-
오늘 학습 키워드
집계함수 적용법과 subquery 작성 헷갈림 주의 -
오늘 학습한 내용을 나만의 언어로 정리하기
오늘 공부한 내용은 난이도가 꽤 높은 편이었다. 전날 작성한 TIL에도 적혀있듯이, subquery는 SQL에 있어서 넘어야 할 첫 번째 산이었다. 그러나 모든 산이 그러하듯 처음 등반을 할 때는 끝이 보이지 않고 험난했지만, 정복하고 나서 뒤를 돌아보니 해내었다는 뿌듯함과 자신감을 충전할 수 있었다. -
학습 내용
오늘 과제는 총 5 문항이었다.
1번 문제는 집계함수의 활용, 2번 문제는 집계함수와 조건절의 활용, 3번 문제는 집계함수와 조건절의 활용2, 4번 문제는 subquery의 활용, 5번 문제는 subquer의 응용이었다.
1번 문제부터 4번 문제까지는 크게 헷갈리는 부분 없이 금방 넘어갈 수 있었다. 진짜 문제는 5번 문제였다.
-
학습 주제: SQL 집계함수와 그룹화, 내부 중첩의 이해 및 활용
-
핵심 개념 정리: SQL 집계함수를 사용한 뒤에는 꼭 기준 컬럼을 잡아 그룹화 해줄 것. 그리고 원하는 데이터를 정확하게 추출하기 위해서 꼼꼼하게 조건을 확인해볼 것.
-
코드 예시 + 결과:
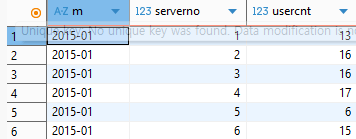
실습 문제를 확인해보자. 먼저 1번 문항이다.아래 조건을 만족시켜 월별, 서버별 게임계정id 수를 중복값 없이 추출해주세요.
월은 첫 접속일자 컬럼을 기준으로 추출해주세요. 전체 결과값 중 일부입니다.
조건1) 월은 yyyy-mm의 형태로 추출
SQL에 꽤나 익숙해졌기에, 어렵지 않게 query를 작성할 수 있었다.
select substr(first_login_date, 1, 7) as m,
serverno,
count(distinct game_account_id) as usercnt
from basic.users
group by 1, 2
;주의해야 할 점은 게임계정 id를 "중복 없이" 추출하는 것이다. 따라서 count()에 반드시 distinct를 적용시켜야 한다.
이 때, 월별 컬럼의 경우 두 가지 방법으로 추출할 수 있는데, 하나는 DATE_FORMAT()을 이용하는 방법, 또 하나는 substr()을 이용하는 방법이다.
DATE_FORMAT()의 경우, 사용자가 원하는 형태로 날짜나 시간을 표시하고 싶을 때 활용한다. 날짜와 시간을 모두 표시할 수도 있고, 연도나 월, 혹은 일자만 따로 표시할 수도 있다.
예를 들어 DATE_FORMAT(컬럼명, '%Y-%m-%d')으로 설정할 경우 '년-월-일'로 날짜가 표시되고, DATE_FORMAT(컬럼명, '%Y-%m')으로 설정할 경우 '년-월'로 날짜가 표시된다.
substr()의 경우, 컬럼 내 데이터의 문자열에서 원하는 순서의 문자부터 잘라서 뽑아내는 방식이다. 여기서는 날짜나 시간을 더하는 것은 불가능하다.
예를 들어 substr(컬럼명, 1, 5)는 컬럼 내 데이터의 첫 번째 글자부터 공백을 포함한 5번째 글자까지만 사용하겠다는 뜻이다.
위에 작성한 코드를 실행하면 다음과 같이 실행된다.
2번 문항으로 넘어가보자. 2번 문항은 다음과 같다.
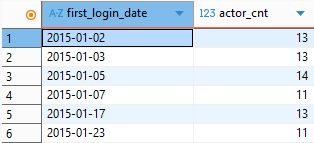
group by 를 활용하여 첫 접속일자별 게임캐릭터수를 중복값 없이 구하고, having 절을 사용하여 그 값이 10개를 초과하는 경우만 추출해주세요. 전체 결과값 중 일부입니다.
