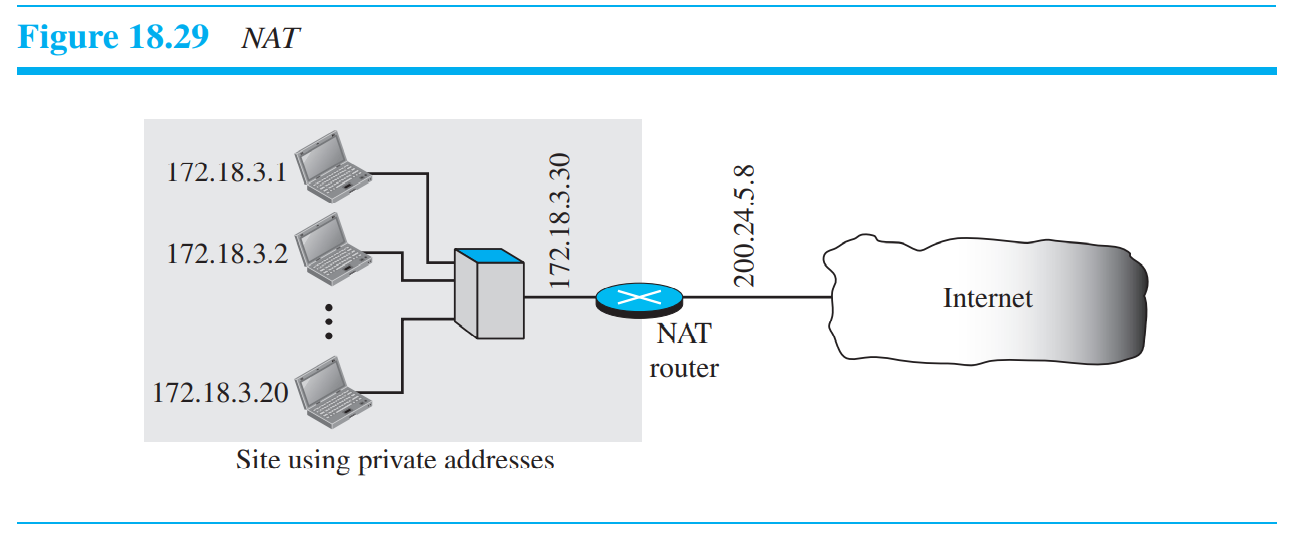
위에서 보듯이 private network는 private 주소들을 사용한다. 보통 172, 192로 시작. 내부와 외부를 연결하는 NAT라우터는 1개의 private 주소와 1개의 global 주소를 사용한다. 인터넷은 내부망의 private 주소들을 볼 수 없다. 오직 연결된 1개의 global주소만 볼 수 있다
Address Translation
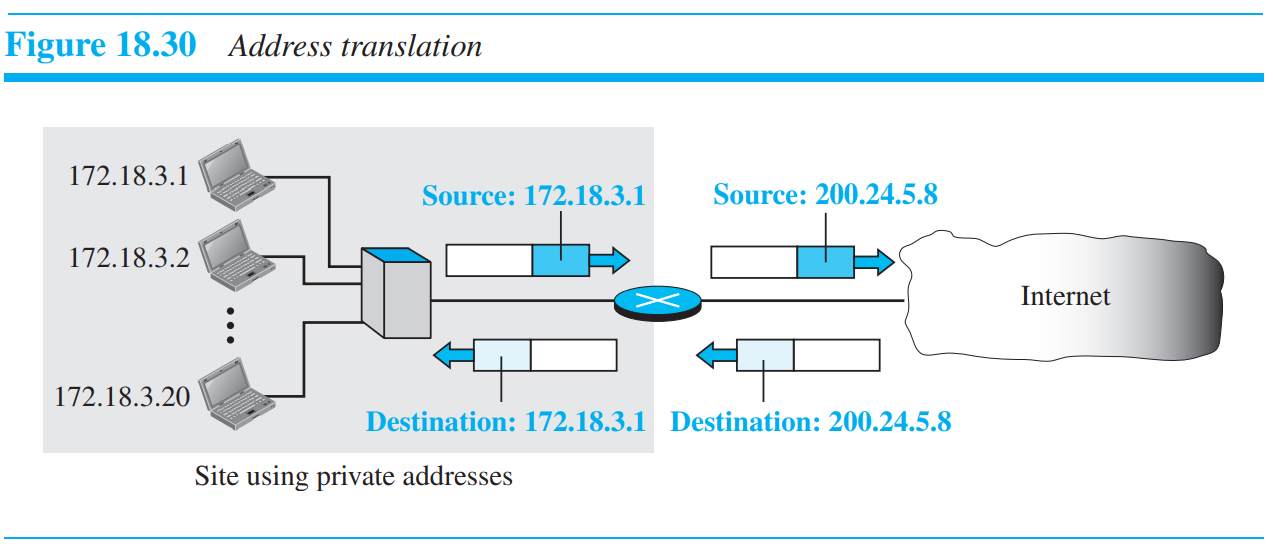
NAT라우터를 통해 나가는 패킷들은, 패킷의 소스 주소로서 NAT 라우터의 global주소를 갖게 된다. 들어오는 패키들은 목적지 주소(NAT global address)를 적절한 private 주소로 바꾼다. 이러한 것을 traslation이라 한다.

