11/19
1. JVM 에서의 autoboxing 이란 어떤 현상을 말하는 걸까요?
-
primitive Data
- boolean, char, byte, short, int, long, float, double - 아주 가벼운 데이터를 말한다. - 스택메모리에 머물러있다. -
Object Data
- 상대적으로 무거운 데이터이다. - 실제 데이터는 힙메모리에 공유하고 레퍼런스만 스택메모리에 있다. -
Wrapper Class
- primitive Data를 ObjectData화 시킨 Class이다.
💡 primitive Data 에서 Wrapper Class로 자동으로 변환되는걸 autoboxing이라 한다.
💡 Wrapper Class에서 primitive Data 자동으로 변환되는걸 unboxing이라 한다.
- 오토박싱은 제네릭 컬렉션에 값을 추가하는 경우 유용
- Integer 타입의 ArrayList에 원시 타입인 int 타입의 값을 할당
- Integer 타입의 ArrayList에서 첫 번째 요소를 int 타입의 변수에 할당합니다.
public class Main {
public static void main(String args[]) {
ArrayList<Integer> intArrayList = new ArrayList<>();
// 오토박싱
intArrayList.add(10);
System.out.println("intArrayList: " + intArrayList);
// 언박싱
int num = intArrayList.get(0);
System.out.println("num: " + num);
}
}🚫문제점
- 오토박싱은 코드에서 보이지 않지만 래퍼 클래스 객체에 값을 할당하기 위해 객체를 생성. 편리한 기능이지만 성능이 저하되는 문제가 존재하므로 반복문에서 오토박싱을 사용하는 것은 좋은 소스코드가 아니다.
private static long sum_with_autoboxing() {
Long sum = 0L;
for (long i = 0; i < Integer.MAX_VALUE; ++i) {
sum += i;
}
return sum;
}sum += i -> sum += Long.valueOf(i); 로 바꾸게 된다.
매번 새로운 객체 생성2. interface default implementation 이란? abstract class 를 상속받는 것과 기본 구현을 들고 있는 interface 를 implements 하는것은 어떤 차이가 있나요?
-
추상 클래스 vs 인터페이스
디폴트 메소드의 도움으로 인터페이스는 추상 클래스(abstract)와 차이가 없어보입니다. 하지만 실제로 다음과 같은 차이가 있습니다.
- 추상 클래스, 인터페이스 둘 다 객체로 만들 수 없다는 공통점이 있습니다. extends하거나 implements해야 합니다.
- 추상 클래스에는 public, protected, private 메소드를 가질 수 있습니다. 반면에 인터페이스는 public만 허용됩니다.
- 추상 클래스에는 멤버변수 선언이 가능하지만 인터페이스는 public static 변수만 선언이 가능합니다.
- 인터페이스는 implements 키워드로 여러 인터페이스를 구현할 수 있습니다. 반면에 추상클래스는 extends 키워드로 1개의 클래스만 상속받을 수 있습니다.
-
우선순위( 같은 이름의 메소드를 사용할때 )
- 클래스가 두개의 인터페이스를 implements 했을
-> 컴파일 에러 , 오버라이딩 필요 - 클래스가 extends와 implements 했을 때
-> 자바는 다중상속을 지원하지 않고 extends와 implements를 다르게 처리. 컴파일러는 충돌이 발생할 때 extends한 클래스의 우선순위가 더 높아, 이 클래스의 디폴트 메소드를 상속
- 클래스가 두개의 인터페이스를 implements 했을
3. Java stream method 중 map 과 flatMap 의 차이에 대해 설명해주세요
-
map은 스트림 내부의 요소 하나하나에 접근해서 제가 파라미터로 넣어준 함수를 실행한 뒤 최종연산에서 지정한 형식으로 반환해주는 메서드 입니다.
-
flatMap을 사용하면 중복 구조로 되어있는 리스트를 하나의 스트림처럼 다룰 수 있습니다.
