Open API를 이용해서 데이터를 받아오는 방법에 대해서 알아보겠습니다.
Open API 사용법을 알기 전에는 저는 사이트에서 제공하는 CSV파일, Excel파일의 데이터 밖에 이용하지 못했습니다...
(흔히들 데이터 분석 프로젝트를 하기 위해서 찾는 공공데이터 포털을 이용했죠)
그런데 유튜브나 책을 통해서 알아 본 결과, 자신의 회사 도메인과 관련된 프로젝트 주제를 선호한다는 걸 알게 되었습니다. 그래서 공모전이나 공공기관 등을 준비하는 아니라면, 공공데이터 이외의 다양한 곳들에서 데이터를 끌어올 줄 알아야 합니다. (준비하고 있는 기업이나 도메인이 있다면 그 쪽 위주로 프로젝트를 진행해보는 것이 도움되겠죠!)
Open API를 사용하는 방법을 알고부턴, 데이터를 확보할 수 있는 또 하나의 방법이 되어줄 겁니다.
(이후에는 일반적인 사이트에서도 데이터를 끌어올 수 있는 '웹크롤링' 방법에 대해서도 알아보겠습니다)
(제가 정의하는) Open API를 통해서 데이터를 끌어오는 일반적인 방법은 다음과 같습니다.