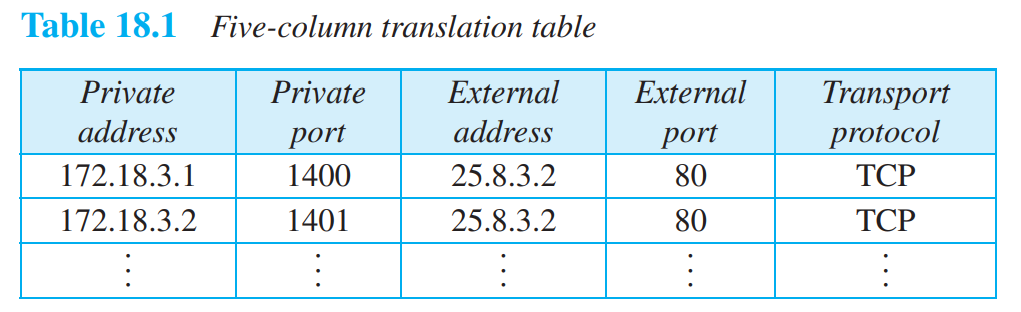
수많은 priavet IP address들을 변환하기 위해서는 translation table을 사용한다. 여러 private 정보가 같은 soruce주소를 가지고 나가기 때문에, 인터넷은 다시 private 주소에게 패킷을 전송하기 어려울 것이므로, traslation table에 있는 수많은 정보를 봐야 구분하여 보낼 수 있을 것이다. 즉 private address간 중첩되지 않는 key들을 사용해야 하며(NAT software), 업체마다 NAT 알고리즘이 있다. destination으로 부터의 response를 어떤 private address를 보내야 할지 결정하기 위해서 사용!
18.5 Forwarding concept of IP packets
Forwarding이란 패킷을 목적지를 향한 경로에 두는 것이다. 인터넷은 여러 네트워크들의 조합이므로, forwarding은 패킷을 다음 장치로 전달하는 것이다. IP 프로토콜은 본래 연결설정이 없는 프로토콜로 설계되었으나, connection-oriented한 프로토콜로 변화하는 중이다. Connectionless의 경우 IP datagram을, connection-oriented는 IP datagram에 label이 붙어진 방식을 사용한다.
18.5.1 Forwarding Based on Destination Address
Address Aggregation
classful addressing에서는 라우터에 패킷이 도달하면, 라우터는 대응값을 찾아 각각 forwarding해준다. 반면에 classless addressing에서는 forwarding table의 크기가 증가한다. 이유로는, classless addressing에서는 forwarding table을 관리가능한 block들로 나누기 때문이다. 표의 크기가 증가한 만큼, 찾는 시간도 오래 걸릴 것이다.