여기서도 주의할 점은 "중복값 없이"라는 점이다. 따라서 count()에 반드시 distinct를 적용해야 한다. 또한 having을 통해 그룹화된 컬럼의 데이터를 필터링해주는 것에 유의해서 코드를 작성해야 한다.
select first_login_date,
count(distinct game_actor_id) as actor_cnt
from basic.users
group by 1
having count(distinct game_actor_id)>10
;위 코드를 실행하면 다음과 같이 작동하게 된다.
다음으로 3번 문항이다.
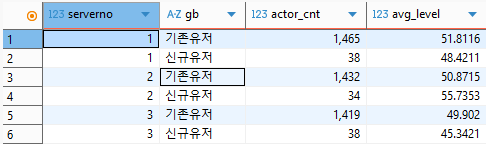
group by 절을 사용하여 서버별, 유저구분(기존/신규)별 게임캐릭터id수 및 평균레벨을 추출해주세요. 게임캐릭터id수는 중복값을 허용하지 않는 고유한 갯수로 추출해주세요. 전체 결과값 중 일부입니다.
조건1) 기존/신규 기준→ 첫 접속일자가 2024-01-01 보다 작으면(미만) 기존유저, 그렇지 않은 경우 신규유저
여기서 조건문이 적용되는데, if문을 사용해도, case when을 사용해도 같은 결괏값을 얻을 수 있다.
if를 사용하는 경우 "if(first_login_date<'2024-01-01', '기존유저', '신규유저')"로 작성하면 된다.
case when을 사용하는 경우 "case when first_login_date<'2024-01-01' then '기존유저' else '신규유저' end"로 작성하면 된다.
이 때 튜터님께서 설명하시길, "if는 거의 사용되지 않고, 대부분 case when을 사용한다"라고 하셨기 때문에, 여기서는 if 대신 case when을 사용하도록 하겠다.
select serverno,
case when first_login_date<'2024-01-01' then '기존유저'
else '신규유저' end as gb,
count(distinct game_actor_id) as actor_cnt,
avg(level) as avg_level
from basic.users
group by 1, 2
;코드는 위와 같이 작성되고, 실행하면 다음과 같다.
4번 문항은 2번 문항을 다른 방식으로 작성하는 연습이었다.
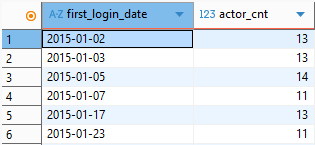
문제2번을 having 이 아닌 인라인 뷰 서브쿼리를 사용하여 추출해주세요.
여기서부터 subquery를 적용하는 연습을 진행했다.
생각해야 할 부분은 having을 빼고 subquery를 어떻게 적용시킬 것인지였다.
답은 간단했다. having의 조건을 빼준 뒤, 기존의 query를 인라인 뷰 subquery로 묶어준 다음, 미리 빼둔 having의 조건을 where절로 바꿔주니 쉽게 해결되었다.
select *
from( select first_login_date,
count(distinct game_actor_id) as actor_cnt
from basic.users
group by 1
) as a
where a.actor_cnt>10
;위 코드를 실행하면 2번 문항과 동일한 결괏값이 출력되는 것을 확인할 수 있었다.
여기까지는 큰 어려움 없이 잘 풀어냈다. 난관은 5번 문항에 있었다.
5번 문항은 다음과 같다.
레벨이 30 이상인 캐릭터를 기준으로, 게임계정 별 캐릭터 수를 중복값 없이 추출해주세요.
그 다음, having 구문을 사용하여 계정별 캐릭터 수가 2개 이상인 경우만 추출해주세요.
마지막으로 인라인 뷰 서브쿼리를 활용하여 캐릭터 수 별 게임계정 개수를 중복값 없이 추출해주세요.
