
MSA 환경에서는 특정 서버가 분리 분해된 다른 우리의 서비스 또는 외부의 서비스와 어떻게 통신할 것인가에 대한 논의는 매우 중요한 논의이자 기본이다.
이번 시간에는 MSA 환경에서 어떻게 통신을 하면 좋을지에 대해 이야기 하는 시간을 가져보도록 하겠다.
외부와의 통신에 대해 크게 로직 처리 순서가 중요한 통신, 로직 처리 순서가 중요하지 않고 처리 효율성이 중요한 통신 2가지로 나눌수 있다. 각 통신의 효용성은 각 비즈니스의 상황에 따라 결정된다.
- 로직 처리 순서가 중요한 통신
* ex) MVC HttpClient, RestTemplate, WebFlux WebClient- 로직 처리 순서가 중요하지 않고 처리 효율성이 중요한 통신
* ex) Message Queueing: Kafka, Rabbit MQ
로직 처리 순서가 중요한 통신
HttpClient (MVC)
- MVC 기반으로 개발 할때 우리가 개발하는 특정 도메인에서 순서가 중요한 비지니스 로직이 있을 수 있다. 이럴때는 순서를 보장해주는 HttpClient를 기반으로 통신을 하여 처리하는게 적합하다.
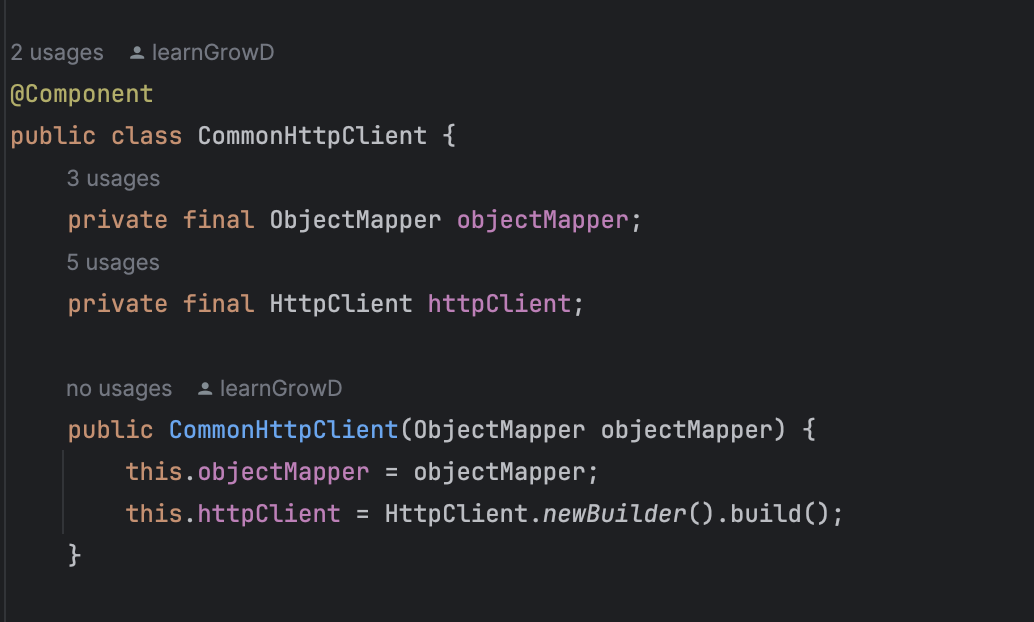
- CommonHttpClient
MSA 환경에서 우리 서비스 및 서버와 통신하기 위한 보조로직을 HttpClient 기반으로 Mapping한 Class다.
