[번역] React Query API 디자인, 그 교훈
해당 글은 tkdodo.eu의 27번째 글을 번역했습니다.

안녕하세요, 여러분 👋
오늘 이 자리에 서게 되어 정말 기쁩니다.
이번이 제가 직접 참여하는 컨퍼런스에서 라이브로 발표하는 첫 번째 기회인데,
그 무대가 오늘 런던에서 열리는 React Advanced라는 점이 특히 뜻깊습니다.

요즘엔 “TanStack React Query”라고 부르고 있습니다.
간단한 질문 하나 드릴게요. 손 들어 보세요—여러분 중 React Query에 대해 들어본 분 계신가요? 사용해 보신 분은요?
좋습니다! 그렇다면 오늘 제가 이야기할 API 중 일부는 이미 아실 수도 있겠네요.

왜냐하면 React Query에서 우리가 내린 몇 가지 API 디자인 선택을 여러분과 함께 살펴보고, 잘된 점에 대한 이야기뿐만 아니라 우리가 겪은 절충점과 실수들을 짚어 보며, 그로부터 얻은 교훈을 공유해 드리려고 합니다. 그리고 제가 이 내용을 다루려는 주된 이유는 크게 두 가지입니다.
첫번째로, api 디자인은 어렵다는 것입니다.
제 말을 안 믿으시겠다면, Julius가 이렇게 말했습니다.
정말 똑똑한 사람인데요, tRPC를 유지·관리하고 React Query에도 기여하고 있습니다.
그가 이렇게 말했다면, 아마 맞을 거예요.

그리고 두 번째 이유는, React Query에는 정말 정말 매력적인 API가 있다고 생각하기 때문입니다.
이 점이 지난 몇 년간 React Query가 크게 성공할 수 있었던 이유 중 하나이기도 하고요.
물론 이 모든 공을 제가 가져갈 순 없습니다. 이 라이브러리와 대부분의 API를 설계한 건 Tanner Linsley이니까요.
그리고 그가 목표를 잘 요약한 멋진 트윗이 하나 있습니다:
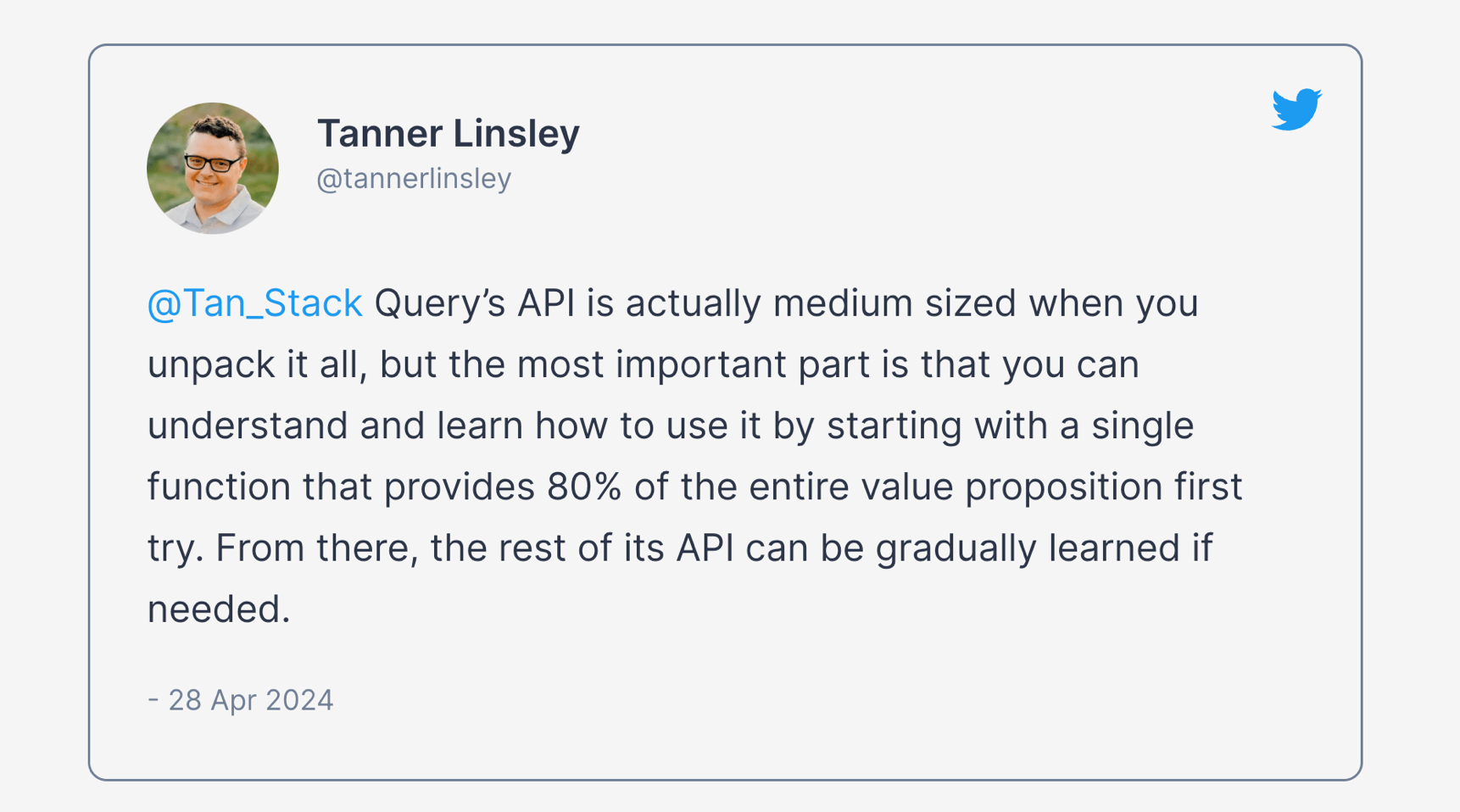
“@Tan_Stack Query의 API는 사실 모두 펼쳐 보면 중간 정도 크기이지만,
가장 중요한 점은 ‘가치 제안의 80%를 한 번에 제공하는 단일 함수’부터 시작해
이해하고 사용법을 배울 수 있다는 것입니다.
거기서부터 나머지 API는 필요에 따라 점진적으로 학습하면 됩니다.”
— Tanner Linsley (@tannerlinsley), 2024년 4월 28일
그리고 저는, 이것이 라이브러리가 인기를 얻기 위해 필요한 요소라고 생각합니다.