1. 해당 Open API 사이트로부터 데이터 활용 신청하기
(인증키 발급받기)
2. 필요한 데이터를 끌어오기 위한 적절한 URL 만들어주기
3. 데이터를 불러올 때 사용되는 라이브러리 불러오기
4. XML 형태의 데이터를 살펴보기
5. 적절한 형태의 DataFrame 만들어주기
각 단계의 방법들을 구체적인 예시를 통해서 알아보겠습니다.
(kobis라는 영화진흥위원회의 사이트를 통해서 알아보겠습니다)
1단계 Open API 사이트로부터 데이터 활용 신청하기
사이트에 접속하고 키 발급/관리 버튼을 눌러줍니다.
이동하게 되면 키 발급받기 버튼을 한 번 더 눌러줍니다.
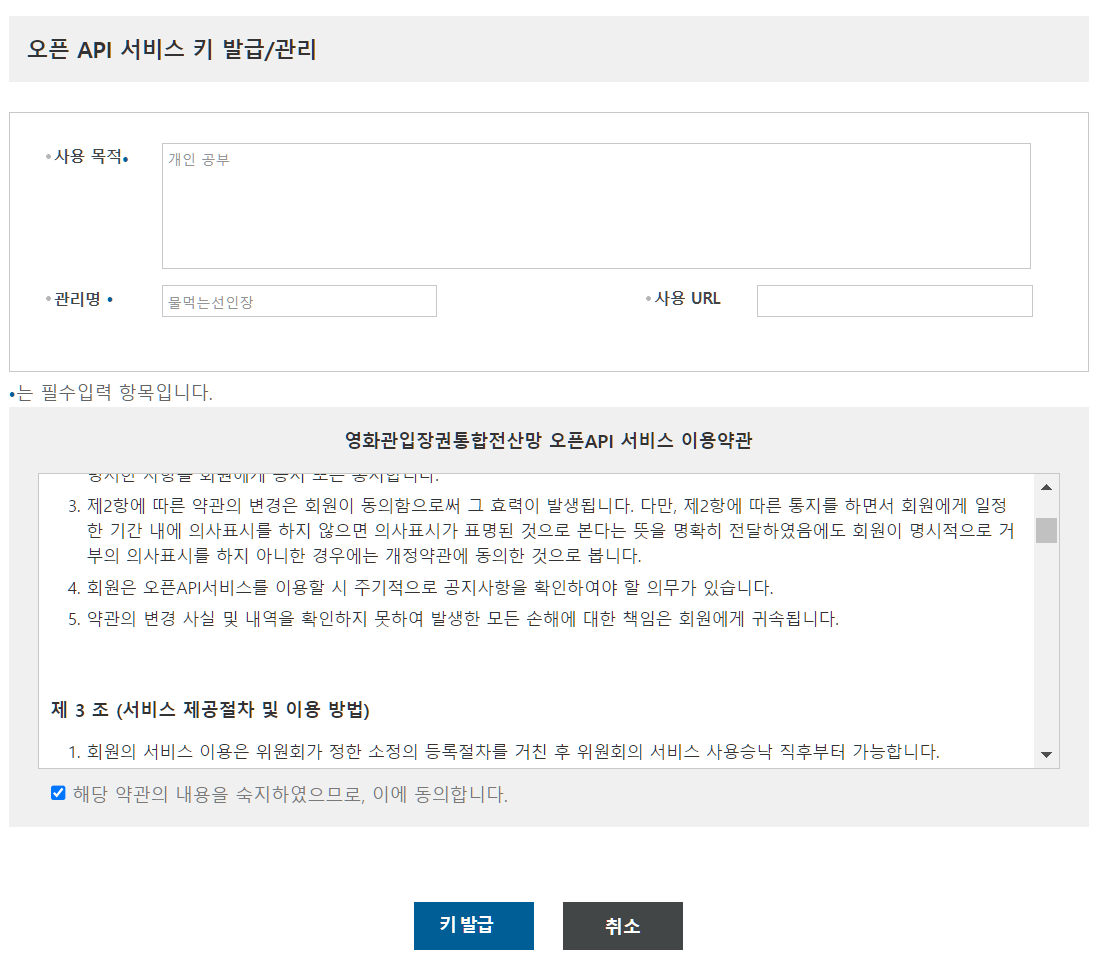
사용 목적과 관리명을 입력하게 되는 창이 나오게 되는데 간단하게 적어주면 됩니다. 그리고 키 발급 버튼을 눌러줍니다.
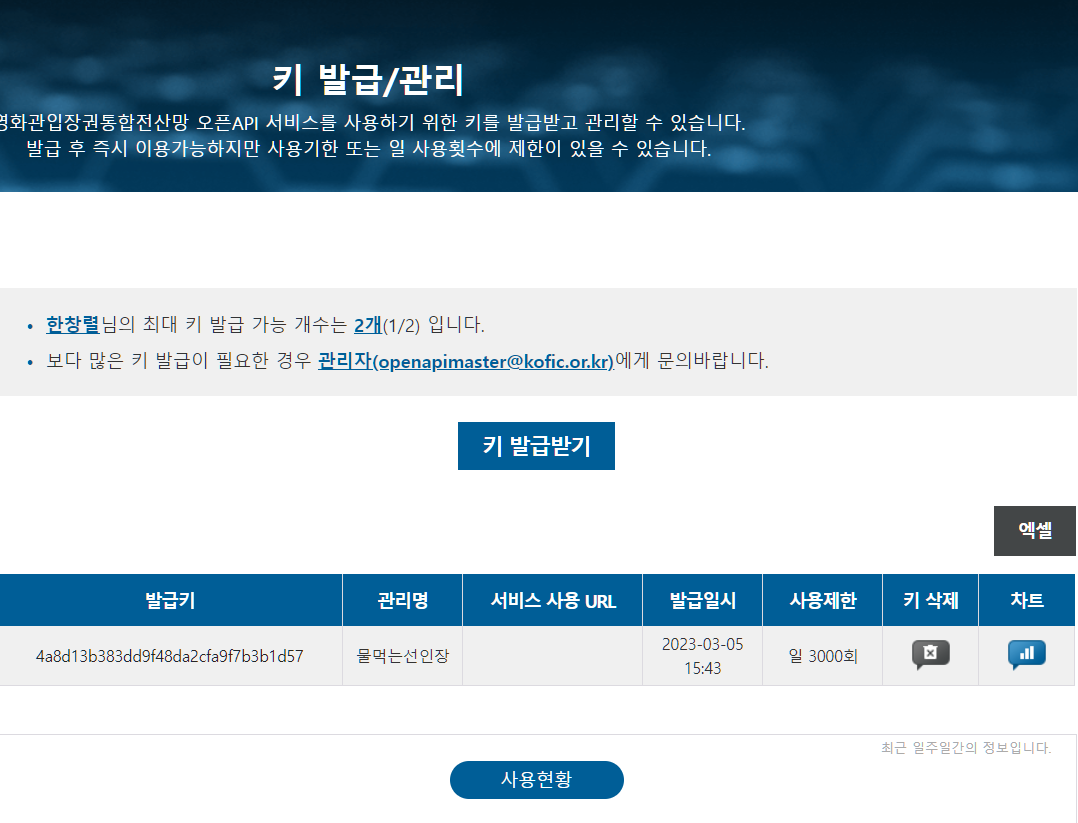
그러면 위와 같이 키가 발급되었습니다. 키 발급을 바로 해주는 사이트도 있고, 경우에 따라서는 하루 정도 걸리는 사이트가 있습니다.
