CS 스터디 자료조사 10/28
1 SSL (또는 TLS) 가 어떻게 동작하는지 말씀해주세요.
SSL
SSL이란 보안 소켓 계층을 이르는 것으로, 인터넷 상에서 데이터를 안전하게 전송하기 위한 인터넷 암호화 통신 프로토콜이며 데이터 보안을 위해서 개발한 통신 레이어다.
- 응용계층과 전송계층 사이에 독립적인 프로토콜 계층을 만들어서 동작
-> 응용계층의 프로토콜들은 외부로 보내는 데이터를 TCP가 아닌 SSL에 보내게 되고, SSL은 받은 데이터를 암호화하여 TCP에 보내어 외부 인터넷으로 전달하게 된다. 전달 받을 때 역시, TCP로부터 받은 데이터를 복호화하여 응용계층에 전달하게 되는데, 이 과정에서 Application은 SSL을 TCP로 인식하고, TCP는 SSL을 Application으로 인식하기 때문에, Application과 TCP사이의 데이터 전달 방식은 기존 전달 방식을 그대로 사용
SSL/TLS 프로토콜 스택
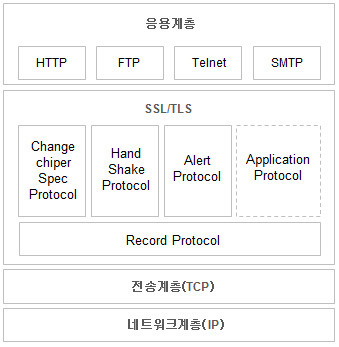
- 크게, 두 그룹으로 구성
- 상위 핸드세이크 관련 프로토콜들
- 하위 레코드 프로토콜 (단편화,압축,무결성,암호화 기능 제공)
SSL/TLS 핸드세이크 프로토콜(동작과정)
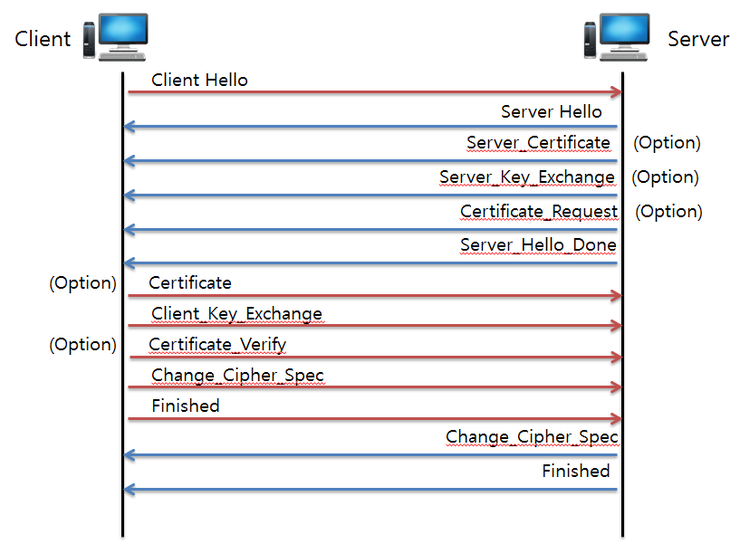
(1) Client hello (클라이언트 -> 서버)
= 자신이 사용하는 TLS버전(TLS1.2) + Client Random + CIpher Suites
사용자(client)가 네이버에 접속하기 위해 네이버 서버쪽에 통신을 요청 이 때, 클라이언트는 통신하고자 하는 TLS 버전, 자신이 지원하는 cipher 리스트, 클라이언트가 생성한 난수 정보 전송
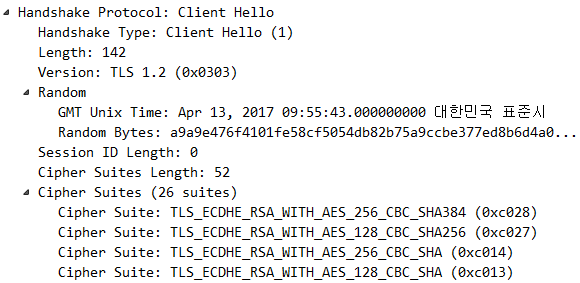
1) Client Random(32바이트)
4바이트 현재시각 + 28바이트 랜덤값
Client Random은 이후 Premaster Secret 과 Server Random과 함게 Master Secret을 생성하는데 사용 합니다.2)Cipher Suites
Cipher Suites란 ? 클라이언트가 사용가능한 암호도구목록
(나는 대칭키는 DES,AES,3DES가 사용가능하고 해시함수는 MD5, SHA1 등이 사용 가능해! 라고 알려주는 겁니다.)