API는 최소·직관적이면서도 강력하고 유연해야 합니다.
이제 각 API별로 구체적인 디자인을 살펴보겠습니다…
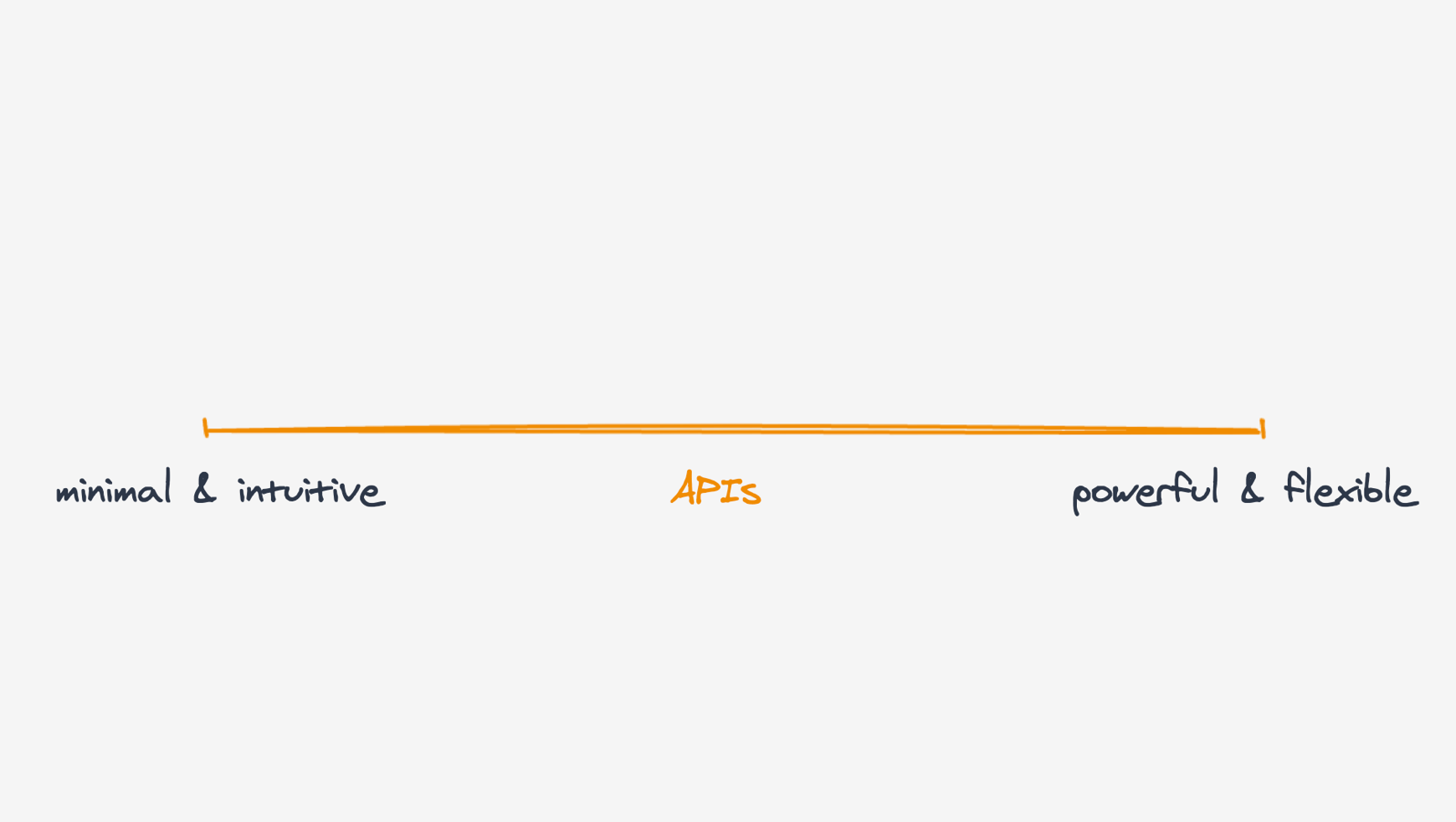
최소·직관적이거나 강력하고·유연하거나
API는 위 두 축의 중간 어딘가에 위치해야 합니다
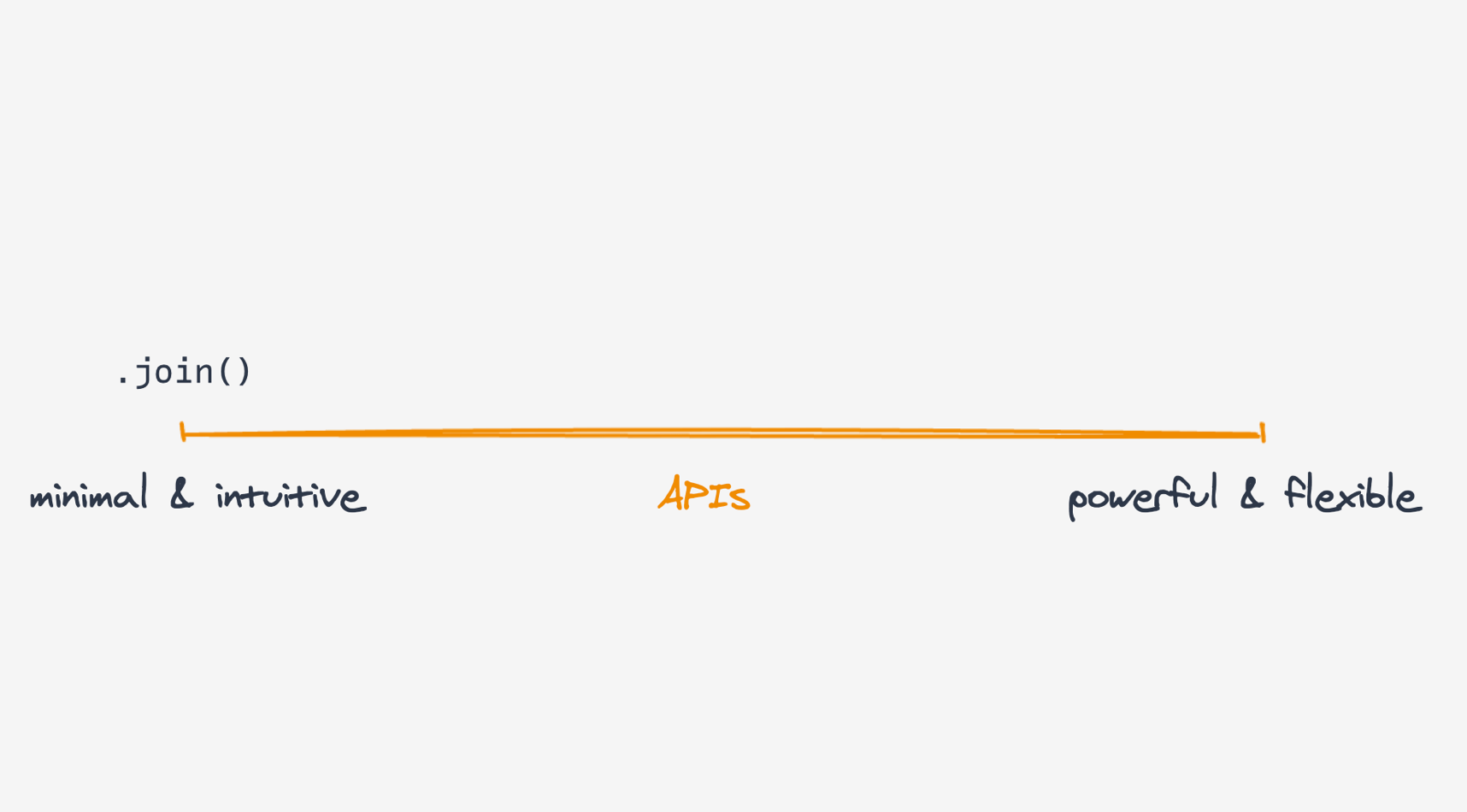
예를 들어 Array.join을 보세요.
하나의 기능을 아주 잘 수행하는 최소한의 API로, 놀랄 만한 요소 없이 매우 직관적입니다.
스펙트럼 반대편에는 Array.reduce가 있습니다.
reduce는 매우 강력해서(실제로 모든 배열 메서드를 reduce 하나로 구현할 수 있죠) 유연하지만, 이해하기 어려울 수 있습니다.
