1. 컴퓨터는 10진수를 2진수로 바꿔서 계산합니다. 10진수를 2진수로 바꾸는 방법과, 그 반대 방법에 대해 설명해 주시기 바랍니다.
- 10진수 -> 2진수 :
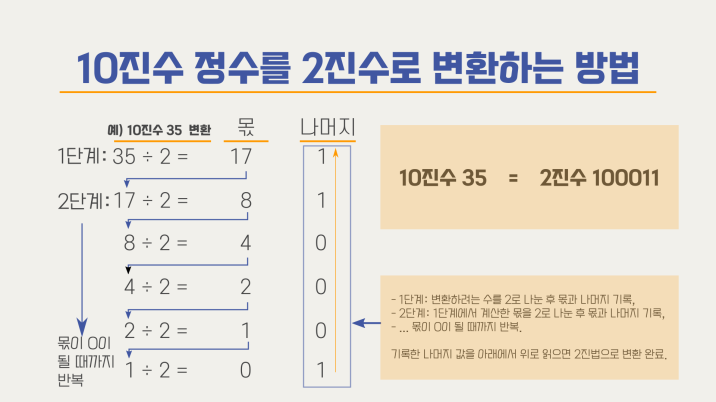
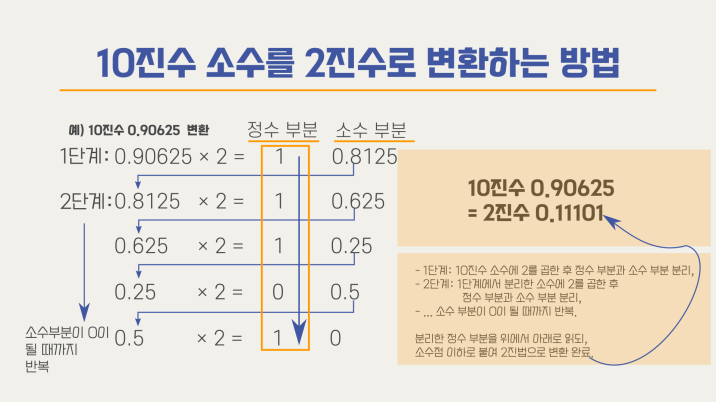
위과정을 몫이 0이 될 때까지 반복.
- 2진수 -> 10진수
2진수 정수 10진수 변환 공식
- x0×b0 + x1×b1 + … + xn-1×bn-1
- 1000112 = 1×20 + 1×21 + 0×22 + 0×23 + 0×4 + 1×25 = 1 + 2 + 32 = 3510
2진수 소수 10진수 변환 공식
- x1×b-1 + x2×b-2 + … + xn×b-n
- 0.111012 = 1×2-1 + 1×2-2 + 1×2-3 + 0×2-4 + 1×2-5 = 1/2 + 1/4 + 1/8 + 1/32 = 0.9062510
2. 컴퓨터는 소숫점 계산을 잘 못합니다. 그 이유가 무엇일까요? 어떻게 문제를 해결할 수 있을까요? 직접 구현한다면 어떻게 하시겠습니까?
10진법에서 유한소수가 2진법에서 무한소수인 경우
대표적인 예가 10진수 0.1 입니다
1/10 이라는 소수의 분모에 어떤 수를 곱하더라도 2의 제곱수를 만들 수 없으므로
10진법 유한소수 0.1은, 2진법에서는 무한소수입니다
BigDecimal을 사용하면 내부적으로 10진수로 저장하기 때문에 현실의 정밀한 값을 표현할 수 있다
3. Thread 간의 데이터 공유와 Process 간의 데이터 공유의 공통점과 차이점
-
프로세스 : 프로그램이 메모리에 올라와 운영체제로부터 CPU를 할당받고 프로그램이 실행되고 있는 상태.