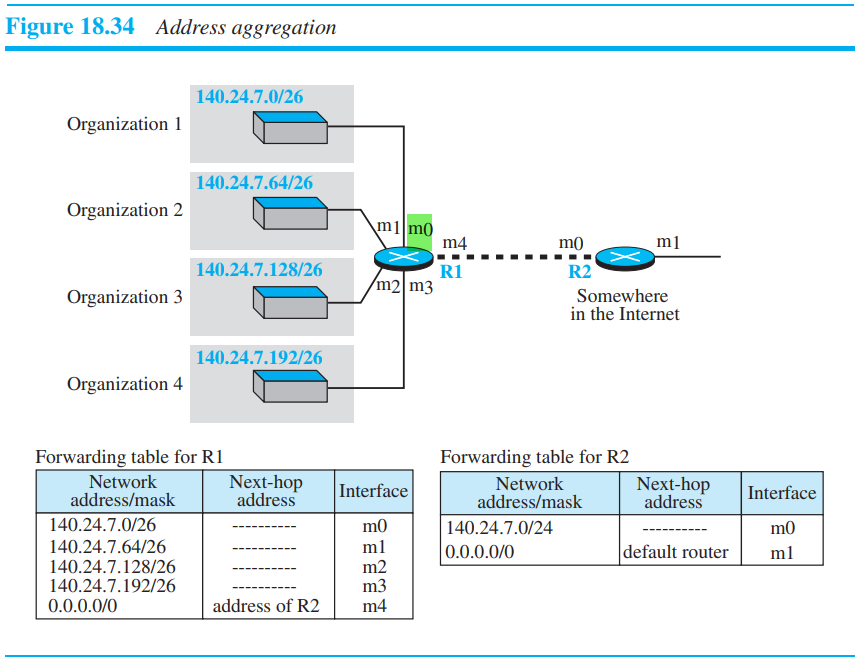
Address aggregation에 의해서 4가지 조직의 주소들이 하나의 큰 블록단위로 관리되므로, R2는 R1보다 작은 forwarding table을 가진다.
Longest Mask Matching
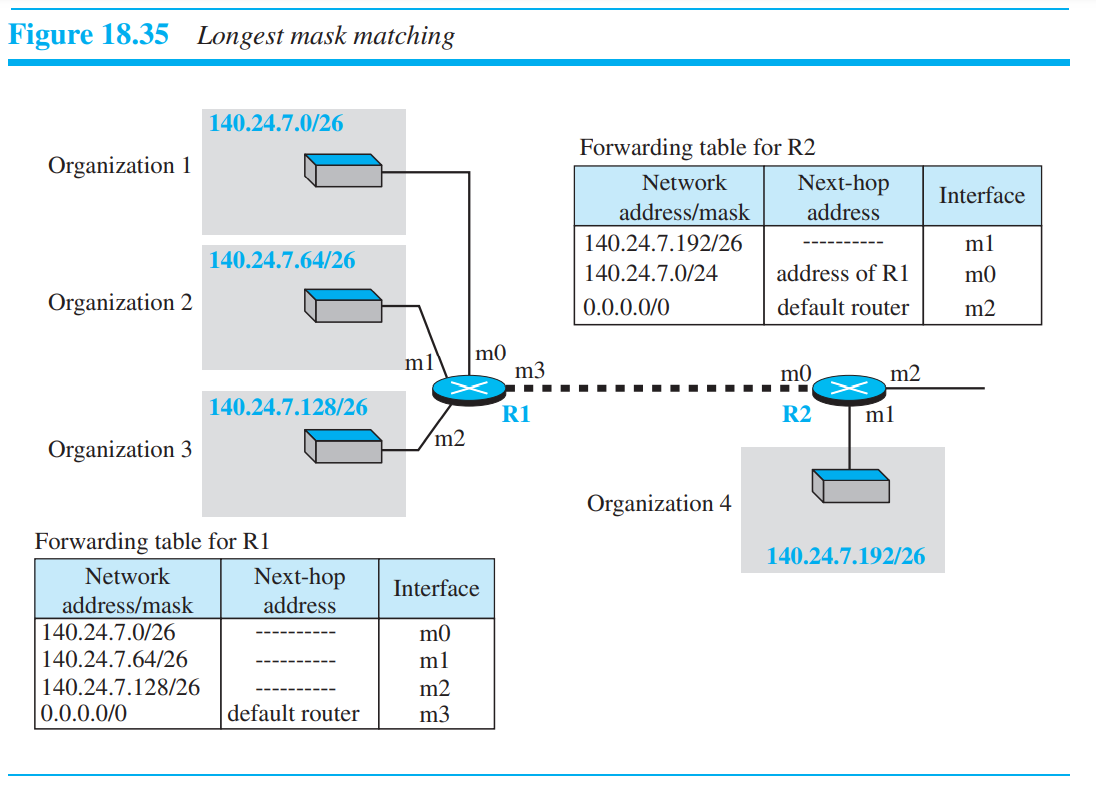
위의 경우처럼 organization4가 R1에서 R2로 옮겨졌다면, longest mask matching에 의해 organization4 block의 주소와 address aggregation은 여전히 사용 가능하다. 만약 R2의 forwarding table에 longest prefix가 먼저 저장되어 있지 않았다면, /24mask를 적용하여 R1으로 잘못 보낼수 있었을 것이다.