그리고 만약 우리가 사용할 수 있는 유일한 API가 reduce뿐이라면
사용자 입장에서는 결코 만족스럽지 않을 거예요.
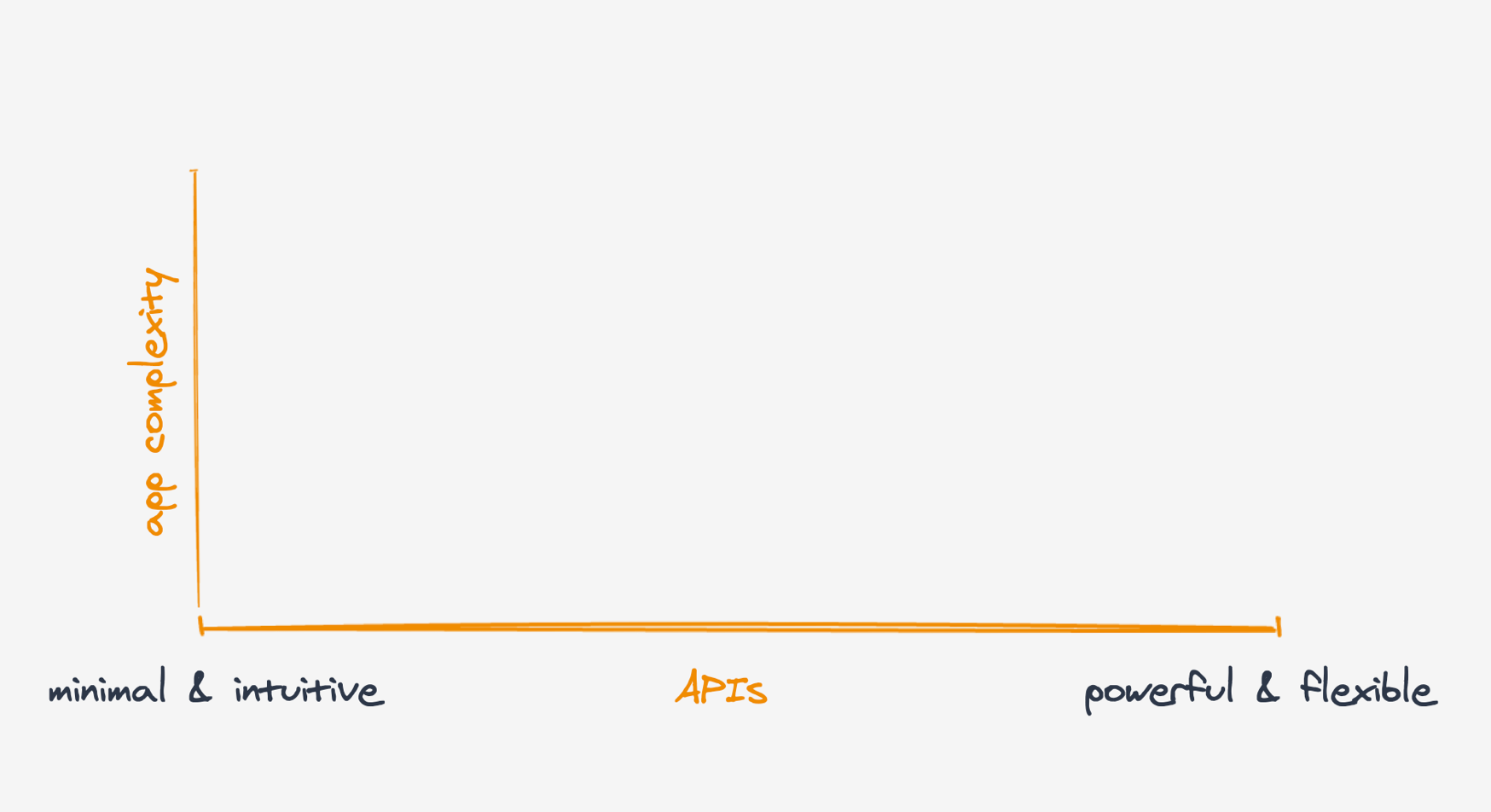
그래서 빠진 축은 두 번째 척도, 즉 “앱 복잡도”입니다.
앱 복잡도가 커질수록 API도 자연스럽게 더 강력하고 유연해져야 합니다.
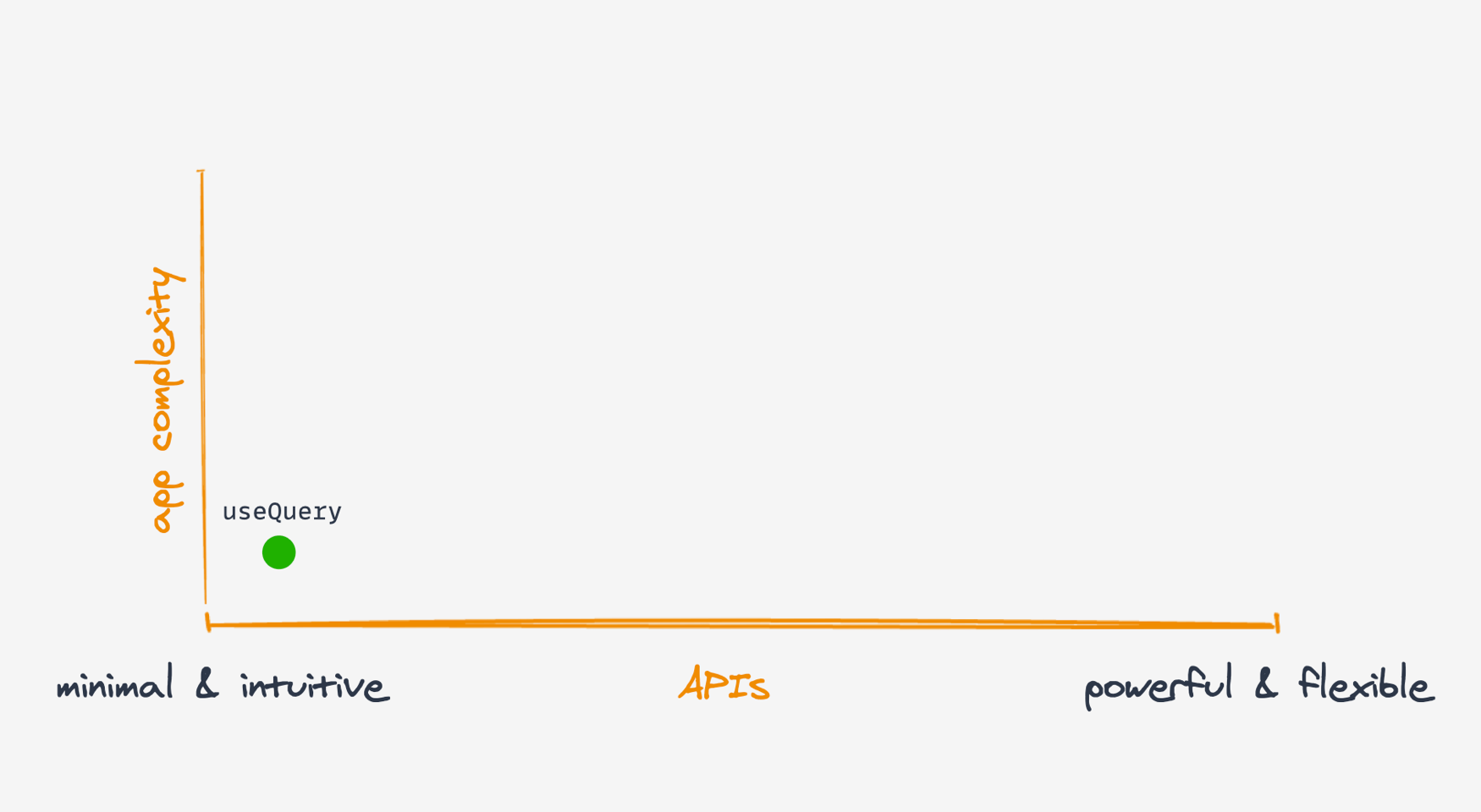
이 차트에서 보시다시피, useQuery 훅은 앱 복잡도가 낮고 최소·직관적인 영역에 위치합니다.
즉, 단일 API만으로 대부분의 기본적인 데이터 페칭 요구사항(전체 값의 약 80%)을 한 번에 해결할 수 있죠.
앱이 단순할 때는 useQuery 하나만으로도 충분합니다.