예시)
animal = ["cat","dog"]
->원하는 결과 = [ "c", "a", "t", "d", "o", "g" ]
List<String[]> results = animals.stream().map(animal -> animal.split(""))
.collect(Collectors.toList());
// 결과 = [ [ "c", "a", "t" ] , [ "d", "o", "g" ] ]
List<String> results = animals.stream().map(animal -> animal.split(""))
.flatMap(Arrays::stream)
.collect(Collectors.toList());
// 결과 = [ "c", "a", "t", "d", "o", "g" ]
Arrays::stream은 배열을 스트림으로 변환해주는 메서드 참조 표현
4. 메소드에서 리스트 타입의 파라미터를 받을 때, ArrayList - List - Collection - Iterable 처럼 구체 타입 뿐 아니라 상위 타입도 받을 수 있습니다. 컬렉션을 받는 어떤 API 를 구현하실 때 구체 타입의 API 디자인을 선호하는지, 추상 타입의 API 디자인을 선호하는지를 설명해 주세요. 왜 그런 선택을 하시나요?
구체 타입 : 자식메서드를 사용할수 있다.
추상 타입 : 다형성을 이용할수 있다.
5. Java 의 equals 와 == 의 차이에 대해 설명해주세요. Kotlin 의 == 와 === 는 어떤 차이가 있나요?
- equals() 는 객체간의 값(value)을 비교할 수 있고, == 은 대상의 주소(reference)를 비교합니다.
6. 스프링의 @Autowired 를 가급적 쓰지 말라는 이야기가 종종 들리는데 원인이 뭘까요?
생성자 주입
- 필드 주입의 단점
- 필드 주입으로 객체를 주입하면 외부에서 수정이 불가능하고, 이러한 이유 때문에 테스트 코드를 작성할 때 객체를 수정불가
- 필드 주입은 반드시 Spring 같은 DI를 지원하는 프레임워크가 있어야 사용
- 수정자 주입의 단점
- Setter의 경우 public으로 구현하기 때문에, 관계를 주입받는 객체의 변경 가능성을 열어둠
- 테스트 코드 작성의 편리함
- Spring 같은 DI 프레임워크 위에서 동작하지만, 테스트 코드는 그러지 않아서 의존관계 주입이 정상적으로 되지 않아 null상태여서 NullPointError가 발생
- 순환 참조 방지
- 필드주입은 순환참조 발생시 StackOverFlow에러가 나서 애플리케이션이 다운(애플리케이션이 실행 중에 발생)
- 생성자 주입 = 컴파일 에러
- 개발자의 의존성 주입 실수 방지 (final 키워드 VS 수정자 주입)
https://programforlife.tistory.com/111
7. final 키워드를 변수, 메소드, 클래스에 선언하는 것은 어떤 의미가 있습니까?
개발자가 final 키워드를 사용한 코드 ( 고정되여야 하는 것 ) 를 변경하려할때 컴파일 에러를 통해 변경을 막을수 있다
- final variables, arguments : 값이 변경되지 않도록 만듬
- final class : 클래스를 상속하지 못하도록 만듬
- final method : 메소드가 오버라이드되지 못하도록 만듬
8. synchronized 를 메소드에 선언하는 것과, 특정 객체에 선언하는 것은 어떤 차이가 있습니까?
synchronized 메소드는 synchronized(this) {} 블럭과 같다고 생각하면 되며, 현재 인스턴스에 대해서 락을 획득한다.
만약 2개 이상의 인스턴스가 있다면 각각의 인스턴스에 대해 모니터락이 걸린 것이므로, 두 개의 인스턴스가 각각의 method를 실행하는 것이 가능하다.
해당 메서드 락을 획득하고 나서 메서드 블록을 벗어나면 락을 반납한다.
//둘 클래스는 같은 거임
public class SynchronizedTest {
public synchronized void a() {... }
public synchronized void b() {... }
}
public class SynchronizedTest {
public static void a() {
synchronized(this) {... }
}
public static void b() {
synchronized(this) {... }
}
}synchronized를 특정 객체에 선언하는 것은 synchronized 블록을 사용하는 것이다. synchronized 메서드는 현재 객체 자체에 락을 거는 것이지만, synchronized 블록은 특정 객체에만 락을 걸어서 최소한의 필요한 영역에만 락을 걸 수 있다. lock 블록의 범위를 줄인 것이기 때문에 동시성을 향상시킬 수 있다.
