
Django에 Elasticsearch를 사용하여 검색엔진을 구축해보겠습니다.
서버에 로컬로 설치해도 되지만 저는 일단 Docker를 사용해서 설치하였습니다.
Elasticsearch 구축
이미지 생성
공식적인 elasticsearch 이미지를 다운 (버전: 7.17.4 )
docker pull elasticsearch:7.17.4컨테이너 생성
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" c5ac99164e4b코드 설명
-name elasticsearch: 컨테이너에 "elasticsearch"라는 이름을 지정합니다.p 9200:9200: 호스트의 9200 포트와 컨테이너의 9200 포트를 매핑합니다. 이를 통해 호스트에서 Elasticsearch에 접근할 수 있습니다.p 9300:9300: 호스트의 9300 포트와 컨테이너의 9300 포트를 매핑합니다. Elasticsearch의 클러스터 간 통신에 사용됩니다.e "discovery.type=single-node": Elasticsearch의 노드 탐색 타입을 단일 노드로 설정합니다. 단일 노드로 실행되는 단일 Elasticsearch 노드를 생성합니다.c5ac99164e4b: 이미지 ID
분석기 설치
컨테이너로 접속해서 설치해줘야 한다.
docker exec -it elasticsearch /bin/bash- “elasticsearch” 라는 이름을 가진 컨테이너로 접속하는 코드이다.
해당 폴더에 들어간 후 “nori”라는 우리말 형태소 분석 모델을 설치하면 된다.
$ cd /usr/share/elasticsearch/bin/
$ ./elasticsearch-plugin install analysis-nori분석기 삭제
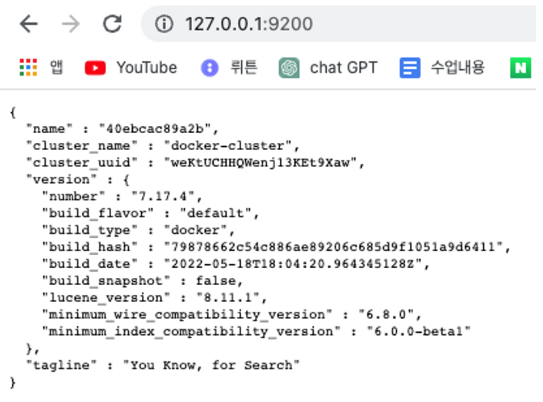
$ bin/elasticsearch-plugin remove analysis-nori웹에서 127.0.0.1:9200 으로 접속해 보면 아래와 같은 모습이 보일 것이다.
Django 적용
이제 장고에 연결시킬 것이다.
나는 원래 진행하던 파이널 프로젝트에서 Elasticsearch 를 적용시켜볼 것이다.
앱(App) 생성
먼저 search 라는 앱을 만들어주자.
django-admin startapp search패키지 설치
pip install djangorestframework
## api 통신을 위한 rest-framework 설치
pip install elasticsearch settings.py 설정
설치한 패키지와 앱을 settings.py에 등록시켜보자.
INSTALLED_APPS = [
...
"rest_framework",
"search",
]컨테이너로 띄운 elasticsearch 도 등록해야한다.
ELASTICSEARCH_DSL = {
'default': {
'hosts': '127.0.0.1:9200'
},
}urls.py 설정
"search" 앱을 위한 url를 따로 설정해준다.
경로 : <project이름>/config/urls.py
urlpatterns = [
...
path('search/', include('search.urls', namespace='search')),
]
다음은 elasticsearch 을 사용할 url을 등록하자.
먼저 urls.py를 생성하고 난 후 아래 코드를 입력하면 된다.
경로 : <project이름>/search/urls.py
from django.urls import path
from . import views
app_name = 'search'
urlpatterns = [
path('home/', views.search, name="home"), ## 사용자가 검색할 페이지
path('', views.SearchView.as_view(), name="search"), ## elasticsearch api 주소
]views.py 설정
경로 : <project이름>/search/views.py
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework import status
from elasticsearch import Elasticsearch
class SearchView(APIView):
def get(self, request):
es = Elasticsearch() ## elasticsearch 를 사용
search_word = request.GET.get('search') ## GET 요청으로 'search' 값을 가져옴
if not search_word: ## 만약 'search'값이 존재하지 않는다면
return Response(status=status.HTTP_400_BAD_REQUEST, data={'message': '검색 단어를 찾을 수 없습니다.'}) ## 404 에러와 함께 메세지를 출력
docs = es.search(
index='media', ## media 라는 인덱스에서
body={
"query": {
"multi_match": {
"query": search_word, ## 해당 검색 단어를
"fields": ["titleKr"] ## 필드는 titleKr에서 찾아줘
}
}
}
) ## 검색 결과를 "docs"에 저장
data_list = docs['hits'] ## 필요한 결과만 data_list에 저장
return Response({'data': data_list}) ## JSON 응답 전달Data Insert
index를 만들고 데이터를 넣기 위해 setting_bulk.py 파일을 생성하자.