위에 보시는 그림이 Cipher Suites(암호도구 목록) 입니다. 클라이언트가 서버에게 목록을 주는거에요~
Client Hello패킷을 보내며 저 목록들을 서버에게 주고~ 서버는 저 목록 중에서 선택을 할겁니다!즉, 대칭키+키길이+블록암호운용모드+해시함수의 종류를 Cipher Spec(암호명세) 라고 부르며
키교환 및 인증 + Cipher Spec 의 조합이 CIpher Suite 이 되겠고
사용 가능한 Cipher Suite의 목록들을 Cipher Suites 라고 합니다.
(2) Server hello (클라이언트 <- 서버)
=사용할 TLS버전 + Server Random + Session ID + Cipher Suite
서버는 자신의 SSL버전, 자신이 만든 임의의 난수와 클라이언트의 cipher 리스트 중 하나의 선택하여 그 정보를 클라이언트에게 보낸다.
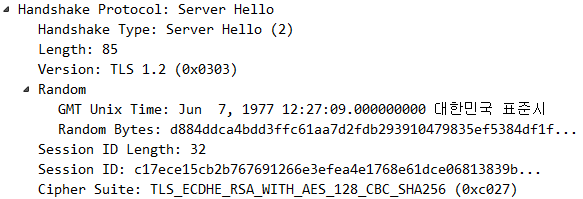
1)Server Random
4바이트 현재시각 + 28바이트 랜덤값
Server Random은 이후 Premaster Secret 과 Client Random과 함게 Master Secret을 생성하는데 사용 합니다.2)Cipher Suite
이제 저 용어들을 해석해보겠습니다.TLS_ECDHE_RSA_WITH_AES_256_CBC_SHA384
키교환은 ECDHE를 사용
인증은 RSA공개키 인증서 방식을 사용
대칭키는 AES알고리즘을 사용
키길이는 256bit
블록암호운용모드는 CBC
해시함수는 SHA384
사용할 것이다.
클라이언트가 준 Cipher Suites 중에 Server는 저것을 선택한겁니다.
우리 통신할때 이 보안파라미터를 사용해서 통신하자~라고 정한겁니다.
여기서 Cipher Spec 정보는 세션상태에 저장합니다.3)Session ID
위에서 저장한 세션상태정보를 식별할 식별 값입니다!
Session ID는 32바이트 고유한 값으로 되어있습니다.
클라이언트가 각 개별연결에서는 이 Session ID를 제시하면 되는겁니다.
Client Hello 에서는 Session ID가 0인것이 보이죠? 이후 단축협상때는 Session ID를 제시하는 것을 볼 수 있습니다.
(3) Server certificate or Server key Exchanges (클라이언트 <- 서버)(Optional)
서버는 거기에 더불어 자신이 갖고있는 인증서정보를 전송
- Server certificate - RSA
- Server key Exchanges - 디피헬만(DHE)
(4) Certificate Request (클라이언트 <- 서버)(Optional)
번외로 클라이언트랑 마찬가지로 서버 또한 클라이언트에게 너 정상적인애니 ? 라며 인증서를 요청할 수 있어요(선택적으로 동작 - RSA)
(5) Server hello done (클라이언트 <- 서버)
드디어 서버의 요청 종료
(6) Client Certificate (클라이언트 -> 서버)(Optional)
서버가 클라이언트의 인증서를 요청할 경우 클라이언트는 자신의 공개키 인증서를 전송합니다.
(7) Client key exchange (클라이언트 -> 서버)
1)RSA방식의 경우
클라이언트는 Premaster Secret(난수값)을 생성하여 서버의 공개키로 암호화하여 전송합니다.
클라이언트는 Premaster Secret + Client Hello + Server Hello 를 조합하여 Master Secret을 상태정보에 유지합니다.
2)DHE방식의 경우
클라이언트의 디피헬만 공개키를 전달합니다.
