
- 연산을 여러번 해야하는데, 쿼리문에 줄이고 싶다.
- 연산한 결과를 다른 연산이나 조건문에 사용하고 싶다.
- 필요한 데이터가 여러 테이블에 나누어져 있는데 한 번에 조회하고 싶다.
SUBQUERY
언제 필요한가?
- 여러번의 연산을 수행해야 할 때
- 조건문에 연산 결과를 사용해야 할 때
- 조건에 쿼리 결과를 사용하고 싶을 때 (예: 30대 이상이 주문한 결과만 조회)
(예시1) 불러온 결과 값을 사용하는 예시.
select price/quantity '단가' from ( select price,quantity from food_orders ) sub_1
예시(2) Basic
음식 주문시간이 25분보다 초과한 시간을 가져오기
select order_id, restaurant_name, if(over_time>=0, over_time, 0) over_time from ( select order_id, restaurant_name, food_preparation_time-25 over_time from food_orders ) aover_time값이 0보다 큰 경우에만(값이 존재할 경우)에만 결과 값을 출력하라.
내부 쿼리만 실행 할 경우 -값들이 나오므로,
그렇지 않도록 서브쿼리 결과값에 조건문을 줄 수 있다.
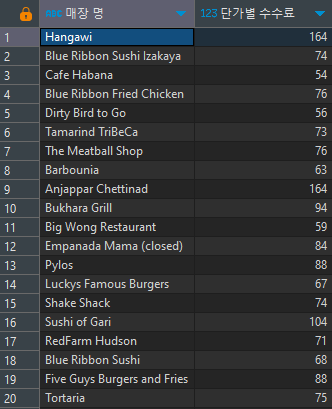
예시(3) 수수료
음식점의 평균 단가별 세분화를 진행하고, 그룹에 따라 수수료 연산하기
- 수수료 구간
~5000원 미만 0.05%
~20000원 미만 1%
~30000원 미만 2%
30000원 초과 3%select -- 가게 별 수수료 계산 restaurant_name '매장 명, floor(price_per_plate*ratio_of_add) "단가별 수수료" from ( -- sub_2: 단가 범위에 따른 수수료 비율 조건문 select restaurant_name, case when (price_per_plate < 5000) then 0.0005 -- 0.05% when (price_per_plate between 5000 and 19999) then 0.01 -- 1% when (price_per_plate between 20000 and 29999) then 0.02 -- 2% else 0.03 -- 3% end ratio_of_add, price_per_plate from ( -- sub_1: 레스토랑 별 단가의 평균 값 select restaurant_name, floor(avg(price/quantity)) price_per_plate from food_orders group by 1 ) sub_1 ) sub_2
완전히 이해했어.
실습(1) 평균 배달 시간
음식점의 지역과 평균 배달시간 세분화 -> (해석) 지역 별 평균 배달 시간
1. 어떤 테이블에서 데이터를 뽑을 것인가: food_order
2. 어떤 컬럼을 이용할 것인가: restaurant_name, addr, delivery_time
3. 어떤 조건을 지정해야 하는가: x
4. 어떤 함수 (수식) 을 이용해야 하는가: avg(), substr(), if(), group by(), case when ()select restaurant_name '매장명', addr '배달 지역', CASE when avg_time <=20 then '20분 이하' when avg_time > 20 and avg_time <=30 then '20분~30분' when avg_time >= 30 then '30분 이상' END '평균 배달 시간' from ( select restaurant_name, IF ( substr(addr,1,2) = '경기', substr(addr,5,2), substr(addr, 1,2) ) addr, avg(delivery_time) avg_time from food_orders group by 1,2 -- 음식점의 지역별로 그룹화 order by 1 ) sub1 -- 지역별 매장 평균 배달 시간group by 1,2 해주는 이유
가장 우선시 되어야 하는 기준은 매장(음식점) ->(의)-> 지역(별)
두 열을 모두 기준으로 그룹화하여 각 조합의 결과 값을 뽑기 위함.
쿼리를 작성하는 의도를 항상 생각해야 한다.
cf.group by가 없다면? 전체의 평균 값을 구하기 때문에 하나의 결과 값만 나온다.
실습(2) 수수료 부과
하나의 쿼리문에서 수행하기 어려운 복잡한 연산을 Subquery로 실행
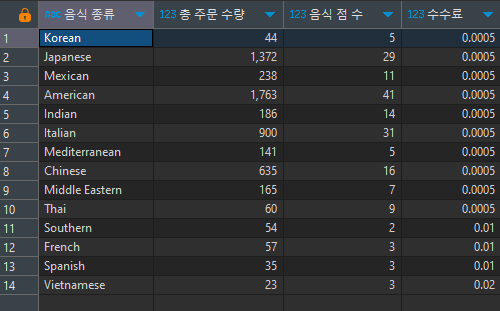
- 음식 타입별 총 주문수량과 음식점 수를 연산하고,
주문수량과 음식점수 별 수수료율을 산정하기
음식점수 5개 이상, 주문수 30개 이상 → 수수료 0.05% (0.05 / 100 = 0.0005)
음식점수 5개 이상, 주문수 30개 미만 → 수수료 0.08%
음식점수 5개 미만, 주문수 30개 이상 → 수수료 1%
음식점수 5개 미만, 주문수 30개 미만 → 수수로 2%
- 어떤 테이블에서 데이터를 뽑을 것인가: food_order
- 어떤 컬럼을 이용할 것인가: cuisine_type, restaurant_name, quantity
- 어떤 조건을 지정해야 하는가 : 주문수 별 수수료
- 어떤 함수 (수식) 을 이용해야 하는가: if(), case(), sum(), count()
select cuisine_type '음식 종류', total_quantity '총 주문 수량', total_shop '음식 점 수', case when total_shop >= 5 and total_quantity >= 30 then 0.0005 when total_shop >= 5 and total_quantity < 30 then 0.0008 when total_shop < 5 and total_quantity >= 30 then 0.01 when total_shop < 5 and total_quantity < 30 then 0.02 else 0 end '수수료' from ( SELECT cuisine_type , sum(sum_quantity) total_quantity, -- '총 주문 수량', sum(shop_count) total_shop -- '매장수' from ( SELECT restaurant_name, cuisine_type, sum(quantity) as sum_quantity, if (COUNT(restaurant_name) > 1, 1, 1) shop_count -- count(distinct restaurant_name) count_res 중복제거 count from food_orders group by 1,2 -- order by 2 ) sub1 group by 1 ) sub2

모든 사람이 쉽게 이해할 수 있는 데이터 분석을 지향하는 분석가가 되고 싶습니다. "데이터 분석은 사람을 설득 시킬 수단이다. "