발급키는 Open API를 사용하기 위한 URL를 만들어줄 때 사용됩니다.
2. 필요한 데이터를 끌어오기 위한 적절한 URL 만들어주기
이제 키는 발급 받았으니, 원하는 데이터를 끌어오기 위해서 적절한 URL을 만들어보도록 하겠습니다.
홈페이지에서 제공서비스 부분을 눌러줍니다.
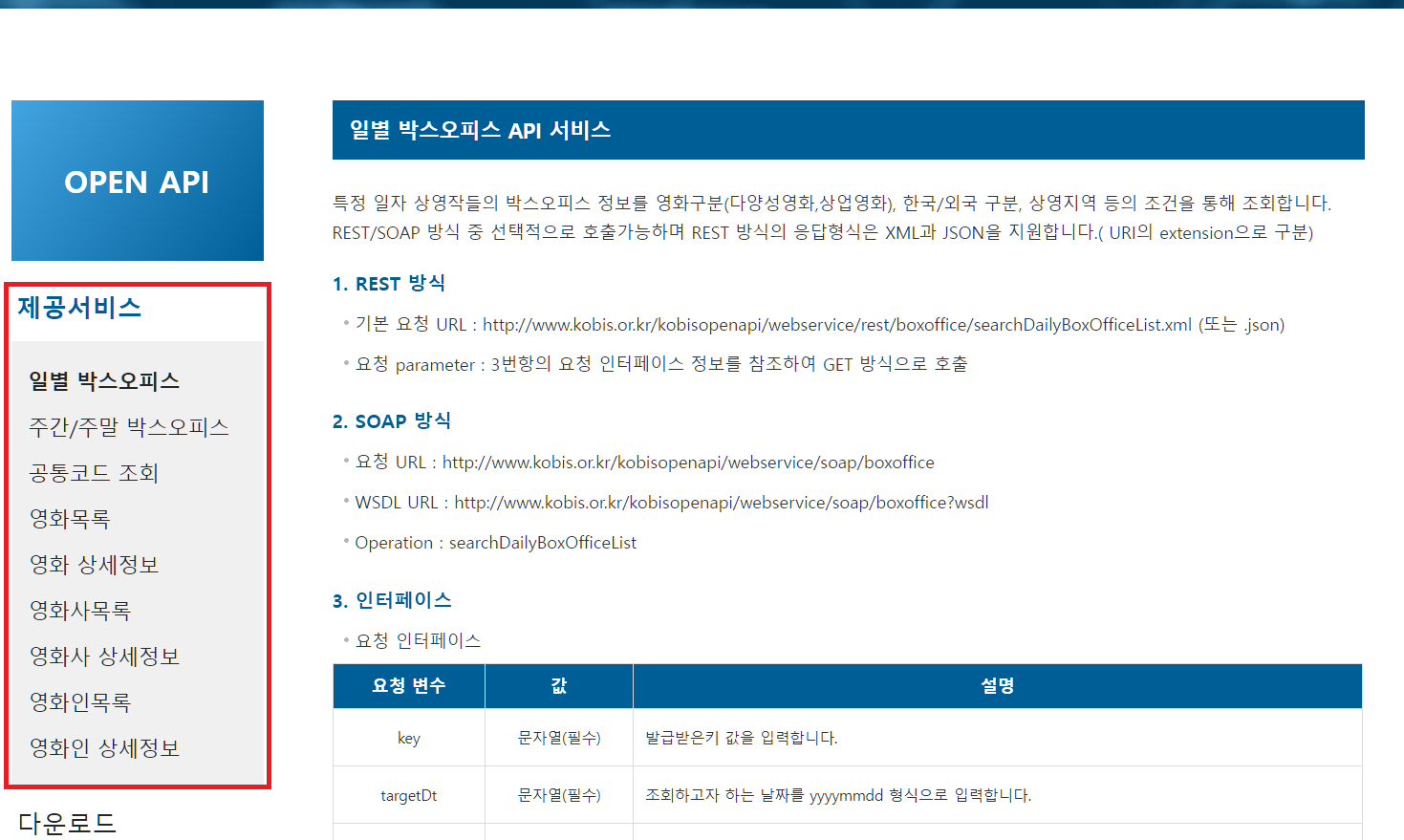
이 페이지에서는 어떤 데이터들을 제공하고 있는지 알 수 있습니다.