9.Reflection 을 유용하게 사용하는 사례를 말씀해 주세요
💡Reflection : class타입 객체 생성 후 힙 영역에 저장
- 장점
- 런타임 시점 인스턴스 생성 후 접근제어자에 관계없이 작업 수행가능
- 단점
- 캡슐화에 위배된다.
- 런타임 동작 - > 컴파일러 에러가 없다.
💡사용
- 빈등록시 빈팩토리에 직접 등록하지 않아도 어노테이션으로 접근제어자에 관계 없이 등록가능
10. JDK/JVM 은 대표적으로 OpenJDK 와 Oracle JDK 로 나뉘는데요, 업무에 어떤 JDK 를 사용하시겠습니까? 선택의 이유를 말씀해 주세요.
11. hashCode / equals 메소드의 역할에 대해 아시는 내용을 최대한 설명해주세요.
- == : 주소값만으로만 비교
- equals : 논리적동등비교 ( 재정의 가능 )
- hashcode : 객체의 메모리 번지를 이용하여 생성
- 다른 객체라도 해쉬값이 같을 수 있다
- java8인가 9버전부터 LinkedList 아이템의 갯수가 8개 이상으로 넘어가면 TreeMap 자료구조로 저장된다
💡hash컬랙션비교 과정
1. 해쉬값 비교
2. 해쉬값이 동일하다면 equals 메소드 이용
- set이 중복이 없는 이유 -> 해쉬테이블을 이용한 빠른검색을 이용한 중복제거
- HashTable에 put 메서드로 객체를 추가하는 경우
- 값이 같은 객체가 이미 있다면(equals()가 true) 기존 객체를 덮어쓴다.
- 값이 같은 객체가 없다면(equals()가 false) 해당 entry를 LinkedList에 추가한다.
12. Java 의 Collections.unmodifiableList 같은 API 를 이용해 List 같은 collection 을 변경 불가능하게 만들 수 있습니다. 그렇다면 이 API 를 사용하면 immutability 를 달성할 수 있을까요?
💡불변객체 : 불변객체는 재할당은 가능하지만, 한번 할당하면 내부 데이터를 변경할 수 없는 객체
- 불변객체는 참조타입일경우 내부 변수도 불변이여야 한다. 객체 자체는 변경이 일어날수 없지만 접근은 가능하기 때문에 내부 변수또한 통제하여야 한다.
public class Animal {
private final Age age;
public Animal(final Age age) {
this.age = age;
}
public Age getAge() {
return age;
}
}
class Age {
private int value;
public Age(final int value) {
this.value = value;
}
public void setValue(final int value) {
this.value = value;
}
public int getValue() {
return value;
}
}Animal 클래스는 final을 사용하고, Setter를 구현하지 않았지만 불변객체가 될 수 없습니다. 왜냐하면 Animal 클래스의 필드인 Age의 값을 아래처럼 변경할 수 있기 때문입니다.
public static void main(String[] args) {
Age age = new Age(1);
Animal animal = new Animal(age);
System.out.println(animal.getAge().getValue());
// Output: 1
animal.getAge().setValue(10);
System.out.println(animal.getAge().getValue());
// Output: 10
}https://velog.io/@conatuseus/Java-Immutable-Object%EB%B6%88%EB%B3%80%EA%B0%9D%EC%B2%B4
13. 다음 싱글턴 코드의 어떤 점을 개선하실 수 있습니까? (개선이 필요 없을 수도 있음 / 왜?)
class MySingleton {
private static MySingleton instance;
public static synchronized MySingleton getInstance() {
if (instance == null) {
instance = new MySingleton();
}
return instance;
}
}
- synchronized 키워드 자체에 대한 비용이 크기 때문에 싱글톤 인스턴스 호출이 잦은 어플리케이션에서는 성능이 떨어지게 됩니다.
public class Singleton {
private volatile static Singleton instance;
private Sigleton() {}
// Lazy Initialization. DCL
public Singleton getInstance() {
if(instance == null) {
synchronized(Singleton.class) {
if(instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}- 인스턴스가 생성되어 있지 않은 시점에만 synchronized가 실행되게끔 구현
- volatile 키워드를 사용하면 멀티스레드 환경에서도 객체가 Sigleton 인스턴스로 초기화 되는 과정이 올바르게 진행되도록 할 수 있습니다.
https://ttl-blog.tistory.com/89
14. java 9 이상에 도입된 추가 기능들 중 마음에 드는거 아무거나 하나만 설명해주세요.
https://velog.io/@ljo_0920/java-%EB%B2%84%EC%A0%84%EB%B3%84-%EC%B0%A8%EC%9D%B4-%ED%8A%B9%EC%A7%95
15. 민감한 정보를 String 으로 저장하는 것과, char[] 또는 StringBuilder/StringBuffer 같은 클래스로 저장하는 것은 어떤 차이가 있나요?