경로:<project이름>/search/setting_bulk.pyimport json
from elasticsearch import Elasticsearch
es = Elasticsearch()
## index 생성
es.indices.create(
index='media',
body={
"settings": {
"index": {
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
}
},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"titleKr": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
)
## json 파일 불러오기
with open('./ott_all.json', encoding='utf-8') as json_file:
json_data = json.load(json_file)
body = ""
for item in json_data:
id = item.get("id")
title_kr = item.get("titleKr")
body += json.dumps({"index": {"_index": "media"}}) + "\n"
body += json.dumps({"id": id, "titleKr": title_kr}, ensure_ascii=False) + "\n"
es.bulk(body)“media” 라는 인덱스 주소를 만들고 한글분석기 nori를 지정합니다.
mapping은 elasticsearch에 적용할 속성들을 넣습니다.
그리고 json 형태로 불러온 데이터셋을 읽어와서 만들어진다.
그후 es.bulk(body)로 데이터를 집어넣습니다.
주의사항 dictionary라는 index가 이미 생성되었다면 다시 생성되지않습니다.
그 땐 index 지우고 다시 데이터를 넣어야 합니다.
다음 명령어를 실행하여 elasticsearch에 dataset을 insert합니다.
python setting_bulk.py인덱스 DELETE
🌟 콘솔창에 다음 명령어 실행
curl -XDELETE localhost:9200/<인덱스이름>Data 확인
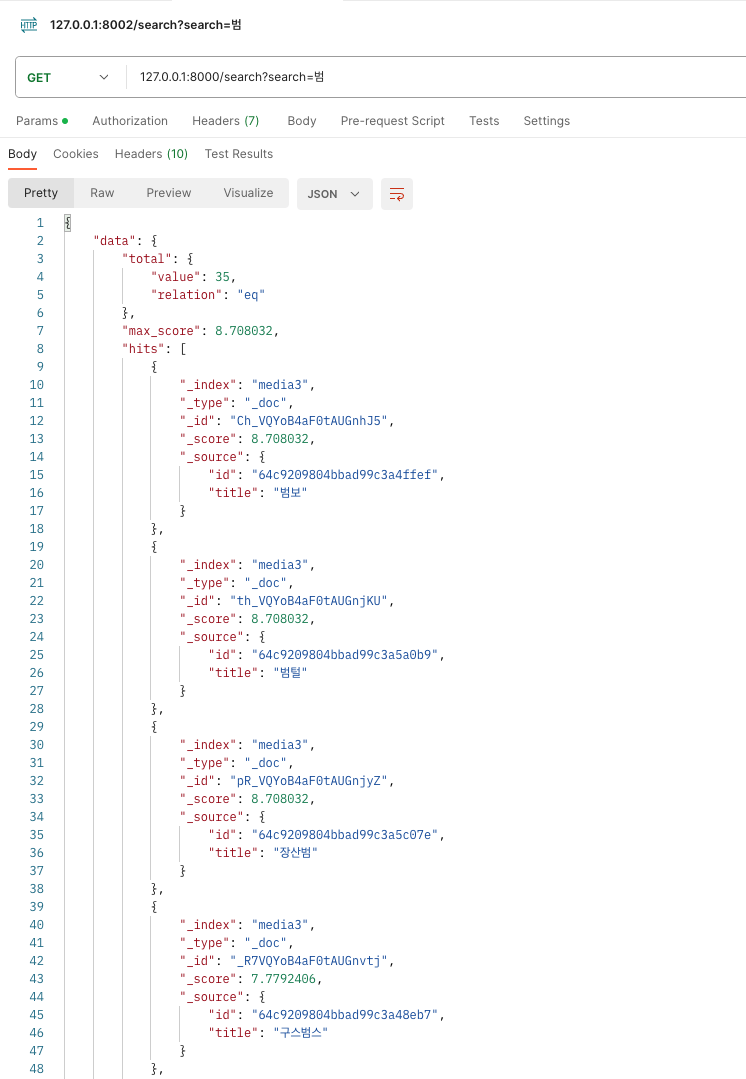
데이터 확인을 하기 위해서는 kibana가 있어야 하지만 필자는 api로 검색해서 확인했다.
본인은 Postman 으로 API 결과를 확인해봅니다.
Elasticsearch 버전 업그레이드
버전이 업그레이드되면서 파이썬으로 데이터 넣는 방식이 바뀌었다. 만약 위에 코드가 실행이 안된다면 아래 코드로 실행해보자.
import json
from elasticsearch import Elasticsearch
from pymongo import MongoClient
es = Elasticsearch('<엘라스틱서치IP:포트번호>')
## es = Elasticsearch('https://<엘라스틱서치IP:포트번호>')
es.indices.create(
index='media3',
settings={
"analysis": {
"analyzer": {
"my_analyzer": {
"type": "custom",
"tokenizer": "nori_tokenizer"
}
}
}
},
mappings={
"properties": {
## 컬럼 지정
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "my_analyzer"
},
}
}
)
## 몽고디비 클라이언트 연결
client = MongoClient('mongodb://final:123@34.22.93.125:27017/')
## 몽고 db 이름 연결
db = client['final']
## collection 연결
collection = db['movies2']
body = ""
for x in collection.find():
id = str(x['_id'])
title = x['title_kr']
body += json.dumps({"index": {"_index": "media3"}}) + "\n"
body += json.dumps({"id": id, "title": title}, ensure_ascii=False) + "\n"
es.bulk(body)