ManytomanyField를 사용한 model
이전 글에서 아주 기초 세팅부터 시작해서 django에 app을 추가해 보았다. 기초중의 기초인데다가 테이블 1개만 사용해서 간단한 입,출력을 구현한 것이었다.
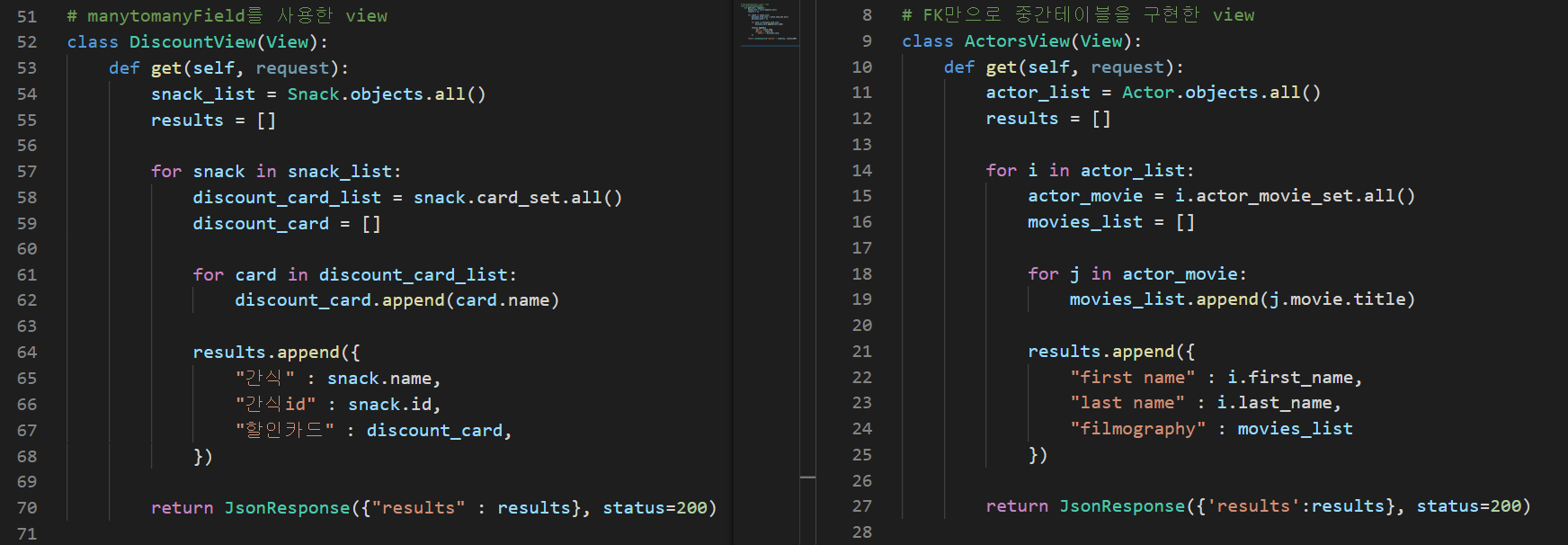
하지만 생성한 테이블이 3개였는데, 다음과 같다.


snacks_cards 테이블은 중간 테이블로, 각 테이블의 id를 FK로 참조하고 있다. 또 card 테이블이 snack을 manytomanyField로 참조하고 있는 것도 보일 것이다.
먼저 cards 테이블을 활용해 기존의 snack말고 다른 뷰도 작성한 후에 중간 테이블을 사용해서 데이터를 꺼내 보자.
간단하게 코드를 복붙해서 CardsView를 작성해 보았다.