💡String
- String은 불변(immutable)의 속성
- 문자열 추가,수정,삭제 등의 연산이 빈번하게 발생하는 알고리즘에 String 클래스를 사용하면 힙 메모리(Heap)에 많은 임시 가비지(Garbage)가 생성되어 힙메모리가 부족으로 어플리케이션 성능에 치명적인 영향
💡StringBuffer
- StringBuffer는 동기화 키워드를 지원하여 멀티쓰레드 환경에서 안전(thread-safe)
💡StringBuilder
- StringBuilder는 동기화를 지원하지 않기때문에 멀티쓰레드 환경에서 사용하는 것은 적합하지 않지만 동기화를 고려하지 않는 만큼 단일쓰레드에서의 성능은 StringBuffer 보다 뛰어납니다.
-
정리
마지막으로 각 클래스별 특징을 정리해 보겠습니다. 컴파일러에서 분석 할때 최적화에 따라 다른 성능이 나올 수도 있지만 일반적인 경우에는 아래와 같은 경우에 맞게 사용하시면 될 것 같네요.- String : 문자열 연산이 적고 멀티쓰레드 환경일 경우
- StringBuffer : 문자열 연산이 많고 멀티쓰레드 환경일 경우
- StringBuilder : 문자열 연산이 많고 단일쓰레드이거나 동기화를 고려하지 않아도 되는 경우
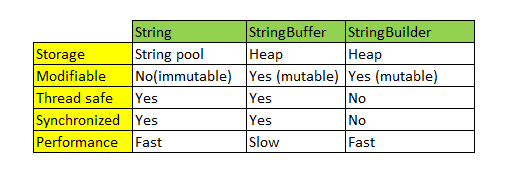
16. 크기를 지정하지 않고 ArrayList 를 new 로 생성하면 크기 10의 ArrayList 가 생성됩니다. Array 는 크기를 넘길 수 없는데 반해 ArrayList 는 꽉 찬 List 에 element 를 추가로 더할 수 있습니다. 그렇다면 10개의 element 를 채워넣은 ArrayList 의 11번째 element 을 add 하기위해 어떤 일이 일어나는지 설명해주세요.
-
ArrayList의 구현코드를 보면서 add 메서드를 따라가보았다. 참 재밌는 일이 벌어진다.
결론부터 말하자면 ArrayList는 배열이다 -
new ArrayList(); 가 호출이 되면 빈 Object 배열 객체가 elementData에 할당이 된다. size는 주석의 설명대로 ArrayList의 크기이다.
-
add가 호출이되면 또 다른 오버로딩된 add를 호출한다. 넣을 element 와 가지고 있는 element 배열 그리고 size를 넘겨준다. 현재 사이즈가 배열의 길이와 같다면 grow 함수를 호출 그렇지 않다면 해당 인덱스에 값 저장 후에 사이즈를 늘려준다.
-
grow 메서드에서는 size+1을 파라미터로 넘겨준다. 이제 이 값을 minCapacity로 받아 Arrays.java 의 copyOf 메서드를 호출한다. 그 전에 minCapacity를 newCapacity를 거치게 하는데, 여러 조건들이 붙지만 이것도 간단히 살펴보면 이전 elementData의 길이에 해당 길이의 반을 더한 길이를 리턴해준다. 근데 이 값이 minCapacity 보다 작다면 minCapacity 값을 리턴한다(2개의 조건이 더 있지만 코드를 직접 보길 바란다).
-
이제 copyOf 에서 현재 배열, 새로운 길이, 배열의 클래스 정보를 또 다른 copyOf에 넘긴다.
넘긴 배열이 Object 배열 클래스 정보와 같으면 해당 길이의 Object 배열을 copy 변수에 초기화 그렇지 않다면 새로운 타입의 배열을 저장한다. 이후 arraycopy를 이용해 기존의 배열의 copy에 앞에서부터 복사하고 이 배열을 리턴해주는 형식이다.