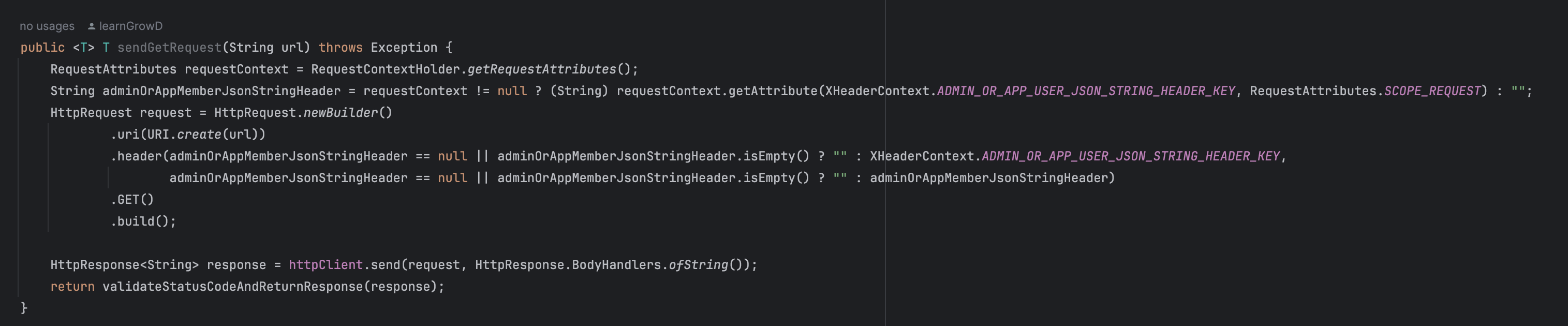
MVC 기반으로 특정 서비스를 개발하고 있다면, 우리 서비스 및 서버와 통신할 때는 CommonHttpClient를 사용한다.주요 기능
1. JWT Context 유지 (with Local Thread)
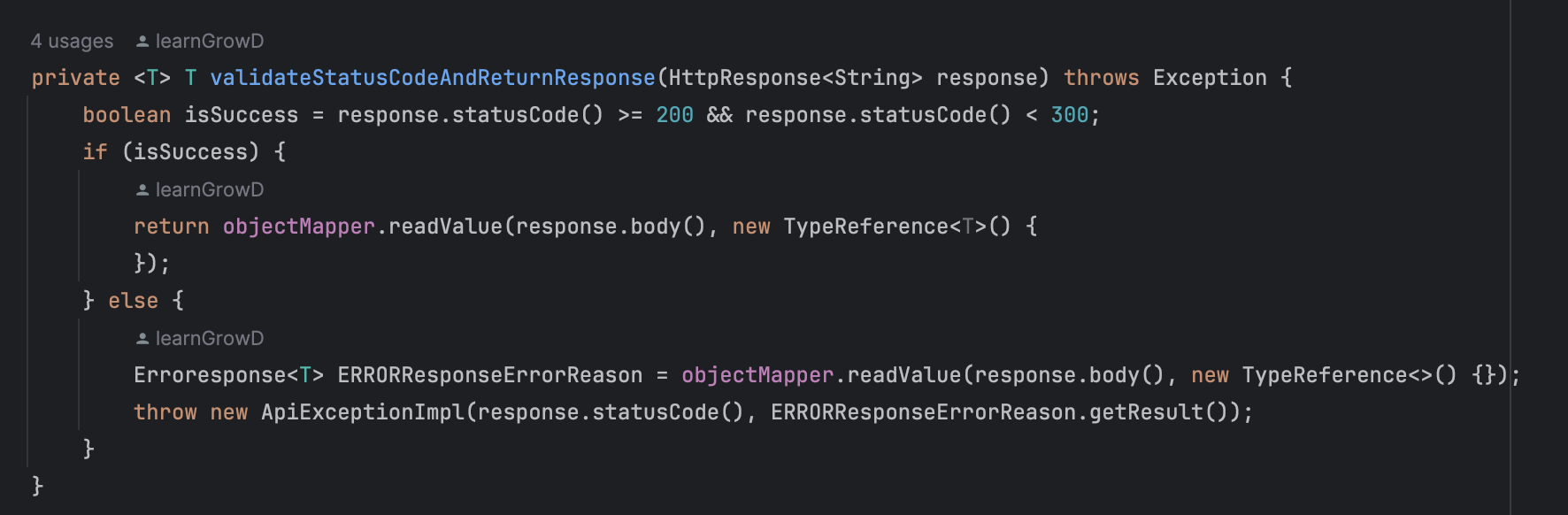
2. Exception Handling
3. 값 변환
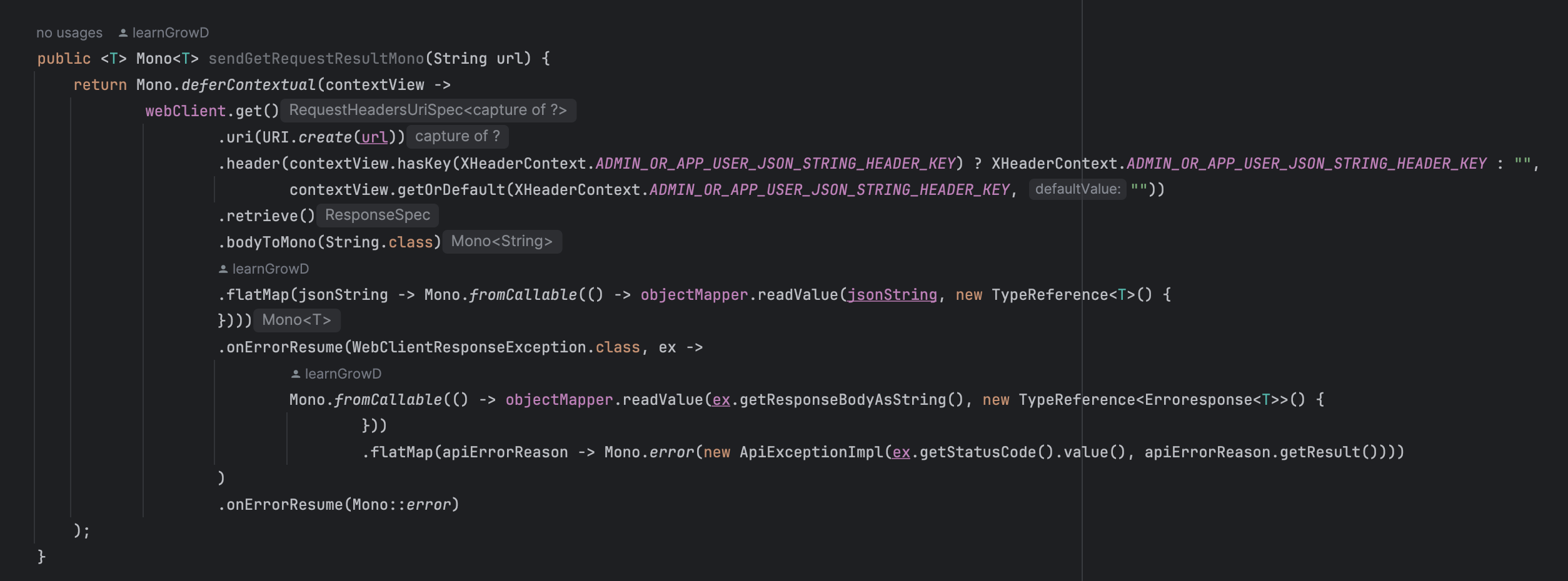
WebClient (WebFlux)
- WebFlux 기반으로 개발을 할때 Async, NonBlocking 기반으로 외부와 통신해야 한다. WebFlux에서 병목 현상은 시스템에 치명적인 성능저하를 유발하기 때문이다. (참고: MSA 심장부를 설계하다: Theme3. MVC, WebFlux 경계) 그래서 WebFlux에서는 Async, NonBlocking Client인 WebClient를 지원하고, 이를 사용한다. WebClient가 Async, NonBlocking Client이긴 하나 이를 사용하는 효용성은 HttpClient를 사용하듯이 특정 비지니스의 순서가 중요한 로직에서 사용하는게 적합하다.