튜터님께서 굉장히 친절하게 조건을 풀어서 적어두셨다. 덕분에 코드를 작성하는 것 자체는 문제 없이 진행되었다. 내가 작성한 코드값도 학습 자료의 예시와 동일하게 추출되어서 '금방 잘 풀었구나' 하고 생각했다. 다음은 내가 가장 처음 작성했던 코드이다.
select a.actor_cnt,
count(a.game_account_id) as accnt
from ( select game_account_id,
count(distinct game_actor_id) as actor_cnt
from basic.users
where level>=30
group by 1
having count(game_account_id)>=2
) as a
group by 1
order by 1
;하지만 다른 팀원들과 내 코드 답안을 비교해보니, 차이가 드러났다. 내가 최초로 작성했던 코드에는 오류가 발생할 가능성이 높다는 것을 확인할 수 있었다.
다음은 팀원이 작성한 코드이다.
select a.actor_cnt,
count(distinct a.game_account_id) as accnt
from
( select game_account_id,
count(distinct game_actor_id) as actor_cnt
from basic.users
where level >= 30
group by 1
having actor_cnt >= 2
) a
group by 1두 코드를 모두 실행해보면 다음과 같이 동일한 데이터가 추출된다.
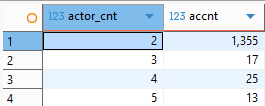
하지만 이 두 코드는 엄연히 다른 내용을 말하고 있다.
내가 작성한 코드와 팀원이 작성한 코드의 차이점은 인라인 뷰 subquery에 있었다.
나는 하나의 계정 안에 복수의 게임 캐릭터가 생성될 수 있다는 것만 생각하고 having에 "count(game_account_id)>=2"로 작성해서 넣었다. 하지만 이것은 중복된 캐릭터가 다른 레벨로 존재하는 경우도 포함하는 데이터를 가지고 있기 때문에 정확한 코드가 아니었다.
팀원이 작성한 having에는 "having actor_cnt >= 2" 이라고 작성되어 있다.
이 문장을 해석하면 "group by로 묶은 범주 내에서 '중복된 캐릭터를 제외하고 모든 캐릭터를 세어 줘'라는 필터를 씌울 것"이라는 뜻이다.
즉, 계정 내에 동일한 캐릭터가 존재하는 경우의 데이터값을 제외하고 결과를 추출하겠다는 의미이다.
따라서 두 코드 모두 출력되는 값은 같지만, 팀원이 작성한 코드가 5번 문항의 조건에 더욱 부합하는 데이터라는 필연적인 결론에 이르게 된다.
최종적으로 나는 코드를 다음과 같이 수정했다.
select a.actor_cnt,
count(*) as accnt
from ( select u.game_account_id,
count(distinct u.game_actor_id) as actor_cnt
from basic.users as u
where level>=30
group by 1
having count(distinct u.game_actor_id)>=2
) as a
group by 1
order by 1
;having의 조건을 바꿔줌으로써 추출되는 데이터의 신뢰성과 정확성을 높여줄 수 있게 되었다.
- 이번 학습을 진행하면서 느낀 점
같은 값이 출력되더라도 전혀 다른 의미를 포함하게 된다는 것을 알 수 있었다. 튜터님께서 세션을 진행하실 때, "현업에서는 반드시 다른 동료들과 크로스체크를 한다"라고 말씀하신 것의 의미를 몸소 깨닫게 되었다. 나는 올바르게 작성했다고 생각할 지 몰라도 객관적으로는 아닐 가능성이 존재한다는 것을 알았고, 데이터를 확인해볼 때에는 더욱 꼼꼼하게 조건을 확인하는 습관을 가질 필요성을 절실히 느꼈다.
- 내일 학습할 것은 무엇인지
내일은 튜터님의 직무 세션을 제외하고는 특별히 준비된 라이브 세션이 없는 날이다. 즉 개인적인 공부를 하기에 좋은 날이라는 것. 오늘 배웠던 SQL 집계함수와 내부 중첩을 한 번 더 복습하고 활용에 익숙해지기 위해 반복 숙달할 예정이다.
마치며 : 아무리 바빠도 식사는 하면서 진행합시다. 다 먹고 살자고 하는 일이 아닌가. 다만, 건강을 생각해서 적당히 먹어야겠지만 말이다.
