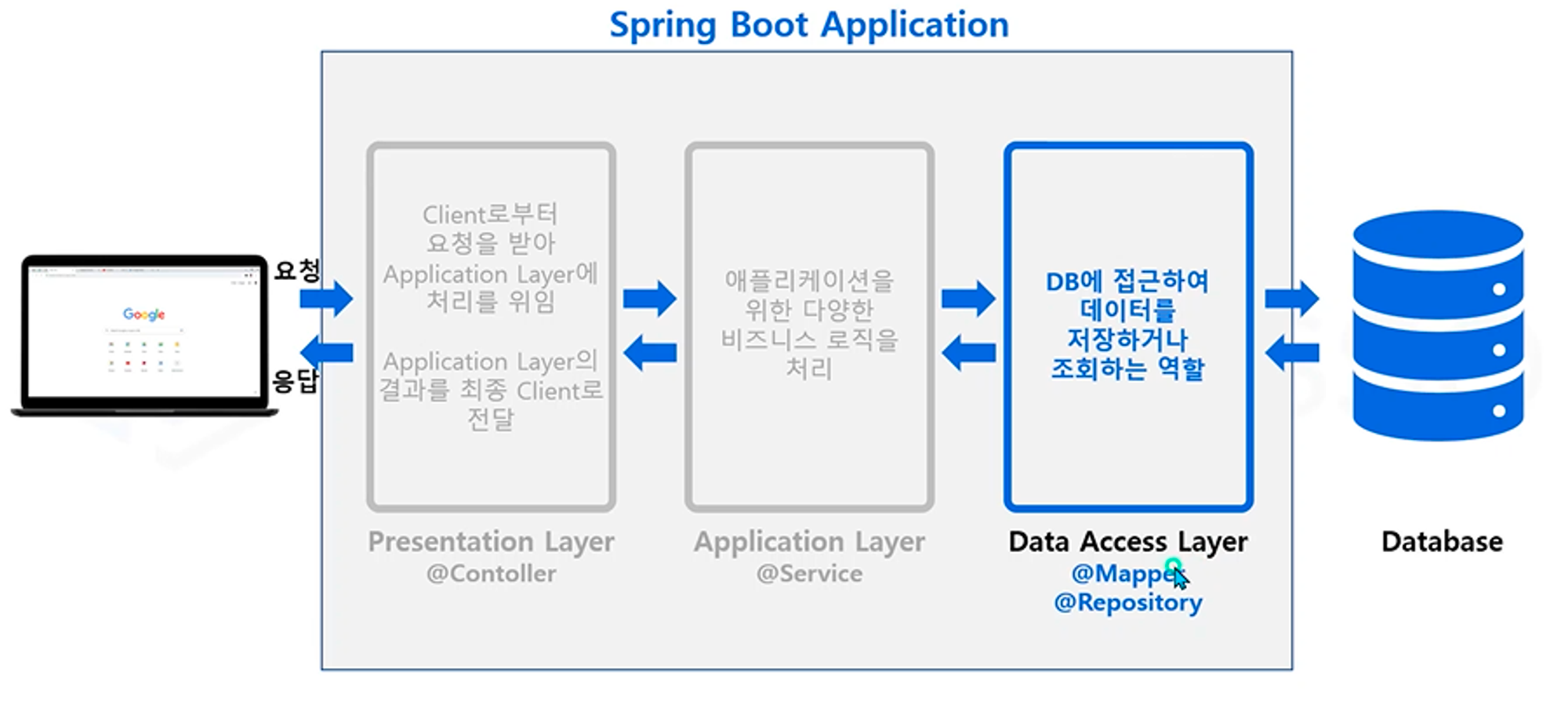
학교 내 커뮤니티에서 스프링 스터디 겸 멘토링이 있어, 관련된 자료를 작성하게 되었다.
Domain model (= JPA Entity)
- 테이블와 매핑되는 객체
- 우리는 JPA를 사용하기에 Domain model은 JPA Entity과 동일시함
- 객체의 필드나 타 객체와의 관계를 수정하면 DB 테이블에도 동일한 구도로 적용
- Springboot에서 가장 기초적이면서 가장 중요한 설계 영역
- 어노테이션: @이 붙은 문자열, 코드 사이에 주석처럼 쓰이며 특별한 의미, 기능을 수행하도록 하는 기술
- Lombok 라이브러리를 통해 기본적인 어노테이션 활용 가능 (아래 문자열 build.gradle에 추가)
- compileOnly 'org.projectlombok:lombok'
annotationProcessor 'org.projectlombok:lombok'
- @Getter: 필드에 getXX 메서드를 자동 생성
- @Setter: 필드에 setXX 메서드를 자동 생성
- @NoArgsConstructor: 어떤 필드도 없는 <기본 생성자>
- @AllArgsConstructor: 모든 필드를 포함하는 <전체 생성자>
Entity의 값은 철저하게 통제된 환경 내에서 변동되어야 무결성을 유지할 수 있기 때문에 돌발적인 속성 변동을 일으킬 수 있는 @Setter는 지양하는 게 바람직하다. 필요하다면 직접 만들어 쓰도록 하자.