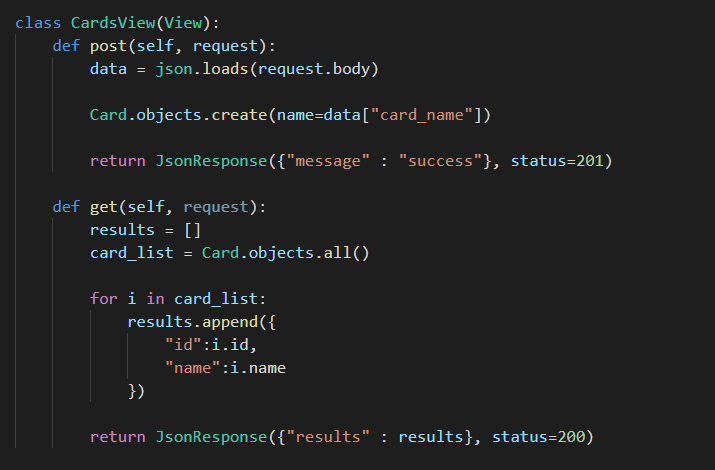
아까 SnacksView가 간식의 종류를 입,출력했다면 이번에는 카드의 종류를 입,출력할 수 있는 것이다.
이대로 실행하면 될까? 아니다!
잘 만든 뷰가 여기 있다고, 여기로 찾으러 오면 된다고 urls.py를 설정해 줘야 한다.
다시 설명하자면, urls.py는 여러 개 존재할 수 있다.
기본적으로 프로젝트명으로 생기는 하위 디렉토리에 있는 urls.py에서는
from django.urls import path, include
urlpatterns = [
path('snack', include('snack.urls'))
]아래와 같이 url의 첫 번째까지 찾아와 연결해줄 수 있다. http://127.0.0.1:8080/snack/~~~ 뒤에 뭐라고 붙어 있어도 8080/snack까지의 url만 판단해서 snack.urls를 찾아오는 것이다.
그러면 snack 디렉토리의(앱의) urls.py에는 어떻게 작성했었지?
from django.urls import path
from snack.views import SnacksView
urlpatterns = [
path('/snack', SnacksView.as_view())
]http://127.0.0.1:8080/snack/snack 이라는 경로가 있다면, 첫 번째 snack까지는 app으로 찾아오는 길잡이 역할을 하고, 남은 /snack(슬래시의 위치가 중요하다!) 으로는 SnacksView로 이동하는 길잡이 역할을 한다. 그 후에 SnacksView에서 http의 메서드가 get인지 post인지에 따라 각각의 함수 get 또는 post로 이동해 로직을 타고 데이터를 입력하거나 가공해 리턴한다.
그러니 또다른 view를 생성한 지금은 /snack 아래에 새로운 urlpattern을 추가해 주면 되겠다.
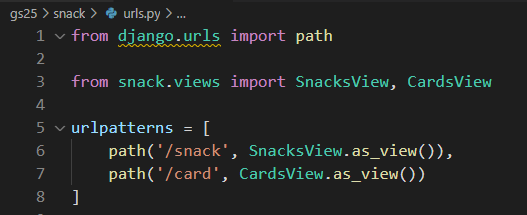
그러면 httpie로 데이터를 몇개 추가한 후 접속해 보자.
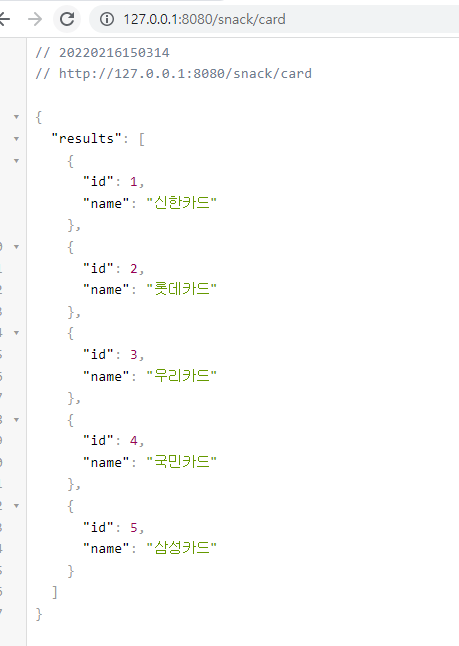

이제 간식목록과 카드목록이 있다.
중요한 질문을 해 보자.
어떤 카드로 어떤 간식을 사야 할인을 받을 수 있을까?