(8) Client verify (클라이언트 -> 서버)(Optional)
클라이언트는 자신이 보낸 공개키 인증서가 자신의 것이 맞다는 것을 인증 해야겠죠?
지금까지 주고받은 메시지와 Master Secret을 조합한 해시값에 자신의 개인키로 서명을 하여 보냅니다.
(9) Change cipher spec / finished (클라이언트 -> 서버)
암호화된 통신을 시작 + 완료
(10) Change cipher spec / finished (클라이언트 <- 서버)
암호화된 통신을 시작 + 완료
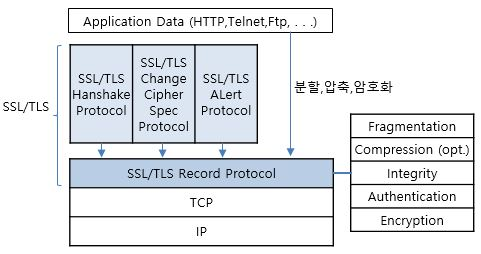
SSL 레코드 프로토콜 (SSL Record Protocol)
-
SSL 레코드 프로토콜은 전송할 응용 메시지를 다룰 수 있는 크기의 블록으로 잘라내어 단편화한다.
-
옵션으로 데이터를 압축하고, MAC을 적용하여 암호화를 하고, 헤더를 추가하여 결과를 TCP 단편으로 전송한다.
- 수신된 데이터는 복호화하고, 확인하며 압축을 풀고 재조립하여 상위 계층 사용자에게 전달한다.
- SSL 레코드 프로토콜(SSL Record Protocol)은 SSL연결을 위해 2가지 서비스를 제공한다.
- 기밀성(Confidentiality): 핸드셰이크 프로토콜은 SSL 페이로드를 관용 암호화하는데 쓸 공유 비밀키를 정의한다.
- 메시지 무결성(Message Integrity): 핸드셰이크 프로토콜은 또한 메시지 인증 코드(MAC)를 생성하는데 사용할 공유 비밀키를 정의한다.
SSL 레코드 프로토콜 동작
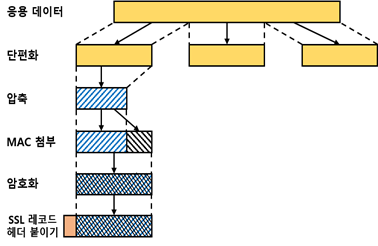
SSL 레코드 프로토콜의 전반적인 동작
1) 단편화 (fragmentation)
- 각 상위 계층 메시지는 214바이트나 이보다 작은 블록으로 단편화한다.
2) 압축 (compression)
- 압축을 할 때는 손실이 없어야만 하며, 내용의 길이가 1024바이트 이상이 되면 안 된다.
3) 메시지 인증 코드(MAC) 계산
- 압축된 데이터의 메시지 인증 코드를 계산하는데, 이 때 공유 비밀키를 사용한다.
4) 암호화
- 압축된 메시지와 MAC을 대칭 암호로 암호화한다.
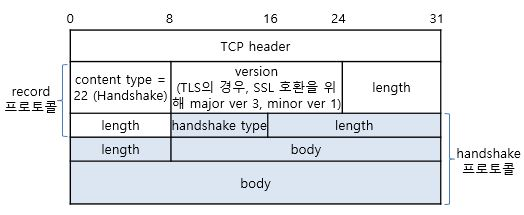
5) SSL 레코드 헤더 붙이기
헤더는 다음의 필드로 구성된다.
-
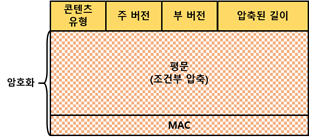
콘텐츠 유형 (Contents Type): 포함된 단편을 처리할 때 사용하는 상위 계층 프로토콜이다.
-
주 버전 (Major Version): 사용 중인 SSL의 주 버전을 나타낸다.
-
부 버전 (Minor Version): 사용 중인 서브버전을 나타낸다.
-
압축된 길이 (Compressed Length): 평문 단편의 바이트 단위 길이로 최댓값은 214+2048이다.
SSL 인증서
클라이언트와 서버간의 통신을 공인된 제3자(CA) 업체가 보증해주는 전자화된 문서
인증서 내용
- 인증서의 내용은 CA의 비공개 키를 이용해서 암호화 되어 웹브라우저에게 제공된다.