//ArrayList.java 내의 코드
/**
* Shared empty array instance used for default sized empty instances. We
* distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when
* first element is added.
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* Constructs an empty list with an initial capacity of ten.
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
*
* @serial
*/
private int size;
public boolean add(E e) {
modCount++;
add(e, elementData, size);
return true;
}
private void add(E e, Object[] elementData, int s) {
if (s == elementData.length)
elementData = grow();
elementData[s] = e;
size = s + 1;
}
private Object[] grow() {
return grow(size + 1);
}
private Object[] grow(int minCapacity) {
return elementData = Arrays.copyOf(elementData,
newCapacity(minCapacity));
}
private int newCapacity(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity <= 0) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
return Math.max(DEFAULT_CAPACITY, minCapacity);
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return minCapacity;
}
return (newCapacity - MAX_ARRAY_SIZE <= 0)
? newCapacity
: hugeCapacity(minCapacity);
}
//Arrays.java 내의 코드
public static <T> T[] copyOf(T[] original, int newLength) {
return (T[]) copyOf(original, newLength, original.getClass());
}
@HotSpotIntrinsicCandidate
public static <T,U> T[] copyOf(U[] original, int newLength, Class<? extends T[]> newType) {
@SuppressWarnings("unchecked")
T[] copy = ((Object)newType == (Object)Object[].class)
? (T[]) new Object[newLength]
: (T[]) Array.newInstance(newType.getComponentType(), newLength);
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
17. java.lang.String 의 hashCode 구현에 대해 고찰해 봅시다. 왜 그런 구현일지, 문제점은 없을지 이야기해주세요.
String 클래스는 아래와 같이 모든 문자에 대한 해시 함수를 계산하는 게 아니였다.
skip을 통해 일정 간격의 문자를 건너가면서 해시 함수를 계산했다.
아래 코드를 보면 문자열의 길이가 16을 넘으면 최소 하나의 문자가 건너뛰어지며 해시 함수가 계산된다.
public int hashCode() {
int hash = 0;
int skip = Math.max(1, length() / 8);
for (int i = 0; i < length(): i+= skip)
hash = s[i] + (37 * hash);
return hash;
}
이 방식은 심각한 문제를 얘기한다. 웹상의 URL은 앞부분이 동일한 경우가 많은데 서로 다른 URL에 대해서 동일한 해시 값이 나오는 문제가 생겼기 때문이다. HashSet, HashMap과 같이 HashCode를 사용하여 해시 버킷에 데이터를 저장할 때 중복되는 hashCode는 해시 버킷에 데이터를 LinkedList 형식으로 연결해서 저장하기 때문에 hashCode가 중복될 수록 성능에 영향을 준다.
Java 8에서는 String 클래스의 hashCode 메서드에도 성능 향상을 위해 31을 사용한다. 이 방식은 연산을 빠르게 처리할 수 있다. 31 * N = 32N - N으로서 32는 2^5이니 어떤 수 N에 대해 32를 곱한 값은 시프트연산으로 쉽게 구현할 수 있다. 따라서 N에 31을 곱한 값은 (N << 5) - N이다. 31을 곱하면 이렇게 쉬프트 연산을 통해 빠른 계산이 가능하기 때문에 31을 사용한다.
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}hashCode 자체가 고르게 사용되고 빠른 계산이 가능하더라도
실제 HashMap, HashSet에서의 해시 버킷의 개수 M은 2^a의 형태가 되기 때문에
해시 버킷 index = x.hashCode() % M을 계싼할 때 x.hashCode()의 하위 a개의 비트만 사용하게 된다. 즉, hashCode가 아무리 고르게 분포되도 해시 값을 2의 승수로 나누면 해시 충돌이 발생할 수 있다.
18. lambda 와 메소드 1개만 있는 익명 클래스 직접 선언은 문법적 차이 외에 어떤 내부적인 차이가 있을까요?
-
공통점
- 익명클래스나 람다가 선언되어 있는 바깥 클래스의 멤버 변수나 메서드에 접근할수 있습니다.