Snack_card 클래스에 각각의 id를 통해 간식과 할인카드의 값을 넣어두었다. 어떤 카드가 어떤 간식을 할인해 주는지 출력하고 싶은데, 따로 출력하기보다는 한 간식의 이름과 할인카드 목록을 한번에 출력하고 싶다.
서버로부터 전달받는 데이터를 가공하고 싶은 것이므로 당연히 view를 수정해야 한다.
card와 snack을 동시에 가공할 view를, 정확히는 View를 상속받는 클래스를 새로 하나 만들어 보자.
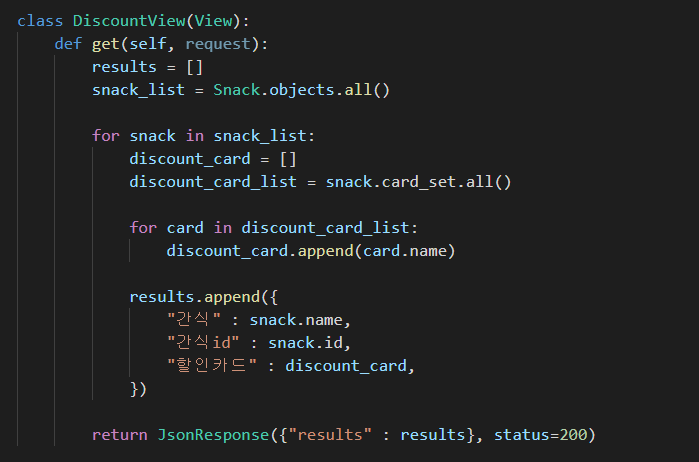
DiscountView라는 새로운 view가 get메서드를 가지고 있다. 한번 앞에서부터 차분히 읽어 보자.
class DiscountView(View):
def get(self, request):
# 결과물을 출력할 results
results = []
# 각 snack별로 할인카드 목록을 가져오기 위해 QuerySet을 저장
snack_list = Snack.objects.all()
for snack in snack_list:
discount_card = []
discount_card_list = snack.card_set.all()
# results에 삽입하기 위한, 한 간식을 할인받을 수 있는 카드 목록 discount_card
# snack이라는 객체를 역참조하고있는 card_set을 통해
# 한 snack의 할인카드 목록이라는 QuerySet 저장
for card in discount_card_list:
discount_card.append(card.name)
# 이중 for문으로 아까 QuerySet을 저장한 할인카드 목록에서 name이라는 컬럼을
# results에 삽입하기 위해 discount_card에 append
# 리턴할 결과물
results.append({
"간식" : snack.name,
"간식id" : snack.id,
"할인카드" : discount_card,
})
return JsonResponse({"results" : results}, status=200)이렇게 view를 짜 주면, 다음과 같은 결과를 얻을 수 있다.

완성!
그러면 이 ManytomanyField란 정확히 어떤 역할을 하는 걸까?
ManytomanyField를 사용하지 않으면 어떻게 되는 걸까?
이게 많이 헷갈렸다. 찾아봐도 맘에 차게 시원한 결과를 찾지 못했다.
그래서 위와 같은 프로젝트를 생성한 것이다. 이전에 작성한, ManytomanyField가 없는 프로젝트와 이 프로젝트를 한번 비교해 보려고 한다.
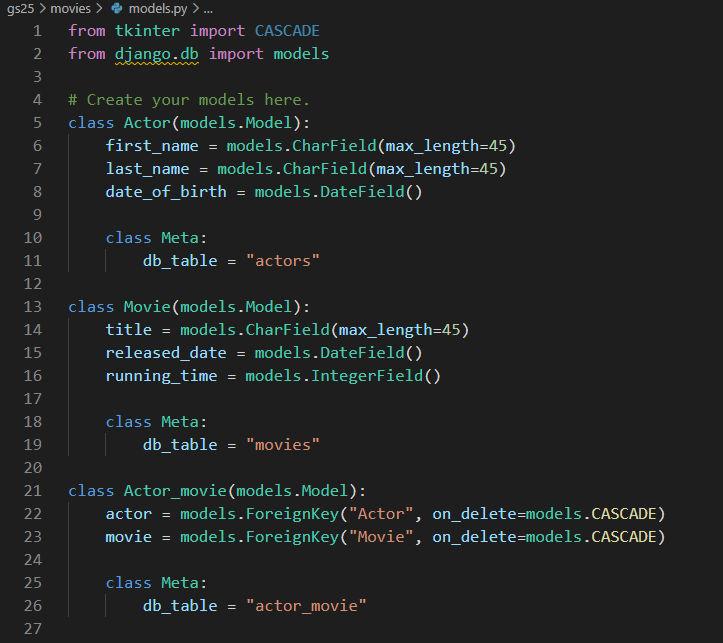
ForeignKey만 사용한 model
gs25라는 프로젝트에, 이전에 작성한 앱인 movies를 이식했다.