간단한 API로 사용하기 쉽고, 다양한 기능을 제공합니다.

useQuery 하나만으로도 셀 수 없이 많은 기능이 제공됩니다.
- 캐싱
- 요청 중복 제거
- stale-while-revalidate 백그라운드 업데이트
- 전역 상태 관리
- 자동 가비지 컬렉션
- 로딩 상태 처리
- 오류 상태 & 재시도
- etc…

그다음으로는 useMutation을 추가해 서버에 업데이트를 보내고, 성공 시 쿼리 무효화로 관련 데이터를 자동 갱신할 수 있습니다. 코드가 조금 늘어나긴 하지만, useQuery와 useMutation만으로도 대부분의 데이터 조회·갱신 흐름을 손쉽게 처리할 수 있죠.
그리고 앱 복잡도가 높아지면…
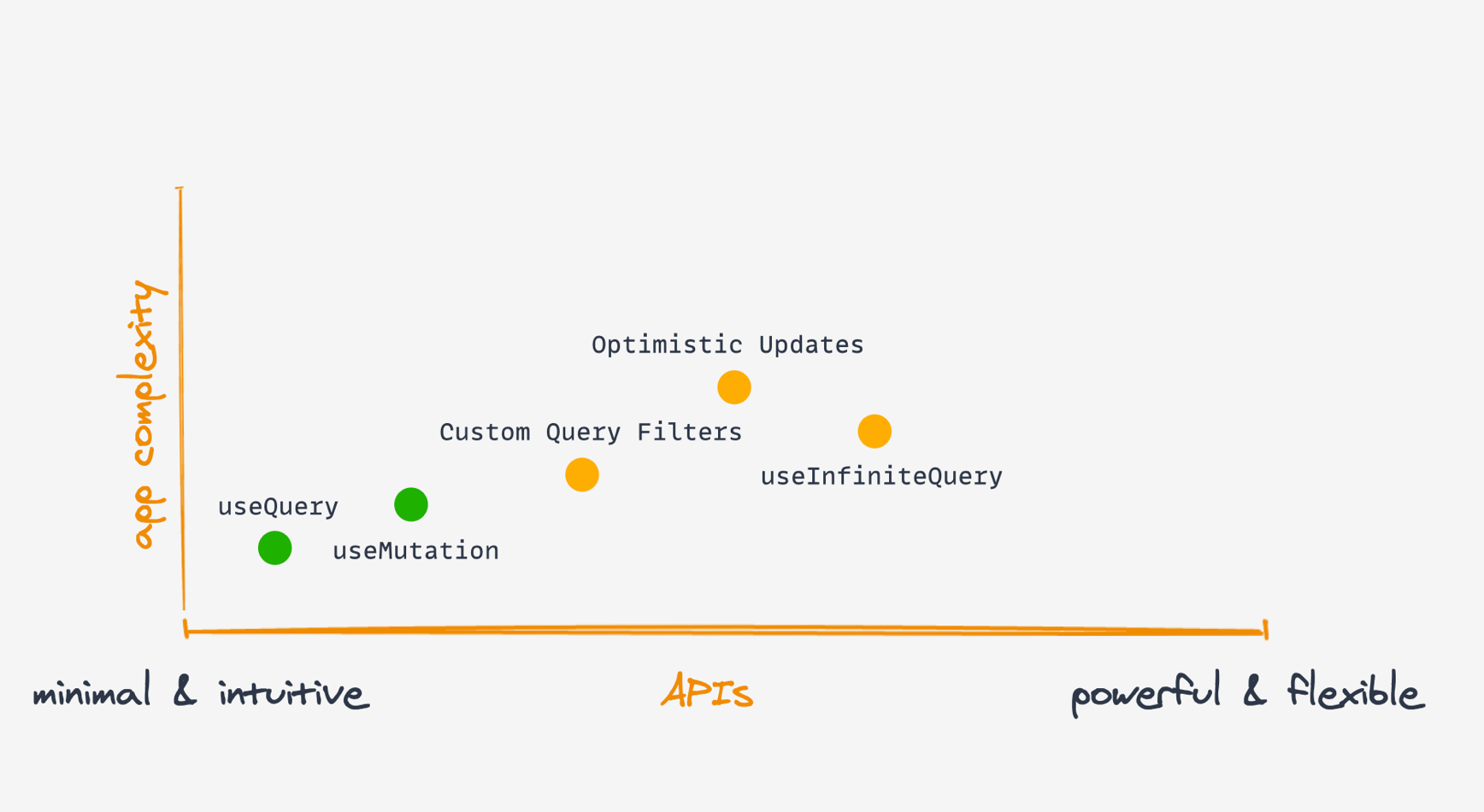
이처럼 사용하는 Query API의 유연성(flexibility) 역시
앱 복잡도가 올라갈수록 함께 높아집니다.
예를 들어 optimistic update를 추가하거나 무한 스크롤 쿼리(useInfiniteQuery) 같은 기능을 도입할 수도 있겠죠.
물론 이 기능들은 조금 더 복잡하게 구현해야 합니다.
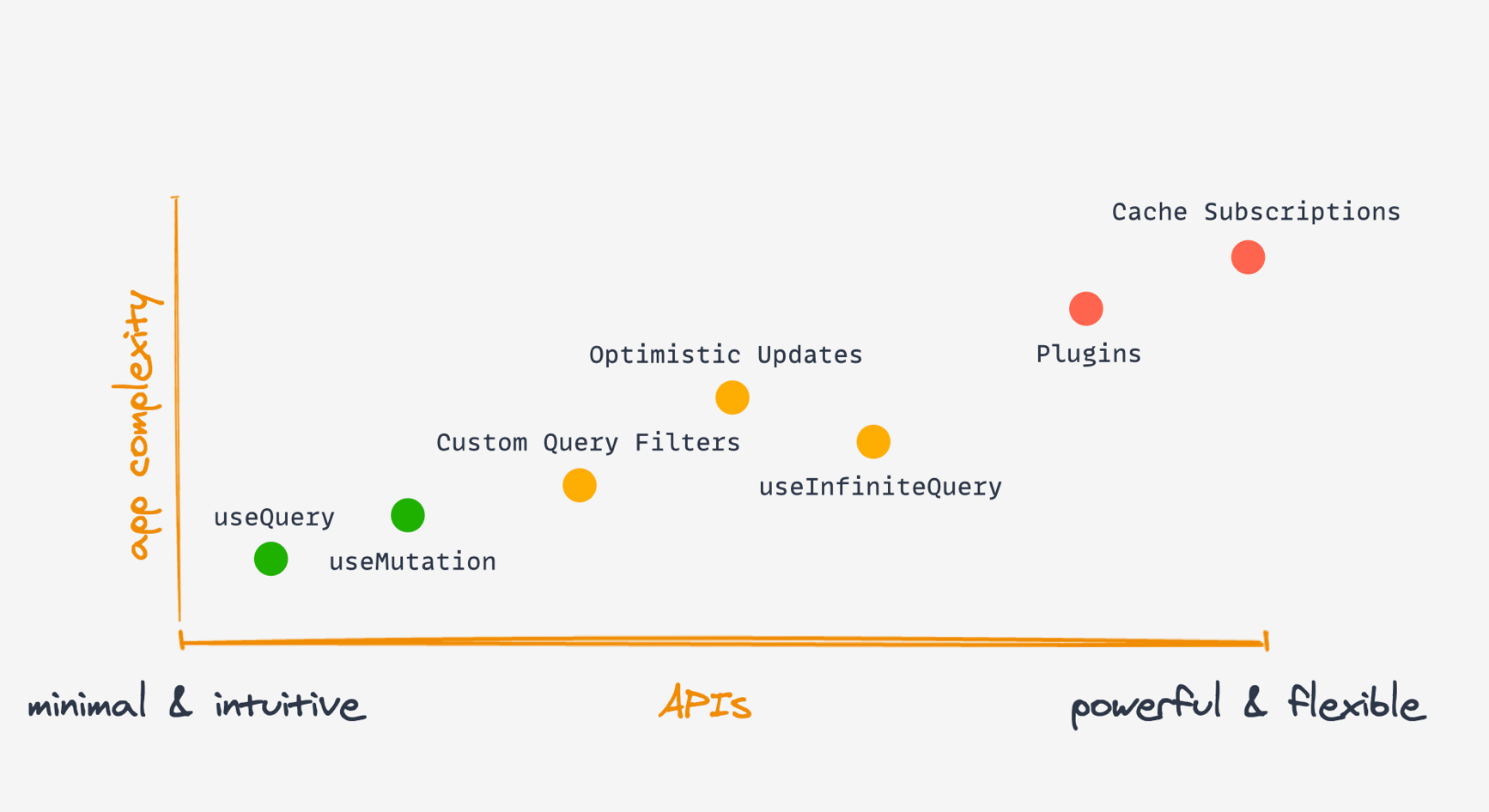
그리고 스펙트럼의 맨 오른쪽에는 퍼시스터 플러그인과 정교한 캐시 구독(Cache Subscriptions) 기능이 있습니다.
예컨대 React Query Devtools가 이 구독 API를 사용해 캐시 변경을 추적하죠.
이 기능들은 초기에 배울 필요는 없지만, 앱 복잡도가 일정 수준에 도달하면
“다행히도 이런 기능이 있구나!” 하고 반가워질 겁니다.
자, 이렇게 해서 여러분과 함께 성장하는 API 디자인을 살펴봤습니다.

신중한 기획과 수많은 반복, 그리고 몇 번의 메이저 버전을 거치면서요.
이 과정이 제가 오픈소스 유지보수자로서 처음 배운 교훈으로 이어집니다.

Learning #1 : 메이저 버전에 기대하지 않기
저는 더 이상 메이저 버전에 크게 들뜨지 않습니다 (여러분도 마찬가지여야 해요).

오픈소스 환경에서는 한번 내린 결정을 쉽게 되돌릴 수 없기 때문에,
API 설계가 특히 더 어렵다고 생각합니다.

Adverity에서는 예전엔 디자인 시스템을 사설 npm 레지스트리를 통해 배포했었습니다.
지금은 모노레포로 합쳐서 더 이상 그럴 필요가 없지만,
그때도 Semantic Versioning을 철저히 지켰죠.
그런데 여러분, 그 패키지의 최신 버전이 얼마인지 아시나요?