- 각 프로세스는 별도의 주소 공간에서 실행되고 프로세스끼리는 자원을 공유하지 않음
- Code, Data, Stack, Heap 구조로 되어있는 독립된 메모리 영역
- 하나의 프로세스가 다른 프로세스의 자원에 접근하려면 프로세스 간의 통신 필요
(IPC, inter-process communication) Ex. 메일 슬롯, 파이프, 소켓, 시그널, 공유 메모리
-
쓰레드 : 프로세스 내에서 실행되는 흐름의 단위
- 하나의 프로세스 내의 주소 공간이나 자원들 공유
4. 운영체제가 여러 프로그램을 동시에 실행하는 원리에 대해 설명해주세요.
OS는 다중 프로그래밍 환경을 구현하기 위해 컨텍스트 스위칭이라는 기능을 제공합니다. 이는 CPU가 어떤 하나의 프로세스를 실행하고 있는 상태에서 인터럽트 요청에 의해 다음 우선 순위의 프로세스가 실행되어야 할 때 기존의 프로세스의 상태 또는 레지스터 값을 저장하고 CPU가 다음 프로세스를 수행하도록 새로운 프로세스의 상태 또는 레지스터 값을 교체하는 작업을 뜻합니다. 이 작업이 빠르게 일어나면서 실제 여러 프로그램을 사용하는 사용자 입장에서는 동시에 실행하는 것처럼 보이는 것입니다.
가비지 컬렉션(Garbage Collection)이란?
- 가비지 컬렉션은 자바의 메모리 관리 기법이다.
- 힙 메모리에서 동적으로 할당되어 사용 중인 객체와 사용하지 않는 객체를 식별하고 사용하지 않는 개체를 삭제하는 작업을 담당하고 있다.
- C와 같은 프로그래밍 언어는 메모리 할당 및 할당 해제를 수동으로 하지만 Java에서는 이 가비지 컬렉션이 자동으로 처리된다.
JVM 세이프포인트
- 애플리케이션 스레드마다 세이프포인트(안전점, safe point)라는 특별한 지점을 둡니다.
- 세이프포인트는 스레드의 내부 자료 구조가 보이는 지점이며, 이때 어떤 작업을 하기 위해 스레드는 잠시 중단될 수 있습니다.
세이브 포인트 규칙
- JVM은 강제로 스레드를 세이프포인트 상태로 바꿀 수 없습니다.
- JVM은 스레드가 세이프포인트 상태에서 벗어나지 못하게 할 수 있습니다.
따라서 세이프포인트 요청을 받았을 때 그 지점에서 스레드가 제어권을 반납하게 만드는 코드가 VM 인터프리터 구현체 어디에 잇어야합니다. 세이프포인트 상태로 바뀌는 경우는 다음과 같습니다.
- JVM이 전역을 세이프포인트 시간 플래그를 세팅합니다.
- 각 애플리케이션 스레드는 폴링(스레드 할당) 을 하면서 이 플래그가 세팅됐는지 확인합니다.
- 애플리케이션 스레드는 일단 멈췄다가 다시 깨어날 때까지 대기합니다.
- 세이프포인트 시간 플래그를 세팅하면 모든 애플리케이션 스레드는 반드시 멈춰야합니다.
다음의 경우, 스레드는 자동으로 세이프포인트 상태가 됩니다.
- 모니터에서 차단되는 경우
- JNI 코드를 실행하는 경우
다음의 경우, 스레드가 꼭 세이프포인트 상태가 되는 것은 아닙니다.
- 바이트코드를 실행하는 도중(인터프리티드 모드) OS가 인터럽트를 거는 경우
Garbage collection 이 있는 언어를 원자력 발전소, 자동차 동력 제어, 인공위성, 국가 전력망 제어시스템 같은 곳에 쓸 수 있을까요? 후보자님의 생각을 말씀해 주세요.