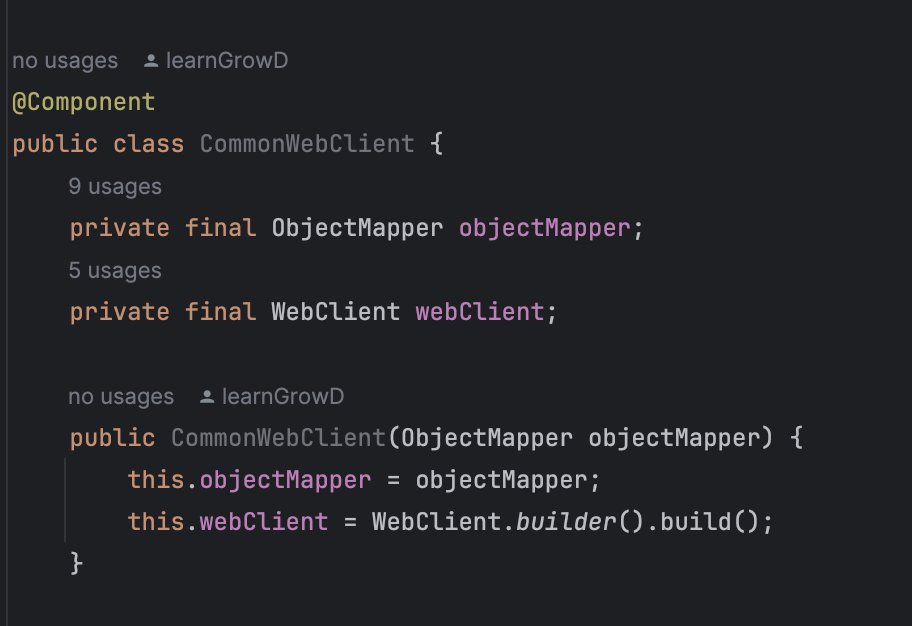
- CommonWebClient
MSA 환경에서 우리 서비스 및 서버와 통신하기 위한 보조로직을 WebClient 기반으로 Mapping한 Class다.
WebFlux 기반으로 특정 서비스를 개발하고 있다면, 우리 서비스 및 서버와 통신할 때는 CommonWebClient를 사용한다.주요 기능
1. JWT Context 유지 (with Reactor Context)
2. Exception Handling
3. 값 변환
로직 처리 순서가 중요하지 않고 처리 효율성이 중요한 통신
Message Queueing (with Kafka)
Message Queueing에 대한 설명은 Kafka를 기반으로 설명하도록 하겠다.
이커머스에서 특정 상품을 주문했을 때 재고에 대한 업데이트가 필요하며, 주문이 정상적으로 성공했을때 사용자에게 알림을 보내야 한다고 가정해보자. 이때 서버에서 로직처리를 할 때 재고가 모두 업데이트 되는 상황에 대해 응답을 받고 알림이 보내졌다는 응답을 모두 확인 한 후 사용자에게 최종 결과를 응답하는 것은 효율적일까? 이러한 방식으로 응답을 내리는것이 틀린 것은 아니지만 더 효율적인 방법이 있을거 같다. 정상적으로 사용자의 주문 요청이 완료 되면 바로 응답을 내리고 재고 처리와, 알림은 비동기적으로 처리하는것이다. 이러한 상황에서 우리는 비동기 통신을 활용할 수 있다. 이러한 절차를 기반으로 처리했을때 이점은 아래와 같다.
- 요청 - 응답 속도 향상 (사용자 경험 향상)
- 부하 / 분산을 통한 효율적 자원 활용
결론적으로 우리의 서비스가 효율적인 자원활용과 빠른 처리가 필요할때 생각할 수 있는 방법이다.
* 참고) 부하 / 분산을 통한 효율적 자원 활용 및 성능 개선 이외에도 Kafka를 기반으로 통신하면 브로커 서버를 중심으로 각 서비스가 통신하여 서비스간의 결합도를 낮춰 더욱 확장성있는 프로그래밍을 가능하게 하는 장점도 있다. 이를 기반으로 한 아키텍처 EDA (Event Driven Architecture)가 있고 기회가 된다면 EDA에 대해 소개하는 포스팅을 남기도록 하겠다.
Kafka 운용
1. 각 도메인을 기준으로 Topic을 나눈다.
2. 각 도메인의 특성과 처리량을 고려하여 Patition의 갯수를 정한다. ( Partition은 Kafka 운용에서 병렬처리에 대한 지표로서 중요한 역할을 한다.)