"@adverity/design-system": "105.2.0"아무도 신경 쓰지 않았습니다.
버전 숫자만 계속 올라갈 뿐이었죠.
대부분의 프로젝트는 업데이트만 하고,
“메이저 변경”이 전혀 쓰지 않던 컴포넌트에 영향을 주거나,
아주 사소한 변경이어서 고치고 넘어갔을 겁니다.
별일 아니었으니까요.
그러나 오픈소스에서는,
파괴적 변경(breaking change)을 가볍게 할 수 없습니다.
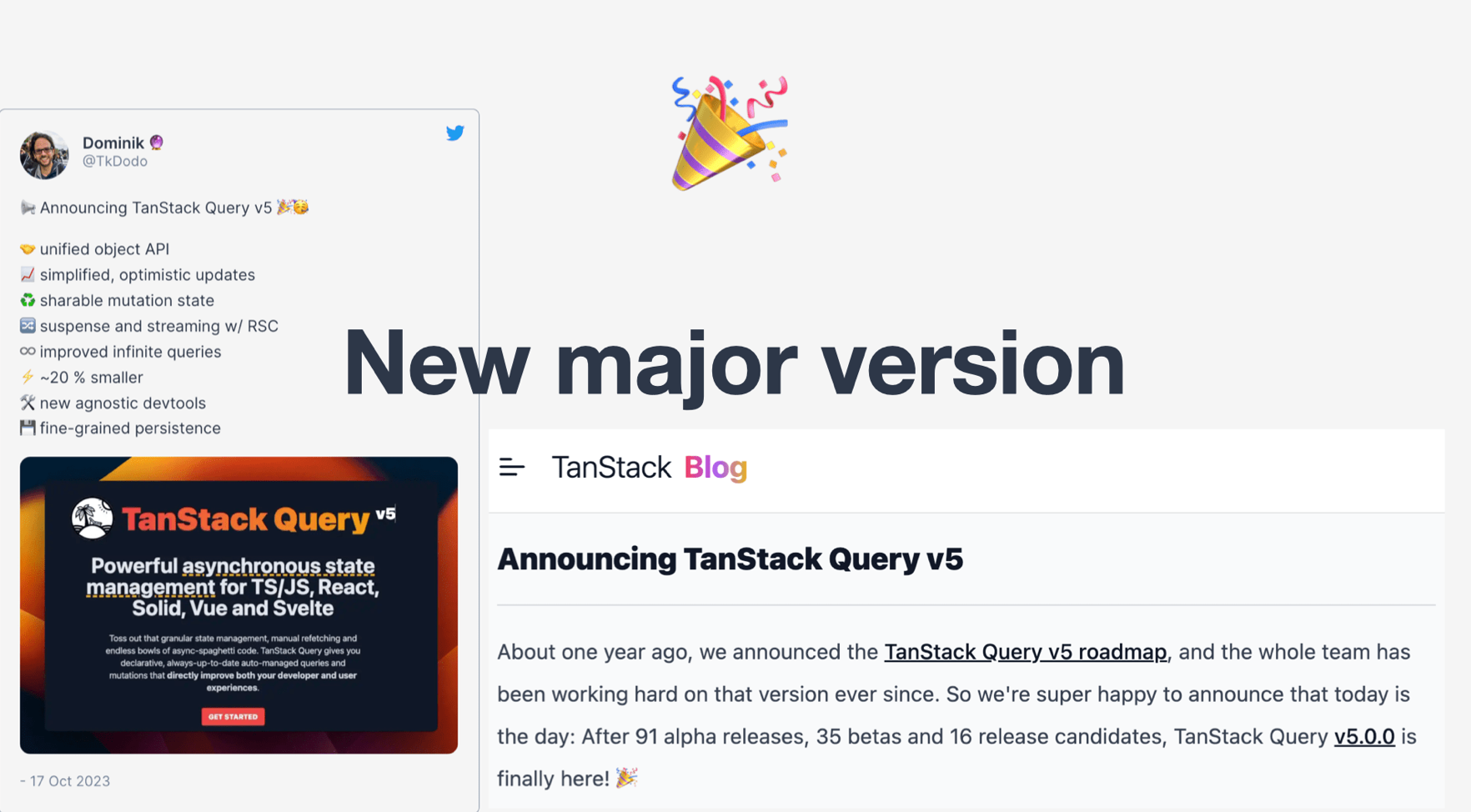
사실 정말로 하나의 마케팅 이벤트가 되어야 합니다.
발표 트윗과 영상, 블로그 포스트 등 모든 홍보 수단이 필요하죠.
사용자들은 ‘메이저(Major)’ 버전이 새로 나왔다고 들으면
Major가 ‘거대함’과 ‘훌륭함’을 동시에 암시하기 때문에
자연스럽게 가장 먼저 떠올리는 질문이 있습니다.

“새로운 기능이 무엇인가요?”
문제는, 메이저 버전은 기능 추가를 위한 것이 아니라는 점입니다.
메이저 버전은 기존 API에 파괴적 변경(major breaking change)을 수반할 때 올리는 것이고,
새로운 기능(feature)은 주로 마이너 버전(minor release)에 포함됩니다.

Hooks 기억하시나요? React는 16.8에서 도입했고,
React Router는 6.4에서 Route Loader를 추가했으며,
Bun은 1.1에서 Windows 지원을 넣었습니다.
기능 추가만으로는 기존 API를 깨뜨릴 필요가 거의 없습니다.
물론 완전히 처음부터 다시 설계해야 하는 예외가 있긴 하지만,
대체로 새로운 기능은 마이너 버전에 포함됩니다

React Query v5의 새로운 기능에 대해 물었을 때, 저는 땀을 삐질삐질 흘리기 시작했습니다. 사실 저희는 주로 기존 API를 깨뜨리고 이름을 바꾸는 작업만 하고 있었지, 딱히 “이게 새로 나온 기능이다!” 할 만한 게 계획되어 있지 않았거든요.
그래서 솔직히 말해 v4에도 역이식(backport)할 수 있었던 몇 가지 기능을 억지로 묶어서 넣었습니다. 하지만 이런 방식은 결코 좋지 않습니다.
단순히 “멋진 마케팅 이벤트”나 “굉장한 새 버전”이라는 명목으로
사용자들에게 기능을 묶어두는 셈이니까요.

제게 달려 있다면, 이런 둘을 분리하는 더 나은 시스템을 만들고 싶습니다. 즉, “파괴적 변경”과 “마케팅 이벤트”를 완전히 떼어내는 방식이죠.
Anthony Fu가 이에 대한 좋은 제안을 했습니다:
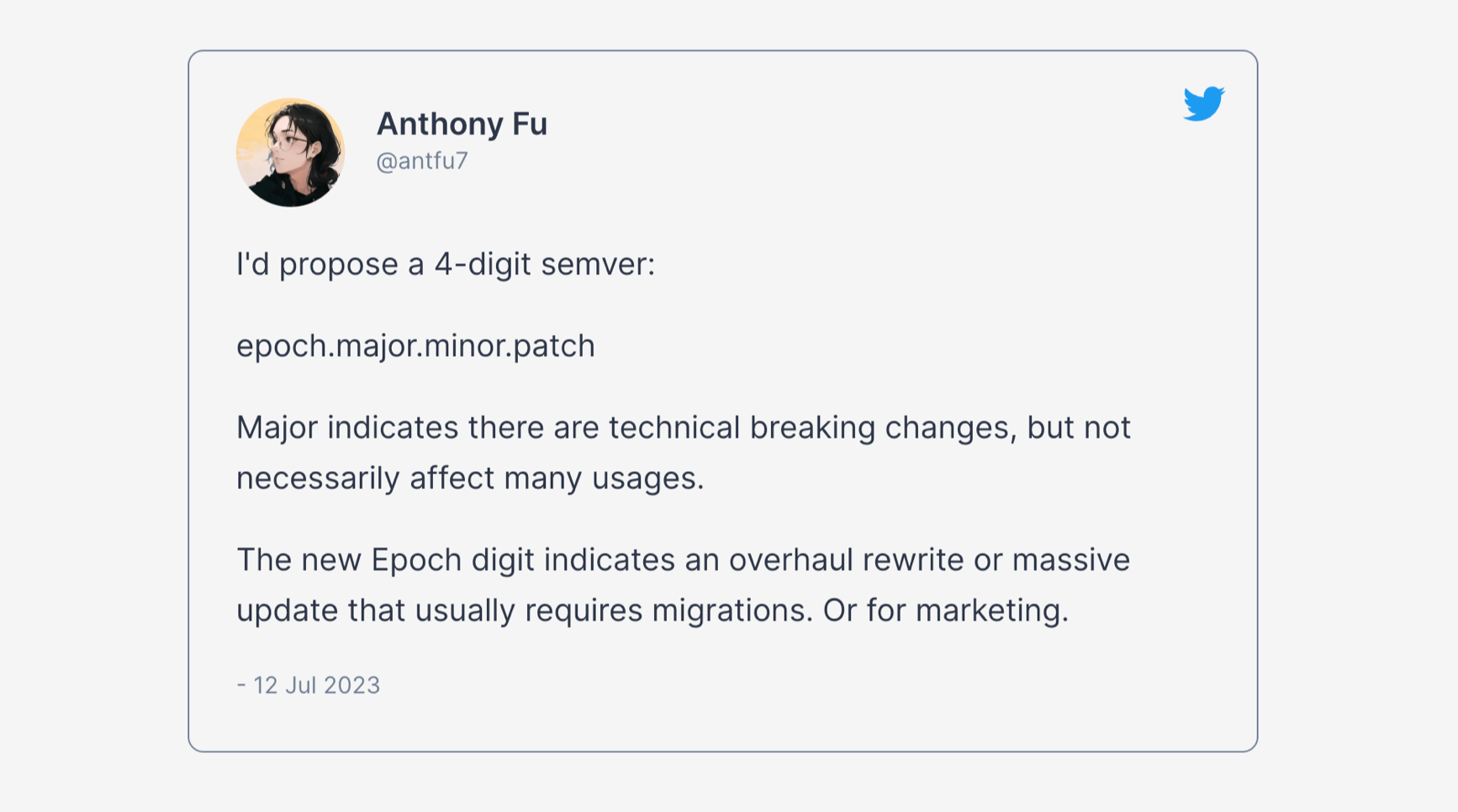
“4자리 SemVer를 제안합니다:
epoch.major.minor.patchmajor는 기술적 파괴적 변경을 의미하지만, 반드시 많은 사용례에 영향을 주진 않습니다. 새로 추가된 epoch 숫자는 보통 마이그레이션을 수반하는 전면 리팩토링 혹은 대규모 업데이트, 또는 마케팅용 변경을 나타냅니다.”
이렇게 4자리 SemVer를 도입하면, 마케팅 이벤트나 커다란 전환점을 표시할 때 epoch 숫자를 올릴 수 있습니다. 실제로 도입될지는 모르겠지만, 생각해볼 만한 좋은 아이디어라고 봐요.
그리고 새 버전이 나올 때는 “무슨 새로운 기능이 있냐”가 아니라
“어떤 파괴적 변경이 있었나”부터 확인하는 습관을 들이면 좋겠습니다.