왼편에 제공서비스 목록을 참고하여 선택할 수 있습니다.
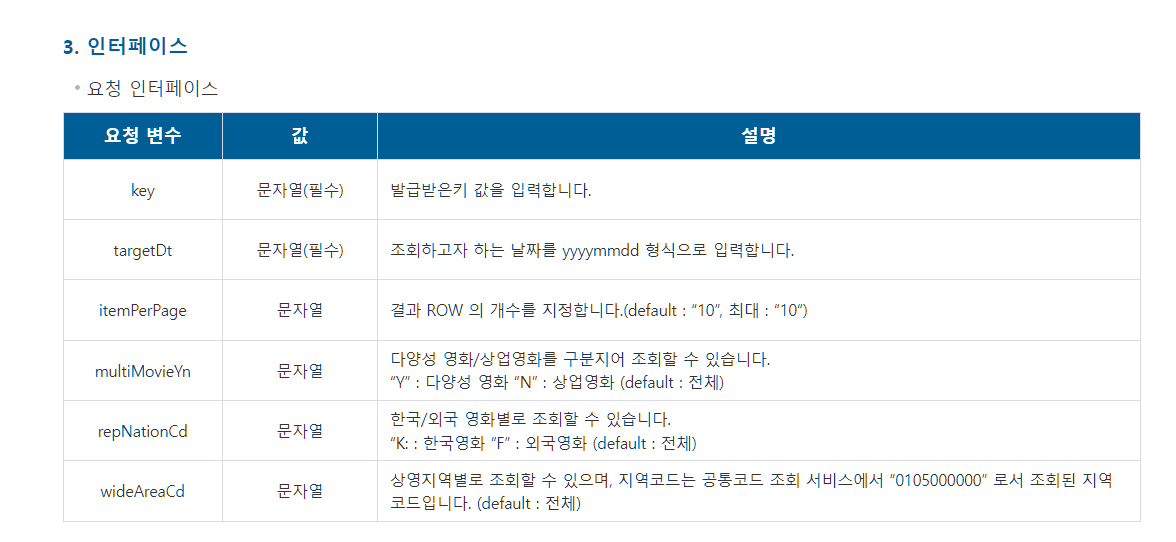
요청 인터페이스는 URL을 만들 때 요청할 수 있는 파라미터들을 이야기 해주고 있습니다. Key와 targetDt는 필수적으로 입력해야하고, 나머지 파라미터는 선택해서 사용하면 됩니다.