**@Entity**
public class User {
**@Id @GeneratedValue(strategy = GenerationType.IDENTITY)**
**@Column(name = "user_id")**
private Long id;
private String name; // 닉네임
private int height; // 키
private int weight; // 몸무게
private int gender; // 성별 (0, 1)
private int age;
@OneToMany(mappedBy = "user", cascade = {CascadeType.REMOVE}, orphanRemoval: false)
private List<Article> articles = new ArrayList<>();
public User(String name, int height, int weight, int gender, int age) {
this.name = name;
this.height = height;
this.weight = weight;
this.gender = gender;
this.age = age;
}
}- @Entity: 이 객체가 테이블과 매핑되는 JPA Entity임을 알림
- @GeneratedValue(strategy = GenerationType.IDENTITY): DB에 한 행마다 생성 시 자동으로 id값을 부여 (1, 2, 3, 4….)
- @Id: Primary Key 속성에 부여한다.
- @Column(name= “user_id”): 이 컬럼명에 이름을 부여한다.
- 이제 이 별명을 통해 다른 객체와의 관계를 설정할 수 있다.
- PK에는 항상 @Column을 달아주는 것이 좋다.
생성자
- Java에서, 클래스를 객체로 인스턴화하는 방법
- 클래스: 붕어빵 틀, 객체: 만들어진 붕어빵
- User user = new User();
- Springboot에서는 생성자를 직접 사용하기보다 생성 메서드나 빌더 패턴을 선호
정적 팩토리 메서드(Static Factory Method)는 왜 사용할까?
생성메서드
public static User createUser(String name, String keyCode, String profileImage) {
User user = new User();
user.name = name;
user.keyCode = keyCode;
user.profileImage = profileImage;
return user;
}- = 정적 팩토리 메서드라고도 불림
- 이름을 가질 수 있고 여러 객체 생성 전략을 구축할 수 있음
- 보통 여러 개의 인자는 of, 하나의 인자는 from을 사용
@Getter
**@AllArgsConstructor(access = AccessLevel.PRIVATE)** // 생성자 PRIVATE로 한정
public class ResponseUserDto {
private String name;
private int height;
private int weight;
private int age;
public static ResponseUserDto **from(User user)** {
return new ResponseUserDto(user.getName(), user.getHeight(), user.getWeight(), user.getAge());
}
public static ResponseUserDto **of(String name, int height, int weight, int age)** {
return new ResponseUserDto(name, height, weight, age);
}
}- 생성자를 외부에 드러내지 않기 때문에 특정 상황에서 정보 은닉 가능
- 단순히 생성자의 역할을 대신하는 것 뿐만 아니라, 우리가 좀 더 가독성 좋은 코드를 작성하고 객체지향적으로 프로그래밍할 수 있도록 지원
참고) 빌더패턴
- JPA Entity에 생성자를 제거하고, @Builder 어노테이션을 부여하여 활용 가능
User user = User.builder()
.name("John")
.height(180)
.weight(75)
.gender(1)
.age(30)
.build();생성메서드 vs 빌더패턴
- JPA Entity는 보통 생성메서드
- 철저한 관리를 통한 데이터 무결성 유지가 목적
- Dto는 보통 빌더패턴
- 클라이언트로의 데이터 전송이 목적
- 여러 속성을 설정하고 생성하기가 간편하며, 필수 및 선택적 속성을 명확하게 다룰 수 있음
- 다만 Dto를 생성메서드로 작성하는 경우도 존재 (본인 아직 Dto에 빌더패턴 안 써봄)
객체간 관계 제어
@OneToMany(mappedBy = "user", cascade = {CascadeType.REMOVE}, orphanRemoval: false)
private List<Article> articles = new ArrayList<>();-
@OneToMany: 현재 Entity와 해당 Entity의 관계를 일대다로 설정
-
왜 ArrayList가 아니라 List로 굳이 선언한 뒤에 초기화하나요? 그냥 선언하면 안 되나요?