좋아요, 저는 더 이상 메이저 버전에 들뜨지 않지만,
오픈소스 이전보다 더 기대되는 것은 TypeScript입니다.

걱정 마세요. 오늘은 라이브러리 수준의 타입스크립트 내용까지 다루진 않을 겁니다. 다만, 무언가를 설계·구현할 때 초반부터 타입을 고민해두면 이후 유지보수·확장이 훨씬 수월해집니다.

Learning #2 : 타입을 염두에 두고 설계하기
API를 설계할 때는 반드시 “어떤 타입”으로 사용할지를 먼저 고민하세요.
많은 사람들이 “일단 동작만 되게 만들고, 나중에 타입은 나중에 맞추면 된다”고 하지만, 저는 그 방법이 옳지 않다고 생각합니다.
JavaScript에서는 런타임에 동작하는 귀여운(dynamic) 트릭들을 얼마든지 만들어낼 수 있지만, 그 트릭들이 타입스크립트에서는 제대로 표현조차 되지 않는 경우가 많습니다.

충분한 마법(트릭)을 쓰면 거의 모든 것을 구현할 수 있지만,
그 대가로 타입 복잡도와 유지 보수 부담이 급격히 올라갑니다.
“All magic comes with a price.”

“컴파일러가 못 알아먹는 건 사람도 못 알아먹는다”
“If something is hard for a compiler to figure out, it’s also hard for humans to understand.”
컴파일러에게 표현하기 어려운 API라면, 사람에게도 이해하기 어려울 가능성이 높습니다.
만약 우리가 “컴파일러에게 이걸 어떻게 표현해야 하지?” 하며 고심한다면, 아마 좀 더 직관적인 API 디자인을 고민해볼 필요가 있습니다.

초창기 React Query의 “귀여운” 예
React Query 초창기(타입 지원 전)에는 useQuery를 세 가지 방식으로 호출할 수 있었는데, 이 역시 “런타임에는 작동하지만 타입스크립트로 다루기엔 어렵다”는 대표적 사례였습니다.

TypeScript는 가능한 모든 오버로드를 시도한 뒤 “마지막으로 시도한” 시그니처의 에러만 보여주기 때문에, 실제 문제와 전혀 상관없는 잘못된 힌트를 줄 때가 많습니다.
또, 같은 기능을 3가지 방법으로 호출할 수 있도록 런타임 검사를 추가해야 했는데, “한 가지 동작을 달성하는 데 세 가지 방식이 정말로 필요할까요?” 하는 의문이 들었습니다.

v5부터는 오직 “옵션 객체” 형식으로만 useQuery를 호출하도록 통일했습니다. 그 결과 useQuery의 타입 선언부를 125줄 → 25줄로 무려 80%나 줄일 수 있었습니다.
“처음부터 타입을 염두에 두고 설계했다면” 바로 이 지점에 도달했을 거라고 생각합니다.

사용자는 더 많은 기능을 원합니다.
솔직히 말하자면, 까다로운 사용자 기반을 관리하는 일은 오픈 소스에서 가장 힘든 과제 중 하나입니다.
한편으로는 채택을 늘리려면 사용자 피드백에 귀 기울여야 하고, 그들의 기대를 충족시키며 문제를 해결해 줘야 합니다. 다른 한편으로는 라이브러리에 기능을 추가할수록 API는 점점 부피가 커지고 복잡도가 올라가 결국 채택이 오히려 감소하게 됩니다.
이 둘 사이에서 절묘한 균형을 찾아야 합니다.

Learning #3 : 요구사항에는 신중하게 대응하라
사용자는 매우 다양한 요구사항을 제시할 수 있고, 그들의 마감 기한과 중요도를 설명하는 것은 사용자(혹은 사례)의 역할입니다.
그러나 기능을 실제로 라이브러리에 추가할지는 유지보수자의 몫인데요.
이 기능이 정말 모든 사용자에게 도움이 되는지 요청자가 미처 고려하지 못한 예외 사례는 없는지, 한 번 공개된 API는 메이저 릴리스 전까지는 변경할 수 없다는 점을 반드시 유념해야 합니다.
결국, 사용자 요구를 무작정 수용하기보다 “전체 그림”을 보고, 충분히 고민한 뒤 최종 결정을 내려야 합니다.
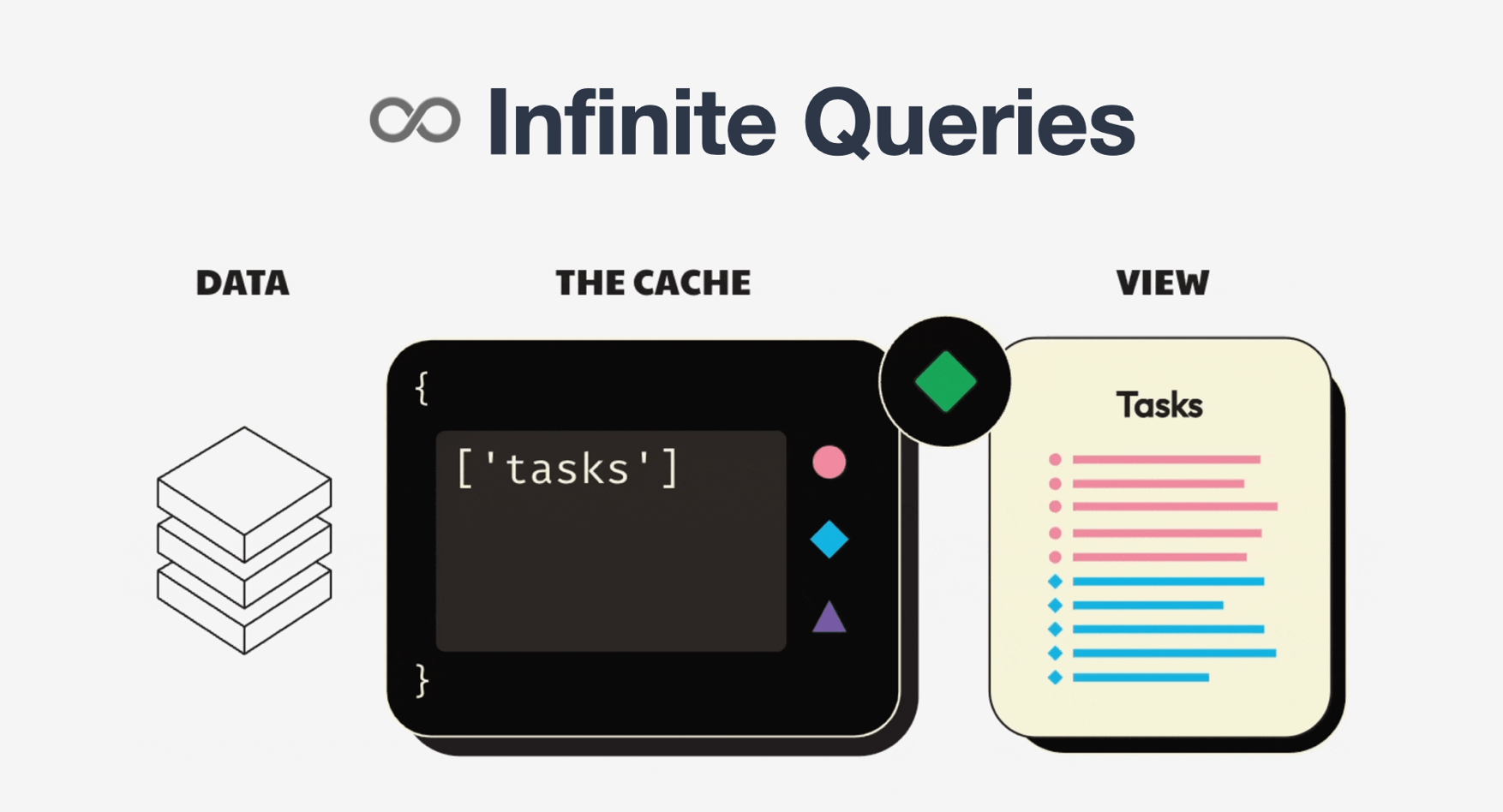
여기 예시가 있습니다.
무한 스크롤 페이지를 간단히 구현하기 위해 도입한 기능입니다.
기술적으로는 하나의 캐시 엔트리(['tasks'])를 “페이지별 청크”로 쪼개 관리하죠.
리패치(refetch)가 발생할 때마다 React Query가 캐시된 모든 페이지를 전부 다시 요청했습니다. 하지만 대부분의 경우, “특정 페이지 한 페이지만” 다시 불러오고 싶어했습니다.