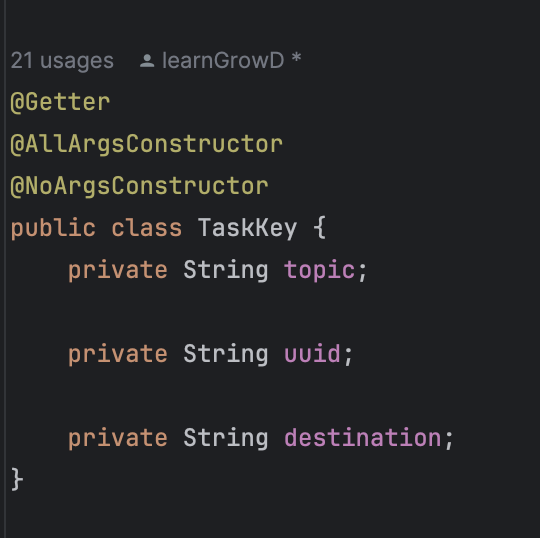
3. Producer를 통해 Kafka Broker 서버에 값을 발행할때는 Topic을 기준으로 아래와 같은 Json Data를 발행한다.
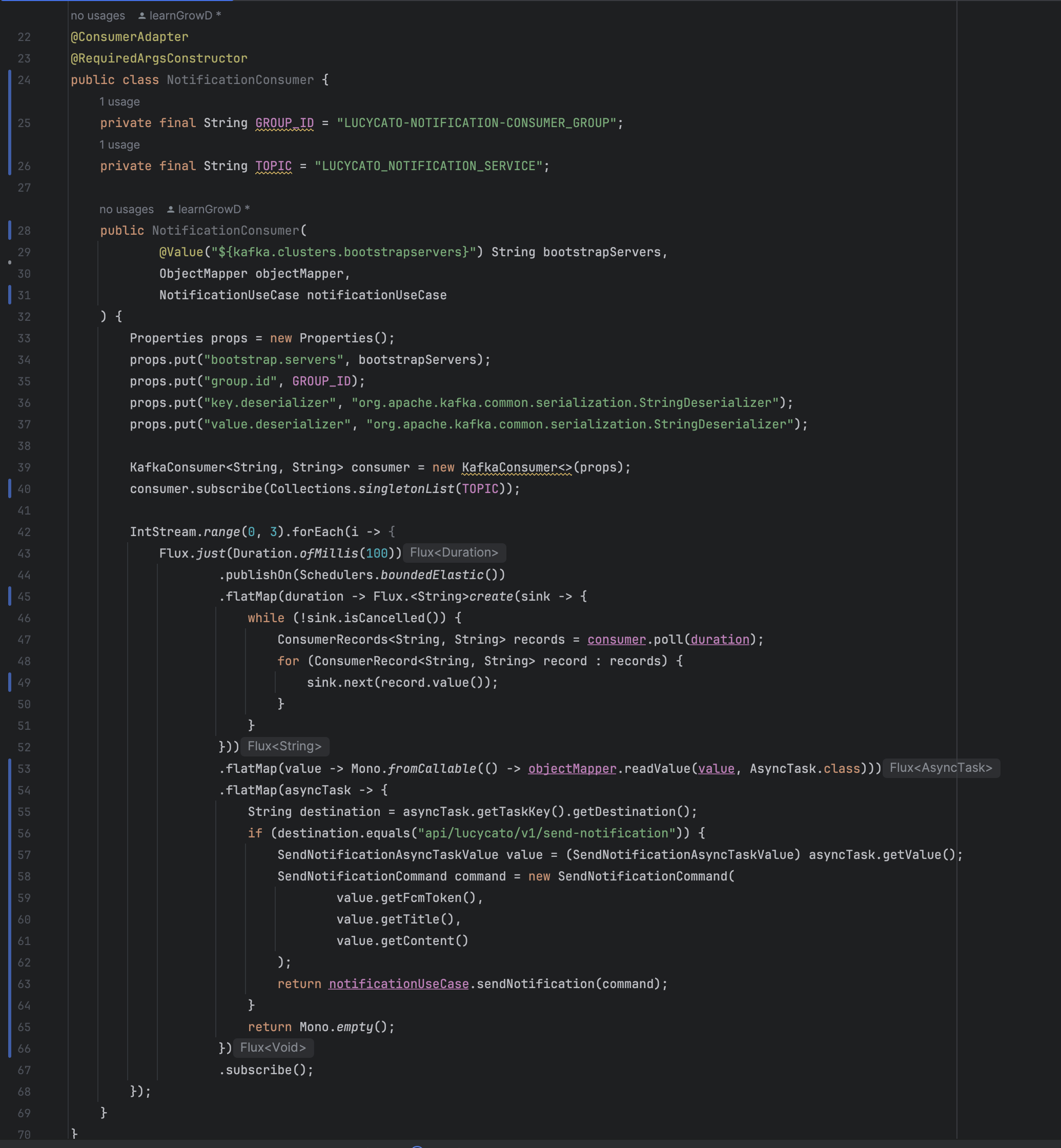
4. Partition의 갯수를 기반으로 Consumer Group에 Consumer를 배치하고, Topic을 기준으로 구독하여 Producer에서 보낸 값을 소비한다. ( Consumer Group에 배치된 Consumer들은 각각 특정 Partition을 할당받아 병렬 처리를 진행한다.)