절대 안됨 Garbage collection은 개발자가 직접 메모리 할당과 해제를 관여하지 않는 대신 stw가 언제 적용될지 알수 없다. 은행이나 전산업무 어플리케이션은 잠깐 기다리면 되지만 전기는 잠깐 기다린다고 공급안하면 중단됨 자동차와같은 운행또한 잠깐 멈추고 대기상태가 되었을때 무슨일이 벌어질지 모른다.
https://www.kernelpanic.kr/32?category=930930
gc가 없는 언어는 어떻게 메모리를 관리하는가?
c 언어
- 스택 : 호출 함수가 종료되면 자동 해제 해당 로컬변수들(검색할 필요가 없음 어플리케이션 중단 x)
크기 제한이 있어 오버플로우 가능
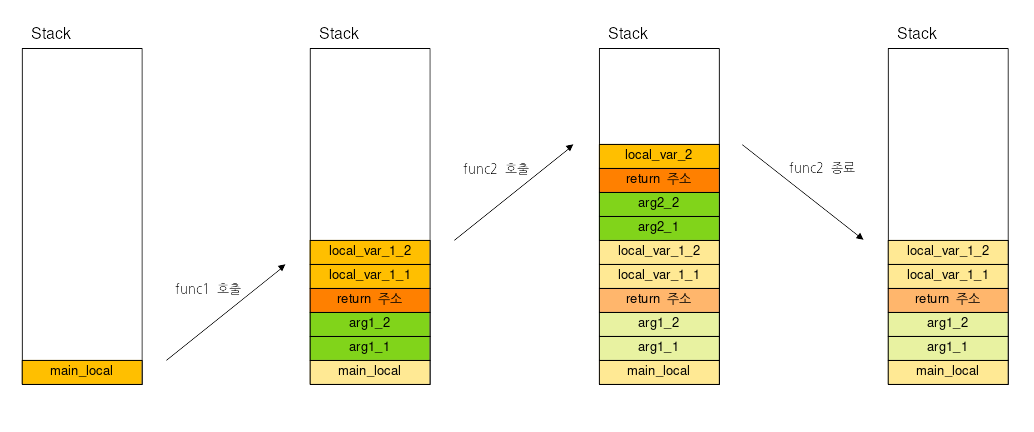
- 힙 (Heap)
힙은 '더미'로 직역된다. 스택이 함수 호출에 따라서 메모리가 차곡차곡 쌓인 모양으로 관리되는 반면, 힙은 이름 그대로 메모리가 힙 영역에 아무렇게나 할당되어 있다. 따라서 힙은 스택과 비교하면 크게는 다음 세가지 특징을 가지고 있다.
- 힙에 저장된 데이터는 함수 호출이 종료되어도 해제되지 않는다. 개발자가 명시적으로 해제하거나, 프로그램이 종료되어야 해제된다.
- 프로그램은 메모리 주소에 따라서 힙 데이터에 접근한다.
- 힙 공간은 크기의 제약이 없다. 메모리가 충분하다면, 힙 영역은 필요한 만큼 확장될 수 있다.
보통 힙에 메모리 할당은 malloc, calloc, realloc 함수를 사용하고, 해제는 free 함수를 사용한다.