-
models.py
-
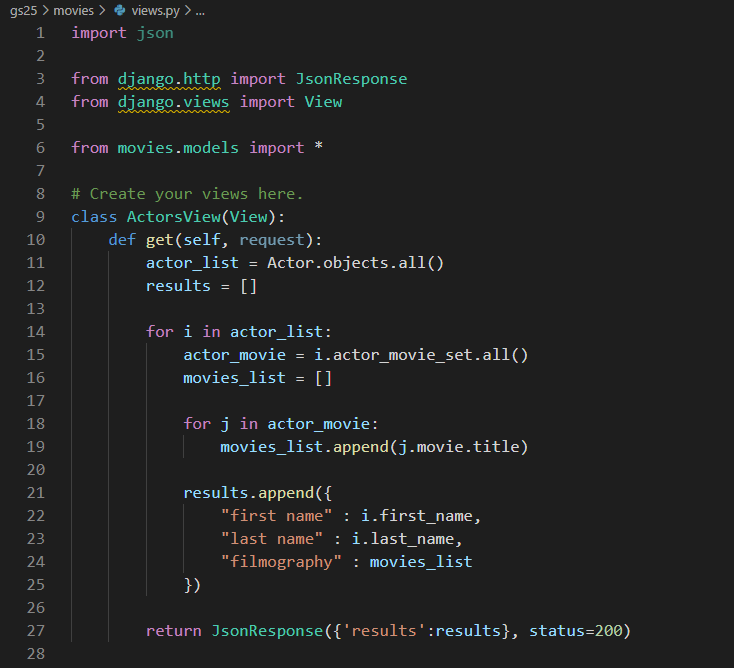
views.py

- urls.py(gs25와 movies의 urls.py)
- 마지막으로, makemigrations와 migrate
그리고 데이터를 삽입해 준다.
은근히 노가다 체질인가보다.
이렇게 작성을 마치면, 이런 결과를 볼 수 있다.

배우의 성과 이름, 그리고 필모그래피 목록이다.
Actor를 가지고 해당 배우가 출연한 영화의 리스트를 가져온 것이다.
비교해보자!
그러면 두 코드가 어떻게 다른지 볼까?
# manytomanyField를 사용한 view
class DiscountView(View):
def get(self, request):
snack_list = Snack.objects.all()
results = []
for snack in snack_list:
discount_card_list = snack.card_set.all()
discount_card = []
for card in discount_card_list:
discount_card.append(card.name)
results.append({
"간식" : snack.name,
"간식id" : snack.id,
"할인카드" : discount_card,
})
return JsonResponse({"results" : results}, status=200)# FK만으로 중간테이블을 구현한 view
class ActorsView(View):
def get(self, request):
actor_list = Actor.objects.all()
results = []
for i in actor_list:
actor_movie = i.actor_movie_set.all()
movies_list = []
for j in actor_movie:
movies_list.append(j.movie.title)
results.append({
"first name" : i.first_name,
"last name" : i.last_name,
"filmography" : movies_list
})
return JsonResponse({'results':results}, status=200)한번에 비교할 수 있도록 아래는 이미지를 가져왔다.