- 하지만 멤버 변수나 메서드의 매개변수에 접근하기 위해서는 해당 변수들이 final의 특성을 가지고 있어야 합니다.
- 이 말은 final로 선언하지 않았더라도 변수를 변경하지 않으면 실질적으로 final과 같기때문에 final 선언을 생략할수 있음을 말합니다.
-
차이점
- 익명클래스와 람다에서의 this의 의미는 다르다!
- 익명클래스의 this는 익명클래스 자신을 가리키지만 람다에서의 this는 선언된 클래스를 가리킵니다.
- 람다는 은닉 변수(Shadow Variable)을 허용하지 않는다!
- 익명 클래스는 변수를 선언하여 사용할 수 있지만 람다는 이를 허용하지 않습니다.
- 람다는 인터페이스에 반드시 하나의 메서드만 가지고 있어야 한다!
- 인터페이스에 @FunctionalInterface 어노테이션을 붙이면 두개 이상의 추상 메서드가 선언되었을 경우 컴파일 에러를 발생시킨다.
- 익명클래스는 함수를 명시할수 있기 때문에 상관없음
- 람다는 하기와 같이, 같은 시그니처를 가지는 인터페이스에 대하여 의미가 모호해 집니다!
interface Hello {
void print();
}
interface World {
void print();
}
public static void action(Hello hello) {
hello.print();
}
public static void action(World world) {
world.print();
}
public void foo() {
// 익명클래스는 다음과 같이 타입이 지정되어 의미가 분명함
action(new Hello() {
public void print() {
System.out.println("Hello");
}
});
// 람다는 Hello 객체인지 World 객체인지 불분명함
action(()-> System.out.println("Hello"));
// 다음과 같이 타입을 지정해 주어야 함
action((Hello) () -> System.out.println("Hello"));
}19. Java generics 에는 primitive type 을 쓸 수 없는 문제가 있습니다. 왜 그럴까요? 어떻게 해결할 수 있을까요?
Generic Type으로 Primitie Type을 사용할 수 없다.
Generic이 Compile Time 특성이고 Type 제거라는 특성을 통해 Object로 변할 수 있다.
하지만 Primitive Type은 Object를 상속받은 게 아니기 때문에 불가능하다.
대신 Wrapper Class를 활용하여 해결이 가능하다.
// 불가능!!!
List<int> list = new ArrayList<>();
list.add(17);
// Wrapper Class로 대체, 가능!!!
List<Integer> list = new ArrayList<>();
list.add(17);20. I/O 를 Java nio 로 코딩할 때 주의점은 어떤게 있을까요?
NIO는 연결 클라이언트 수가 많고 하나의 입출력 처리 작업이 오래걸리지 않는 경우에 사용하는 것이 좋음, 스레드에서 입출력 처리가 오래 걸린다면 대기하는 작업의 수가 늘어나므로 제한된 스레드로
처리하는 것이 불편할 수 있음. 대용량의 데이터 처리의 경우 IO가 좋다. NIO는 버퍼 할당 크기가 문제가 되고, 모든 입출력 작업에 버퍼를 무조건 사용해야 하므로 즉시 처리하는 IO보다 조금 더 복잡.
연결 클라이언트 수가 적고 전송되는 데이터가 대용량이면서 순차적으로 처리될 필요성이 있는 경우
IO로 서버를 구현하는 것이 좋음.
https://velog.io/@alsgus92/JAVA-IO-vs-NIO
21. Java 는 Pure OOP 언어가 아니라고 하는데, 왜 그런 걸까요?
💡pure OOP의 조건
1. Encapsulation/Data Hiding 캡슐화/은닉화
2. Inheritance 상속
3. Polymorphism 다형성
4. Abstraction 추상화
5. All predefined types are objects 이미 작성된 타입이 모두 객체
6. All user defined types are objects 사용자가 작성하는 것도 모두 객체
7. All operations performed on objects must be only through methods exposed at the objects.
모든 연산은 반드시 객체 안에 있는 메소드를 통해
이걸 단적으로 잘 지키는 언어는 Smalltalk라고 할 수 있다.
💡왜 Java는 pure OOP 언어가 아닌가?
Java는 위 조건들 중 5번과 7번을 충족시키지 못한다.