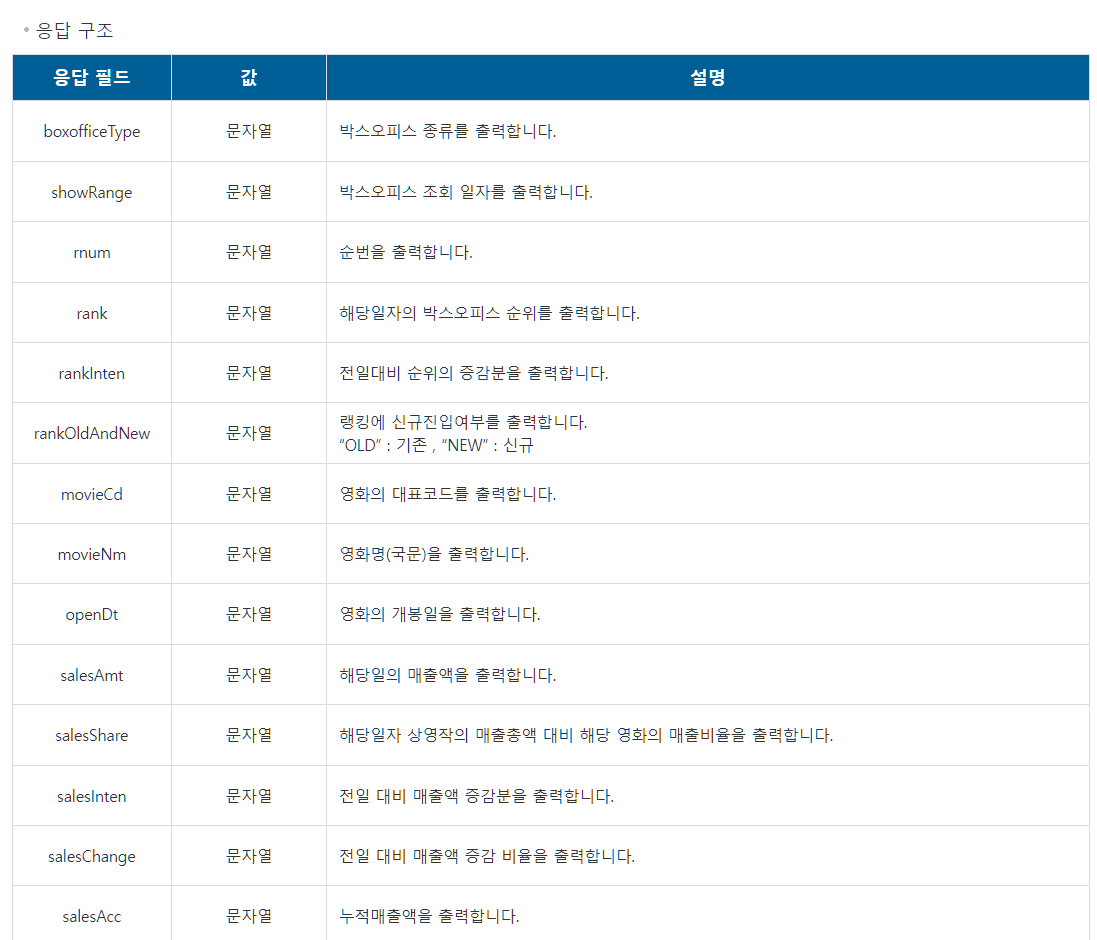
아래의 응답 구조는 내가 URL을 만들어서 데이터를 요청했을 시 얻게 되는 데이터 목록들을 알려 줍니다. 응답 구조에 내가 필요한 데이터를 제공하는지 먼저 알아보고 데이터를 요청하는 게 좋겠네요.
이 사이트는 친절하게 요청하는 URL 예시까지 제공하였습니다.
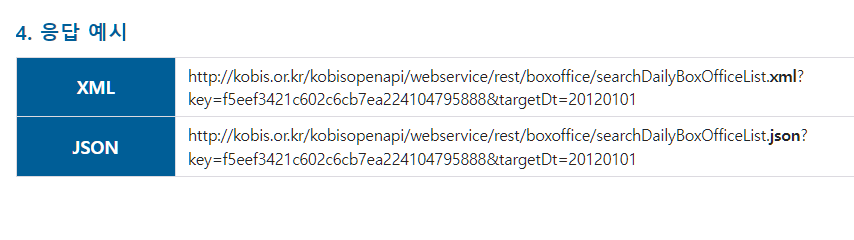
URL 예시에서 알 수 있듯,
(기본 URL)(key= )&(요청 파라미터 값 1)&(요청 파라미터 값 2)&(요청 파라미터 값 3).... 과 같은 형식으로 만들어주면 됩니다.