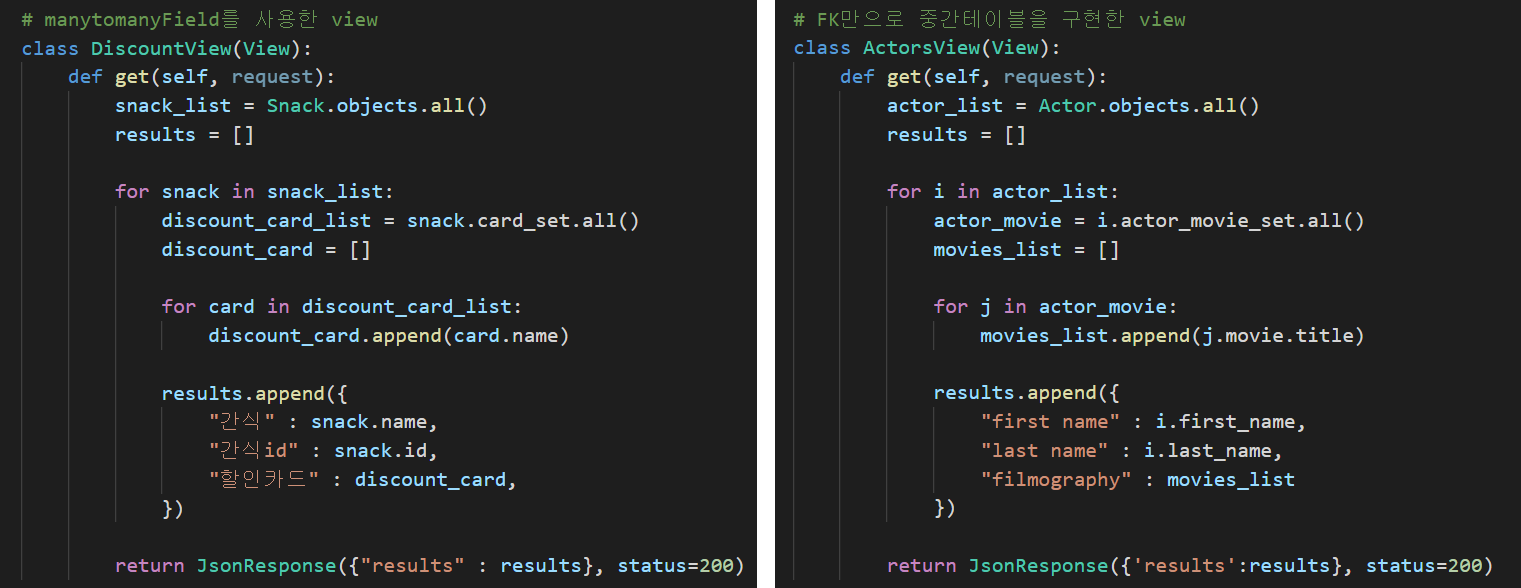
이렇게 보면 거의 똑같아 보인다. 어라, 그러면 굳이 ManytomanyField를 사용할 이유가 뭘까?
조금 더 자세히 보자.
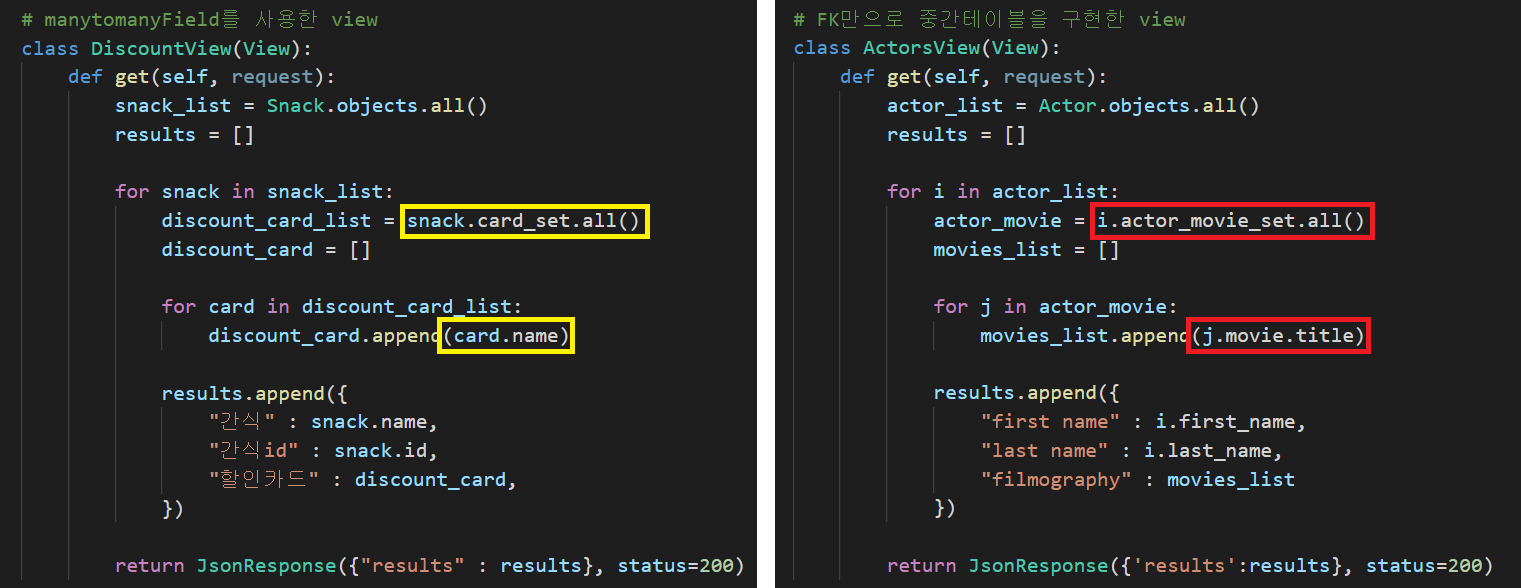
여기가 조금 특이하게 다른 것이 보일 것이다!
이 부분만 자세하게 뜯어보면 아래와 같다.
# manytomanyField를 사용한 view
for snack in snack_list:
discount_card_list = snack.card_set.all()
discount_card = []
for card in discount_card_list:
discount_card.append(card.name)
# FK만으로 중간테이블을 구현한 view
for i in actor_list:
actor_movie = i.actor_movie_set.all()
movies_list = []
for j in actor_movie:
movies_list.append(j.movie.title)먼저 리스트에 all()로 담는 코드를 비교해 보자.
discount_card_list = snack.card_set.all()
actor_movie = i.actor_movie_set.all()-
discount_card_list에서는 객체 snack이 바로
card_set에 들어간다. 이 card_set이란 한 클래스가 역참조될때 자신을 참조하고 있는 클래스(테이블)에서 데이터를 끌어오기 위해 클래스 뒤에 '_set'을 붙여 사용하는 것이다.