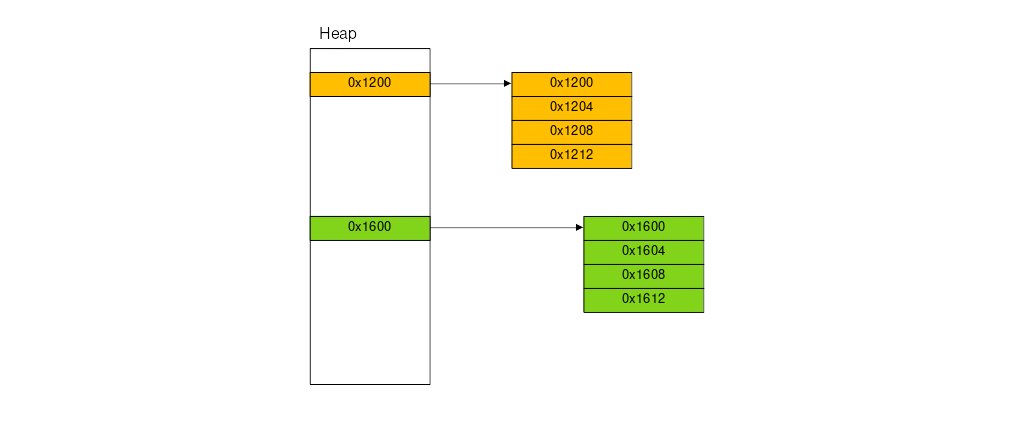
c언어의 메모리 관리
메모리 관리 규칙
1. (규칙1) 가능하다면 메모리 할당과 해제는 한 코드 블록 안에서 한 번만
2. (규칙2) 메모리 할당과 해제가 한 블록 이내에서 이뤄질 수 없다면 레퍼런스 카운트를 활용
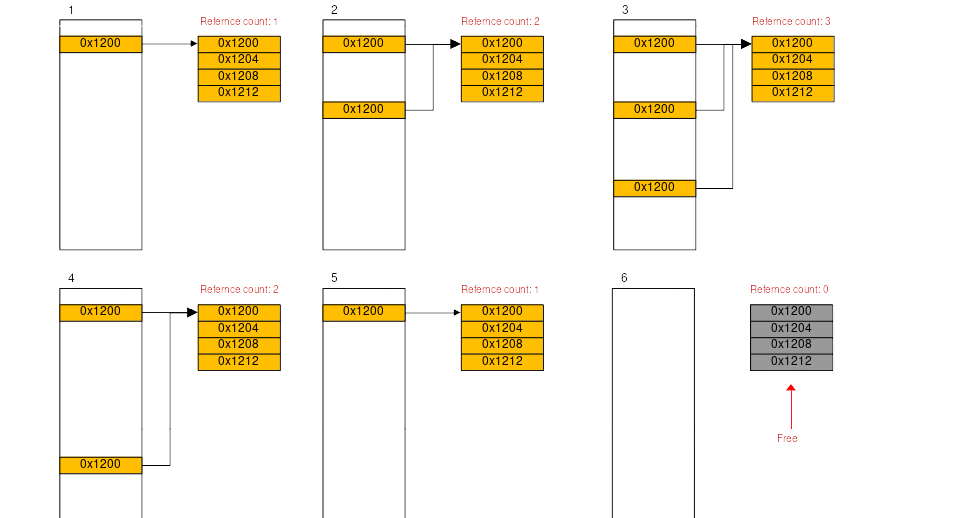
레퍼런스 카운트
c 언어의 경우 rc 레퍼런스 카운트를 활용한다. (하지만 C언어에서는 개발자가 레퍼런스 카운트를 직접 관리해야 한다.)
레퍼런스 카운트는 동적으로 할당된 메모리를 참조하는 객체의 수를 의미한다. 동적으로 할당된 메모리를 특정 객체가 참조하게 되면 레퍼런스 카운트 값을 증가시키고 해당 메모리를 참조하는 객체가 종료되면 레퍼런스 카운트를 감소시킨다. 레퍼런스 카운트 값이 0이 되면 해당 메모리를 해제한다.
레퍼런스 카운트를 활용한 메모리 관리는 원리가 어렵지 않고 구현하기 간단하며 프로세스에 연산 / 메모리 부하를 많이 주지 않는다. 따라서 초기버전의 가비지 컬렉터나 Rust의 Rc/Arc 객체등에 의해서 사용되고 있다.
시스템 콜 이란?