- 서비스 정보 (인증서 발급자, CA의 디지털 서명,서비스 도메인)
- 서버측 공개키
SSL 인증서의 서비스 보증방법
- 웹브라우저가 서버에 접속하면 서버는 제일 먼저 인증서를 제공한다.
- 브라우저는 인증서를 발급한 CA가 자신이 갖고있는 CA 리스트에 있는지 확인한다.
- 리스트에 있다면 해당 CA의 공개키를 이용해서 인증서를 복호화 한다.
- 인증서를 복호화 할 수 있다는 것은 이 인증서가 CA의 비공개키에 의해서 암호화 된 것을 의미한다. 즉 데이터를 제공한 사람의 신원을 보장해주게 되는 것이다.
HTTP 무상태
1) 무상태란?
Connectionless로 인해 서버는 클라이언트를 식별할 수가 없는데, 이를 Stateless라고 합니다.
클라이언트의 상태를 모른다는 것은 예를 들면 다음과 같습니다.
- 쇼핑몰에 접속
- 로그인 - >상품 클릭 -> 상세화면으로 이동
- 로그인 - >주문
- 로그인 - >....
즉, 매번 새로운 인증을 해야하는 번거로움이 발생.
2) 상태를 기억하는 방법 - 쿠키
서비스를 운영하려면 서버가 클라이언트를 기억해야 할 경우가 많이 있는데, 클라이언트를 기억할 수 있는 방법은 없을까요?
HTTP는 이러한 문제점을 해결하기 위해 브라우저 단에서 쿠키라는 것을 저장하여 서버가 클라이언트를 식별할 수 있도록 합니다.
( HTTP 헤더 : set-cookie )
3) 상태를 기억하는 방법 - 세션
쿠키는 사용자 정보가 브라우저에 저장되기 때문에 공격자로부터 위변조의 가능성이 높아 보안에 취약합니다.
이와 달리 세션은 브라우저가 아닌 서버단에서 사용자 정보를 저장하는 구조입니다.
따라서 쿠키보다는 안전하다고 할 수 있습니다.
그런데 세션 정보도 중간에 탈취 당할 수 있기 때문에 보안에 완벽하다고 할 수 없습니다.
또한 세션을 사용하면 서버에 사용자 정보를 저장하므로, 서버의 메모리를 차지하게 되고, 만약 동시 접속자 수가 많은 서비스일 경우에는 서버 과부화의 원인이 됩니다.
4) 상태를 기억하는 방법 - 토큰을 사용하는 OAuth, JWT
쿠키와 세션의 문제점들을 보완하기 위해 토큰( Token )기반의 인증 방식이 도입되었습니다.
토큰 기반의 인증 방식의 핵심은 보호할 데이터를 토큰으로 치환하여 원본 데이터 대신 토큰을 사용하는 기술입니다.
그래서 중간에 공격자로부터 토큰이 탈취당하더라도 데이터에 대한 정보를 알 수 없으므로, 보안성을 높은 기술이라 할 수 있습니다.
대표적으로는 OAuth와 JWT이 있습니다.
그런데 꼭 토큰 기반의 인증이 좋다고는 할 수 없습니다.
서비스에 따라 기술의 특징을 잘 이해하여 때에 따라 쿠키, 세션, OAuth, JWT 등을 적절히 사용하는 것이 좋습니다.
위에서 언급한 기술들에 대해서는 아래의 링크를 참고해주시기 바랍니다.