맨 앞에 기본 URL과 발급받은 키를 붙여준 뒤 '&' 기호를 이용해 원하는 파라미터 값을 덧붙여주면 됩니다. 이는 다른 Open Api 사이트에서도 똑같이 적용됩니다.
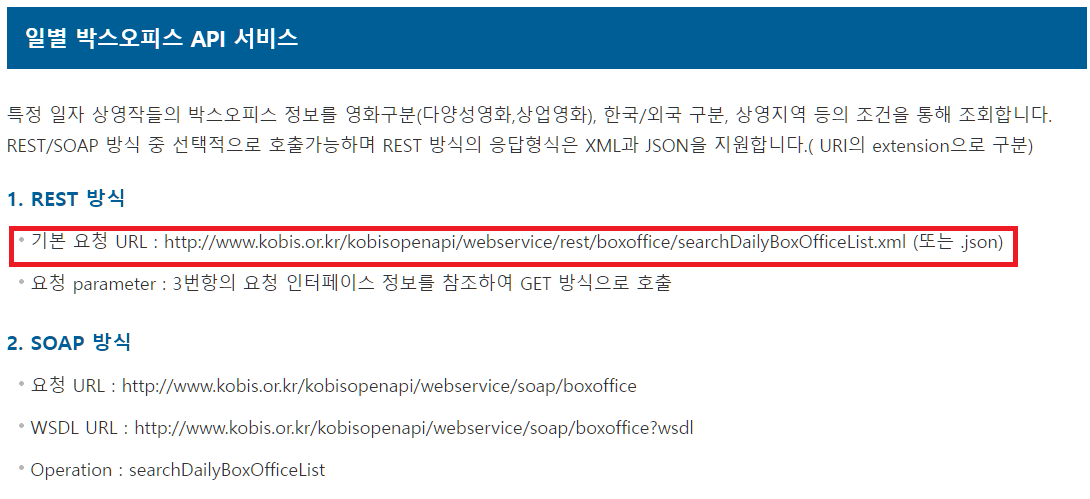
기본 URL은 맨 위 REST 방식이라고 쓰여진 부분에서 알 수 있네요.
위와 같은 설명 방식에 따라 Colab이나 Jupyter Notebook 등을 열어 파이썬에서 url을 아래와 같이 만들 수 있겠네요.
base_url = "http://www.kobis.or.kr/kobisopenapi/webservice/rest/boxoffice/searchDailyBoxOfficeList.xml?"
key = "key=4a8d13b383dd9f48da2cfa9f7b3b1d57"
para1 = "&targetDt=20230301"
para2 = "&itemPerPage=10"
url = base_url + key + para1 + para2
이러면 데이터를 요청받기 위한 URL이 완성되었습니다.
3. 데이터를 불러올 때 사용되는 라이브러리 불러오기
이제 URL은 완성되었지만, 이 URL을 이용해서 데이터를 불러와야겠죠.
그러기 위해 아래와 같은 라이브러리들을 불러와줍니다.
import pandas as pd
import urllib.request
from bs4 import BeautifulSoup
import pandas as pd는 나중에 데이터들을 정리하기 위한 라이브러리이고,
(그 유명한 판다스입니다)
import urllib.request는 만들어 준 url를 통신을 통해서 데이터를 불러오기 위한 라이브러리입니다.
from bs4 import BeautifulSoup 뷰티풀숲은 불러온 데이터를 우리가 적절히 알아보고 찾기 위해 사용하는 라이브러리입니다.
XML 데이터는 어떻게 생겼는지, 그리고 어떻게 뷰티풀숲을 이용해서 DataFrame을 만들어주는지에 대해서는 2편을 통해서 알아보도록 하겠습니다.
긴 글 읽어주셔서 감사합니다!