시스템 호출(system call)은 운영 체제의 커널이 제공하는 서비스에 대해, 응용 프로그램의 요청에 따라 커널에 접근하기 위한 인터페이스이다. 고급 언어로 작성된 프로그램들은 직접 시스템 호출을 사용할 수 없기 때문에 고급 API를 통해 시스템 호출에 접근하게 하는 방법이다.
os의 존재 이유
운영체제의 가장 핵심적인 역할 중 하나인 '복잡한 잡일'들은 컴퓨터에서 매우 민감한 자원들을 직접적으로 조작하는 일입니다(사용자가 OS를 건들여서 컴퓨터에 치명적인 오류나 손상을 입히게하는 일을 막기 위해서도 있습니다.)
운영체제는 크게 2가지 모드로 프로세스를 동작시킨다.
- 1 사용자 모드(User mode)
- 2 커널 모드(Kernel mode)
1은 우리가 사용하는 대부분의 프로그램들이 동작하는 모드이다. 2는 운영체제 내부의 커널이 관리하는 프로세스의 모드이다.
사용자 모드가 커널 영역에 직접 접근하는 것이 아니라 운영체제에게 요청을 하면 해당 처리를 운영체제에 위임을 해서 처리하도록 하였다.
이것이 바로 시스템 콜이다.
우리가 C를 사용하면서 malloc 과 같은 명령어를 수행하면 내부적으로 시스템 콜이 발생해서 운영체제에게 이 요청을 위임한다. 운영체제는 해당 명령어를 해석하고 할당해서 완료가 되면 해당 프로세스에게 알려주고 다시 프로세스는 사용자 모드로 동작한다.
자바의 i/o향상을 위한 운영체제 수준의 기술
- 버퍼(Buffer)
- Scatter/Gather
- 가상메모리(Virtual Memory)
- 메모리 맵 파일
- 파일 락
https://brewagebear.github.io/java-syscall-and-io/
컴파일언어
컴파일 언어는 내가 작성한 소스 코드 전체를 컴퓨터가 알아먹을 수 있는 기계어로 번역한 뒤, 이 번역된 코드를 한번에 실행하는 두 단계를 거쳐 진행된다. 즉 번역과 실행이 완전히 따로 이루어진다는 뜻이다. 번역은 컴파일러를 통해 수행되고, 대표적인 예시로는 C, C++, Go 등이 있다.
- 컴파일은 오래 걸릴 수 있다!
- 이미 컴파일이 된 프로그램이라면? 굉장히 빠른 속도로 실행이 가능하다.
- 운영체제 (OS) 이식성이 낮다.
--- OS마다 실행할 수 있는 기계어가 다른 경우가 있다. 그럼 다른 OS에서 내 실행 파일을 실행시키려면? 이미 만들어둔 실행 파일은 불행히도 실행되지 않는다. 해당 OS에 맞는 컴파일러로 다시 컴파일 해줘야한다.
2. 인터프리터 언어
인터프리터 언어는 소스 코드를 한 줄씩, 번역과 실행을 동시에 진행한다. 번역은 인터프리터를 통해 수행되며, 대표적인 예시로는 Python, R, JavaScript 등이 있다.
- 줄 단위로 번역과 실행을 하기 때문에 실행이 느리다.
- 디버깅이 쉽다! (개발의 편의성)
--- 오류를 발견하면 해당 코드 밑으로는 번역 및 실행을 못하기 때문에 오류 발견이 쉽다.
- 운영체제 이식성이 좋다.
--- OS마다 호환되는 인터프리터만 준비되어 있다면 바로 실행이 가능하다!
그렇다면 자바는 ??
1.컴파일 언어?
Java는 다른 컴파일 언어들이 작동하듯이 컴파일러를 이용해 전체 코드를 한번에 번역한다. 여기서 사용하는 컴파일러를 자바 컴파일러(Java Compiler)라고 하며, 이 자바 컴파일러는 우리가 작성한 Java 코드를 자바 가상 머신(Java Virtual Machine, JVM)이 실행시킬 수 있는 자바 바이트 코드로 번역한다.
2.인터프리터 언어?