- ArrayList는 List를 상속받은 자식 객체
- LinkedList 등으로 변동될 가능성이 존재함
- Entity 코드를 작성하거나 유지 관리할 때 List와 같은 컬렉션에 대한 구체적인 구현체에 의존하는 것보다 추상화된 인터페이스에 의존하는 것이 바람직하기 때문
- 다만 ArrayList로 쓸 거라면 반드시 필드에서 ArrayList라고 명시적으로 초기화해주어야 함
-
mappedBy: 어떤 필드가 주인 엔티티의 관계를 관리하는지를 나타냄
- user는 Article을 작성하고 관리하는 “주인” 이기에 관리자로 볼 수 있음
-
cascade: 연관관계의 트리거를 관리
-
부모 Entity의 상태 변화가 자식 Entity에도 전이되는 기능
-
다시말해 부모 Entity의 상태 변경(추가, 수정, 삭제)이 자식 Entity에 자동으로 적용
주요 CascadeType은 다음과 같다.
-
CascadeType.PERSIST: 부모 Entity가 영속성 컨텍스트에 진입할 때 자식 Entity도 함께 진입한다. 즉 부모 Entity가 저장/수정되면 자식 Entity도 함께 수정된다. 예를 들어 user가 getArticles()를 통해 게시물 목록을 받아와 특정 게시물을 삭제하거나 새 게시물을 추가할 때, 이 변동사항을 DB에 반영되도록 한다.
-
CascadeType.REMOVE: 부모 Entity가 데이터베이스에서 소멸하면 연관된 자식 Entity도 함께 소멸한다.
-
그 외 MERGE, DETACH, REFRESH 등이 있다.
-
CascadeType.ALL: 위 5개 Cascade를 적용한다. ALL을 남용하면 중요한 순간 의도치 않은 DB 제어로 인해 치명적인 결과를 발생시킬 수 있으므로 사용을 되도록이면 자제해야 한다.
-
→ 그러므로 Cascade의 구체적인 타입은 명시적으로, 한정적으로 결정해 주는 것이 바람직하다. 예를 들어 부모가 삭제되면 자식이 삭제되는 기능만 활성화되는 것을 원한다면, 예시와 같이 지정할 수 있을 것이다.
- orphanRemoval: true 시 부모-자식으로 연결된 관계에서 자식이 부모를 잃는, 즉 고아 객체가 감지될 때 이를 DB에서 삭제해주는 기능
- 따라서 부모 Entity 삭제 상황 시 REMOVE 옵션과 동일한 기능을 해낸다. (부모가 소멸되면 자식은 부모를 잃은 것이므로)
@Entity
public class Article {
@Id @GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "article_id")
private Long id;
private String title;
**@ManyToOne(fetch = FetchType.LAZY)**
**@JoinColumn(name = "user_id")**
private User user;-
지연 로딩(fetch = FetchType.LAZY) (vs EAGER)
- EAGER: 게시물이 DB 상에서 불러와질 때, 게시물의 주인인 user까지 함께 불러온다.
- LAZY: getUser() 메서드를 직접 콜하기 전까지는 user를 불러오지 않는다.
- 주인에 접근할 필요가 없다면 LAZY가 바람직하다.
-
JoinColumn(name = “user_id”): DB 테이블 상에는 주인의 PK가 이 필드에 저장되며, user 테이블의 PK의 별명인 user_id를 자신의 주인으로 인식하게 된다.
주의: 다대다 관계?
- 유저는 여러 게시물에 좋아요를 누를 수 있다.
- 게시물은 여러 유저에게 좋아요를 받을 수 있다.
- 이 경우 @ManyToMany를 통해 좋아요 객체를 생성하기보다, 별도의 좋아요 객체를 생성하는 것이 바람직하다.
@Entity
public class Likes {
@Id
@Column(name = "likes_id")
private Long id;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "article_id")
private Article article;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "user_id")
private User user;
@CreatedDate
private LocalDateTime createdAt;- Likes 객체는 게시물, 유저와 다대일 관계
- @CreatedDate: 생성 일시 속성의 경우 객체 생성 시 별도의 값 지정 없이 자동으로 생성한다.
- 이를 통해 다대다 관계를 안정적으로 해소하고, 생성일시 등의 속성을 추가로 기입할 수 있게 된다.
- 보니까 PK 속성을 해낼 수 있는 게 [유저id, 게시물id] 두개인거같은데 그냥 복합키 쓰면 안되나요?