쿠키와 세션
OAuth
JWT
브라우저 검색 - 링크
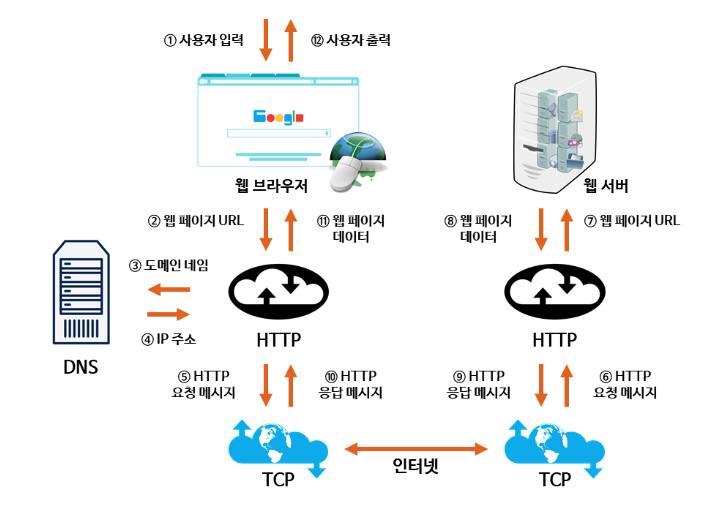
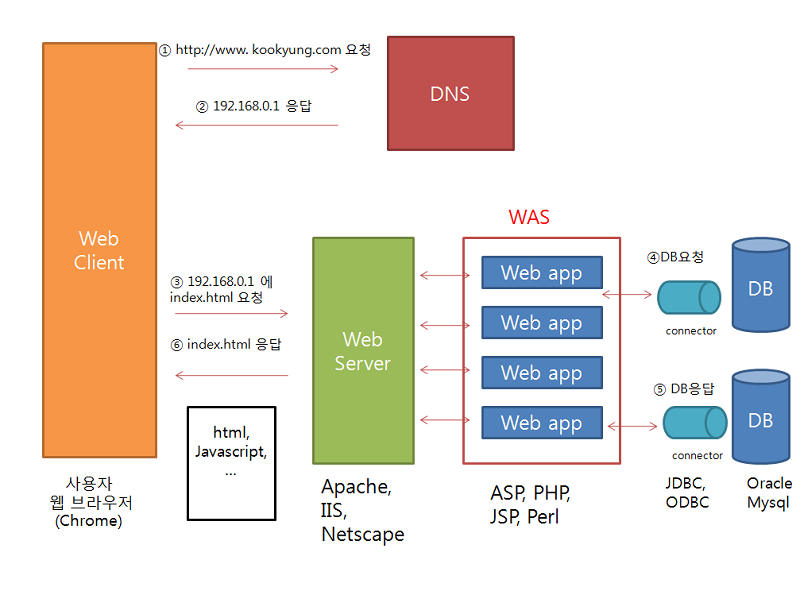
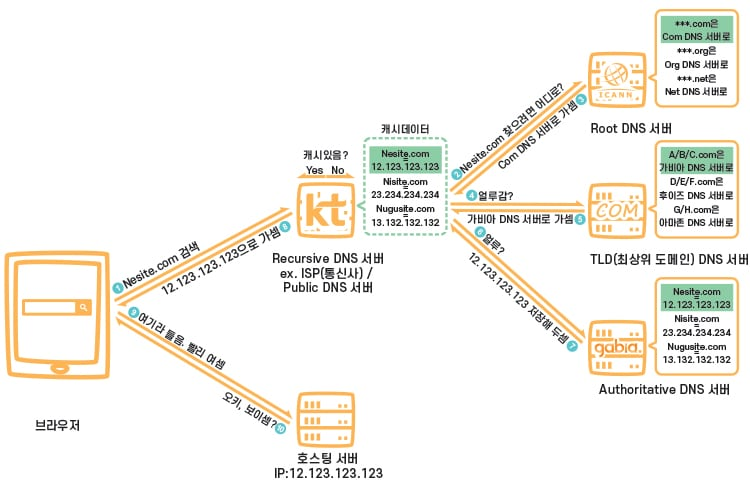
1. 브라우저의 주소창에 maps.google.com을 입력한다.
2. 브라우저는 maps.google.com에 상응하는 IP 주소를 찾기 위해서 DNS 기록 캐시를 확인한다.
DNS(Domain Name System)은 웹사이트의 이름(URL)과 그것이 연결된 IP 주소를 갖고 있는 데이터베이스이다. 모든 URL은 자신만의 IP 주소를 가지고 있다. 이때 IP 주소는 우리가 접속하려하는 웹사이트의 서버를 가지고 있는 컴퓨터에 있다.
-DNS 서버는 각 통신사들이 제공한다.
DNS의 주목적은 인간 친화적인 저장소이다. 원하는 웹사이트에 IP 주소를 브라우저에 입력해서 접근할 수 있다. 하지만 많은 숫자의 조합으로 되어있는 IP 주소를 모두 기억할 수 있을까? 아닐 것이다. 그러므로 URL을 이용해 웹사이트의 이름을 기억하는 것이 더 쉽고, DNS가 URL을 올바른 IP와 이어주는 일을 담당하게 된다.