하지만 자바 바이트 코드는 자바 가상 머신(JVM)의 자바 인터프리터(Java Interpreter)를 이용해 한 줄씩 실행된다. 조금 더 자세하게 말하자면, 자바 바이트 코드로 작성되어 있는 실행 프로그램을 자바 인터프리터가 한 줄씩 읽으면서 컴퓨터가 이해할 수 있는 2진 코드로 번역한 후 실행시킨다는 뜻이다.
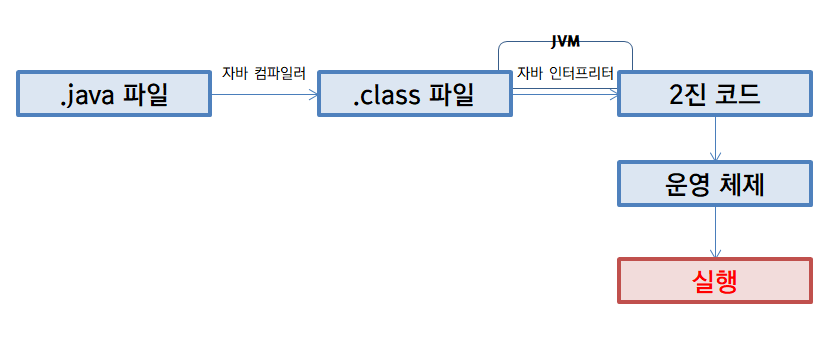
그래서 Java는 하이브리드 언어라는 괴상한 이름으로 불린다. 컴파일 언어와 인터프리터 언어를 혼합한 형태의 언어라는 의미인데, 처음에는 인터프리터 언어로써 사용되다가, 성능 향상을 위하여 컴파일 언어의 장점을 가져왔다고 한다.
https://jooona.tistory.com/157
객체지향 프로그래밍이란?
아래 두 표현을 생각해보면:
-
f(o);
-
o.f();
무엇이 다를까요?
1.번 표현에서는 떠올리지 않는 특별한 의미론적 성질을
2.번 표현에서는 추론해냈기 때문입니다. 그 성질은 바로 다형성입니다.
1.번 표현을 볼 때는 o 라는 객체에 대해 f 라는 함수가 호출되는 것으로 볼 수 있습니다. f 라는 함수는 하나만 있을 것이고, 객체 o 를 둘러싼 표준 함수 집단의 일원은 아닐 거라고 추측할 수 있습니다.
2.번 표현을 볼 때는 o 라는 객체가 f 라는 메세지를 받은 것으로 볼 수 있습니다. 이 때는 f 라는 메세지를 받을 수 있는 다른 종류의 객체들이 있을 거라고 예상할 수 있고, 따라서 정확히 f 가 어떤 것일지 알 수 없습니다. 이렇게 f 처럼 객체 o 의 타입에 따라 달라지는 성질을 “다형적이다” 라고 합니다.
이러한 다형성을 기대하는 것이 객체지향의 핵심입니다. 이것이 객체지향에서 떼어낼 수 없는 환원주의적 정의입니다. 다형성 없는 객체지향은 객체지향이 아닙니다. 이외에 객체지향의 특징으로 거론되는 캡슐화, 데이터와 함수의 연결, 심지어 상속까지도 표현 2.보다는 표현 1.과 관련 있는 것들입니다.
객체지향 프로그램과 비-객체지향 프로그램을 진정으로 구분하는 것은 다형성이라고 할 수 있죠.
다형성 메커니즘은 반드시 호출자(Caller)에서 피호출자(Callee)로 소스코드 종속성을 만들어내서는 안된다.
설명하자면, 두 개의 표현을 다시 봅시다. 표현 1. f(o) 는 함수 f 에 대해 소스코드 종속성을 가지고 있을 것으로 보입니다. 왜냐하면 f 라는 함수가 하나만 있을 것으로 추측되기 때문에 호출자는 그게 뭔지 정확히 알아야 하기 때문이죠.