꽤 합리적인 요구사항이라 생각해서, invalidateQueries와 같은 일부 기존 API에 새로운 필드를 추가했습니다.
이제 모든 페이지를 다시 가져오는 대신, false를 반환하여 특정 페이지만 다시 가져오는 방식을 적용했습니다. 그러나 이것은 실수였습니다.

API가 이상하고 혼란스럽습니다.
이제 invalidateQueries에도 refetchPage 옵션이 생겼지만, invalidateQueries는 쿼리의 타입을 알지 못합니다.
만약 tasks에 매칭되는 쿼리가 무한 쿼리가 아니라면, 해당 매개변수는 아무런 동작도 하지 않습니다.
제약에 따른 설계
이 API는 기술적 제약 때문에 오직 명령형 메서드에만 추가되었습니다.
React Query가 자동으로 트리거한 리패치에서는 여전히 모든 페이지를 다시 요청합니다.
정확성 우선
기본값으로 모든 페이지를 무조건 무효화하는 이유는 정확성을 보장하기 위해서입니다.
무한 쿼리는 각 페이지가 이전 페이지 위에 쌓여 있는 연결 리스트와 같아서,
중간 페이지만 리패치하고 그 사이에 누군가가 항목을 삭제하면 UI가 엉뚱하게 동기화되지 않을 수 있습니다.

그래서 다시 요구사항을 봤습니다. 이 API를 사용하던 유너에게 주요 동기가 무엇인지 물어보았고, 대답은 늘 같았습니다.
사용자가 한참 아래로 스크롤해서 캐시에 100개의 페이지가 쌓여 있는데, 그 상황에서 서버에 연달아 요청을 날리는 건 원치 않는다는 것이었죠. 지극히 합리적이기 때문에, 우리는 대신 이 문제를 해결할 수 있는 API를 찾기로 했습니다.

그래서 우리는 useInfiniteQuery에 maxPages라는 새 옵션을 도입했어요. 이 옵션을 쓰면 캐시에 몇 개의 페이지만 보관할지 간단하게 제한할 수 있죠.
이 API가 훨씬 낫다고 느낀 이유는, 리패치가 발생할 때마다 페이지 단위로 전부 다시 불러오는 대신 문제를 한 번에 해결해주기 때문이에요.
게다가 캐시에 이미 있는 페이지로 이동할 때 렌더링 속도도 빨라집니다. v5 버전에서 이 기능을 정식으로 넣으면서, 번거로웠던 refetchPages API는 과감히 제거했어요.
이번 일을 통해 제일 크게 깨달은 건, 너무 서둘러 API 설계를 결정하면서 최적이 아닌 선택을 했다는 점입니다. 문제의 본질을 좀 더 깊이 파악할 시간을 가졌더라면, 더 나은 방안을 만들어낼 수 있었을 거예요.
사실 새 API를 공개할 때, 안정화 전까지는 unstable이나 experimental이라는 이름을 붙여야만 하는 경우가 많아요. 이 방식이 나쁘진 않지만, 사용자 입장에선 “정식 지원이 아닌 건가?” 하는 망설임이 생길 수 있죠.
우리는 몇몇 실험적 API에 이런 꼬리표를 달아 사용했지만, 그다지 반응이 좋지 않았습니다. 결국 “다른 대안이 없으니 이렇게라도 해보자”는 선택이었는데, 사용자에게 달가운 소식은 아니었나 봐요. 결국 이 방법이 정말 더 나은지에 대해서는 아직도 고민이 남습니다.
또 하나 자주 요청받는 기능은 API 호출 디바운스(debounce)예요.
예를 들어 검색창에 입력할 때마다 자동으로 필터링을 걸고 싶다면, 연속된 요청을 적절히 묶어서 보내는 디바운스 기능이 꼭 필요하죠.
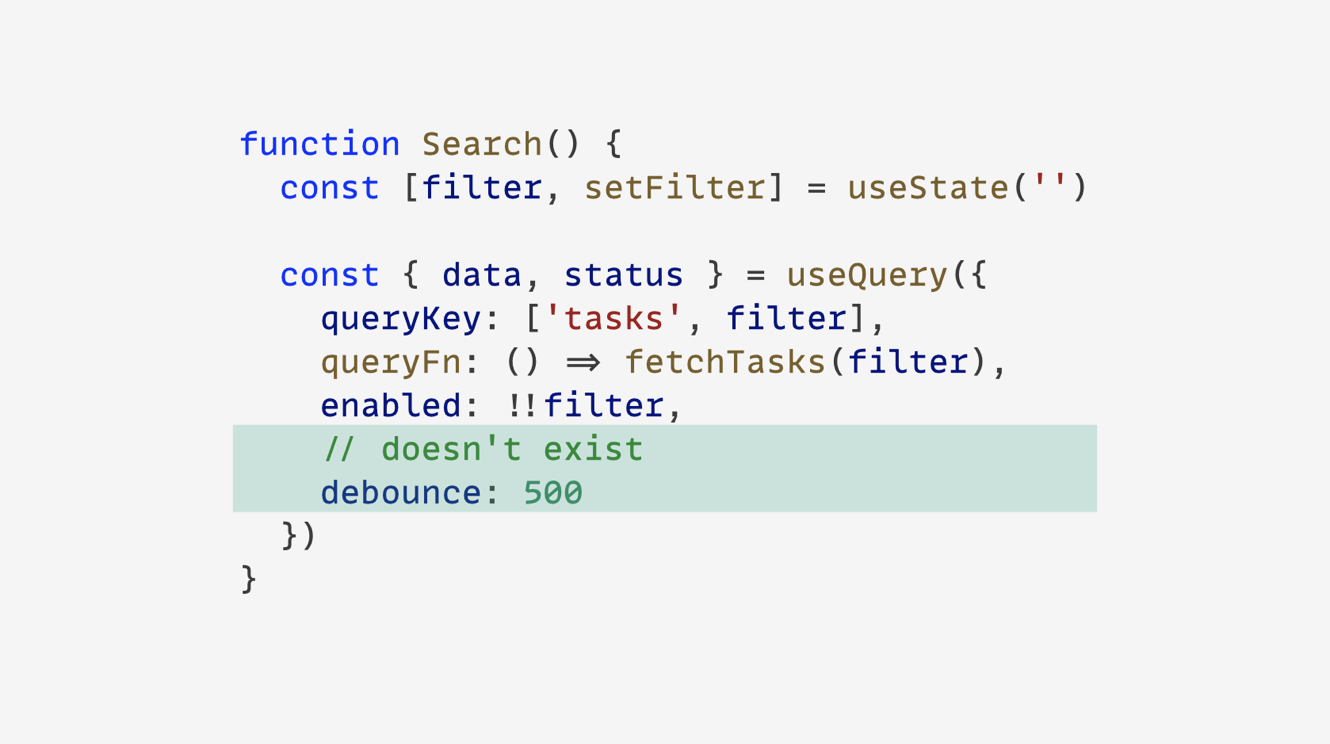
검색창에 입력할 때마다 바로 API 요청을 보내고 싶지 않다면, 디바운스(debounce) 기능이 필수죠.
하지만 디바운스는 React Query의 책임 범위가 아니어서 공식적으로 제공될 일은 없을 거예요. 구현 방식도 무척 다양해서 단순히 debounce: 500 같은 숫자 옵션만 넘기는 것으로 해결할 수 없거든요. 오히려 React Query 내부에 디바운스 로직을 집어넣다 보면 코드 복잡도와 번들 사이즈만 늘어날 뿐입니다.
다행히도, 애플리케이션 레벨에서 비교적 간단하게 디바운스를 구현할 수 있으니, 필요한 형태로 직접 훅이나 유틸을 만들어 사용하는 쪽을 추천합니다.

원하는 useDebounce 구현을 골라 쓰거나, 직접 만들어 사용하시면 됩니다.