- 가능
- 다만 스프링 초기 시점에서 복합키를 능숙하게 다루기는 어려울 것임
Repository
public interface UserRepository extends JpaRepository<User, Long> {
}- Springboot DAO(Data Acccess Object)의 일종
- 서버 최후방에서 DB에 접근하여 CRUD 역할을 수행
- 왜 interface인가요?
- 구현체는 JPA에서 동적으로 생성해주기 때문
- <User, Long>으로 대표되는 Entity-PK 타입을 작성해준다면, 기본적으로 사용하는 다양한 쿼리를 직접 만들어준다.
- 다만 User의 다른 필드를 기반으로 CRUD 메서드를 활용하고자 한다면, 직접 원하는 메서드를 선언해 두면 이 역시 JPA가 자동으로 만들어준다.
public interface FoodRepository extends JpaRepository<Food, Long> {
boolean existsByIdAndUserId(Long id, Long userId); // 유저가 먹은 음식인지 확인
List<Food> findAllByUserIdAndDate(Long userId, LocalDate date); //유저가 특정 날짜에 먹은 음식 반환
List<Food> findAllByUserIdAndDateBetween(Long userId, LocalDate startDate, LocalDate endDate); // 유저가 특정 기간 내에 먹은 음식 반환
}주요 메서드
- existsById: 주어진 Id에 해당하는 엔티티가 존재하는 여부를 확인하며 true/false를 반환한다.
- findById: 주어진 Id에 해당하는 엔티티를 가져온다. 만약 존재하지 않으면 Optional.empty()를 반환하고, Service에서 이와 관련된 예외처리 로직을 orElseThrow() 등을 사용하여 작성한다.
- findAll(By): 모든 엔티티를 가져온다. 기본적으로 List 형태로 반환되나 아래처럼 Page 형태로도 가능하다.
- count(): Entity의 총 개수를 반환한다.
- deleteById: 주어진 Id에 해당하는 엔티티를 삭제한다.
- delete: 주어진 엔티티를 삭제한다.
- deleteAll: 모든 엔티티를 삭제한다.
- save: 주어진 엔티티를 저장한다. 이미 엔티티의 id가 존재한다면 저장이 아닌 수정이 이루어진다.
N + 1 문제?
- Springboot JPA를 쓰면 항상 면접장에서 듣는 단골 질문!
- 1개의 쿼리를 사용할 목적으로 작성했으나 실제로는 N개의 쿼리가 추가적으로 생성되는 문제
- 당연히 N이 커지면 시간이 오래 걸릴 것이고 서버의 부담이 가중
- 예를 들어, 유저가 작성한 게시물 조회 기능을 구현한다면 우리는 DB 쿼리의 JOIN 연산을 사용하여 하나의 쿼리로 처리하기를 기대하지만, 실제로는 N개의 게시글을 추가로 조회하는 쿼리가 발생하는 문제가 대표적
- 지연로딩을 도입하면 첫 쿼리를 사용하는 순간에는 추가적인 N개의 쿼리가 발생하진 않지만, 마찬가지로 게시물에 접근하는 순간에는 N개의 쿼리가 필연적으로 발생
- 결국 Repository 상에 직접 JOIN 연산 쿼리를 작성하는 등의 대책이 필요
public interface FollowRepository extends JpaRepository<Follow, Follow.PK> {
@Query(value = "select u from Follow f INNER JOIN User u ON f.toUser = u.id where f.fromUser = :userId") // 팔로잉 목록 조회
List<User> findAllByFromUser(@Param("userId") Long userId);
}요약
Domain Model (JPA Entity)
- 생성자보단 빌더패턴이나 정적 팩토리 생성메서드로 (생성메서드 시 생성자는 protected로)
- @Setter 어노테이션은 가급적 피하고 반드시 필요한 필드만 public void setId() 등으로 직접 구현
- @ManyToOne은 항상 지연로딩(FetchType.LAZY) 표기
- 다대다 관계는 중간테이블을 두어 해소 (@ManyToMany 지양)
- 생성 일시는 @CreatedDate로 간소화
- Cascade 옵션은 ALL보다는 PERSIST/REMOVE 등으로 구체적으로 표기
- 단일 부모-자식 관계의 두 Entity에서, 자식 고아객체가 소멸해야하면 orphanRemoval 도입
Repository
- JpaRepository<Entity, PK>를 상속받은 인터페이스로 생성한다.
- 기본적으로 PK를 활용한 CRUD를 구현체에 자체적으로 만들어지나, 그렇지 않은 경우 직접 원하는 메서드를 선언하여 사용하면 된다.
- 문법이나 표현이 틀리면 무조건 에러가 발생하기에, 구글링이나 GPT 등을 통해 검증하도록 하자.