- Primitive Data Type의 존재
Java에서는 int, long, bool, float, double, char 등과 같은 기본형 자료 타입이 버젓이 존재하고, 이는 객체로 표현되지 않았다.
pure OOP 언어인 Smalltalk에서는 실제로 기본형 타입들도 object(객체)로 표현해두었다.
- static keyword의 존재
우리가 class를 static으로 선언하면 그것은 object로써 쓰이지 않을 수도 있다.
예를 들어, static function이나 static variable에는 class에 dot(.)을 붙여 인스턴스 없이 바로 접근할 수 있다. 이런 점이 pure OOP 스럽지 않다고 할 수 있다.
- Wrapper Class의 한계
우리가 Wrapper Class로 선언한 Integer 인스턴스를 가지고 자유롭게 (int의 도움 없이) 사칙연산을 할 수 있지 않다.
public class BoxingExample {
public static void main(String[] args) {
Integer i = new Integer(10);
Integer j = new Integer(20);
Integer k = new Integer(i.intValue() + j.intValue());
System.out.println("Output: "+ k);
}
}위 코드의 문제점
Integer 인스턴스를 만들 때 사용되는 10, 20이 Java에게는 int형이다.
덧셈을 할 때도 바로 할 수 없고 .intValue()를 통해 int형으로 변환하여 사용
wrapper class와 Primitive Data Type의 존재 이유
.효율성을 위해서라고 한다. Primitive Type의 변수는 값을 직접 포함한다. 참조형 타입의 변수는 메모리 내의 다른 곳에 저장된 객체를 참조하는 참조이다.
Wrapper Type의 값을 사용해야 할 때마다 JVM은 객체를 메모리에서 찾아 값을 가져와야 한다. 반면에 값이 포함된 객체에 대한 참조 대신 변수 자체에 값이 포함되어 있는 Primitive Type에는 메모리에 접근할 필요가 없다.
객체인 Wrapper는 힙 영역에 저장된다. Primitive는 단지 "값"이기 때문에 스택 영역에 들어간다. 힙의 래핑된 Primitive의 경우 스택에 있는 값과 Wrapper 객체에 대한 참조가 둘 다 필요하기 때문에 더 효율적이다.
22. java.lang.String 의 length 메소드는 정확한 결과를 반환하지 않는 경우가 종종 있습니다. 정확한 의 의미란 무엇이고, 왜 그럴까요?
23. Maven 이나 Gradle 이, 의존성 선언한 artifact 들을 찾는 과정에 대해 설명해주세요.
24. java.util.Property extends Hashtable, java.util.Stack extends Vector 같은 클래스는 상속으로 망한 대표 사례입니다. 이유를 설명해 주세요.
- 상속을 통해 하위클래스의 캡슐화를 깨트리기 때문이다.
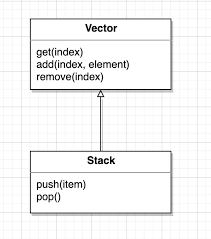
- Stack이 Vectort를 상속받기 때문에 Stack의 퍼블릭 인터페이스에 Vector의 퍼블릭 인터페이스가 합쳐진다. 즉, Stack이 상속받은 퍼블릭 인터페이스를 통해서 임의의 위치에 요소를 추가/삭제할 수 있어 Stack 규칙을 쉽게 위반
25. Spring boot 가 stereotype annotation 을 붙인 클래스들을 어떻게 찾고 bean 으로 등록하는지 그 과정을 최대한 상세하게 설명해주세요.
-
스프링/스프링 부트는 @ComponentScan 을 통하여 빈들을 찾고, 등록함.
-
basePackages, basePackageClasses로 스캔 시작할 위치를 지정, 생략시 스캔 위치가 현재 클래스의 패키지로 지정.
-
ComponentScanAnnotationParser가 @ComponentScan를 읽으며 설정 파일 파싱.
-
ComponentScanAnnotationParser는 ClassPathBeanDefinitionScanner 를 호출하며 현재 base package를 기점으로 하위 패키지들을 탐색, 패키지의 모든 파일들의 메타데이터를 확인 & @Component 어노테이션(및 stereo annotation)이 적용된지 확인.
-
이후 매개변수로 넘어온 빈 팩토리(registerBeanDefinition, 레지스터)에 빈 등록.