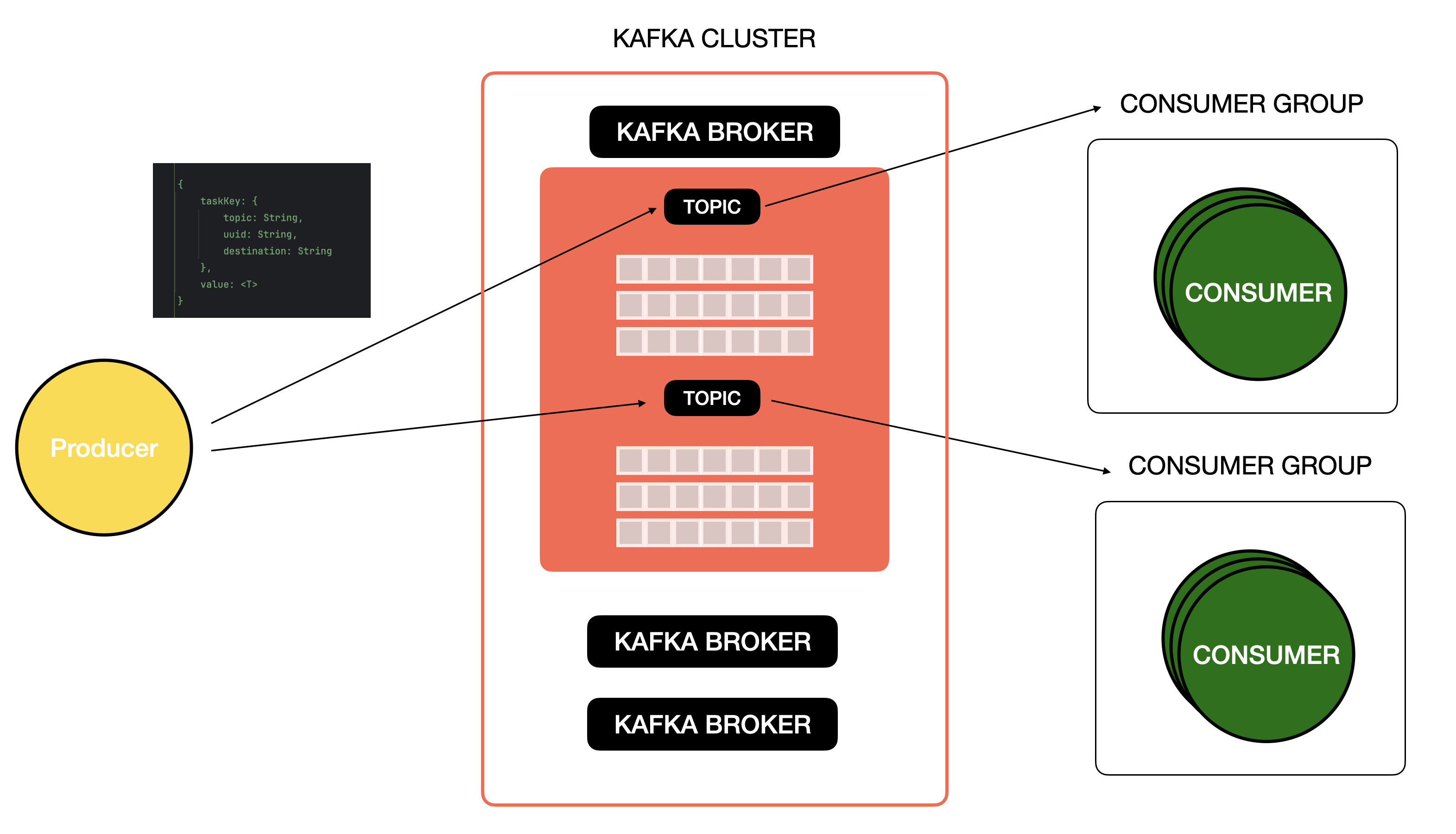

*부가 설명)
- Topic을 생성하는 기준은 각 도메인을 기반으로 생성한다. notification-service가 비동기 통신이 필요하면 이에 관한 Topic을 생성하고, product-sevice가 비동기 통신이 필요하면 이에 대한 Topic을 생성한다.