DNS 기록을 찾기 위해서 브라우저는 browser → OS → router → ISP순으로 확인한다. 흠.. 왜 이렇게 많은 단계에 캐시가 저장되어 있는 것일까? 프라이빗한 정보라면 불안할 수도 있지만, 캐시는 네트워크 트래픽을 통제하고 데이터 전송 시간을 높이는데 필수적으로 필요하기 때문이다.
3. 만약에 요청한 URL이 캐시에 없다면 ISP의 DNS 서버는 maps.google.com을 갖는 서버의 IP 주소를 찾기 위해 DNS query를 시작한다.
내 컴퓨터가 maps.google.com을 호스트하는 서버와 통신하기 위해서 IP 주소가 필요하다. DNS 쿼리의 목적은 올바른 IP 주소를 찾을 때까지 인터넷에 있는 많은 DNS 서버를 검색하는 것이다. 이런 식의 검색을 recursive search (반복되는 검색) 라고 한다. 이 검색은 한 DNS 서버에서 다른 DNS 서버로 옮겨가며 IP 주소를 찾을 때까지 혹은 못 찾겠다는 응답을 반환할 때까지 계속하게 된다.
이러한 상황에서 ISP(통신사)의 DNS 서버를 DNS resursor라고 부른다. 이 서버는 인터넷에 있는 다른 DNS 서버에 물어봄으로써 도메인 이름에 대한 적절한 IP 주소를 찾아야 한다. 이때 다른 DNS 서버는 name server라고 부르는데 웹사이트의 도메인 이름의 구조를 기반으로해서 DNS 검색을 수행하기 때문이다.
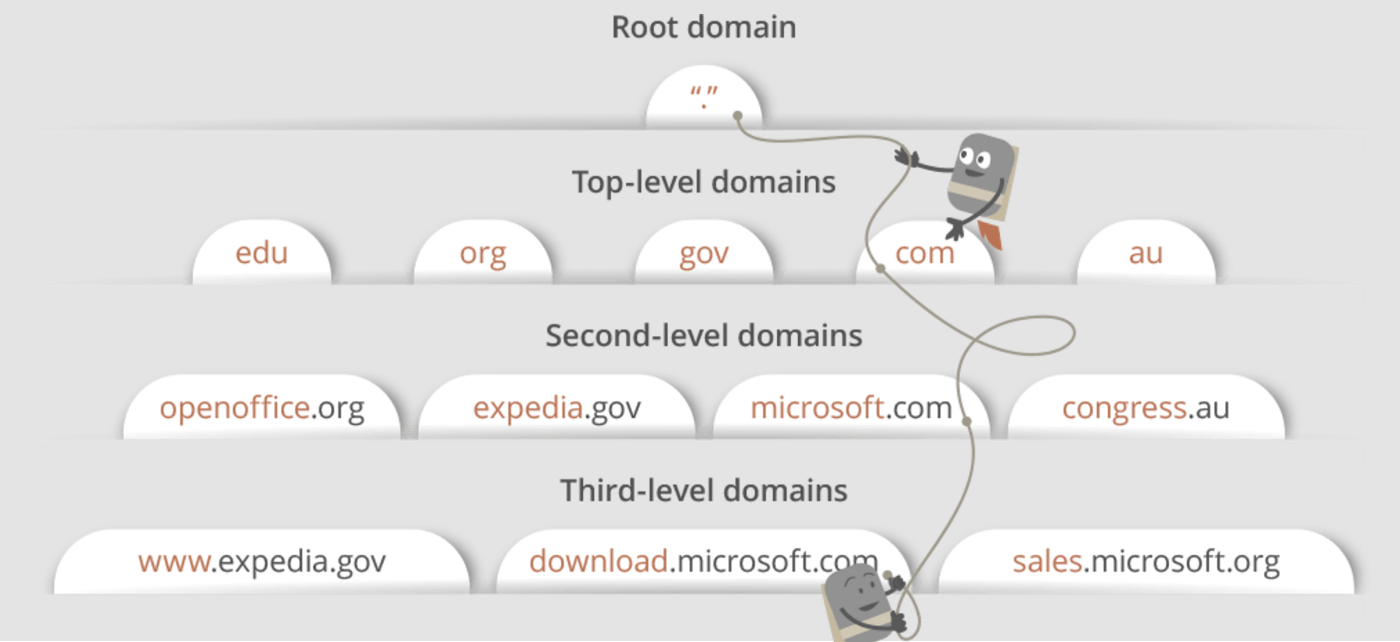
위 그림은 도메인 구조에 대한 설명이다. 오늘날 우리가 접하는 URL은 대부분 third-level, second-level, top-level 도메인을 가지고 있고, 각 도메인은 DNS 검색 과정 동안 쿼리하는 자신만의 name serer를 가진다.