아니면 React의 내장 훅인 useDeferredValue를 써도 좋아요.
이 훅은 filter에는 사용자가 입력한 값을 그대로 담아두고, debouncedFilter에는 일정 시간 지연된(deferred) 값을 저장해 줍니다.
그렇게 분리된 debouncedFilter만을 쿼리 키와 queryFn 인자로 넘기면, 마치 디바운스된 API 호출처럼 동작시킬 수 있죠.

Learning #4: 제어의 역전(Inversion of Control)이 탁월하다
“제어의 역전” 패턴은 API 표면은 작게 유지하면서, 사용자가 직접 원하는 기능을 자유롭게 구현할 수 있도록 해 줍니다.
물론 queryKey 자체가 이 패턴의 대표적인 예이지만, 다른 옵션들도 마찬가지로 콜백 함수를 넘기는 방식으로 제어를 사용자에게 위임할 수 있습니다.
예를 들어 에러 처리 로직을 onError 콜백으로 내보내거나, 캐싱 전략을 함수 형태로 받아 사용자가 직접 결정하게 만드는 식이죠.
이렇게 하면 라이브러리 차원의 코드 복잡도는 낮아지면서도, 사용자는 “여기에 내 코드를 꽂아서” 마음껏 동작을 제어할 수 있는 일종의 플러그인 포인트를 얻을 수 있습니다.

예를 들어, 기본적으로 refetchOnWindowFocus: true 설정을 통해 브라우저 창이 포커스될 때마다 데이터를 다시 가져오도록 되어 있는데요.
어떤 사용자는 “쿼리가 에러 상태일 때까지 이 동작이 자동으로 일어나는 건 원치 않는다”고 피드백을 주었습니다. 단순히 그 경우만을 위한 별도의 옵션을 추가하기보다는, 대신 이 설정에 콜백 함수를 넘길 수 있게끔 API를 확장했죠.

함수에는 항상 query 객체가 전달되므로, 그 안에서 필요한 정보를 자유롭게 꺼내 쓸 수 있습니다. 덕분에 이런 방식의 기능이나, 비슷한 사용자 정의 기능을 애플리케이션 레벨에서 직접 구현하기가 한층 쉬워졌죠.
그래서 이제는 거의 모든 옵션이 콜백 함수를 받도록 API를 확장했습니다. 쿼리 상태별로 동작을 바꾸고 싶을 때, 아주 간단한 트릭으로 원하는 로직을 꽂을 수 있게 된 거예요.
마지막으로, 아무리 이런 원칙들을 잘 지킨다고 해도, 어떤 API를 설계하든 일부 사용자는 여전히 불만족스러워할 수밖에 없다는 사실을 잊지 맙시다.

Learning #5: API는 어차피 실수하기 마련
그리고 그 실수에 대해 목소리를 크게 내는 사람도 대개는 그 사용자들이죠. 오픈 소스 유지 관리자라고 예외일 순 없습니다. 언젠가는 반응이 좋지 않은 API를 발표하게 될 확률이 높아요. 저도 React Query v4에서 주요 상태 관리 로직을 변경하면서 이 교훈을 뼈저리게 얻었습니다.

이제 앞서 보았던 검색 예제로 돌아가서, React Query v4에서 추가된 isLoading과 isError 플래그를 이용해 로딩 상태와 에러 상태를 처리했을 때 어떻게 달라지는지 살펴보겠습니다.

이 코드는 v3에서는 아무 문제 없이 잘 동작했지만, v4에선 스피너가 무한히 렌더링될 뿐이었어요.

쿼리가 비활성화된 상태로 시작하면 내부적으로도 isLoading 상태로 간주되기 때문입니다. 물론 이렇게 설계된 나름의 이유가 있고, 처음엔 크게 문제로 느껴지지 않았지만, 객관적으로 보면 React Query를 모르는 사람이 코드를 보고 이 동작 방식을 그대로 받아들인다면… 이건 정말 형편없는 API예요. 변명의 여지 없이 최악이었죠. 실제로 많은 분들이 똑같이 그렇게 느꼈습니다.
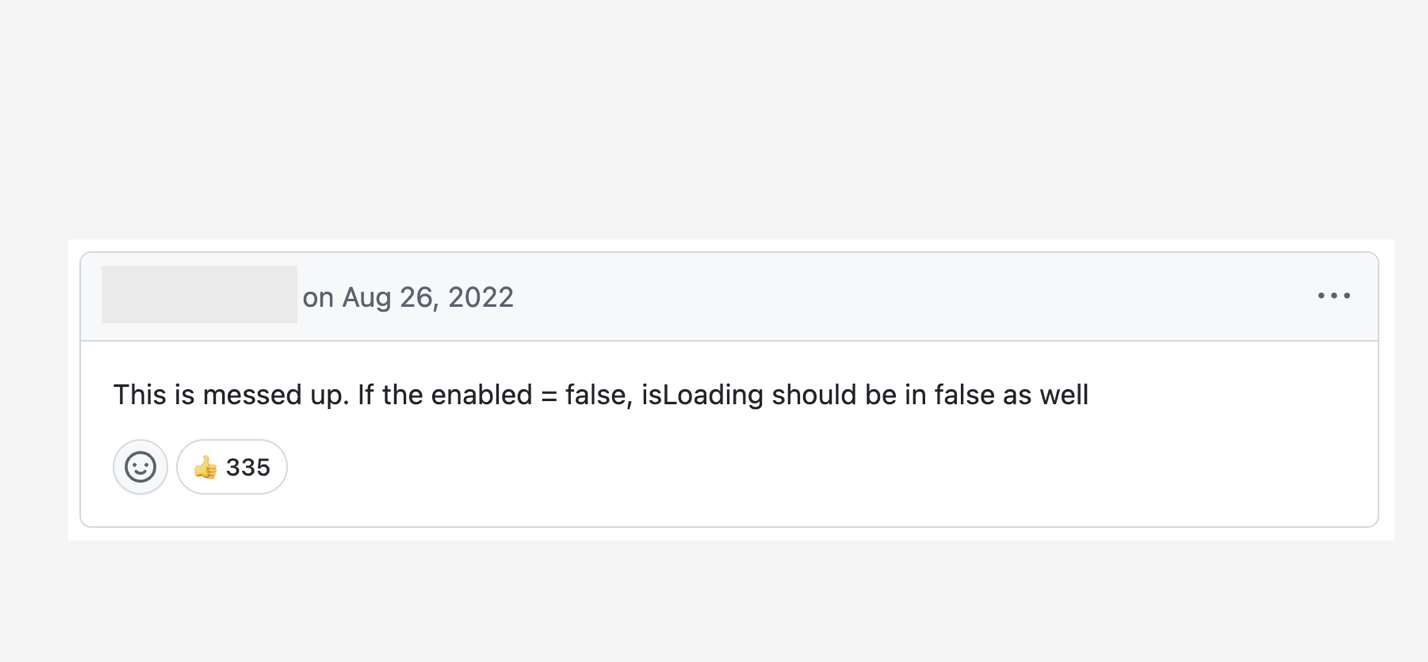
저도 완전 공감합니다. 참고로, v5에서 이 문제를 이미 수정했음에도 저 카운터는 계속 올라가고 있어요. 그런데 이런 보고들이 v4 메이저 버전을 출시한 직후에 쏟아졌거든요. 며칠만 더 일찍 받았더라면 훨씬 좋았을 텐데요.
이 일화에서 가장 인상적이었던 건, 사용자들이 “유지보수자는 API를 완벽히 만들어야 한다”는 기대를 품으면서도, 동시에 베타 버전을 직접 써보고 피드백을 남길 의지는 거의 없다는 점이었습니다.
그래서 이 강연에서 꼭 하나만 기억에 남기신다면, 제가 전하고 싶은 메시지는 이겁니다.

베타 & 프리릴리즈를 꼭 사용해 보세요
사용 중인 오픈 소스 라이브러리의 유지보수자를 돕는 가장 좋은 방법은, 새 베타 버전을 직접 써보고 피드백을 남기는 일입니다. 지금이 바로 목소리를 가장 잘 들려줄 수 있는 타이밍이에요.
이른 피드백이 없다면, 사소한 실수가 “안정(stable)” 릴리즈에 그대로 묻혀 버릴 수도 있습니다. 하지만 “안정”이 버그 없음을 보장하거나 충분히 검증되었다는 뜻은 아니에요—그저 더 이상 API를 바꿀 수 없는 상태가 되었다는 의미일 뿐이죠.
오픈 소스는 쌍방향 소통입니다. 여러분의 참여가 곧 프로젝트를 더 강하게 만들고, 동시에 여러분에게도 돌아오는 혜택이 더욱 커집니다. 베타와 프리릴리즈를 적극 활용해 보세요!
