Big Endian vs Little Endian
이 글은 기존 운영했던 WordPress 블로그인 PyxisPub: Development Life (pyxispub.uzuki.live) 에서 가져온 글 입니다. 모든 글을 가져오지는 않으며, 작성 시점과 현재 시점에는 차이가 많이 존재합니다.
작성 시점: 2017-09-26
지난 AudioRecord to Wav 글 에서 나왔던 Little Endian.
뭔가 한번이라도 정리해 둬야 될 것 같았다.
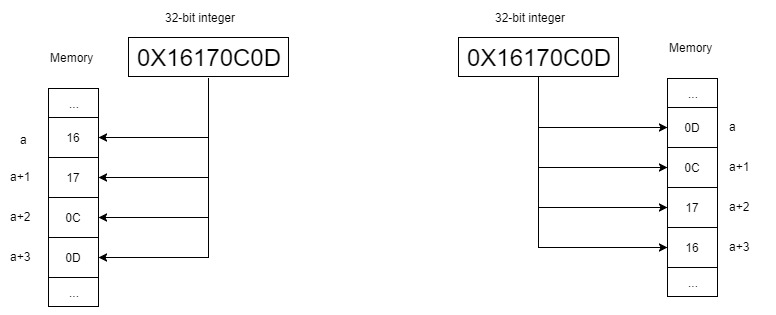
왼쪽이 Big-Endian, 오른쪽이 Little-Endian 이다.
그림으로 정리하면 위랑 같은데, 0x16170C0D 라는 값이 있다고 해보자.
Big Endian
메모리에는 16, 17, 0C, 0D 순으로 들어가면 Big Endian 이다. 사람이 숫자를 읽고 쓰는 방법과 동일하기 때문에 비교적 디버깅 하기 쉽다.
Little Endian
메모리에 역순으로 0D, 0C, 17, 16 순으로 들어가면 Little Endian 이다. 언뜻 보면 반대로 표현되기에 디버깅을 하기 어렵다는 점이 있다. 하지만 리틀 엔디안 에는 다른 장점이 있다.
예를 들어서, 32-bit integer 인 0x2A 는 Little Endian 환경에서는 2A 00 00 00 으로 표현되, 앞에 부분만 따내면 쉽게 하위 비트를 얻을 수 있다. 보통 첫 바이트를 주소로 삼는 성질이 있어 프로그래밍을 편하게 한다.
지난 글에서 설명한 WAV 헤더를 다시 한번 봐보자.
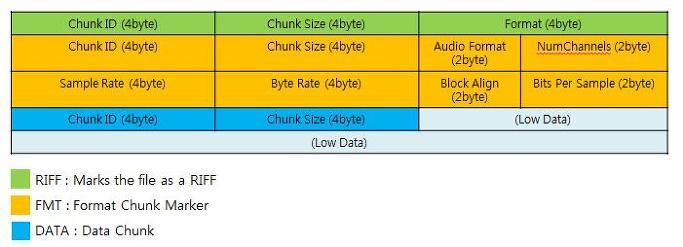
이 중 FMT 영역의 Chunk Size 에 대해 설명할 때 아래와 같이 정리했다.
총 24 바이트가 들어가는데, 이 4바이트와 Chunk ID 의 4 바이트를 제외한 나머지 부분인 16 을 채워넣는다.
그리고, 이걸 코드에 넣을 때에는 16, 0, 0, 0, // Chunk Size 이런 식으로 넣는다.
빅 엔디안 이라면 앞에 2바이트 정도 더 추가해서 알아내야 되는 것에 비하면, 의외로 큰 도움이 된다는 것을 알 수 있다.
참고로, 리틀 엔디안 은 x86 가 리틀 엔디안 을 사용하기에 대부분 데스크톱은 리틀 엔디안 을 쓴다.
반대로 빅 엔디안 은 네트워크에서 주소를 표현하는 방식을 쓰이는데 이의 영향으로 많은 프로토콜과 파일 포맷들이 빅 엔디안 을 사용한다.
주로 모바일 프로세서에 쓰이는 ARM 아키텍쳐의 경우 성능 향상을 위해 빅 엔디안,리틀 엔디안을 선택할 수 있다고 한다.
참고로, WAV 는 빅 엔디안, 리틀 엔디안 을 모두 사용해서 작성해야 된다고 한다. Big Endian 으로 쓸 부분은 'R I F F' , 'W A V E' , 'F M T ', 'd a t a' 의 4종류, 나머지는 리틀 엔디안 을 사용하는 것 같다.