- Consumer Group내의 Consumer들은 하나의 Topic을 공유할 수 있다. 이 말은 각 Consumer는 각각의 Partition을 할당 받아 각 Partition의 레코드를 처리한다. 이때 Consumer Group내의 Consumer들은 병렬처리를 진행한다. 즉, Partition은 병렬처리를 위한 중요한 성능 지표고 각 도메인의 특성을 고려하여 갯수를 잘 정하는것이 중요하다.
- Producer는 우리가 정한 Protocol을 기반으로 값을 발행한다. Consumer 또한 이 Protocol을 이해하고 있다. 즉, Consumer는 Producer가 값을 발행하면 우리가 정한 Protocol을 기반으로 데이터를 해석하여 특정 비지니스 로직을 실행하는 Trigger 역할을 한다.
코드를 통해 자세히 이해해보자
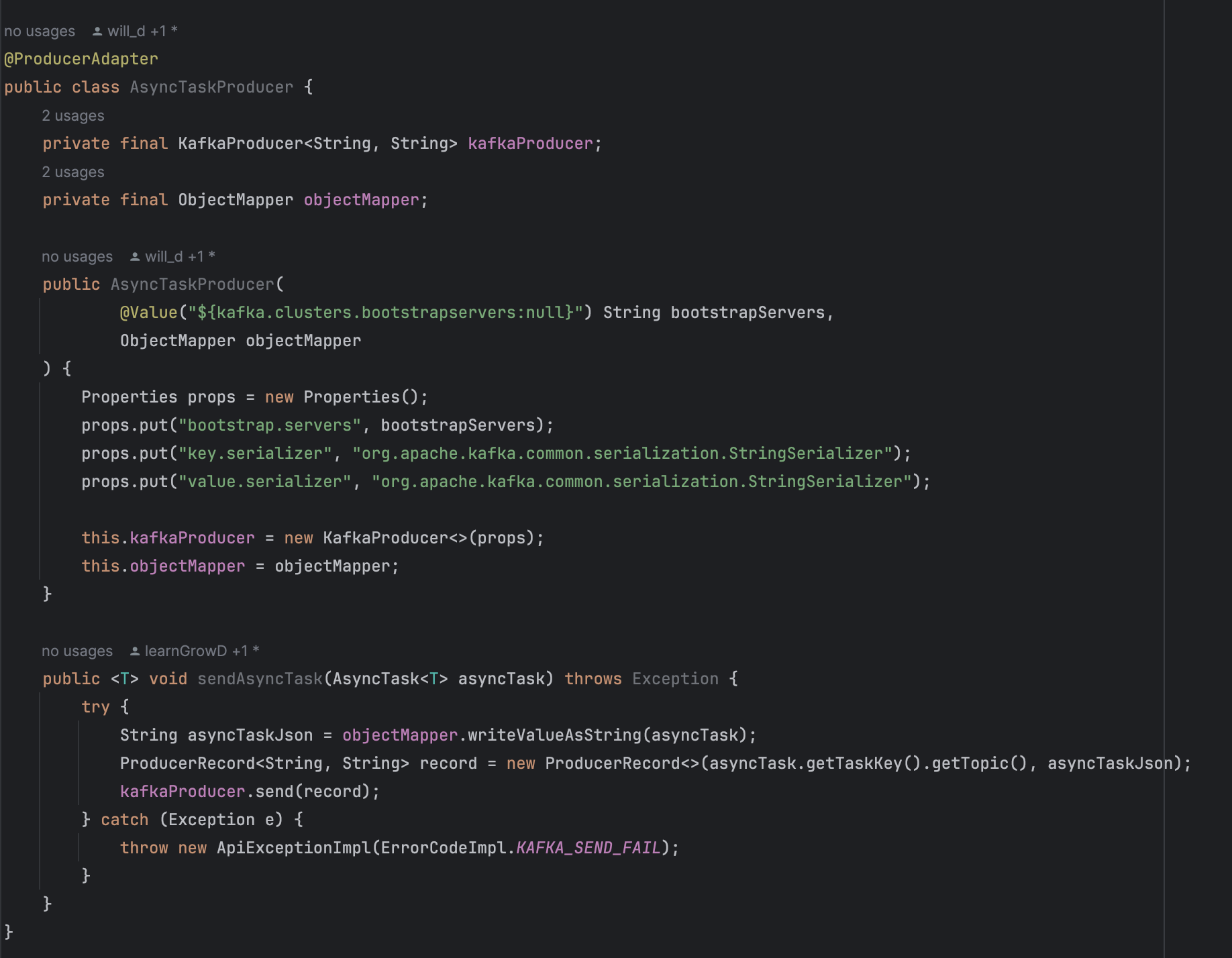