그래서 discount_card_list에는 한 snack의 할인카드 객체들 목록이 그대로 들어간다. -
actor_movie에서는 객체 i(Actor 클래스에서 가져온 목록 중 한 배우의 객체)가 자신을 역참조하는 중간 테이블,
actor_movie_set을 모두 가져와 담았다.
그래서 actor_movie에는 한 i(배우)의 id를 가지고 actor_movie 클래스에서 그 배우의 id를 가진 영화의 객체들을 가진 QuerySet이 담기는 것이다.
그러면 각각의 list(QuerySet)에서 값(영화 제목 리스트와 할인카드 리스트)을 꺼내는 방법은 어떻게 다를까?
두 append문을 살펴보자.
discount_card.append(card.name)
movies_list.append(j.movie.title)-
card는 신용카드 객체 그 자체이기 때문에, 바로 card.name으로 Card클래스의 name속성을 꺼낼 수 있다.
-
하지만 j는 중간 테이블인 actor_movie의 객체기 때문에, 참조하고 있는 Movie클래스를 통해 title속성을 꺼낼 수 있다.
이게 끝이야?
이게 끝이다.
ManytomanyField는 중간 테이블을 거치지 않고 목표 테이블의 데이터를 가져올 수 있기 때문에, 코드 자체를 아주 짧게 만들어줄 수 있는 것은 아니지만 코드를 짜는 과정을 쉽게 만들어준다.
또 python shell에서 작업할 때에는 객체에 담는 과정이 없어지기 때문에 훨씬 간단해진다.