그런데 표현 2. o.f() 의 경우는 좀 다릅니다. f 의 구현이 많을 수도 있다는 것을 알고 있고, 그중에 어떤 것이 실제로 호출될지 알 수 없습니다. 따라서 표현 2.를 포함한 소스코드는 호출될 함수에 대해 소스코드 종속성을 가지지 않습니다.
구체적으로 말하면 함수를 다형적으로 호출하는 소스파일은 그 함수의 구현을 가진 소스파일을 참조해서는 안됩니다. include 혹은 use, require 같이 소스파일이 다른 소스파일에 의존하도록 하는 선언을 사용하지 않아도 됩니다.
따라서 객체지향 프로그래밍 환원적 정의는:
함수 호출의 다형성을 사용할 때, 호출자의 소스코드가 피호출자의 소스코드에 의존하지 않아도 되도록 하는 기술
OOP : 객체 내부에 상태변수와 메소드를 가지고 있고 그것들끼리 긴밀한 관계를 맺고있음, 클래스로 만들어진 인스턴스마다 다른 상태값을 가지고 있기 때문에 같은 인자값에 대해 다른 결과값이 리턴될 수 있음.
예) obj.func() : 객체 내부의 메소드를 호출.
특징 : 관련된 기능을 모아놓은 종합선물세트, 객체들간 상호작용으로 로직 처리
함수형 프로그래밍이란?
다시 환원주의자가 되어보겠습니다. 함수형 프로그래밍은 소프트웨어 영역을 넘어서는 풍부한 역사와 전통을 가지고 있습니다. 객체지향과 마찬가지로 특유의 발상, 신념, 기법, 패턴, 철학이 있지만 무시하겠습니다. 곧바로 함수형 프로그래밍이 함수형 프로그래밍이도록 하는 고유의 성질을 봅시다. 그냥 단순히 이겁니다:
f(a) == f(b) when a == b.
함수형 프로그래밍에서는 어떤 값으로 어떤 함수를 호출하면 언제든 같은 결과를 얻습니다. 프로그램이 얼마나 오래 실행되고 있었는지는 상관없이 말이죠. 이런 성질은 참조 투명성이라고도 불립니다.
이 성질은 즉, 함수 f 가 자신의 결과를 변화시키는 전역 상태를 변경하면 안된다는 것을 뜻합니다. 더 나아가서 시스템의 모든 함수가 참조 투명하다고 하면, 어떤 함수도 시스템의 전역 상태를 변경할 수 없게 됩니다. 어떤 함수도 다른 함수가 같은 입력에 대해 다른 결과를 반환하도록 할 수 없습니다.
더 깊게 들어가면, 이름 붙은 값은 절대 바뀔 수 없습니다. 즉, 대입 연산이 존재할 수 없습니다.
이런 성질에 대해 생각하다보면 참조 투명한 함수들만으로 이루어진 프로그램은 결국 아무 것도 할 수 없다는 결론에 이르게됩니다. 시스템의 유용한 기능들은 항상 무언가의 상태를 바꾸기 때문입니다. 프린터나 모니터의 상태같은 것 말이죠. 하지만 하드웨어와 외부의 모든 요소들을 제외하고 나면, 사실 우리는 이런 성질로 아주 유용한 시스템을 만들 수 있게 됩니다.
비결은 재귀에 있습니다. 예를 들어 state 라는 구조체를 인자로 받는 함수를 생각해봅시다. 이 구조체는 함수에서 사용하는 모든 상태 정보를 가집니다. 함수가 끝날 때 업데이트된 값들로 새로운 state 구조체를 만들고, 그것을 인자로 자기자신을 호출합니다.
이것이 함수형 프로그램이 내부 상태를 실제로는 변경하지 않으면서도, 내부 상태 변경을 구현하는 방법 중의 한 가지입니다.
따라서 함수형 프로그래밍의 환원적 정의는:
참조 투명성 – 값을 다시 할당하지 않는 것