Hierarchical routing with ISPs

위의 그림처럼 여러개의 ISP 주소들을 여러 ISP들에게 분배하여, forwarding table 사이즈를 줄이면서 관리할 수 있다.
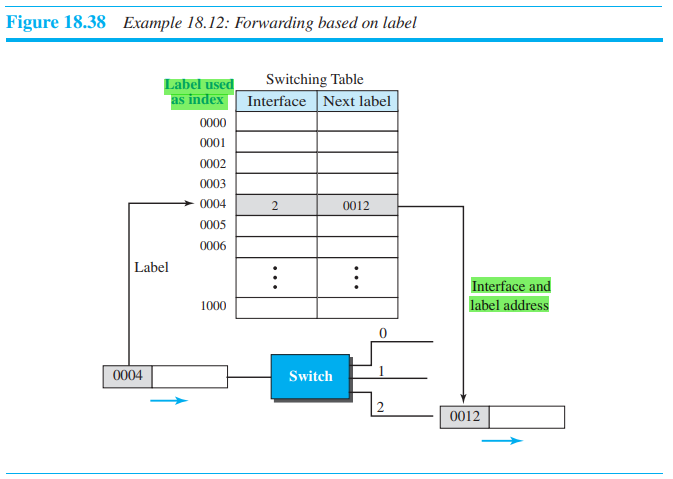
18.5.2 Forwarding based on Label
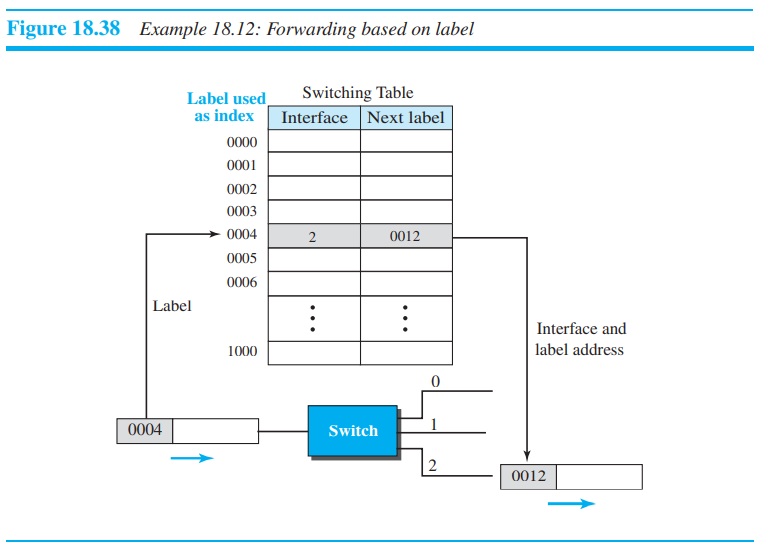
Connection-oriented(virtual circuit) approach에서는 라벨에 따라 패킷을 forwarding하게 된다. 라우팅은 표에서 label값을 index로 사용하여 찾는 방식으로 진행된다. forwarding 알고리즘을 통해 패킷의 목적지 주소값을 알기위해서는, mask를 목적지 주소값에 matching 해줘야 한다. 이후, 라우터는 다음 hop의 주소값과 interface 값을 추출한다.