maps.google.com을 예로 들어보자. 첫 번째로 DNS recursor는 루트 네임 서버에 접촉한다. 루트 네임 서버는 .com 도메인 네임 서버로 다시 보낸다. .com 네임 서버는 google.com 네임 서버로 다시 보낸다. google.com 네임 서버는 자신의 DNS 기록에서 maps.google.com에 매칭하는 IP 주소를 찾을 것이고 DNS resursor에 반환하게 된다. 그리고 DNS recursor는 브라우저에 IP 주소를 보내게 된다.
4. 브라우저는 서버와 TCP 통신을 시작한다.
브라우저가 올바른 IP 주소를 받으면, IP 주소가 일치하는 서버와 정보 전달을 위한 연결을 시도한다. 브라우저는 그러한 연결을 위해 인터넷 프로토콜을 사용한다. 여기에 사용되는 인터넷 프로토콜 중에 TCP가 HTTP 요청을 위채 사용되는 가장 흔한 방법인다.
컴퓨터와 서버간의 데이터 패킷 전송을 위해 TCP 연결이 만들어지는 것이 가장 중요하다. 이 연결은 TCP/IP three-way handshake과정을 통해 만들어진다. 이것은 클라이언트와 서버가 연결 하기 위해서 SYN(synchronize), ACK(acknowledge) 메세지를 교환하는 과정을 의미한다.
클라이언트 기계는 서버가 새 연결을 위해 열려있는지 물어보며 서버에 SYN 패킷을 보낸다.
만약 서버가 새 연결을 시작할 수 있는 오픈 포트를 가진다면, SYN/ACK 패킷을 사용하여 SYN 패킷의 ACKnowledgement로 응답한다.
클라이언트가 서버로부터 SYN/ACK 패킷을 받을 것이고 서버에 ACK 패킷을 보냄으로써 받았음을 알려줄 것이다.
그러면 데이터 전송을 위한 TCP 통신이 이루어진다!!
- 브라우저는 웹 서버에 HTTP 요청을 보낸다.
자 TCP 연결이 되면 데이터를 전송할 때다. 브라우저는 maps.google.com 페이지에 대해 묻는 GET 요청을 보낼 것이다. 만약에 증명 정보를 입력하거나 폼을 제출한다면 이 요청은 POST가 될 것이다. 이 요청은 브라우저 식별 정보(User-Agent header), 수락에 대한 요청(Accept header), TCP 연결을 유지하도록 요청하는 connection header 등에 대한 추가적인 정보를 가질 수 있다. 또한 브라우저가 도메인 저장소에 갖는 쿠키로부터 가져온 정보를 넘길 수도 있다.
아래 그림은 GET 요청에 대한 예시이다.

- 서버는 요청을 처리하고 응답을 다시 보낸다.
- 서버는 HTTP 응답을 내보낸다.
서버 응답은 요청한 페이지와 함께 status code, compression type(Content-Encoding), 페이지를 캐시하는 법(Cache-Control), 프라이빗 정보 등을 담고 있다.
아래 그림은 HTTP 서버 응답에 대한 예시이다.

- 브라우저는 HTML 컨텐츠를 표시한다.
브라우저는 HTML 내용을 표시한다. 첫 번째로 HTML 뼈대만 렌더한다. 그리고 HTML 태그를 확인하고 이미지, CSS stylesheet, JavaScript 파일과 같은 추가적인 요소에 대한 GET 요청을 내보낸다. static file(js, css, image 등과 같이 개발자가 사전에 미리 서버에 저장 해둔 파일)은 브라우저에 의해 캐시되기 때문에 다음에 동일한 페이지를 방문했을 때 그것들을 다시 fetch할 필요가 없는 것이다.