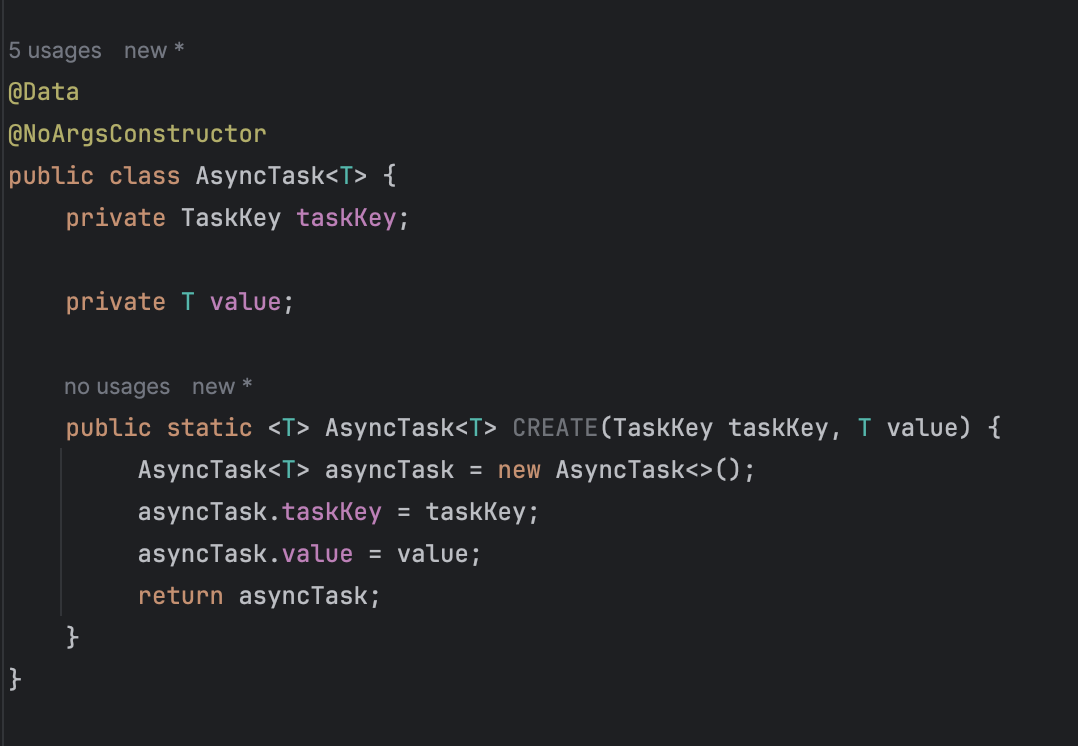
통신을 안정적으로 운용하는 방법
동기적으로 통신을 하던, 비동기적으로 통신을 하던 통신에 대원칙이 있다. 한번 떠나간 요청은 다시 회수할 수 없다. 이미 떠나간 요청을 막는 방법은 없다. 이러한 특성을 고려하여 실패 상황에 대한 대응은 통신을 안정적으로 운용하는데 있어 매우 중요한다.
- 순서가 보장된 통신에서는 실패에 대한 응답을 확일 할 수 있다. 실패에 대한 응답을 기준으로 보상트랜잭션 (Rallback API)와 같은 처리를 통해 정합성을 맞출수 있다.
- 순서가 보장되지 않는 통신에서는 실패에 대한 응답을 확일 할 수 없다. 만약 Kafka를 통해 이벤트를 발행하여 특정 서버에서 이 처리를 하다 실패를 했을때 추후 대응을 위해 실패에 대한 요청을 관리해야 한다. 이 관리를 통해 데이터의 정합성을 맞출 수 있다.
